Проверка значимости регрессии с помощью дисперсионного анализа (F-тест)
history 26 января 2019 г.
- Группы статей
- Статистический анализ
Проведем проверку значимости простой линейной регрессии с помощью процедуры F -тест.
Disclaimer : Данную статью не стоит рассматривать, как пересказ главы из учебника по статистике. Статья не обладает ни полнотой, ни строгостью изложения положений статистической науки. Эта статья – о применении MS EXCEL для целей Регрессионного анализа. Теоретические отступления приведены лишь из соображения логики изложения. Использование данной статьи для изучения Регрессии – плохая идея.
Проверку значимости взаимосвязи переменных в рамках модели простой линейной регрессии можно провести разными, но эквивалентными между собой, способами:
Проверку значимости взаимосвязи переменных в рамках модели простой линейной регрессии можно провести разными, но эквивалентными между собой, способами:
Процедуру F -теста рассмотрим на примере простой линейной регрессии , когда прогнозируемая переменная Y зависит только от одной переменной Х.
Чтобы определить может ли предложенная модель линейной регрессии быть использована для адекватного описания значений переменной Y, дисперсию наблюдаемых данных анализируют методом Дисперсионного анализа (ANOVA for Simple Regression) . Дисперсия данных разбивается на компоненты, которые затем используются в F -тесте для определения значимости регрессии.
F -тест для проверки значимости регрессии НЕ относится к простым и интуитивно понятным процедурам. Вероятно, это связано с тем, что для проведения F -теста требуется быть знакомым с определенным количеством статистических понятий и нужно неплохо разбираться в связанных с ними статистических методах. Нам потребуются понятия из следующих разделов статистики:
Можно, конечно, рассмотреть F -тест формально:
- вычислить на основании выборки значение тестовойFстатистики;
- сравнить полученное значение со значением, соответствующему заданному уровню значимости ;
- в зависимости от соотношения этих величин принять решение о значимости вычисленной линейной регрессии
В этой статье ставится более амбициозная задача – разобраться в самом подходе, на котором основан F -тест . Сначала введем несколько определений, которые используются в процедуре F -теста , затем рассмотрим саму процедуру.
Примечание : Для тех, кому некогда, незачем или просто не хочется разбираться в теоретических выкладках предлагается сразу перейти к вычислительной части .
Определения, необходимые для F -теста
Согласно определению дисперсии , дисперсия выборки прогнозируемой переменной Y определяется формулой:
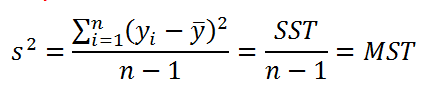
В формуле используется ряд сокращений:
- SST (Total Sum of Squares) – это просто компактное обозначение Суммы Квадратов отклонений от среднего (такое сокращение часто используется в зарубежной литературе).
- MST (Total Mean Square) – Среднее Суммы Квадратов отклонений (еще одно общеупотребительное сокращение).
Примечание : Необходимо иметь в виду, что с одной стороны величины MST и SST являются случайными величинами, вычисленными на основании выборки, т.е. статистиками . Однако с другой стороны, при проведении регрессионного анализа по данным имеющейся выборки вычисляются их конкретные значения. В этом случае величины MST и SST являются просто числами.
Значение n-1 в вышеуказанной формуле равно числу степеней свободы ( DF ) , которое относится к дисперсии выборки (одна степень свободы у n величин yi потеряна в результате наличия ограничения 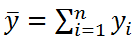 , связывающего все значения выборки). Число степеней свободы у величины SST также имеет специальное обозначение: DFT (DF Total).
, связывающего все значения выборки). Число степеней свободы у величины SST также имеет специальное обозначение: DFT (DF Total).
Как видно из формулы, отношение величин SST и DFT обозначается как MST. Эти 3 величины обычно выдаются в таблице результатов дисперсионного анализа в различных прикладных статистических программах (в том числе и в надстройке Пакет анализа, инструмент Регрессия ).
Значение SST, характеризующую общую изменчивость переменной Y, можно разбить на 2 компоненты:
- Изменчивость объясненную моделью (Explained variation), обозначается SSR
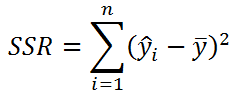
- Необъясненную изменчивость (Unexplained variation), обозначается SSЕ
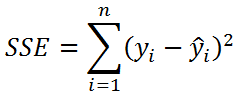
Известно , что справедливо равенство:
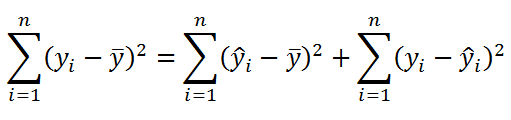
Величинам SSR и SSE также сопоставлены степени свободы . У SSR одна степень свободы , т.к. она однозначно определяется одним параметром – наклоном линии регрессии a (напомним, что мы рассматриваем простую линейную регрессию ). Это очевидно из формулы:
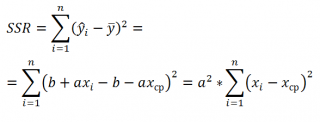
Примечание: Очевидность наличия только одной степени свободы проистекает из факта, что переменная Х – контролируемая (не является случайной величиной).
Число степеней свободы величины SSR имеет специальное обозначение: DFR (для простой регрессии DFR=1, т.к. число независимых переменных Х равно 1) . По аналогии с MST, отношение этих величин также часто обозначают MSR = SSR / DFR .
У SSE число степеней свободы равно n -2 , которое обозначается как DFE (или DFRES — residual degrees of freedom). Двойка вычитается, т.к. изменчивость переменной yi имеет 2 ограничения, связанные с оценкой 2-х параметров линейной модели ( а и b ): ŷi=a*xi+b
Отношение этих величин также часто обозначают MSE = SSE / DFE .
MSR и MSE имеют размерность дисперсий, хотя корректней их называть средними значениями квадратов отклонений. Тем не менее, ниже мы их будем «дисперсиями», т.к. они отображают меру разброса: MSE – меру разброса точек наблюдений относительно линии регрессии, MSR показывает насколько линия регрессии совпадает с горизонтальной линией среднего значения Y.
Примечание : Напомним, что MSE (Mean Square of Errors) является оценкой дисперсии s 2 ошибки, подробнее см. статью про линейную регрессию , раздел Стандартная ошибка регрессии .
Число степеней свободы обладает свойством аддитивности: DFT = DFR + DFE . В этом можно убедиться, составив соответствующее равенство n -1=1+( n -2)
Наконец, определившись с определениями, переходим к рассмотрению самой процедуры F -тест .
Процедура F -теста
Сущность F -теста при проверке значимости регрессии заключается в том, чтобы сравнить 2 дисперсии : объясненную моделью (MSR) и необъясненную (MSE). Если эти дисперсии «примерно равны», то регрессия незначима (построенная модель не позволяет объяснить поведение прогнозируемой Y в зависимости от значений переменной Х). Если дисперсия, объясненная моделью (MSR) «существенно больше», чем необъясненная, то регрессия значимая .
Примечание : Чтобы быстрее разобраться с процедурой F -теста рекомендуется вспомнить процедуру проверки статистических гипотез о равенстве дисперсий 2-х нормальных распределений (т.е. двухвыборочный F-тест для дисперсий ).
Чтобы пояснить вышесказанное изобразим на диаграммах рассеяния 2 случая:
- регрессия значима (в этом случае имеем значительный наклон прямой) и
- регрессия незначима (линия регрессии близка к горизонтальной прямой).
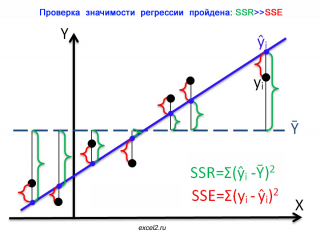
На первой диаграмме показан случай, когда регрессия значима:
- Зеленым цветом выделены расстояния от среднего значения до линии регрессии , вычисленные для каждого хi. Сумма квадратов этих расстояний равна SSR;
- Красным цветом выделены расстояния от линии регрессии до соответствующих точек наблюдений . Сумма квадратов этих расстояний равна SSЕ.
Из диаграммы видно, что в случае значимой регрессии, сумма квадратов «зеленых» расстояний, гораздо больше суммы квадратов «красных». Понятно, что их отношение будет гораздо больше 1. Следовательно, и отношение дисперсий MSR и MSE будет гораздо больше 1 (не забываем, что SSE нужно разделить еще на соответствующее количество степеней свободы n-2).
В случае значимой регрессии точки наблюдений будут находиться вдоль линии регрессии. Их разброс вокруг этой линии описываются ошибками регрессии, которые были минимизированы посредством процедуры МНК . Очевидно, что разброс точек относительно линии регрессии значительно меньше, чем относительно горизонтальной линии, соответствующей среднему значению Y.
Совершенно другую картину мы можем наблюдать в случае незначимой регрессии.
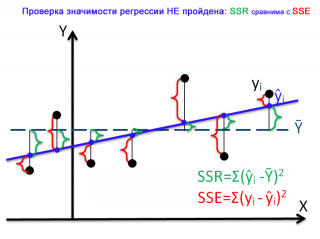
Очевидно, что в этом случае, сумма квадратов «зеленых» расстояний, примерно соответствует сумме квадратов «красных». Это означает, что объясненная дисперсия примерно соответствует величине необъясненной дисперсии (MSR/MSE будет близко к 1).
Если ответ о значимости регрессии практически очевиден для 2-х вышеуказанных крайних ситуаций, то как сделать правильное заключение для промежуточных углов наклона линии регрессии?
Понятно, что если вычисленное на основании выборки значение MSR/MSE будет существенно больше некоторого критического значения, то регрессия значима, если нет, то не значима. Очевидно, что это значение должно быть больше 1, но как определить это критическое значение статистически обоснованным методом ?
Вспомним, что для формулирования статистического вывода (т.е. значима регрессия или нет) используют проверку гипотез . Для этого формулируют 2 гипотезы: нулевую Н 0 и альтернативную Н 1 . Для проверки значимости регрессии в качестве нулевой гипотезы Н 0 принимают, что связи нет, т.е. наклон прямой a=0. В качестве альтернативной гипотезы Н 1 принимают, что a <>0.
Примечание : Даже если связи между переменными нет (a=0), то вычисленная на основании данных выборки оценка наклона — величина а , из-за случайности выборки будет близка, но все же отлична от 0.
По умолчанию принимается, что нулевая гипотеза верна – связи между переменными нет. Если это так, то:
- MSR/MSE будет близко к 1;
- Случайная величина F = MSR/MSE будет иметь F-распределениесо степенями свободы 1 (в числителе) и n-2 (знаменателе). F является тестовой статистикой для проверки значимости регрессии.
Примечание : MSR и MSE являются случайными величинами (т.к. они получены на основе случайной выборки). Соответственно, выражение F=MSR/MSE, также является случайной величиной, которая имеет свое распределение, среднее значение и дисперсию .
Ниже приведен график плотности вероятности F-распределения со степенями свободы 1 (в числителе) и 59 (знаменателе). 59=61-2, 61 наблюдение минус 2 степени свободы.
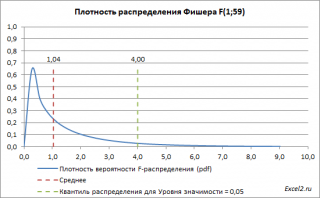
Если нулевая гипотеза верна, то значение F 0 =MSR/MSE, вычисленное на основании выборки, должно быть около ее среднего значения (т.е. около 1,04). Если F 0 будет существенно больше 1 (чем больше F0 отклоняется в сторону больших значений, тем это маловероятней), то это будет означать, что F не имеет F-распределение , а, следовательно, нулевую гипотезу нужно отклонить и принять альтернативную, утверждающую, что связь между переменными есть (значима).
Обычно предполагают, что если вероятность, того что F -статистика приняла значение F0 составляет менее 5%, то это событие маловероятно и нулевую гипотезу необходимо отклонить. 5% — это заданный исследователем уровень значимости , который может быть, например, 1% или 10%.
Значение статистики F0 может быть вычислено на основании выборки:
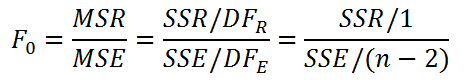
Вычисления в MS EXCEL
В MS EXCEL критическое значение для заданного уровня значимости F1-альфа, 1, n-2 можно вычислить по формуле = F.ОБР(1- альфа;1; n-2) или = F.ОБР.ПХ(альфа;1; n-2) . Другими словами требуется вычислить верхний альфа-квантиль F-распределения с соответствующими степенями свободы .
Таким образом, при значении статистики F0> F1-альфа, 1, n-2 мы имеем основание для отклонения нулевой гипотезы.
Значение F 0 можно вычислить на основании значений выборки по вышеуказанной формуле или с помощью функции ЛИНЕЙН() :
В случае простой регрессии значение F0 также равно квадрату t-статистики, которую мы использовали при проверке двусторонней гипотезе о равенстве 0 коэффициента регрессии .
Проверку значимости регрессии можно также осуществить через вычисление p-значения. В этом случае вычисляют вероятность того, что случайная величина F примет значение F0 (это и есть p-значение), затем сравнивают p-значение с заданным уровнем значимости . Если p-значение больше уровня значимости, то нулевую гипотезу нет оснований отклонить, и регрессия незначима.
В MS EXCEL для проверки гипотезы используя p -значение используйте формулу = F.РАСП.ПХ(F0;1;n-2) файл примера , где показано эквивалентность всех подходов проверки значимости регрессии).
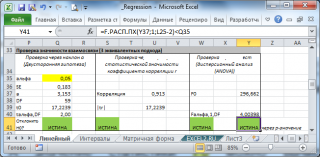
В программах статистики результаты процедуры F -теста выводят с помощью стандартной таблицы дисперсионного анализа . В файле примера такая таблица приведена на листе Таблица, которая построена на основе результатов, возвращаемых инструментом Регрессия надстройки Пакета анализа MS EXCEL .
Пример нахождения статистической значимости коэффициентов регрессии
Числитель в этой формуле может быть рассчитан через коэффициент детерминации и общую дисперсию признака-результата:  .
.
Для параметра a критерий проверки гипотезы о незначимом отличии его от нуля имеет вид:
,
где — оценка параметра регрессии, полученная по наблюдаемым данным;
μa – стандартная ошибка параметра a.
Для линейного парного уравнения регрессии: .
Для проверки гипотезы о незначимом отличии от нуля коэффициента линейной парной корреляции в генеральной совокупности используют следующий критерий: , где ryx — оценка коэффициента корреляции, полученная по наблюдаемым данным; mr – стандартная ошибка коэффициента корреляции ryx.
Для линейного парного уравнения регрессии: .
В парной линейной регрессии между наблюдаемыми значениями критериев существует взаимосвязь: t ( b =0) = t (r=0).
Пример №1 . Уравнение имеет вид y=ax+b
1. Параметры уравнения регрессии.
Средние значения
Связь между признаком Y фактором X сильная и прямая
Уравнение регрессии
Коэффициент детерминации
R 2 = 0.73 2 = 0.54, т.е. в 54% случаев изменения х приводят к изменению y . Другими словами — точность подбора уравнения регрессии — средняя.
| x | y | x 2 | y 2 | x ∙ y | y(x) | (y-y cp ) 2 | (y-y(x)) 2 | (x-x p ) 2 |
| 69 | 124 | 4761 | 15376 | 8556 | 128.48 | 491.36 | 20.11 | 367.36 |
| 83 | 133 | 6889 | 17689 | 11039 | 141.4 | 173.36 | 70.56 | 26.69 |
| 92 | 146 | 8464 | 21316 | 13432 | 149.7 | 0.03 | 13.71 | 14.69 |
| 97 | 153 | 9409 | 23409 | 14841 | 154.32 | 46.69 | 1.73 | 78.03 |
| 88 | 138 | 7744 | 19044 | 12144 | 146.01 | 66.69 | 64.21 | 0.03 |
| 93 | 159 | 8649 | 25281 | 14787 | 150.63 | 164.69 | 70.13 | 23.36 |
| 74 | 145 | 5476 | 21025 | 10730 | 133.1 | 1.36 | 141.68 | 200.69 |
| 79 | 152 | 6241 | 23104 | 12008 | 137.71 | 34.03 | 204.21 | 84.03 |
| 105 | 168 | 11025 | 28224 | 17640 | 161.7 | 476.69 | 39.74 | 283.36 |
| 99 | 154 | 9801 | 23716 | 15246 | 156.16 | 61.36 | 4.67 | 117.36 |
| 85 | 127 | 7225 | 16129 | 10795 | 143.25 | 367.36 | 263.91 | 10.03 |
| 94 | 155 | 8836 | 24025 | 14570 | 151.55 | 78.03 | 11.91 | 34.03 |
| 1058 | 1754 | 94520 | 258338 | 155788 | 1754 | 1961.67 | 906.57 | 1239.67 |
Значимость коэффициента корреляции
По таблице Стьюдента находим Tтабл
Tтабл (n-m-1;a) = (10;0.05) = 1.812
Поскольку Tнабл > Tтабл , то отклоняем гипотезу о равенстве 0 коэффициента корреляции. Другими словами, коэффициента корреляции статистически — значим.
Анализ точности определения оценок коэффициентов регрессии
S a = 0.2704
Доверительные интервалы для зависимой переменной
Рассчитаем границы интервала, в котором будет сосредоточено 95% возможных значений Y при неограниченно большом числе наблюдений и X = 88,16
(128.06;163.97)
Проверка гипотез относительно коэффициентов линейного уравнения регрессии
1) t-статистика
Статистическая значимость коэффициента регрессии a подтверждается (3.41>1.812).
Статистическая значимость коэффициента регрессии b подтверждается (2.7>1.812).
Доверительный интервал для коэффициентов уравнения регрессии
Определим доверительные интервалы коэффициентов регрессии, которые с надежность 95% будут следующими (tтабл=1.812):
(a — tтабл·S a; a + tтабл·Sa)
(0.4325;1.4126)
(b — tтабл·S b; b + tтабл·Sb)
(21.3389;108.3164)
2) F-статистики
Fkp = 4.96
Поскольку F > Fkp, то коэффициент детерминации статистически значим.
Пример №2 . По территориям региона приводятся данные за 199Х г.;
| Среднедневная заработная плата, руб., у | ||
| 1 | 78 | 133 |
| 2 | 82 | 148 |
| 3 | 87 | 134 |
| 4 | 79 | 154 |
| 5 | 89 | 162 |
| 6 | 106 | 195 |
| 7 | 67 | 139 |
| 8 | 88 | 158 |
| 9 | 73 | 152 |
| 10 | 87 | 162 |
| 11 | 76 | 159 |
| 12 | 115 | 173 |
1. Построить линейное уравнение парной регрессии у от х.
2. Рассчитать линейный коэффициент парной корреляции и среднюю ошибку аппроксимации.
3. Оценить статистическую значимость параметров регрессии и корреляции.
4. Выполнить прогноз заработной платы у при прогнозном значении среднедушевого прожиточного минимума х , составляющем 107% от среднего уровня.
5. Оценить точность прогноза, рассчитав ошибку прогноза и его доверительный интервал.
Решение находим с помощью калькулятора.
Использование графического метода .
Этот метод применяют для наглядного изображения формы связи между изучаемыми экономическими показателями. Для этого в прямоугольной системе координат строят график, по оси ординат откладывают индивидуальные значения результативного признака Y, а по оси абсцисс — индивидуальные значения факторного признака X.
Совокупность точек результативного и факторного признаков называется полем корреляции.
На основании поля корреляции можно выдвинуть гипотезу (для генеральной совокупности) о том, что связь между всеми возможными значениями X и Y носит линейный характер.
Линейное уравнение регрессии имеет вид y = bx + a + ε
Здесь ε — случайная ошибка (отклонение, возмущение).
Причины существования случайной ошибки:
1. Невключение в регрессионную модель значимых объясняющих переменных;
2. Агрегирование переменных. Например, функция суммарного потребления – это попытка общего выражения совокупности решений отдельных индивидов о расходах. Это лишь аппроксимация отдельных соотношений, которые имеют разные параметры.
3. Неправильное описание структуры модели;
4. Неправильная функциональная спецификация;
5. Ошибки измерения.
Так как отклонения εi для каждого конкретного наблюдения i – случайны и их значения в выборке неизвестны, то:
1) по наблюдениям xi и yi можно получить только оценки параметров α и β
2) Оценками параметров α и β регрессионной модели являются соответственно величины а и b, которые носят случайный характер, т.к. соответствуют случайной выборке;
Тогда оценочное уравнение регрессии (построенное по выборочным данным) будет иметь вид y = bx + a + ε, где ei – наблюдаемые значения (оценки) ошибок εi, а и b соответственно оценки параметров α и β регрессионной модели, которые следует найти.
Для оценки параметров α и β — используют МНК (метод наименьших квадратов).
Система нормальных уравнений.
Для наших данных система уравнений имеет вид
12a+1027b=1869
1027a+89907b=161808
Из первого уравнения выражаем а и подставим во второе уравнение. Получаем b = 0.92, a = 76.98
Уравнение регрессии: y = 0.92 x + 76.98 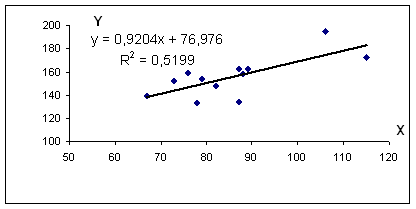
1. Параметры уравнения регрессии.
Выборочные средние.
Коэффициент корреляции
Рассчитываем показатель тесноты связи. Таким показателем является выборочный линейный коэффициент корреляции, который рассчитывается по формуле:
Линейный коэффициент корреляции принимает значения от –1 до +1.
Связи между признаками могут быть слабыми и сильными (тесными). Их критерии оцениваются по шкале Чеддока:
0.1 0 – прямая связь, иначе — обратная). В нашем примере связь прямая.
Коэффициент эластичности.
Коэффициенты регрессии (в примере b) нежелательно использовать для непосредственной оценки влияния факторов на результативный признак в том случае, если существует различие единиц измерения результативного показателя у и факторного признака х.
Для этих целей вычисляются коэффициенты эластичности и бета — коэффициенты. Коэффициент эластичности находится по формуле:
Он показывает, на сколько процентов в среднем изменяется результативный признак у при изменении факторного признака х на 1%. Он не учитывает степень колеблемости факторов.
Коэффициент эластичности меньше 1. Следовательно, при изменении среднедушевого прожиточного минимума в день на 1%, среднедневная заработная плата изменится менее чем на 1%. Другими словами — влияние среднедушевого прожиточного минимума Х на среднедневную заработную плату Y не существенно.
Бета – коэффициент показывает, на какую часть величины своего среднего квадратичного отклонения изменится в среднем значение результативного признака при изменении факторного признака на величину его среднеквадратического отклонения при фиксированном на постоянном уровне значении остальных независимых переменных:
Т.е. увеличение x на величину среднеквадратического отклонения этого показателя приведет к увеличению средней среднедневной заработной платы Y на 0.721 среднеквадратичного отклонения этого показателя.
1.4. Ошибка аппроксимации.
Оценим качество уравнения регрессии с помощью ошибки абсолютной аппроксимации.
Поскольку ошибка меньше 15%, то данное уравнение можно использовать в качестве регрессии.
Коэффициент детерминации.
Квадрат (множественного) коэффициента корреляции называется коэффициентом детерминации, который показывает долю вариации результативного признака, объясненную вариацией факторного признака.
Чаще всего, давая интерпретацию коэффициента детерминации, его выражают в процентах.
R 2 = 0.72 2 = 0.5199, т.е. в 51.99 % случаев изменения среднедушевого прожиточного минимума х приводят к изменению среднедневной заработной платы y. Другими словами — точность подбора уравнения регрессии — средняя. Остальные 48.01% изменения среднедневной заработной платы Y объясняются факторами, не учтенными в модели.
| y 2 | x·y | y(x) | (y i — y ) 2 | (y-y(x)) 2 | (x i — x ) 2 | |y-y x |:y | |||
| 78 | 133 | 6084 | 17689 | 10374 | 148,77 | 517,56 | 248,7 | 57,51 | 0,1186 |
| 82 | 148 | 6724 | 21904 | 12136 | 152,45 | 60,06 | 19,82 | 12,84 | 0,0301 |
| 87 | 134 | 7569 | 17956 | 11658 | 157,05 | 473,06 | 531,48 | 2,01 | 0,172 |
| 79 | 154 | 6241 | 23716 | 12166 | 149,69 | 3,06 | 18,57 | 43,34 | 0,028 |
| 89 | 162 | 7921 | 26244 | 14418 | 158,89 | 39,06 | 9,64 | 11,67 | 0,0192 |
| 106 | 195 | 11236 | 38025 | 20670 | 174,54 | 1540,56 | 418,52 | 416,84 | 0,1049 |
| 67 | 139 | 4489 | 19321 | 9313 | 138,65 | 280,56 | 0,1258 | 345,34 | 0,0026 |
| 88 | 158 | 7744 | 24964 | 13904 | 157,97 | 5,06 | 0,0007 | 5,84 | 0,0002 |
| 73 | 152 | 5329 | 23104 | 11096 | 144,17 | 14,06 | 61,34 | 158,34 | 0,0515 |
| 87 | 162 | 7569 | 26244 | 14094 | 157,05 | 39,06 | 24,46 | 2,01 | 0,0305 |
| 76 | 159 | 5776 | 25281 | 12084 | 146,93 | 10,56 | 145,7 | 91,84 | 0,0759 |
| 115 | 173 | 13225 | 29929 | 19895 | 182,83 | 297,56 | 96,55 | 865,34 | 0,0568 |
| 1027 | 1869 | 89907 | 294377 | 161808 | 1869 | 3280,25 | 1574,92 | 2012,92 | 0,6902 |
2.1. Значимость коэффициента корреляции.
По таблице Стьюдента с уровнем значимости α=0.05 и степенями свободы k=10 находим tкрит:
tкрит = (10;0.05) = 1.812
где m = 1 — количество объясняющих переменных.
Если tнабл > tкритич, то полученное значение коэффициента корреляции признается значимым (нулевая гипотеза, утверждающая равенство нулю коэффициента корреляции, отвергается).
Поскольку tнабл > tкрит, то отклоняем гипотезу о равенстве 0 коэффициента корреляции. Другими словами, коэффициент корреляции статистически — значим.
В парной линейной регрессии t 2 r = t 2 b и тогда проверка гипотез о значимости коэффициентов регрессии и корреляции равносильна проверке гипотезы о существенности линейного уравнения регрессии.
2.3. Анализ точности определения оценок коэффициентов регрессии.
Несмещенной оценкой дисперсии возмущений является величина:
S 2 y = 157.4922 — необъясненная дисперсия (мера разброса зависимой переменной вокруг линии регрессии).
12.5496 — стандартная ошибка оценки (стандартная ошибка регрессии).
S a — стандартное отклонение случайной величины a.
Sb — стандартное отклонение случайной величины b.
2.4. Доверительные интервалы для зависимой переменной.
Экономическое прогнозирование на основе построенной модели предполагает, что сохраняются ранее существовавшие взаимосвязи переменных и на период упреждения.
Для прогнозирования зависимой переменной результативного признака необходимо знать прогнозные значения всех входящих в модель факторов.
Прогнозные значения факторов подставляют в модель и получают точечные прогнозные оценки изучаемого показателя.
(a + bxp ± ε)
где
Рассчитаем границы интервала, в котором будет сосредоточено 95% возможных значений Y при неограниченно большом числе наблюдений и X p = 94
(76.98 + 0.92*94 ± 7.8288)
(155.67;171.33)
С вероятностью 95% можно гарантировать, что значения Y при неограниченно большом числе наблюдений не выйдет за пределы найденных интервалов.
2.5. Проверка гипотез относительно коэффициентов линейного уравнения регрессии.
1) t-статистика. Критерий Стьюдента.
Проверим гипотезу H0 о равенстве отдельных коэффициентов регрессии нулю (при альтернативе H1 не равно) на уровне значимости α=0.05.
tкрит = (10;0.05) = 1.812
Поскольку 3.2906 > 1.812, то статистическая значимость коэффициента регрессии b подтверждается (отвергаем гипотезу о равенстве нулю этого коэффициента).
Поскольку 3.1793 > 1.812, то статистическая значимость коэффициента регрессии a подтверждается (отвергаем гипотезу о равенстве нулю этого коэффициента).
Доверительный интервал для коэффициентов уравнения регрессии.
Определим доверительные интервалы коэффициентов регрессии, которые с надежность 95% будут следующими:
(b — tкрит Sb; b + tкрит Sb)
(0.9204 — 1.812·0.2797; 0.9204 + 1.812·0.2797)
(0.4136;1.4273)
С вероятностью 95% можно утверждать, что значение данного параметра будут лежать в найденном интервале.
(a-ta)
(76.9765 — 1.812·24.2116; 76.9765 + 1.812·24.2116)
(33.1051;120.8478)
С вероятностью 95% можно утверждать, что значение данного параметра будут лежать в найденном интервале.
2) F-статистики. Критерий Фишера.
Проверка значимости модели регрессии проводится с использованием F-критерия Фишера, расчетное значение которого находится как отношение дисперсии исходного ряда наблюдений изучаемого показателя и несмещенной оценки дисперсии остаточной последовательности для данной модели.
Если расчетное значение с k1=(m) и k2=(n-m-1) степенями свободы больше табличного при заданном уровне значимости, то модель считается значимой.
где m – число факторов в модели.
Оценка статистической значимости парной линейной регрессии производится по следующему алгоритму:
1. Выдвигается нулевая гипотеза о том, что уравнение в целом статистически незначимо: H0: R 2 =0 на уровне значимости α.
2. Далее определяют фактическое значение F-критерия:
где m=1 для парной регрессии.
3. Табличное значение определяется по таблицам распределения Фишера для заданного уровня значимости, принимая во внимание, что число степеней свободы для общей суммы квадратов (большей дисперсии) равно 1 и число степеней свободы остаточной суммы квадратов (меньшей дисперсии) при линейной регрессии равно n-2.
4. Если фактическое значение F-критерия меньше табличного, то говорят, что нет основания отклонять нулевую гипотезу.
В противном случае, нулевая гипотеза отклоняется и с вероятностью (1-α) принимается альтернативная гипотеза о статистической значимости уравнения в целом.
Табличное значение критерия со степенями свободы k1=1 и k2=10, Fkp = 4.96
Поскольку фактическое значение F > Fkp, то коэффициент детерминации статистически значим (Найденная оценка уравнения регрессии статистически надежна).
Проверка значимости всего уравнения регрессии в целом
После оценки индивидуальной статистической значимости каждого из коэффициентов регрессии обычно анализируется совокупная значимость коэффициентов, т.е. всего уравнения в целом. Такой анализ осуществляется на основе проверки гипотезы об общей значимости гипотезы об одновременном равенстве нулю всех коэффициентов регрессии при объясняющих переменных:
Если данная гипотеза не отклоняется, то делается вывод о том, что совокупное влияние всех m объясняющих переменных Х1, Х2, . Хm модели на зависимую переменную Y можно считать статистически несущественным, а общее качество уравнения регрессии – невысоким.
Проверка данной гипотезы осуществляется на основе дисперсионного анализа сравнения объясненной и остаточной дисперсии.
Н0: (объясненная дисперсия) = (остаточная дисперсия),
H1: (объясненная дисперсия) > (остаточная дисперсия).
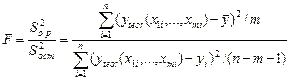 , (8.19)
, (8.19)
где 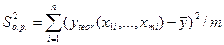 – объясненная регрессией дисперсия;
– объясненная регрессией дисперсия;
 – остаточная дисперсия (сумма квадратов отклонений, поделённая на число степеней свободы n-m-1). При выполнении предпосылок МНК построенная F-статистика имеет распределение Фишера с числами степеней свободы n1 = m, n2 = n–m–1. Поэтому, если при требуемом уровне значимости a Fнабл > Fa; m; n—m-1 = Fa (где Fa; m; n—m-1 — критическая точка распределения Фишера), то Н0 отклоняется в пользу Н1. Это означает, что объяснённая регрессией дисперсия существенно больше остаточной дисперсии, а следовательно, уравнение регрессии достаточно качественно отражает динамику изменения зависимой переменной Y. Если Fнабл 2 :
– остаточная дисперсия (сумма квадратов отклонений, поделённая на число степеней свободы n-m-1). При выполнении предпосылок МНК построенная F-статистика имеет распределение Фишера с числами степеней свободы n1 = m, n2 = n–m–1. Поэтому, если при требуемом уровне значимости a Fнабл > Fa; m; n—m-1 = Fa (где Fa; m; n—m-1 — критическая точка распределения Фишера), то Н0 отклоняется в пользу Н1. Это означает, что объяснённая регрессией дисперсия существенно больше остаточной дисперсии, а следовательно, уравнение регрессии достаточно качественно отражает динамику изменения зависимой переменной Y. Если Fнабл 2 :
Для проверки данной гипотезы используется следующая F-статистика:
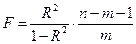 . (8.20)
. (8.20)
Величина F при выполнении предпосылок МНК и при справедливости H0 имеет распределение Фишера, аналогичное распределению F-статистики (8.19). Действительно, разделив числитель и знаменатель дроби в (8.19) на общую сумму квадратов отклонений  и зная, что она распадается на сумму квадратов отклонений, объяснённую регрессией, и остаточную сумму квадратов отклонений (это является следствием, как будет показано позже, системы нормальных уравнений)
и зная, что она распадается на сумму квадратов отклонений, объяснённую регрессией, и остаточную сумму квадратов отклонений (это является следствием, как будет показано позже, системы нормальных уравнений)
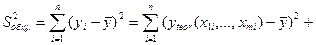
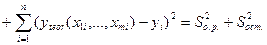 ,
,
мы получим формулу (8.20):
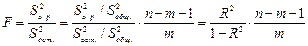 .
.
Из (8.20) очевидно, что показатели F и R 2 равны или не равны нулю одновременно. Если F = 0, то R 2 = 0, и линия регрессии Y = 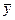 является наилучшей по МНК, и, следовательно, величина Y линейно не зависит от Х1, Х2, . Хm. Для проверки нулевой гипотезы Н0: F = 0 при заданном уровне значимости a по таблицам критических точек распределения Фишера находится критическое значение Fкр = Fa; m; n—m-1. Нулевая гипотеза отклоняется, если F > Fкр. Это равносильно тому, что R 2 > 0, т.е. R 2 статистически значим.
является наилучшей по МНК, и, следовательно, величина Y линейно не зависит от Х1, Х2, . Хm. Для проверки нулевой гипотезы Н0: F = 0 при заданном уровне значимости a по таблицам критических точек распределения Фишера находится критическое значение Fкр = Fa; m; n—m-1. Нулевая гипотеза отклоняется, если F > Fкр. Это равносильно тому, что R 2 > 0, т.е. R 2 статистически значим.
Анализ статистики F позволяет сделать вывод о том, что для принятия гипотезы об одновременном равенстве нулю всех коэффициентов линейной регрессии коэффициент детерминации R 2 не должен существенно отличаться от нуля. Его критическое значение уменьшается при росте числа наблюдений и может стать сколь угодно малым.
Пусть, например, при оценке регрессии с двумя объясняющими переменными X1i, X2i по 30 наблюдениям R 2 = 0,65. Тогда
Fнабл = 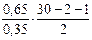 =25,07.
=25,07.
По таблицам критических точек распределения Фишера найдем F0,05; 2; 27 = 3,36; F0,01; 2; 27 = 5,49. Поскольку Fнабл = 25,07 > Fкр как при 5%–м, так и при 1%–м уровне значимости, то нулевая гипотеза в обоих случаях отклоняется.
Если в той же ситуации R 2 = 0,4, то
Fнабл = 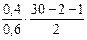 = 9.
= 9.
Предположение о незначимости связи отвергается и здесь.
Отметим, что в случае парной регрессии проверка нулевой гипотезы для F-статистики равносильна проверке нулевой гипотезы для t-статистики

коэффициента корреляции. В этом случае F-статистика равна квадрату t-статистики. Самостоятельную значимость коэффициент R 2 приобретает в случае множественной линейной регрессии.
8.6. Дисперсионный анализ для разложения общей суммы квадратов отклонений. Степени свободы для соответствующих сумм квадратов отклонений
Применим изложенную выше теорию для парной линейной регрессии.
После того, как найдено уравнение линейной регрессии, проводится оценка значимости как уравнения в целом, так и отдельных его параметров.
Оценка значимости уравнения регрессии в целом даётся с помощью F-критерия Фишера. При этом выдвигается нулевая гипотеза, что коэффициент регрессии равен нулю, т.е. b = 0, и, следовательно, фактор х не оказывает влияния на результат у.
Непосредственному расчёту F-критерия предшествует анализ дисперсии. Центральное место в нём занимает разложение общей суммы квадратов отклонений переменной у от среднего значения на две части – “объяснённую” и “необъяснённую”:
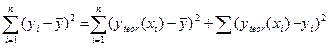 (8.21)
(8.21)
| Общая сумма квадратов отклонений = | Сумма квадратов отклонений, объяснённая дисперсией | Остаточная сумма квадратов отклонений |
Здесь 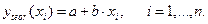
Уравнение (8.21) является следствием системы нормальных уравнений, выведенных в одной предыдущих тем.
Доказательство выражения (8.21).
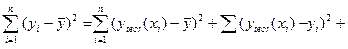


Осталось доказать, что последнее слагаемое равно нулю.
Если сложить от 1 до n все уравнения
то получим åyi = a×å1+b×åxi+åei. Так как åei =0 и å1 =n, то получим
 . (8.23)
. (8.23)
Тогда 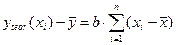 .
.
Если же вычесть из выражения (8.22) уравнение (8.23), то получим
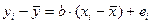 . (8.24)
. (8.24)
 , (8.25)
, (8.25)
В результате получим
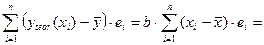
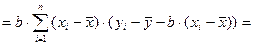
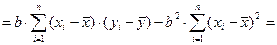
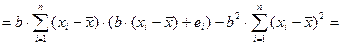


 .
.
Последние суммы равны нулю в силу системы двух нормальных уравнений.
Общая сумма квадратов отклонений индивидуальных значений результативного признака у от среднего значения вызвана влиянием множества причин. Условно разделим всю совокупность причин на две группы: изучаемый фактор х и прочие факторы. Если фактор на оказывает никакого влияния на результат, то линия регрессии параллельна оси OX и 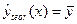 . Тогда вся дисперсия результативного признака обусловлена воздействием прочих факторов и общая сумма квадратов отклонений совпадет с остаточной. Если же прочие факторы не влияют на результат, то у связана с х функционально и остаточная сумма квадратов равна нулю. В этом случае сумма квадратов отклонений, объяснённая регрессией, совпадает с общей суммой квадратов.
. Тогда вся дисперсия результативного признака обусловлена воздействием прочих факторов и общая сумма квадратов отклонений совпадет с остаточной. Если же прочие факторы не влияют на результат, то у связана с х функционально и остаточная сумма квадратов равна нулю. В этом случае сумма квадратов отклонений, объяснённая регрессией, совпадает с общей суммой квадратов.
Поскольку не все точки поля корреляции лежат на линии регрессии, то всегда имеет место их разброс как обусловленный влиянием фактора х, т.е. регрессией у по х, так и вызванный действием прочих причин (необъяснённая вариация). Пригодность линии регрессии для прогноза зависит от того, какая часть общей вариации признака у приходится на объяснённую вариацию. Очевидно, что если сумма квадратов отклонений, обусловленная регрессией, будет больше остаточной суммы квадратов, то уравнение регрессии статистически значимо и фактор х оказывает существенное влияние на признак у. Это равносильно тому, что коэффициент детерминации  будет приближаться к единице.
будет приближаться к единице.
Любая сумма квадратов связана с числом степеней свободы (df – degrees of freedom), с числом свободы независимого варьирования признака. Число степеней свободы связано с числом единиц совокупности n и с числом определяемых по ней констант. Применительно к исследуемой проблеме число степеней свободы должно показать, сколько независимых отклонений из n возможных [  ] требуется для образования данной суммы квадратов. Так, для общей суммы квадратов
] требуется для образования данной суммы квадратов. Так, для общей суммы квадратов  требуется (n-1) независимых отклонений, ибо по совокупности из n единиц после расчёта среднего свободно варьируют лишь (n-1) число отклонений. Например, мы имеем ряд значений у: 1,2,3,4,5. Среднее из них равно 3, и тогда n отклонений от среднего составят: -2, -1, 0, 1, 2. Так как
требуется (n-1) независимых отклонений, ибо по совокупности из n единиц после расчёта среднего свободно варьируют лишь (n-1) число отклонений. Например, мы имеем ряд значений у: 1,2,3,4,5. Среднее из них равно 3, и тогда n отклонений от среднего составят: -2, -1, 0, 1, 2. Так как 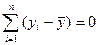 , то свободно варьируют лишь четыре отклонения, а пятое отклонение может быть определено, если предыдущие четыре известны.
, то свободно варьируют лишь четыре отклонения, а пятое отклонение может быть определено, если предыдущие четыре известны.
При расчёте объяснённой или факторной суммы квадратов 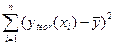 используются теоретические (расчётные) значения результативного признака
используются теоретические (расчётные) значения результативного признака 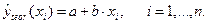
Тогда сумма квадратов отклонений, обусловленных линейной регрессии, равна
 .(8.26)
.(8.26)
Поскольку при заданном объёме наблюдений по x и y факторная сумма квадратов при линейной регрессии зависит только от константы регрессии b, то данная сумма квадратов имеет только одну степень свободы.
Существует равенство между числом степеней свободы общей, факторной и остаточной суммой квадратов отклонений. Число степеней свободы остаточной суммы квадратов при линейной регрессии составляет n-2. Число степеней свободы общей суммы квадратов определяется числом единиц варьируемых признаков, и поскольку мы используем среднюю вычисленную по данным выборки, то теряем одну степень свободы, т.е. dfобщ. = n–1.
Итак, имеем два равенства:
, (8.27)
Разделив каждую сумму квадратов на соответствующее ей число степеней свободы, получим средний квадрат отклонений, или, что то же самое, дисперсию на одну степень свободы D.
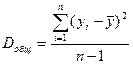 ;
;
 ;
;
 .
.
Определение дисперсии на одну степень свободы приводит дисперсии к сравнимому виду. Сопоставляя факторную и остаточную дисперсии в расчёте на одну степень свободы, получим величину F-критерия Фишера
 ,
,
где F-критерий для проверки нулевой гипотезы H0: Dфакт = Dост.
Если нулевая гипотеза справедлива, то факторная и остаточная дисперсии не отличаются друг от друга. Для H0 необходимо опровержение, чтобы факторная дисперсия превышала остаточную в несколько раз. Английским статистиком Снедекором разработаны таблицы критических значений F-отношений при различных уровнях существенности нулевой гипотезы и различном числе степеней свободы. Табличное значение F-критерия – это максимальная величина отношения дисперсий, которая может иметь место при случайном их расхождении для данного уровня вероятности наличия нулевой гипотезы. Вычисленное значение F-отношения признаётся достоверным, если оно больше табличного. Если Fфакт > Fтабл, то нулевая гипотеза H0: Dфакт = Dост об отсутствии связи признаков отклоняется и делается вывод о существенности этой связи.
Если Fфакт 2 ) = 28979,8 – факторная сумма квадратов;
 =30400-28979,8 = 1420,197 – остаточная сумма квадратов;
=30400-28979,8 = 1420,197 – остаточная сумма квадратов;
Dост = 1420,197/(n-2) = 284,0394;
Fфакт =28979,8/284,0394 = 102,0274;
Поскольку Fфакт > Fтабл как при 1%-ном, так и при 5%-ном уровне значимости, то можно сделать вывод о значимости уравнения регрессии (связь доказана).
Величина F-критерия связана с коэффициентом детерминации . Факторную сумму квадратов отклонений можно представить как
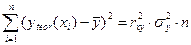 ,
,
а остаточную сумму квадратов – как
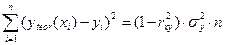 .
.
Тогда значение F-критерия можно выразить как
 .
.
Оценка значимости регрессии обычно даётся в виде таблицы дисперсионного анализа
| Источники вариации | Число степеней свободы | Сумма квадратов отклонений | Дисперсия на одну степень свободы | F-отношение |
| фактическое | Табличное при a=0,05 | |||
| Общая | ||||
| Объяснённая | 28979,8 | 28979,8 | 102,0274 | 6,61 |
| Остаточная | 1420,197 | 284,0394 |
В линейной регрессии обычно оценивается значимость не только уравнения в целом, но и отдельных его параметров. С этой целью по каждому из его параметров определяется его стандартная ошибка: mb и ma.
Стандартная ошибка mb коэффициента регрессии b, как было выведено ранее, определяется по формуле
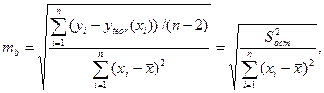
где  — остаточная дисперсия Dост на одну степень свободы.
— остаточная дисперсия Dост на одну степень свободы.
Для нашего примера

Стандартная ошибка коэффициента регрессии a определяется по формуле

где  – остаточная дисперсия Dост на одну степень свободы.
– остаточная дисперсия Dост на одну степень свободы.
Процедура оценивания существенности данного параметра а такая же, как и для параметра b: вычисляется t-критерий 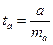 , его величина сравнивается с табличным значением при определённом уровне значимости α и числе степеней свободы (n-2).
, его величина сравнивается с табличным значением при определённом уровне значимости α и числе степеней свободы (n-2).
http://math.semestr.ru/corel/prim3.php
http://megalektsii.ru/s64121t1.html