Расчет коэффициента корреляции
Методы расчета коэффициента корреляции
При изучении различных социально-экономических явлений выделяют функциональную связь и стохастическую зависимость. Функциональная связь — это такой вид связи, при которой некоторому взятому значению факторного показателя соответствует лишь одно значение результативного показателя. Функциональная связь проявляется во всех случаях исследования и для каждой определенной единицы анализируемой совокупности.
Размещено на www.rnz.ru
В том случае, когда причинная зависимость действует не в каждом конкретном случае, а в общем для всей наблюдаемой совокупности, среднем при значительном количестве наблюдений, то такая зависимость является стохастической. Частным случаем стохастической зависимости выступает корреляционная связь, при которой изменение средней величины результативного показателя вызвано изменением значений факторных показателей. Расчет степени тесноты и направления связи выступает значимой задачей исследования и количественной оценки взаимосвязи различных социально-экономических явлений. Определение степени тесноты связи между различными показателями требует определение уровня соотношения изменения результативного признака от изменения одного (в случае исследования парных зависимостей) либо вариации нескольких (в случае исследования множественных зависимостей) признаков-факторов. Для определения такого уровня используется коэффициент корреляции.
Линейный коэффициент корреляции был впервые введен в начале 90-х гг. XIX в. Пирсоном и показывает степень тесноты и направления связи между двумя коррелируемыми факторами в случае, если между ними имеется линейная зависимость. При интерпретации получаемого значения линейного коэффициента корреляции степень тесноты связи между признаками оценивается по шкале Чеддока, один из вариантов этой шкалы приведен в нижеследующей таблице:
Шкала Чеддока количественной оценки степени тесноты связи
| Величина показателя тесноты связи | Характер связи |
|---|---|
| До |±0,3| | Практически отсутствует |
| |±0,3|-|±0,5| | Слабая |
| |±0,5|-|±0,7| | Умеренная |
| |±0,7|-|±1,0| | Сильная |
При интерпретации значения коэффициента линейной корреляции по направлению связи выделяют прямую и обратную. В случае наличия прямой связи с повышением или снижением величины факторного признака происходит повышение или снижение показателей результативного признака, т.е. изменение фактора и результата происходит в одном направлении. Например, повышение величины прибыли способствует росту показателей рентабельности. При наличии обратной связи значения результативного признака изменяются под воздействием факторного, но в противоположном направлении по сравнению с динамикой факторного признака. Например, с повышением производительности труда уменьшается себестоимость единицы выпускаемой продукции и т.п.
Формула расчета коэффициента корреляции
В теории разработаны и на практике применяются различные модификации формул для расчета данного коэффициента. Общая формула для расчета коэффициента корреляции имеет следующий вид:
 Формула расчета коэффициента корреляции
Формула расчета коэффициента корреляции
где r — линейный коэффициент корреляции.
Опираясь на математические свойства средней, общую формулу можно представить следующим образом, получив следующее выражение:
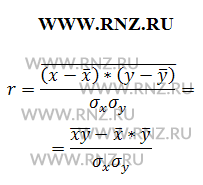 Формула расчета линейного коэффициента парной корреляции
Формула расчета линейного коэффициента парной корреляции
Выполняя дальнейшие преобразование, можно получить следующие формулы вычисления коэффициента корреляции Пирсона:
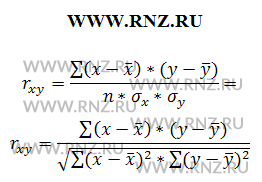 Формула расчета коэффициента корреляции Пирсона
Формула расчета коэффициента корреляции Пирсона
где n — число наблюдений.
Выполняя вычисление по итоговым данным для расчета показателя корреляции, его можно рассчитать с использованием следующих формул:
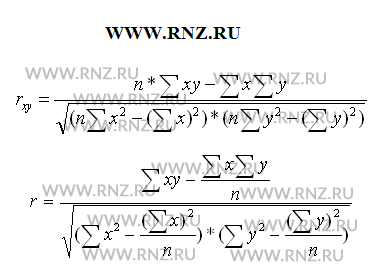 Пирсон онлайн
Пирсон онлайн
Методом расчета показателя корреляции является вычисление данного показателя с использованием его взаимосвязи с дисперсиями факторного и результативного признаков по следующей формуле:
 Формула расчета коэффициента корреляции через дисперсии
Формула расчета коэффициента корреляции через дисперсии
Последние три приведенные формулы используются для изучения взаимосвязи между признаками в совокупностях незначительной величины — до 30 наблюдений.
Также показатель тесноты связи можно определить на основе его взаимосвязи с показателями уравнения регрессии, используя следующее отношение:
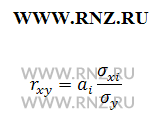 Формула расчета коэффициента корреляции через показатели регрессии
Формула расчета коэффициента корреляции через показатели регрессии
где аi — коэффициент регрессии в уравнении связи;
σхi — среднее квадратическое отклонение соответствующего статистически существенного факторного признака.
Линейный коэффициент корреляции несет в себе важную информацию для успешного изучения социально-экономических явлений и процессов, распределение которых близко к нормальному. Теоретически является обоснованным, что условие rxy = 0 является необходимым и достаточным для того, чтобы факторный и результативный признаки x и y являлись независимыми. При указанном условии, когда показатель корреляции равен нулю, показатели регрессии также имеют нулевые значения, а прямые линии регрессии у по х и х по у являются взаимно перпендикулярными на графике (параллельными: одна прямая — оси х, а другая прямая — оси y).
В том случае, когда rxy = 1, то это означает, что все точки (х, у) расположены на прямой и зависимость между х и у относится к функциональным. При указанном условии прямые линии регрессии совпадают. Указанное положение действует также в случае исследования трех и более показателей, если они подчинены закону нормального распределения.
В целом значение линейного показателя связи находится в диапазоне от — 1 до 1, т.е.: -1
Пример расчета коэффициента корреляции
Приведем пример расчета коэффициента корреляции Пирсона для значений, приведенных в следующей таблице. Для этого используем следующие данные (пример условный):
| Значение показателя X | Значение показателя Y |
|---|---|
| 1,1 | 1,3 |
| 1,9 | 1,1 |
| 1,5 | 1,2 |
| 1,9 | 0,5 |
| 1,9 | 1,5 |
| 1,1 | 1,7 |
| 0,9 | 2 |
| 1 | 0,9 |
| 1,3 | 1,2 |
| 1,5 | 1,7 |
Количество наблюдений менее 30, поэтому в нашем примере для расчета парного коэффициента корреляции используем следующую формулу:
Для этого составим вспомогательную таблицу:
| № п/п | X | Y | xy | x 2 | y 2 |
|---|---|---|---|---|---|
| 1 | 1,1 | 1,3 | 1,43 | 1,21 | 1,69 |
| 2 | 1,9 | 1,1 | 2,09 | 3,61 | 1,21 |
| 3 | 1,5 | 1,2 | 1,8 | 2,25 | 1,44 |
| 4 | 1,9 | 0,5 | 0,95 | 3,61 | 0,25 |
| 5 | 1,9 | 1,5 | 2,85 | 3,61 | 2,25 |
| 6 | 1,1 | 1,7 | 1,87 | 1,21 | 2,89 |
| 7 | 0,9 | 2 | 1,8 | 0,81 | 4 |
| 8 | 1 | 0,9 | 0,9 | 1 | 0,81 |
| 9 | 1,3 | 1,2 | 1,56 | 1,69 | 1,44 |
| 10 | 1,5 | 1,7 | 2,55 | 2,25 | 2,89 |
| Итого | 14,1 | 13,1 | 17,8 | 21,25 | 18,87 |
Методология вычисления: r = (17,8-14,1*13,1/10)/(√((21,25-14,1*14,1/10)*(18,87-13,1*13,1/10))) = -0,4389.
Полученное значение коэффициента корреляции Пирсона говорит о наличии обратной связи между X и Y. Величина коэффициента корреляции Пирсона показывает, что связь между X и Y слабая.
Онлайн калькулятор расчета коэффициента корреляции
В заключении приводим небольшой онлайн калькулятор расчета коэффициента корреляции онлайн, используя который, Вы можете самостоятельно выполнить расчет значения коэффициента корреляции Пирсона и получить интерпретацию рассчитанного значения. При заполнении формы калькулятора внимательно соблюдайте размерность полей, что позволит выполнить расчет коэффициента корреляции онлайн быстро и точно. В форме онлайн калькулятора уже содержатся данные условного примера, чтобы пользователь мог посмотреть, как это работает. Для определения значения показателя по своим данным просто внесите их в соответствующие поля формы онлайн калькулятора и нажмите кнопку «Выполнить вычисления». При заполнении формы соблюдайте размерность показателей! Дробные числа записываются с точной, а не запятой!
Онлайн-калькулятор расчета коэффициента корреляции:
Пример нахождения коэффициента корреляции

Другие варианты формул:
или 

Кxy — корреляционный момент (коэффициент ковариации)

 Для нахождения линейного коэффициента корреляции Пирсона необходимо найти выборочные средние x и y , и их среднеквадратические отклонения σx = S(x), σy = S(y):
Для нахождения линейного коэффициента корреляции Пирсона необходимо найти выборочные средние x и y , и их среднеквадратические отклонения σx = S(x), σy = S(y):
Свойства коэффициента корреляции
- |rxy| ≤ 1;, -1≤x≤1
- если X и Y независимы, то rxy=0 , обратное не всегда верно;
- если |rxy|=1 , то Y=aX+b , |rxy(X,aX+b)|=1 , где a и b постоянные, а ≠ 0;
- |rxy(X,Y)|=|rxy(a1X+b1, a2X+b2)|, где a1, a2, b1, b2 – постоянные.
Поэтому для проверки направления связи выбирается проверка гипотезы при помощи коэффициента корреляции Пирсона с дальнейшей проверкой на достоверность при помощи t-критерия (пример см. ниже).
- Решение онлайн
- Видеоинструкция
- Оформление Word
- Типовые задачи
Вместе с этим калькулятором также используют следующие:
Уравнение множественной регрессии
Пример . На основе данных, приведенных в Приложении 1 и соответствующих Вашему варианту (таблица 2), требуется:
- Рассчитать коэффициент линейной парной корреляции и построить уравнение линейной парной регрессии одного признака от другого. Один из признаков, соответствующих Вашему варианту, будет играть роль факторного (х), другой – результативного (y). Причинно-следственные связи между признаками установить самим на основе экономического анализа. Пояснить смысл параметров уравнения.
- Определить теоретический коэффициент детерминации и остаточную (необъясненную уравнением регрессии) дисперсию. Сделать вывод.
- Оценить статистическую значимость уравнения регрессии в целом на пятипроцентном уровне с помощью F-критерия Фишера. Сделать вывод.
- Выполнить прогноз ожидаемого значения признака-результата y при прогнозном значении признака-фактора х, составляющим 105% от среднего уровня х. Оценить точность прогноза, рассчитав ошибку прогноза и его доверительный интервал с вероятностью 0,95.
Решение. Уравнение имеет вид y = ax + b
Средние значения
Коэффициент регрессии: k = a = 4.01
Коэффициент детерминации
R 2 = 0.99 2 = 0.97, т.е. в 97% случаев изменения х приводят к изменению y . Другими словами — точность подбора уравнения регрессии — высокая. Остаточная дисперсия: 3%.
| x | y | x 2 | y 2 | x·y | y(x) | (yi— y ) 2 | (y-y(x)) 2 | (x-x p ) 2 |
| 1 | 107 | 1 | 11449 | 107 | 103.19 | 333.06 | 14.5 | 30.25 |
| 2 | 109 | 4 | 11881 | 218 | 107.2 | 264.06 | 3.23 | 20.25 |
| 3 | 110 | 9 | 12100 | 330 | 111.21 | 232.56 | 1.47 | 12.25 |
| 4 | 113 | 16 | 12769 | 452 | 115.22 | 150.06 | 4.95 | 6.25 |
| 5 | 120 | 25 | 14400 | 600 | 119.23 | 27.56 | 0.59 | 2.25 |
| 6 | 122 | 36 | 14884 | 732 | 123.24 | 10.56 | 1.55 | 0.25 |
| 7 | 123 | 49 | 15129 | 861 | 127.26 | 5.06 | 18.11 | 0.25 |
| 8 | 128 | 64 | 16384 | 1024 | 131.27 | 7.56 | 10.67 | 2.25 |
| 9 | 136 | 81 | 18496 | 1224 | 135.28 | 115.56 | 0.52 | 6.25 |
| 10 | 140 | 100 | 19600 | 1400 | 139.29 | 217.56 | 0.51 | 12.25 |
| 11 | 145 | 121 | 21025 | 1595 | 143.3 | 390.06 | 2.9 | 20.25 |
| 12 | 150 | 144 | 22500 | 1800 | 147.31 | 612.56 | 7.25 | 30.25 |
| 78 | 1503 | 650 | 190617 | 10343 | 1503 | 2366.25 | 66.23 | 143 |
Примечание: значения y(x) находятся из полученного уравнения регрессии:
y(1) = 4.01*1 + 99.18 = 103.19
y(2) = 4.01*2 + 99.18 = 107.2
. . .
Значимость коэффициента корреляции
Анализ точности определения оценок коэффициентов регрессии
Доверительные интервалы для зависимой переменной
Рассчитаем границы интервала, в котором будет сосредоточено 95% возможных значений Y при неограниченно большом числе наблюдений и X = 7
(122.4;132.11)
Проверка гипотез относительно коэффициентов линейного уравнения регрессии
Статистическая значимость коэффициента регрессии подтверждается (18.63>2.228).
Статистическая значимость коэффициента регрессии подтверждается (62.62>2.228).
Доверительный интервал для коэффициентов уравнения регрессии
Определим доверительные интервалы коэффициентов регрессии, которые с надежность 95% будут следующими (tтабл=2.228):
(a — tтабл·Sa; a + tтабл·S a)
(3.6205;4.4005)
(b — tтабл·Sb; b + tтабл·Sb)
(96.3117;102.0519)
Пример №2
1. Расчет средних значений x , y : x = ∑xi n = 660.6 11 = 60.05 y = ∑yi n = 333.94 11 = 30.36 x·y = ∑xi·yi n = 19952.07 11 = 1813.82
2. Расчет дисперсий: S 2 (x) = xi 2 n — x 2 = 40337.2 11 — 60.05 2 = 60.47 S 2 (y) = yi 2 n — y 2 = 10329.52 11 — 30.36 2 = 17.43 3. Расчет среднеквадратических отклонений: S(x) = √ S 2 (x) = √ 60.47 = 7.78 S(y) = √ S 2 (y) = √ 17.43 = 4.17
4. Расчет линейного коэффициента корреляции Пирсона: rxy = x·y — x · y S(x)·S(y) = 1813.82-60.05·30.36 7.78·4.17 = -0.2872 Линейный коэффициент корреляции принимает значения от –1 до +1.
Связи между признаками могут быть слабыми и сильными (тесными). Их критерии оцениваются по шкале Чеддока:
0.1 2
Значимость линейного коэффициента корреляции Пирсона. tнабл = rxy· √ n-2 √ 1-rxy 2 = 0.2872· √ 9 √ 1-0.2872 2 = 0.9
По таблице Стьюдента с уровнем значимости α=0.05 и степенями свободы k=n-m-1=11-1-1=9 находим tкрит: tкрит(n-m-1;α/2) = tкрит(9;0.025) = 2.262, где m=1 — количество объясняющих переменных.
Если tнабл > tкритич, то полученное значение коэффициента корреляции Пирсона признается значимым (нулевая гипотеза, утверждающая равенство нулю коэффициента корреляции, отвергается).
Поскольку tнабл , то принимаем гипотезу о равенстве 0 коэффициента корреляции. Другими словами, коэффициент корреляции статистически — не значим
В парной линейной регрессии t 2 r = t 2 b и тогда проверка гипотез о значимости коэффициентов регрессии и корреляции равносильна проверке гипотезы о существенности линейного уравнения регрессии.
Интервальная оценка для линейного коэффициента корреляции Пирсона ( rxy — tкрит· 1-rxy 2 √ n ; rxy + tкрит· 1-rxy 2 √ n )
Доверительный интервал для коэффициента корреляции ( 0.29 — 2.262· 1-0.29 2 √ 11 ; 0.29 + 2.262· 1-0.29 2 √ 11 ) Доверительный интервал для линейного коэффициента корреляции Пирсона: r(-0.9129;0.3386)
Корреляции для начинающих
Апдейт для тех, кто сочтет статью полезной и занесет в избранное. Есть приличный шанс, что пост уйдет в минуса, и я буду вынужден унести его в черновики. Сохраняйте копию!
Краткий и несложный материал для неспециалистов, рассказывающий в наглядной форме о различных методах поиска регрессионных зависимостей. Это все и близко не академично, зато надеюсь что понятно. Прокатит как мини-методичка по обработке данных для студентов естественнонаучных специальностей, которые математику знают плохо, впрочем как и автор. Расчеты в Матлабе, подготовка данных в Экселе — так уж повелось в нашей местности 
Введение
Зачем это вообще надо? В науке и около нее очень часто возникает задача предсказания какого-то неизвестного параметра объекта исходя из известных параметров этого объекта (предикторов) и большого набора похожих объектов, так называемой учебной выборки. Пример. Вот мы выбираем на базаре яблоко. Его можно описать такими предикторами: красность, вес, количество червяков. Но как потребителей нас интересует вкус, измеренный в попугаях по пятибалльной шкале. Из жизненного опыта нам известно, что вкус с приличной точностью равен 5*красность+2*вес-7*количество червяков. Вот про поиск такого рода зависимостей мы и побеседуем. Чтобы обучение пошло легче, попробуем предсказать вес девушки исходя из ее 90/60/90 и роста.
Исходные данные
В качестве объекта исследования возьму данные о параметрах фигуры девушек месяца Плейбоя. Источник — www.wired.com/special_multimedia/2009/st_infoporn_1702, слегка облагородил и перевел из дюймов в сантиметры. Вспоминается анекдот про то, что 34 дюйма — это как два семнадцатидюймовых монитора. Также отделил записи с неполной информацией. При работе с реальными объектами их можно использовать, но сейчас они нам только мешают. Зато их можно использовать для проверки адекватности полученных результатов. Все данные у нас непрерывные, то есть грубо говоря типа float. Они приведены к целым числам только чтобы не загромождать экран. Есть способы работы и с дискретными данными — в нашем примере это например может быть цвет кожи или национальность, которые принимают одно из фиксированного набора значений. Это больше имеет отношение к методам классификации и принятия решений, что тянет еще на один мануал. Data.xls В файле два листа. На первом собственно данные, на втором — отсеянные неполные данные и набор для проверки нашей модели.
Обозначения
W — вес реальный
W_p — вес, предсказанный нашей моделью
S — бюст
T — талия
B — бедра
L — рост
E — ошибка модели
Как оценить качество модели?
Задача нашего упражнения — получить некую модель, которая описывает какой-либо объект. Способ получения и принцип работы конкретной модели нас пока не волнует. Это просто функция f(S, T, B, L), которая выдает вес девушки. Как понять, какая функция хорошая и качественная, а какая не очень? Для этого используется так называемая fitness function. Самая классическая и часто используемая — это сумма квадратов разницы предсказанного и реального значения. В нашем случае это будет сумма (W_p — W)^2 для всех точек. Собственно, отсюда и пошло название «метод наименьших квадратов». Критерий не лучший и не единственный, но вполне приемлемый как метод по умолчанию. Его особенность в том, что он чувствителен по отношению к выбросам и тем самым, считает такие модели менее качественными. Есть еще всякие методы наименьших модулей итд, но сейчас нам это пока не надо.
Простая линейная регрессия
Самый простой случай. У нас одна переменная-предиктор и одна зависимая переменная. В нашем случае это может быть например рост и вес. Нам надо построить уравнение W_p = a*L+b, т.е. найти коэффициенты a и b. Если мы проведем этот расчет для каждого образца, то W_p будет максимально совпадать с W для того же образца. То есть у нас для каждой девушки будет такое уравнение:
W_p_i = a*L_i+b
E_i = (W_p-W)^2
Общая ошибка в таком случае составит sum(E_i). В результате, для оптимальных значений a и b sum(E_i) будет минимальным. Как же найти уравнение?
Матлаб
Для упрощения очень рекомендую поставить плагин для Excel под названием Exlink. Он в папке matlab/toolbox/exlink. Очень облегчает пересылку данных между программами. После установки плагина появляется еще одно меню с очевидным названием, и автоматически запускается Матлаб. Переброс информации из Экселя в Матлаб запускается командой «Send data to MATLAB», обратно, соответственно, — «Get data from MATLAB». Пересылаем в Матлаб числа из столбца L и отдельно из W, без заголовков. Переменные назовем так же. Функция расчета линейной регрессии — polyfit(x,y,1). Единица показывает степень аппроксимационного полинома. У нас он линейный, поэтому единица. Получаем наконец-то коэффициенты регрессии: regr=polyfit(L,W,1) . a мы можем получить как regr(1), b — как regr(2). То есть мы можем получить наши значения W_p: W_p=L*repr(1)+repr(2) . Вернем их назад в Эксель.
Графичек
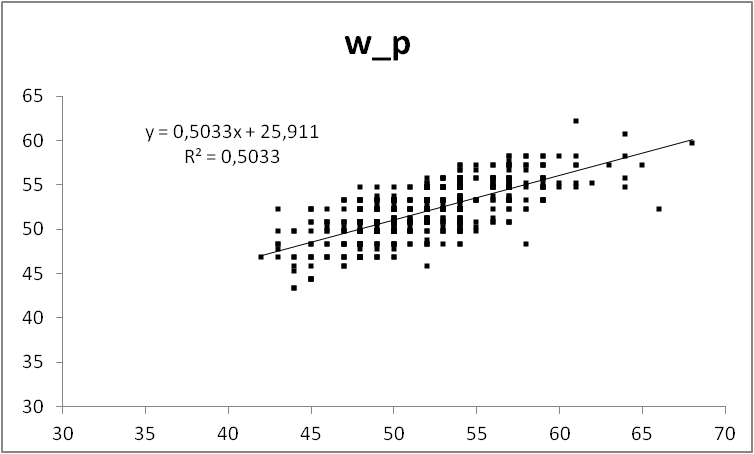
Мда, негусто. Это график W_p(W). Формула на графике показывает связь W_p и W. В идеале там будет W_p = W*1 + 0. Вылезла дискретизация исходных данных — облако точек клетчатое. Коэффициент корреляции ни в дугу — данные слабо коррелированы между собой, т.е. наша модель плохо описывает связь веса и роста. По графику это видно как точки, расположенные в форме слабо вытянутого вдоль прямой облака. Хорошая модель даст облако растянутое в узкую полосу, еще более плохая — просто хаотичный набор точек или круглое облако. Модель необходимо дополнить. Про коэффициент корреляции стоит рассказать отдельно, потому что его часто используют абсолютно неправильно.
Расчет в матричном виде
Можно и без всяких полифитов справиться с построением регрессии, если слегка дополнить столбец с величинами роста еще одним столбцом, заполненным единицами: L(:,2)=1 . Двойка показывает номер столбца, в который пишутся единицы. Тогда коэффициенты регрессии можно будет найти по такой формуле: repr=inv(L’*L)*L’*W . И обратно, найти W_p: W_p=L*repr . Когда осознаешь магию матриц, пользоваться функциями становится неприкольно. Единичный столбец нужен для расчета свободного члена регрессии, то есть просто слагаемого без умножения на параметр. Если его не добавлять, то в регрессии будет всего один член: W_p=a*L. Достаточно очевидно, что она будет хуже по качеству, чем регрессия с двумя слагаемыми. В целом, избавляться от свободного члена надо только в том случае, если он точно не нужен. По умолчанию он все-таки присутствует.
Мультилинейная регрессия
В русскоязычной литературе прошлых лет упоминается как ММНК — метод множественных наименьших квадратов. Это расширение метода наименьших квадратов для нескольких предикторов. То есть у нас в дело идет не только рост, но и все остальные, так сказать, горизонтальные размеры. Подготовка данных точно такая же: обе матрицы в матлаб, добавление столбца единиц, расчет по той же самой формуле. Для любителей функций есть b = regress(y,X) . Эта функция также требует добавления столбца единиц. Повторяем расчет по формуле из раздела про матрицы, пересылаем в Эксель, смотрим.
Попытка номер два
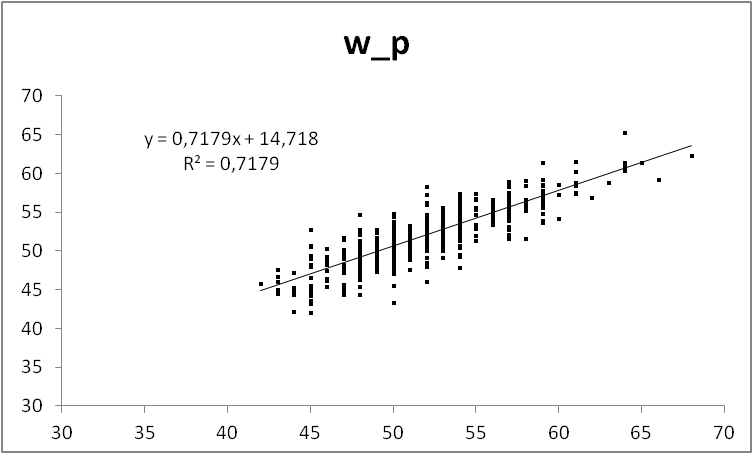
А так получше, но все равно не очень. Как видим, клетчатость осталась только по горизонтали. Никуда не денешься, исходные веса были целыми числами в фунтах. То есть после конверсии в килограммы они ложатся на сетку с шагом около 0.5. Итого финальный вид нашей модели:
W_p = 0.2271*S + 0.1851*T + 0.3125*B + 0.3949*L — 72.9132
Объемы в сантиметрах, вес в кг. Поскольку у нас все величины кроме роста в одних единицах измерения и примерно одного порядка по величине (кроме талии), то мы можем оценить их вклады в общий вес. Рассуждения примерно в таком духе: коэффициент при талии самый маленький, равно как и сами величины в сантиметрах. Значит, вклад этого параметра в вес минимален. У бюста и особенно у бедер он больше, т.е. сантиметр на талии дает меньшую прибавку к массе, чем на груди. А больше всего на вес влияет объем задницы. Впрочем, это знает любой интересующийся вопросом мужчина. То есть как минимум, наша модель реальной жизни не противоречит.
Валидация модели
Название громкое, но попробуем получить хотя бы ориентировочные веса тех девушек, для которых есть полный набор размеров, но нет веса. Их 7: с мая по июнь 1956 года, июль 1957, март 1987, август 1988. Находим предсказанные по модели веса: W_p=X*repr 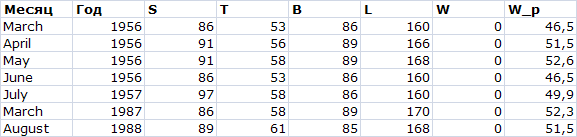
Что ж, по крайней мере в текстовом виде выглядит правдоподобно. А насколько это соответствует реальности — решать вам
Применимость
Если вкратце — полученная модель годится для объектов, подобных нашему набору данных. То есть по полученным корреляциям не стоит считать параметры фигур женщин с весом 80+, возрастом, сильно отличающимся от среднего по больнице итд. В реальных применениях можно считать, что модель пригодна, если параметры изучаемого объекта не слишком отличаются от средних значений этих же параметров для исходного набора данных. Могут возникнуть (и возникнут) проблемы, если у нас предикторы сильно коррелированы между собой. То есть, например это рост и длина ног. Тогда коэффициенты для соответствующих величин в уравнении регрессии будут определены с малой точностью. В таком случае надо выбросить один из параметров, или воспользоваться методом главных компонент для снижения количества предикторов. Если у нас малая выборка и/или много предикторов, то мы рискуем попасть в переопределенность модели. То есть если мы возьмем 604 параметра для нашей выборки (а в таблице всего 604 девушки), то сможем аналитически получить уравнение с 604+1 слагаемым, которое абсолютно точно опишет то, что мы в него забросили. Но предсказательная сила у него будет весьма невелика. Наконец, далеко не все объекты можно описать мультилинейной зависимостью. Бывают и логарифмические, и степенные, и всякие сложные. Их поиск — это уже совсем другой вопрос.
http://math.semestr.ru/corel/prim.php
http://habr.com/ru/post/172043/