Использование критерия Стьюдента для проверки значимости параметров регрессионной модели
Проверка статистической значимости параметров регрессионного уравнения (коэффициентов регрессии) выполняется по t-критерию Стьюдента, который рассчитывается по формуле:

где P — значение параметра;
Sp — стандартное отклонение параметра.
Рассчитанное значение критерия Стьюдента сравнивают с его табличным значением при выбранной доверительной вероятности (как правило, 0.95) и числе степеней свободы N—k-1, где N-число точек, k-число переменных в регрессионном уравнении (например, для линейной модели Y=A*X+B подставляем k=1).
Если вычисленное значение tp выше, чем табличное, то коэффициент регрессии является значимым с данной доверительной вероятностью. В противном случае есть основания для исключения соответствующей переменной из регрессионной модели.
Величины параметров и их стандартные отклонения обычно рассчитываются в алгоритмах, реализующих метод наименьших квадратов.
Критерий Фишера и критерий Стьюдента в эконометрике
С помощью критерия Фишера оценивают качество регрессионной модели в целом и по параметрам.
Для этого выполняется сравнение полученного значения F и табличного F значения. F-критерия Фишера. F фактический определяется из отношения значений факторной и остаточной дисперсий, рассчитанных на одну степень свободы:
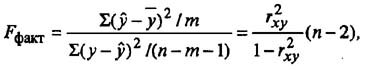
где n — число наблюдений;
m — число параметров при факторе х.
F табличный — это максимальное значение критерия под влиянием случайных факторов при текущих степенях свободы и уровне значимости а.
Уровень значимости а — вероятность не принять гипотезу при условии, что она верна. Как правило а принимается равной 0,05 или 0,01.
Если Fтабл > Fфакт то признается статистическая незначимость модели, ненадежность уравнения регрессии.
Таблицы по нахождению критерия Фишера и Стьюдента
Таблицы значений F-критерия Фишера и t-критерия Стьюдента Вы можете посмотреть здесь.
Табличное значение критерия Фишера вычисляют следующим образом:
- Определяют k1, которое равно количеству факторов (Х). Например, в однофакторной модели (модели парной регрессии) k1=1, в двухфакторной k=2.
- Определяют k2, которое определяется по формуле n — m — 1, где n — число наблюдений, m — количество факторов. Например, в однофакторной модели k2 = n — 2.
- На пересечении столбца k1 и строки k2 находят значение критерия Фишера
Для нахождения табличного значения критерия Стьюдента определяют число степеней свободы, которое определяется по формуле n — m — 1 и находят его значение при определенном уровне значимости (0,10, 0,05, 0,01).
Критерии Стьюдента
Для оценки статистической значимости модели по параметрам рассчитывают t-критерии Стьюдента.
Оценка значимости модели с помощью критерия Стьюдента проводится путем сравнения их значений с величиной случайной ошибки:
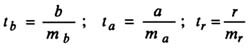
Случайные ошибки коэффициентов линейной регрессии и коэффициента корреляции определяются по формулам:
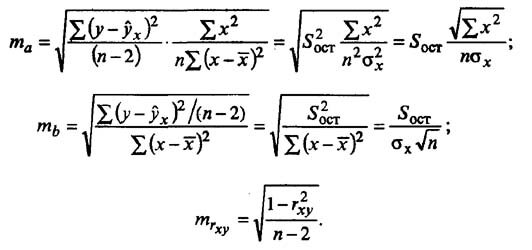
Сравнивая фактическое и табличное значения t-статистики и принимается или отвергается гипотеза о значимости модели по параметрам.
Зависимость между критерием Фишера и значением t-статистики Стьюдента определяется так
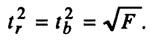
Как и в случае с оценкой значимости уравнения модели в целом, модель считается ненадежной если tтабл > tфакт
Видео лекциий по расчету критериев Фишера и Стьюдента
Для более подробного изучения расчетов критериев Фишера и Стьюдента советуем посмотреть это видео
Лекция 1. Критерии и Гипотезы
Лекция 2. Критерии и Гипотезы
Лекция 3. Критерии и Гипотезы
Определение доверительных интервалов
Для построения доверительного интервала определяется предельная ошибка А для обоих показателей:

Формулы для нахождения доверительных интервалов выглядят так
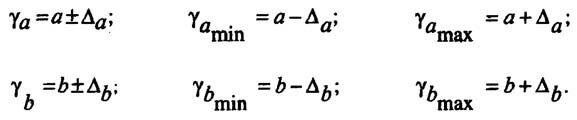
Прогнозное значение у определяется с помощью подстановки в
уравнение регрессии прогнозного значения х. Вычисляется средняя стандартная ошибка прогноза
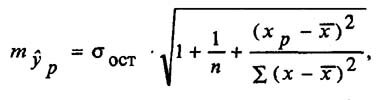
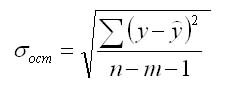
и находится доверительный интервал
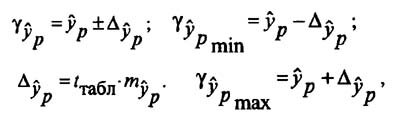
Задача регрессионного анализа в предмете эконометрика состоит в анализе дисперсии изучаемого показателя y:
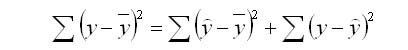
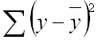 общая сумма квадратов отклонений (TSS)
общая сумма квадратов отклонений (TSS)
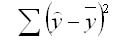 сумма квадратов отклонений, обусловленная регрессией (RSS)
сумма квадратов отклонений, обусловленная регрессией (RSS)
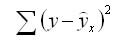 остаточная сумма квадратов отклонений (ESS)
остаточная сумма квадратов отклонений (ESS)
Долю дисперсии, обусловленную регрессией, в общей дисперсии показателя у характеризует коэффициент детерминации R, который должен превышать 50% (R 2 > 0,5). В контрольных по эконометрике в ВУЗах этот показатель рассчитывается всегда.
Проверка на статистическую значимость коэффициентов уравнения регрессии и корреляции.
Качество подбора функции регрессии можно оценить с помощью стандартных ошибок или оценок параметров регрессии. Для оценки статистической значимости коэффициентов регрессии и корреляции рассчитывается t-критерий Стьюдента и доверительные интервалы каждого из показателей. Выдвигается гипотеза Н0 о случайной природе показателей, т.е. о незначимом их отличии от нуля. Оценка значимости коэффициентов регрессии и корреляции с помощью t-критерия Стьюдента проводится путем сопоставления их значений с величиной стандартного отклонения, т.е.:
Стандартные ошибки параметров линейной регрессии и коэффициента корреляции определяются по формулам:
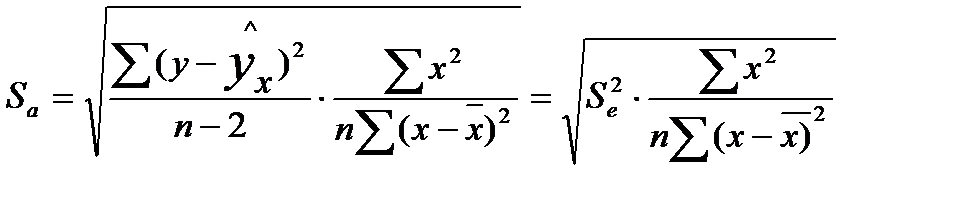

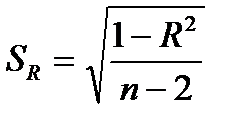
где 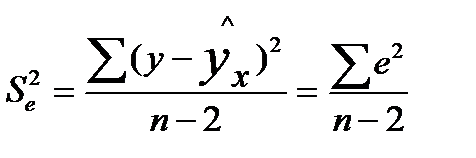 — мера разброса зависимой переменной вокруг линии регрессии (необъясненная дисперсия) или
— мера разброса зависимой переменной вокруг линии регрессии (необъясненная дисперсия) или 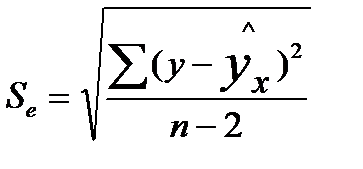 — стандартная ошибка регрессии.
— стандартная ошибка регрессии.
Сравнивая фактическое (расчетное) и критическое (табличное) значения t-статистики, т.е. tфакт и tкрит = t n-1;α — отвергаем или не отвергаем гипотезу Н0:
—если tкрит tфакт,то Н0 не отклоняется и признается случайная природа формирования a, b и R..
Фактическое значение t-критерия Стьюдента определяется как
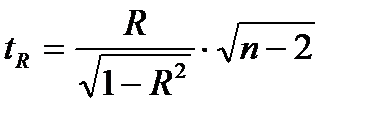
Данная формула свидетельствует, что в парной регрессии 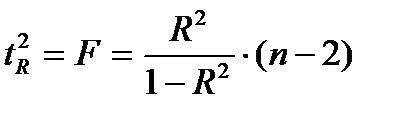 . Кроме того
. Кроме того 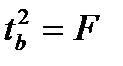 . Следовательно,
. Следовательно, 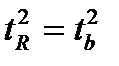
Таким образом, проверка гипотез о значимости коэффициентов регрессии и корреляции равносильна проверке гипотезы о существенности линейного уравнения регрессии.
Формулы для расчета доверительных интервалов a, b имеют следующий вид:
Если в границы доверительного интервала попадает ноль, т.е. нижняя граница отрицательна, а верхняя положительна, то оцениваемый параметр принимается нулевым, т.к. он не может одновременно принимать и положительное, и отрицательное значения.
8.Проверка общего качества уравнения регрессии. Для оценки качества построенной модели используют коэффициент (индекс) детерминации — R 2 , а также среднюю ошибку аппроксимации — А.
F-тест — оценивание качества уравнения регрессии – состоит в проверке гипотезы H0 о статистической не значимости уравнения регрессии и показателя тесноты связи. Для этого выполняется сравнение фактического Fфакт и критического (табличного) Fтабл значений F-критерия Фишера. Fтабл определяется из соотношения значения объясненной и остаточной дисперсии, рассчитанных на одну степень свободы:

где n — объем выборки (объем статистической информации).
Fтабл – это максимально возможное значение критерия под влиянием случайных факторов при данных степенях свободы и уровне значимости a. Уровень значимости a — вероятность отвергнуть правильную гипотезу при условии, что она верна. Обычно a принимается равной 0,05 или 0,01.
Если Fтабл Fфакт, то гипотеза H0 не отклоняется и признаётся статистическая незначимость, ненадёжность уравнения регрессии.
9.Интервалы прогноза по линейному уравнению регрессии.В прогнозных расчетах по уравнению регрессии определяется предсказываемое (расчетное) упрог значение как точечный прогноз  при хпрог=хк, т.е. путем подстановки в уравнение регрессии
при хпрог=хк, т.е. путем подстановки в уравнение регрессии 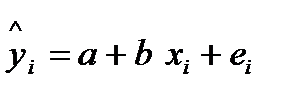 соответствующего прогнозного значения xпрог. Однако точечный прогноз явно не реален. Поэтому он дополняется расчетом стандартной ошибки и соответственно интервальной оценкой прогнозного значения gпрогноз. Фактические значения у варьируют около среднего значения . Индивидуальные значения у могут отклоняться от на величину случайной ошибки e, дисперсия которой оценивается какостаточная дисперсии на одну степень свободы S 2 . Поэтому ошибка предсказываемого индивидуального значения у должна включать не только стандартную ошибку
соответствующего прогнозного значения xпрог. Однако точечный прогноз явно не реален. Поэтому он дополняется расчетом стандартной ошибки и соответственно интервальной оценкой прогнозного значения gпрогноз. Фактические значения у варьируют около среднего значения . Индивидуальные значения у могут отклоняться от на величину случайной ошибки e, дисперсия которой оценивается какостаточная дисперсии на одну степень свободы S 2 . Поэтому ошибка предсказываемого индивидуального значения у должна включать не только стандартную ошибку
S , но и случайную ошибку Se.
Средняя стандартная ошибка прогноза Sпрогноз вычисляется по формуле:
 ,
,
а доверительный интервал прогноза строится по формуле:
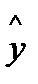 прогноз — tкрит Sпрогноз ≤ gпрогноз ≤
прогноз — tкрит Sпрогноз ≤ gпрогноз ≤  прогноз + tкрит Sпрогноз
прогноз + tкрит Sпрогноз
При прогнозировании на основе уравнения регрессии следует помнить, что величина прогноза зависит не только от стандартной ошибки индивидуального значения у, но и от точности прогноза значения фактора х. Его величина может задаваться на основе анализа других моделей исходя из конкретной ситуации, а также из анализа динамики данного фактора.
10.Таблица дисперсионного анализа. Задача дисперсионного анализа состоит в анализе дисперсии зависимой переменной:å  = å (
= å (  ) 2 + å (
) 2 + å (  ) 2 ,
) 2 ,
где 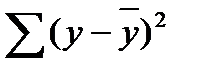 — общая сумма квадратов отклонений;
— общая сумма квадратов отклонений;
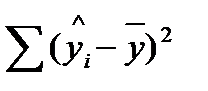 — сумма квадратов отклонений, обусловленная регрессией («объясненная», «факторная»);
— сумма квадратов отклонений, обусловленная регрессией («объясненная», «факторная»);
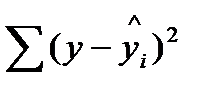 — остаточная сумма квадратов отклонений (“необъясненная”).
— остаточная сумма квадратов отклонений (“необъясненная”).
| Компоненты дисперсии | Сумма квадратов | Число степеней свободы | Дисперсия на одну степень свободы |
| Общая | | n-1 | — |
| Факторная | | m | 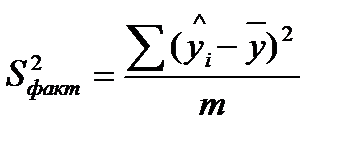 |
| Остаточная | 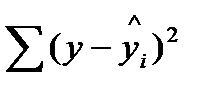 | n-m-1 |  |
Нелинейная регрессия
Нелинейная регрессия -частный случай регрессионного анализа, в котором рассматриваемая регрессионная модель есть функция, зависящая от параметров и от одной или нескольких свободных переменных. Во многих практических случаях моделирование экономических зависимостей линейными уравнениями дает вполне удовлетворительный результат и может использоваться для анализа и прогнозирования. Однако в силу однообразия и сложности экономических процессов ограничиться рассмотрением лишь линейных регрессионных моделей невозможно. Многие экономические зависимости не являются линейными по своей сути, и поэтому их моделирование линейными уравнениями регрессии, безусловно, не даст положительного результата. Например, при рассмотрении спроса Y на некоторый товар от цены X данного товара в ряде случаев можно ограничиться линейным уравнением регрессии: Y=β0+β1X . Здесь β1 характеризует абсолютное изменение Y (в среднем) при единичном изменении X. Если же мы хотим проанализировать эластичность спроса по цене, то приведенное уравнение не позволит это осуществить. В этом случае целесообразно рассмотреть так называемую логарифмическую модель
При анализе издержек Y от объема выпуска X наиболее обоснованной является полиноминальная (точнее, кубическая) модель При рассмотрении производственных функций линейная модель является нереалистичной. В этом случае обычно используются степенные модели. Например, широкую известность имеет производственная функция Кобба-Дугласа Y=AK α L β (здесь Y – объем выпуска; K и L – затраты капитала и труда соответственно; A, α и β – параметры модели).
Достаточно широко применяются в современном эконометрическом анализе и многие другие модели, в частности обратная и экспоненциальная модели.
Построение и анализ нелинейных моделей имеют свою специфику. Приведенные выше примеры и рассуждения дают основания более детально рассмотреть возможные нелинейные модели.
http://univer-nn.ru/ekonometrika/kriterij-fishera-i-kriterij-styudenta-v-ekonometrike/
http://poisk-ru.ru/s51764t1.html