Основы линейной регрессии
Что такое регрессия?
Разместим точки на двумерном графике рассеяния и скажем, что мы имеем линейное соотношение, если данные аппроксимируются прямой линией.
Если мы полагаем, что y зависит от x, причём изменения в y вызываются именно изменениями в x, мы можем определить линию регрессии (регрессия y на x), которая лучше всего описывает прямолинейное соотношение между этими двумя переменными.
Статистическое использование слова «регрессия» исходит из явления, известного как регрессия к среднему, приписываемого сэру Френсису Гальтону (1889).
Он показал, что, хотя высокие отцы имеют тенденцию иметь высоких сыновей, средний рост сыновей меньше, чем у их высоких отцов. Средний рост сыновей «регрессировал» и «двигался вспять» к среднему росту всех отцов в популяции. Таким образом, в среднем высокие отцы имеют более низких (но всё-таки высоких) сыновей, а низкие отцы имеют сыновей более высоких (но всё-таки довольно низких).
Линия регрессии
Математическое уравнение, которое оценивает линию простой (парной) линейной регрессии:
x называется независимой переменной или предиктором.
Y – зависимая переменная или переменная отклика. Это значение, которое мы ожидаем для y (в среднем), если мы знаем величину x, т.е. это «предсказанное значение y»
- a – свободный член (пересечение) линии оценки; это значение Y, когда x=0 (Рис.1).
- b – угловой коэффициент или градиент оценённой линии; она представляет собой величину, на которую Y увеличивается в среднем, если мы увеличиваем x на одну единицу.
- a и b называют коэффициентами регрессии оценённой линии, хотя этот термин часто используют только для b.
Парную линейную регрессию можно расширить, включив в нее более одной независимой переменной; в этом случае она известна как множественная регрессия.

Рис.1. Линия линейной регрессии, показывающая пересечение a и угловой коэффициент b (величину возрастания Y при увеличении x на одну единицу)
Метод наименьших квадратов
Мы выполняем регрессионный анализ, используя выборку наблюдений, где a и b – выборочные оценки истинных (генеральных) параметров, α и β , которые определяют линию линейной регрессии в популяции (генеральной совокупности).
Наиболее простым методом определения коэффициентов a и b является метод наименьших квадратов (МНК).
Подгонка оценивается, рассматривая остатки (вертикальное расстояние каждой точки от линии, например, остаток = наблюдаемому y – предсказанный y, Рис. 2).
Линию лучшей подгонки выбирают так, чтобы сумма квадратов остатков была минимальной.

Рис. 2. Линия линейной регрессии с изображенными остатками (вертикальные пунктирные линии) для каждой точки.
Предположения линейной регрессии
Итак, для каждой наблюдаемой величины  остаток равен разнице
остаток равен разнице  и соответствующего предсказанного
и соответствующего предсказанного  Каждый остаток может быть положительным или отрицательным.
Каждый остаток может быть положительным или отрицательным.
Можно использовать остатки для проверки следующих предположений, лежащих в основе линейной регрессии:
- Между
 и существует линейное соотношение: для любых пар данные должны аппроксимировать прямую линию. Если нанести на двумерный график остатки, то мы должны наблюдать случайное рассеяние точек, а не какую-либо систематическую картину.
и существует линейное соотношение: для любых пар данные должны аппроксимировать прямую линию. Если нанести на двумерный график остатки, то мы должны наблюдать случайное рассеяние точек, а не какую-либо систематическую картину.
 данные должны аппроксимировать прямую линию. Если нанести на двумерный график остатки, то мы должны наблюдать случайное рассеяние точек, а не какую-либо систематическую картину.
данные должны аппроксимировать прямую линию. Если нанести на двумерный график остатки, то мы должны наблюдать случайное рассеяние точек, а не какую-либо систематическую картину.- Остатки нормально распределены с нулевым средним значением;
- Остатки имеют одну и ту же вариабельность (постоянную дисперсию) для всех предсказанных величин Если нанести остатки против предсказанных величин от мы должны наблюдать случайное рассеяние точек. Если график рассеяния остатков увеличивается или уменьшается с увеличением то это допущение не выполняется;
 Если нанести остатки против предсказанных величин
Если нанести остатки против предсказанных величин  от
от  мы должны наблюдать случайное рассеяние точек. Если график рассеяния остатков увеличивается или уменьшается с увеличением
мы должны наблюдать случайное рассеяние точек. Если график рассеяния остатков увеличивается или уменьшается с увеличением  то это допущение не выполняется;
то это допущение не выполняется;Если допущения линейности, нормальности и/или постоянной дисперсии сомнительны, мы можем преобразовать или и рассчитать новую линию регрессии, для которой эти допущения удовлетворяются (например, использовать логарифмическое преобразование или др.).
Аномальные значения (выбросы) и точки влияния
«Влиятельное» наблюдение, если оно опущено, изменяет одну или больше оценок параметров модели (т.е. угловой коэффициент или свободный член).
Выброс (наблюдение, которое противоречит большинству значений в наборе данных) может быть «влиятельным» наблюдением и может хорошо обнаруживаться визуально, при осмотре двумерной диаграммы рассеяния или графика остатков.
И для выбросов, и для «влиятельных» наблюдений (точек) используют модели, как с их включением, так и без них, обращают внимание на изменение оценки (коэффициентов регрессии).
При проведении анализа не стоит отбрасывать выбросы или точки влияния автоматически, поскольку простое игнорирование может повлиять на полученные результаты. Всегда изучайте причины появления этих выбросов и анализируйте их.
Гипотеза линейной регрессии
При построении линейной регрессии проверяется нулевая гипотеза о том, что генеральный угловой коэффициент линии регрессии β равен нулю.
Если угловой коэффициент линии равен нулю, между и нет линейного соотношения: изменение не влияет на 
Для тестирования нулевой гипотезы о том, что истинный угловой коэффициент  равен нулю можно воспользоваться следующим алгоритмом:
равен нулю можно воспользоваться следующим алгоритмом:
Вычислить статистику критерия, равную отношению  , которая подчиняется
, которая подчиняется  распределению с
распределению с  степенями свободы, где
степенями свободы, где  стандартная ошибка коэффициента
стандартная ошибка коэффициента 

 ,
,
 — оценка дисперсии остатков.
— оценка дисперсии остатков.
Обычно если достигнутый уровень значимости  нулевая гипотеза отклоняется.
нулевая гипотеза отклоняется.
Можно рассчитать 95% доверительный интервал для генерального углового коэффициента :

где  процентная точка распределения со степенями свободы
процентная точка распределения со степенями свободы  что дает вероятность двустороннего критерия
что дает вероятность двустороннего критерия 
Это тот интервал, который содержит генеральный угловой коэффициент с вероятностью 95%.
Для больших выборок, скажем,  мы можем аппроксимировать
мы можем аппроксимировать  значением 1,96 (то есть статистика критерия будет стремиться к нормальному распределению)
значением 1,96 (то есть статистика критерия будет стремиться к нормальному распределению)
Оценка качества линейной регрессии: коэффициент детерминации R 2
Из-за линейного соотношения и мы ожидаем, что изменяется, по мере того как изменяется , и называем это вариацией, которая обусловлена или объясняется регрессией. Остаточная вариация должна быть как можно меньше.
Если это так, то большая часть вариации будет объясняться регрессией, а точки будут лежать близко к линии регрессии, т.е. линия хорошо соответствует данным.
Долю общей дисперсии , которая объясняется регрессией называют коэффициентом детерминации, обычно выражают через процентное соотношение и обозначают R 2 (в парной линейной регрессии это величина r 2 , квадрат коэффициента корреляции), позволяет субъективно оценить качество уравнения регрессии.
Разность  представляет собой процент дисперсии который нельзя объяснить регрессией.
представляет собой процент дисперсии который нельзя объяснить регрессией.
Нет формального теста для оценки  мы вынуждены положиться на субъективное суждение, чтобы определить качество подгонки линии регрессии.
мы вынуждены положиться на субъективное суждение, чтобы определить качество подгонки линии регрессии.
Применение линии регрессии для прогноза
Можно применять регрессионную линию для прогнозирования значения по значению в пределе наблюдаемого диапазона (никогда не экстраполируйте вне этих пределов).
Мы предсказываем среднюю величину для наблюдаемых, которые имеют определенное значение  путем подстановки этого значения в уравнение линии регрессии.
путем подстановки этого значения в уравнение линии регрессии.
Итак, если  прогнозируем как
прогнозируем как  Используем эту предсказанную величину и ее стандартную ошибку, чтобы оценить доверительный интервал для истинной средней величины в популяции.
Используем эту предсказанную величину и ее стандартную ошибку, чтобы оценить доверительный интервал для истинной средней величины в популяции.
Повторение этой процедуры для различных величин позволяет построить доверительные границы для этой линии. Это полоса или область, которая содержит истинную линию, например, с 95% доверительной вероятностью.
Подобным образом можно рассчитать более широкую область, внутри которой, как мы ожидаем, лежит наибольшее число (обычно 95%) наблюдений.
Простые регрессионные планы
Простые регрессионные планы содержат один непрерывный предиктор. Если существует 3 наблюдения со значениями предиктора P , например, 7, 4 и 9, а план включает эффект первого порядка P , то матрица плана X будет иметь вид

а регрессионное уравнение с использованием P для X1 выглядит как
Если простой регрессионный план содержит эффект высшего порядка для P , например квадратичный эффект, то значения в столбце X1 в матрице плана будут возведены во вторую степень:

а уравнение примет вид
Y = b 0 + b 1 P 2
Сигма -ограниченные и сверхпараметризованные методы кодирования не применяются по отношению к простым регрессионным планам и другим планам, содержащим только непрерывные предикторы (поскольку, просто не существует категориальных предикторов). Независимо от выбранного метода кодирования, значения непрерывных переменных увеличиваются в соответствующей степени и используются как значения для переменных X . При этом перекодировка не выполняется. Кроме того, при описании регрессионных планов можно опустить рассмотрение матрицы плана X , а работать только с регрессионным уравнением.
Пример: простой регрессионный анализ
Этот пример использует данные, представленные в таблице:

Рис. 3. Таблица исходных данных.
Данные составлены на основе сравнения переписей 1960 и 1970 в произвольно выбранных 30 округах. Названия округов представлены в виде имен наблюдений. Информация относительно каждой переменной представлена ниже:

Рис. 4. Таблица спецификаций переменных.
Задача исследования
Для этого примера будут анализироваться корреляция уровня бедности и степень, которая предсказывает процент семей, которые находятся за чертой бедности. Следовательно мы будем трактовать переменную 3 ( Pt_Poor ) как зависимую переменную.
Можно выдвинуть гипотезу: изменение численности населения и процент семей, которые находятся за чертой бедности, связаны между собой. Кажется разумным ожидать, что бедность ведет к оттоку населения, следовательно, здесь будет отрицательная корреляция между процентом людей за чертой бедности и изменением численности населения. Следовательно мы будем трактовать переменную 1 ( Pop_Chng ) как переменную-предиктор.
Просмотр результатов
Коэффициенты регрессии

Рис. 5. Коэффициенты регрессии Pt_Poor на Pop_Chng.
На пересечении строки Pop_Chng и столбца Парам. не стандартизованный коэффициент для регрессии Pt_Poor на Pop_Chng равен -0.40374 . Это означает, что для каждого уменьшения численности населения на единицу, имеется увеличение уровня бедности на .40374. Верхний и нижний (по умолчанию) 95% доверительные пределы для этого не стандартизованного коэффициента не включают ноль, так что коэффициент регрессии значим на уровне p . Обратите внимание на не стандартизованный коэффициент, который также является коэффициентом корреляции Пирсона для простых регрессионных планов, равен -.65, который означает, что для каждого уменьшения стандартного отклонения численности населения происходит увеличение стандартного отклонения уровня бедности на .65.
Распределение переменных
Коэффициенты корреляции могут стать существенно завышены или занижены, если в данных присутствуют большие выбросы. Изучим распределение зависимой переменной Pt_Poor по округам. Для этого построим гистограмму переменной Pt_Poor .

Рис. 6. Гистограмма переменной Pt_Poor.
Как вы можете заметить, распределение этой переменной заметно отличается от нормального распределения. Тем не менее, хотя даже два округа (два правых столбца) имеют высокий процент семей, которые находятся за чертой бедности, чем ожидалось в случае нормального распределения, кажется, что они находятся «внутри диапазона.»

Рис. 7. Гистограмма переменной Pt_Poor.
Это суждение в некоторой степени субъективно. Эмпирическое правило гласит, что выбросы необходимо учитывать, если наблюдение (или наблюдения) не попадают в интервал (среднее ± 3 умноженное на стандартное отклонение). В этом случае стоит повторить анализ с выбросами и без, чтобы убедиться, что они не оказывают серьезного эффекта на корреляцию между членами совокупности.
Диаграмма рассеяния
Если одна из гипотез априори о взаимосвязи между заданными переменными, то ее полезно проверить на графике соответствующей диаграммы рассеяния.

Рис. 8. Диаграмма рассеяния.
Диаграмма рассеяния показывает явную отрицательную корреляцию ( -.65 ) между двумя переменными. На ней также показан 95% доверительный интервал для линии регрессии, т.е., с 95% вероятностью линия регрессии проходит между двумя пунктирными кривыми.
Критерии значимости

Рис. 9. Таблица, содержащая критерии значимости.
Критерий для коэффициента регрессии Pop_Chng подтверждает, что Pop_Chng сильно связано с Pt_Poor , p .
На этом примере было показано, как проанализировать простой регрессионный план. Была также представлена интерпретация не стандартизованных и стандартизованных коэффициентов регрессии. Обсуждена важность изучения распределения откликов зависимой переменной, продемонстрирована техника определения направления и силы взаимосвязи между предиктором и зависимой переменной.
Простая линейная регрессия
В предыдущих заметках предметом анализа часто становилась отдельная числовая переменная, например, доходность взаимных фондов, время загрузки Web-страницы или объем потребления безалкогольных напитков. В настоящей и следующих заметках мы рассмотрим методы предсказания значений числовой переменной в зависимости от значений одной или нескольких других числовых переменных. [1]
Материал будет проиллюстрирован сквозным примером. Прогнозирование объема продаж в магазине одежды. Сеть магазинов уцененной одежды Sunflowers на протяжении 25 лет постоянно расширялась. Однако в настоящее время у компании нет систематического подхода к выбору новых торговых точек. Место, в котором компания собирается открыть новый магазин, определяется на основе субъективных соображений. Критериями выбора являются выгодные условия аренды или представления менеджера об идеальном местоположении магазина. Представьте, что вы — руководитель отдела специальных проектов и планирования. Вам поручили разработать стратегический план открытия новых магазинов. Этот план должен содержать прогноз годового объема продаж во вновь открываемых магазинах. Вы полагаете, что торговая площадь непосредственно связана с объемом выручки, и хотите учесть этот факт в процессе принятия решения. Как разработать статистическую модель, позволяющую прогнозировать годовой объем продаж на основе размера нового магазина?
Как правило, для предсказания значений переменной используется регрессионный анализ. Его цель — разработать статистическую модель, позволяющую предсказывать значения зависимой переменной, или отклика, по значениям, по крайней мере одной, независимой, или объясняющей, переменной. В настоящей заметке мы рассмотрим простую линейную регрессию — статистический метод, позволяющий предсказывать значения зависимой переменной Y по значениям независимой переменной X. В последующих заметках будет описана модель множественной регрессии, предназначенная для предсказания значений независимой переменной Y по значениям нескольких зависимых переменных (Х1, Х2, …, Xk). [2]
Скачать заметку в формате Word или pdf, примеры в формате Excel2013
Виды регрессионных моделей
В заметке Представление числовых данных в виде таблиц и диаграмм для иллюстрации зависимости между переменными X и Y использовалась диаграмма разброса. На ней значения переменной X откладывались по горизонтальной оси, а значения переменной Y — по вертикальной. Зависимость между двумя переменными может быть разной: от самой простой до крайне сложной. Пример простейшей (линейной) зависимости показан на рис. 1.

Рис. 1. Положительная линейная зависимость
Простая линейная регрессия:
где β0 — сдвиг (длина отрезка, отсекаемого на координатной оси прямой Y), β1 — наклон прямой Y, εi— случайная ошибка переменной Y в i-м наблюдении.
В этой модели наклон β1 представляет собой количество единиц измерения переменной Y, приходящихся на одну единицу измерения переменной X. Эта величина характеризует среднюю величину изменения переменной Y (положительного или отрицательного) на заданном отрезке оси X. Сдвиг β0 представляет собой среднее значение переменной Y, когда переменная X равна 0. Последний компонент модели εi является случайной ошибкой переменной Y в i-м наблюдении. Выбор подходящей математической модели зависит от распределения значений переменных X и Y на диаграмме разброса. Различные виды зависимости переменных показаны на рис. 2.
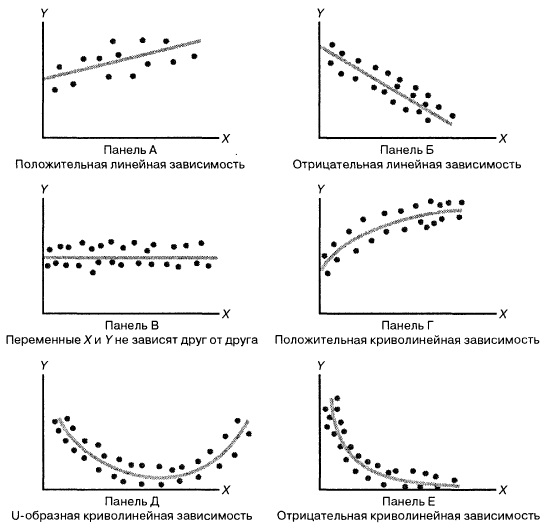
Рис. 2. Диаграммы разброса, иллюстрирующие разные виды зависимостей
На панели А значения переменной Y почти линейно возрастают с увеличением переменной X. Этот рисунок аналогичен рис. 1, иллюстрирующему положительную зависимость между размером магазина (в квадратных футах) и годовым объемом продаж. Панель Б является примером отрицательной линейной зависимости. Если переменная X возрастает, переменная Y в целом убывает. Примером этой зависимости является связь между стоимостью конкретного товара и объемом продаж. На панели В показан набор данных, в котором переменные X и Y практически не зависят друг от друга. Каждому значению переменной X соответствуют как большие, так и малые значения переменной Y. Данные, приведенные на панели Г, демонстрируют криволинейную зависимость между переменными X и Y. Значения переменной Y возрастают при увеличении переменной X, однако скорость роста после определенных значений переменной X падает. Примером положительной криволинейной зависимости является связь между возрастом и стоимостью обслуживания автомобилей. По мере старения машины стоимость ее обслуживания сначала резко возрастает, однако после определенного уровня стабилизируется. Панель Д демонстрирует параболическую U-образную форму зависимости между переменными X и Y. По мере увеличения значений переменной X значения переменной Y сначала убывают, а затем возрастают. Примером такой зависимости является связь между количеством ошибок, совершенных за час работы, и количеством отработанных часов. Сначала работник осваивается и делает много ошибок, потом привыкает, и количество ошибок уменьшается, однако после определенного момента он начинает чувствовать усталость, и число ошибок увеличивается. На панели Е показана экспоненциальная зависимость между переменными X и Y. В этом случае переменная Y сначала очень быстро убывает при возрастании переменной X, однако скорость этого убывания постепенно падает. Например, стоимость автомобиля при перепродаже экспоненциально зависит от его возраста. Если перепродавать автомобиль в течение первого года, его цена резко падает, однако впоследствии ее падение постепенно замедляется.
Мы кратко рассмотрели основные модели, которые позволяют формализовать зависимости между двумя переменными. Несмотря на то что диаграмма разброса чрезвычайно полезна при выборе математической модели зависимости, существуют более сложные и точные статистические процедуры, позволяющие описать отношения между переменными. В дальнейшем мы будем рассматривать лишь линейную зависимость.
Вывод уравнения простой линейной регрессии
Вернемся к сценарию, изложенному в начале главы. Наша цель — предсказать объем годовых продаж для всех новых магазинов, зная их размеры. Для оценки зависимости между размером магазина (в квадратных футах) и объемом его годовых продаж создадим выборки из 14 магазинов (рис. 3).

Рис. 3. Площади и годовые объемы продаж 14 магазинов сети Sunflowers: (а) исходные данные; (б) диаграмма разброса
Анализ рис. 3 показывает, что между площадью магазина X и годовым объемом продаж Y существует положительная зависимость. Если площадь магазина увеличивается, объем продаж возрастает почти линейно. Таким образом, наиболее подходящей для исследования является линейная модель. Остается лишь определить, какая из линейных моделей точнее остальных описывает зависимость между анализируемыми переменными.
Метод наименьших квадратов
Данные, представленные на рис. 1а, получены для случайной выборки магазинов. Если верны некоторые предположения (об этом чуть позже), в качестве оценки параметров генеральной совокупности (β0 и β1) можно использовать сдвиг b0 и наклон b1 прямой Y. Таким образом, уравнение простой линейной регрессии принимает следующий вид:

где  — предсказанное значение переменной Y для i-гo наблюдения, Xi — значение переменной X в i-м наблюдении.
— предсказанное значение переменной Y для i-гo наблюдения, Xi — значение переменной X в i-м наблюдении.
Для того чтобы предсказать значение переменной Y, в уравнении (2) необходимо определить два коэффициента регрессии — сдвиг b0 и наклон b1 прямой Y. Вычислив эти параметры, проведем прямую на диаграмме разброса. Затем исследователь может визуально оценить, насколько близка регрессионная прямая к точкам наблюдения. Простая линейная регрессия позволяет найти прямую линию, максимально приближенную к точкам наблюдения. Критерии соответствия можно задать разными способами. Возможно, проще всего минимизировать разности между фактическими значениями Yi, и предсказанными значениями . Однако, поскольку эти разности могут быть как положительными, так и отрицательными, следует минимизировать сумму их квадратов.
Поскольку = b0 + b1Xi, сумма квадратов принимает следующий вид:

Параметры b0 и b1 неизвестны. Таким образом, сумма квадратов разностей является функцией, зависящей от сдвига b0 и наклона b1 выборки Y. Для того чтобы найти значения параметров b0 и b1, минимизирующих сумму квадратов разностей, применяется метод наименьших квадратов. При любых других значениях сдвига b0 и наклона b1 сумма квадратов разностей между фактическими значениями переменной Y и ее наблюдаемыми значениями лишь увеличится.
До того, как Excel взял на себя всю рутинную работу, вычисления по методу наименьших квадратов были очень трудоемкими. Excel позволяет решать подобные задачи двумя способами. Во-первых, можно воспользоваться Пакетом анализа (строка Регрессия). Результаты представлены на рис. 4. Во-вторых, можно, выделив точки на графике (как на рис. 3б), кликнуть правой кнопкой мыши и выбрать Добавить линию тренда. Далее можно выбрать вид линии тренда (в нашем случае – Линейная), отформатировать линию, показать на графике уравнение и величину достоверности аппроксимации (R 2 ) (рис. 5).
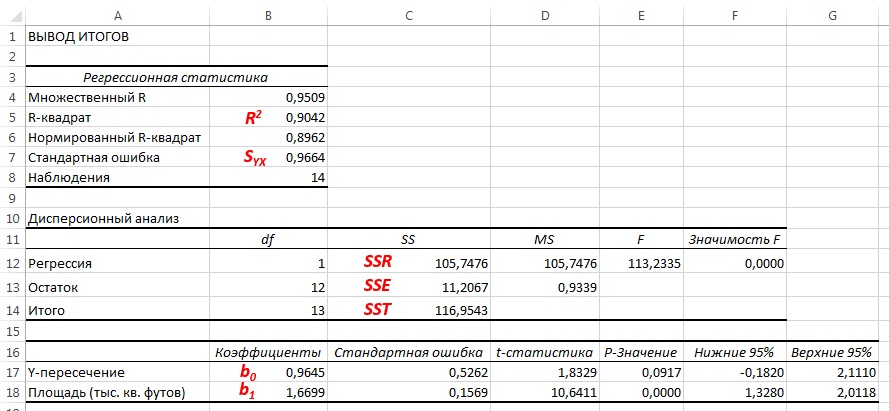
Рис. 4. Результаты решения задачи о зависимости между площадями и годовыми объемами продаж в магазинах сети Sunflower (получены с помощью Пакета анализа Excel)
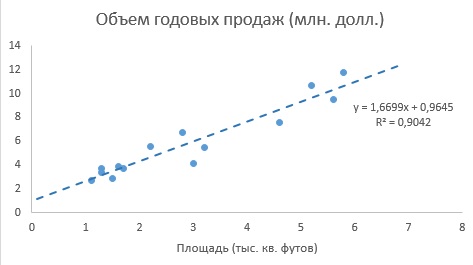
Рис. 5. Диаграмма разброса и линия регрессии (тренда) в задаче о выборе магазина
Как следует из рис. 4 и 5, b0 = 0,9645, а b1 = 1,6699. Таким образом, уравнение линейной регрессии для этих данных имеет следующий вид: = 0,9645 + 1,6699Xi. Вычисленный наклон b1 = +1,6699. Это означает, что при возрастании переменной X на единицу среднее значение переменной Y возрастает на 1,6699 единиц. Иначе говоря, увеличение площади магазина на один квадратный фут приводит к увеличению годового объема продаж на 1,67 тыс. долл. Таким образом, наклон представляет собой долю годового объема продаж, зависящую от размера магазина. Вычисленный сдвиг b0 = +0,9645 (млн. долл.). Эта величина представляет собой среднее значение переменной Y при X = 0. Поскольку площадь магазина не может равняться нулю, сдвиг можно считать долей годового дохода, зависящей от других факторов. Следует отметить, однако, что сдвиг переменной Y выходит за пределы диапазона переменной X. Следовательно, к интерпретации параметра b0 необходимо относиться внимательно.
Пример 1. Один экономист решил предсказать изменение индекса 500 наиболее активно покупаемых акций на Нью-Йоркской фондовой бирже, публикуемого агентством Standard and Poor, на основе показателей экономики США за 50 лет. В результате он получил следующее уравнение линейной регрессии: Ŷi = –5,0 + 7Хi. Какой смысл имеют параметры сдвига b0 и наклона b1.
Решение. Сдвиг регрессии b0 равен –5,0. Это значит, что если рост экономики США равен нулю, индекс акций за год снизится на 5%. Наклон b1 равен 7. Следовательно, при увеличении темпов роста экономики на 1% индекс акций возрастает на 7%.
Пример 2. Вернемся к сценарию, изложенному в начале заметки. Применим модель линейной регрессии для прогноза объема годовых продаж во всех новых магазинах в зависимости от их размеров. Предположим, что площадь магазина равна 4000 квадратных футов. Какой среднегодовой объем продаж можно прогнозировать?
Решение. Подставим значение X = 4 (тыс. кв. футов) в уравнение линейной регрессии: = 0,9645 + 1,6699Xi = 0,9645 + 1,6699*4 = 7,644 млн. долл. Итак, прогнозируемый среднегодовой объем продаж в магазине, площадь которого равна 4000 кв. футов, составляет 7 644 000 долл.
Прогнозирование в регрессионном анализе: интерполяция и экстраполяция
Применяя регрессионную модель для прогнозирования, необходимо учитывать лишь допустимые значения независимой переменной. В этот диапазон входят все значения переменной X, начиная с минимальной и заканчивая максимальной. Таким образом, предсказывая значение переменной Y при конкретном значении переменной X, исследователь выполняет интерполяцию между значениями переменной X в диапазоне возможных значений. Однако экстраполяция значений за пределы этого интервала не всегда релевантна. Например, пытаясь предсказать среднегодовой объем продаж в магазине, зная его площадь (рис. 3а), мы можем вычислять значение переменной Y лишь для значений X от 1,1 до 5,8 тыс. кв. футов. Следовательно, прогнозировать среднегодовой объем продаж можно лишь для магазинов, площадь которых не выходит за пределы указанного диапазона. Любая попытка экстраполяции означает, что мы предполагаем, будто линейная регрессия сохраняет свой характер за пределами допустимого диапазона.
Оценки изменчивости
Вычисление сумм квадратов. Для того чтобы предсказать значение зависимой переменной по значениям независимой переменной в рамках избранной статистической модели, необходимо оценить изменчивость. Существует несколько способов оценки изменчивости. Первый способ использует общую сумму квадратов (total sum of squares — SST), позволяющую оценить колебания значений Yi вокруг среднего значения  . В регрессионном анализе полная вариация, представляющая собой полную сумму квадратов, разделяется на объяснимую вариацию, или сумму квадратов регрессии (regression sum of squares — SSR), и необъяснимую вариацию, или сумму квадратов ошибок (error sum of squares — SSE). Объяснимая вариация характеризует взаимосвязь между переменными X и Y, а необъяснимая зависит от других факторов (рис. 6).
. В регрессионном анализе полная вариация, представляющая собой полную сумму квадратов, разделяется на объяснимую вариацию, или сумму квадратов регрессии (regression sum of squares — SSR), и необъяснимую вариацию, или сумму квадратов ошибок (error sum of squares — SSE). Объяснимая вариация характеризует взаимосвязь между переменными X и Y, а необъяснимая зависит от других факторов (рис. 6).

Рис. 6. Оценки изменчивости в модели регрессии
Сумма квадратов регрессии (SSR) представляет собой сумму квадратов разностей между Ŷi (предсказанным значением переменной Y) и (средним значением переменной Y). Сумма квадратов ошибок (SSE) является частью вариации переменной Y, которую невозможно описать с помощью регрессионной модели. Эта величина зависит от разностей между наблюдаемыми и предсказанными значениями.
Полная сумма квадратов (SST) равна сумме квадратов регрессии плюс сумма квадратов ошибок:
(3) SST = SSR + SSE
Полная сумма квадратов (SST) равна сумме квадратов разностей между наблюдаемыми значениями переменной Y и ее средним значением:

Сумма квадратов регрессии (SSR) равна сумме квадратов разностей между предсказанными значениями переменной Y и ее средним значением:

Сумма квадратов ошибок (SSE) равна сумме квадратов разностей между наблюдаемыми и предсказанными значениями переменной Y:

Суммы квадратов, вычисленные с помощью программы Пакета анализа Excel при решении задачи о сети магазинов Sunflowers, представлены на рис. 4.
Полная сумма квадратов разностей равна SST = 116,9543. Эта величина состоит из суммы квадратов регрессии (SSR) равной 105,7476, и суммы квадратов ошибок (SSE), равной 11,2067.
Коэффициент смешанной корреляции. Величины SSR, SSE и SST не имеют очевидной интерпретации. Однако отношение суммы квадратов регрессии (SSR) к полной сумме квадратов (SST) представляет собой оценку полезности регрессионного уравнения. Это отношение называется коэффициентом смешанной корреляции r 2 :

Коэффициент смешанной корреляции оценивает долю вариации переменной Y, которая объясняется независимой переменной X в регрессионной модели. В задаче о сети магазинов Sunflowers SSR = 105,7476 и SST = 116,9543. Следовательно, r 2 = 105,7476 / 116,9543 = 0,904. Таким образом, 90,4% вариации годового объема продаж объясняется изменчивостью площади магазинов, измеренной в квадратных футах. Данная величина r 2 свидетельствует о сильной положительной линейной взаимосвязи между двумя переменными, поскольку применение регрессионной модели снижает изменчивость прогнозируемых годовых объемов продаж на 90,4%. Только 9,6% изменчивости годовых объемов продаж в выборке магазинов объясняются другими факторами, не учтенными в регрессионной модели.
Коэффициент смешанной корреляции в задаче о сети магазинов Sunflowers представлен в таблице Регрессионная статистика на рис. 4.
Среднеквадратичная ошибка оценки. Хотя метод наименьших квадратов позволяет вычислить линию, минимизирующую отклонение от наблюдаемых значений, наличие суммы квадратов ошибок (SSE) свидетельствует о том, что линейная регрессия не дает абсолютной точности прогноза, если, конечно, точки наблюдения не лежат на регрессионной прямой. Однако ожидать этого так же неестественно, как предполагать, что все выборочные значения точно равны их среднему арифметическому. Следовательно, необходима статистика, которая позволила бы оценить отклонение предсказанных значений переменной Y от ее реальных значений, аналогично тому, как стандартное отклонение, введенное ранее, позволяет оценить колебание данных вокруг их средней величины. Стандартное отклонение наблюдаемых значений переменной Y от ее регрессионной прямой называется среднеквадратичной ошибкой оценки. Отклонение реальных данных от регрессионной прямой в задаче о сети магазинов Sunflowers показано на рис. 5.
Среднеквадратичная ошибка оценки

где Yi — фактическое значение переменной Y при заданном значении Xi, Ŷi — предсказанное значение переменной Y при заданном значении Xi, SSE — сумма квадратов ошибок.
Поскольку SSE = 11,2067, по формуле (8) получаем:

Таким образом, среднеквадратичная ошибка оценки равна 0,9664 млн. долл. (т.е. 966 400 долл.). Этот параметр также рассчитывается Пакетом анализа (см. рис. 4). Среднеквадратичная ошибка оценки характеризует отклонение реальных данных от линии регрессии. Она измеряется в тех же единицах, что и переменная Y. По смыслу среднеквадратичная ошибка очень похожа на стандартное отклонение. В то время как стандартное отклонение характеризует разброс данных вокруг их среднего значения, среднеквадратичная ошибка позволяет оценить колебание точек наблюдения вокруг регрессионной прямой. Cреднеквадратичная ошибка оценки позволяет обнаружить статистически значимую зависимость, существующую между двумя переменными, и предсказать значения переменной Y.
Предположения
Обсуждая методы проверки гипотез и дисперсионного анализа, мы не раз подчеркивали важность условий, которые должны обеспечивать корректность сделанных выводов. Поскольку и регрессионный, и дисперсионный анализ используют линейную модель, условия их применения приблизительно одинаковы:
- Ошибка должна иметь нормальное распределение.
- Вариация данных вокруг линии регрессии должна быть постоянной.
- Ошибки должны быть независимыми.
Первое предположение, о нормальном распределении ошибок, требует, чтобы при каждом значении переменной X ошибки линейной регрессии имели нормальное распределение (рис. 7). Как и t— и F-критерий дисперсионного анализа, регрессионный анализ довольно устойчив к нарушениям этого условия. Если распределение ошибок относительно линии регрессии при каждом значении X не слишком сильно отличается от нормального, выводы относительно линии регрессии и коэффициентов регрессии изменяются незначительно.

Рис. 7. Предположение о нормальном распределении ошибок
Второе условие заключается в том, что вариация данных вокруг линии регрессии должна быть постоянной при любом значении переменной X. Это означает, что величина ошибки как при малых, так и при больших значениях переменной X должна изменяться в одном и том же интервале (см. рис. 7). Это свойство очень важно для метода наименьших квадратов, с помощью которого определяются коэффициенты регрессии. Если это условие нарушается, следует применять либо преобразование данных, либо метод наименьших квадратов с весами.
Третье предположение, о независимости ошибок, заключается в том, что ошибки регрессии не должны зависеть от значения переменной X. Это условие особенно важно, если данные собираются на протяжении определенного отрезка времени. В этих ситуациях ошибки, присущие конкретному отрезку времени, часто коррелируют с ошибками, характерными для предыдущего периода.
Анализ остатков
Чуть выше при решении задачи о сети магазинов Sunflowers мы использовали модель линейной регрессии. Рассмотрим теперь анализ ошибок — графический метод, позволяющий оценить точность регрессионной модели. Кроме того, с его помощью можно обнаружить потенциальные нарушения условий применения регрессионного анализа.
Оценка пригодности эмпирической модели. Остаток, или оценка ошибки еi, представляет собой разность между наблюдаемым (Yi) и предсказанным (Ŷi) значениями зависимой переменной при заданном значении Xi.
Для оценки пригодности эмпирической модели регрессии остатки откладываются по вертикальной оси, а значения Xi — по горизонтальной. Если эмпирическая модель пригодна, график не должен иметь ярко выраженной закономерности. Если же модель регрессии не пригодна, на рисунке проявится зависимость между значениями Xi и остатками еi.
Рассмотрим примеры (рис. 8). Панель А иллюстрирует возрастание переменной Y при увеличении переменной X. Однако зависимость между этими переменными носит нелинейный характер, поскольку скорость возрастания переменной Y падает при увеличении переменной X. Таким образом, для аппроксимации зависимости между этими переменными лучше подойдет квадратичная модель. Особенно ярко квадратичная зависимость между величинами Xi и ei проявляется на панели Б. Графическое изображение остатков позволяет отфильтровать или удалить линейную зависимость между переменными X и Y и выявить недостаточную точность модели простой линейной регрессии. Таким образом, в данной ситуации вместо простой линейной модели должна применяться квадратичная модель, обладающая более высокой точностью.

Рис. 8. Исследование эмпирической модели простой линейной регрессии
Вернемся к задаче о сети магазинов Sunflowers и посмотрим, хорошо ли подходит простая линейная регрессия для ее решения. Соответствующие данные и расчеты приведены на рис. 9а (формулы можно посмотреть в Excel-файле). Построим диаграмму разброса, откладывая по вертикальной оси остатки ei, а по горизонтальной — независимую переменную Xi (рис. 9б). Несмотря на большой разброс остатков, между ei и Хi нет ярко выраженной зависимости. Остатки одинаково часто принимают как положительные, так и отрицательные значения. Это позволяет сделать вывод, что модель линейной регрессии пригодна для решения задачи о сети магазинов Sunflowers.
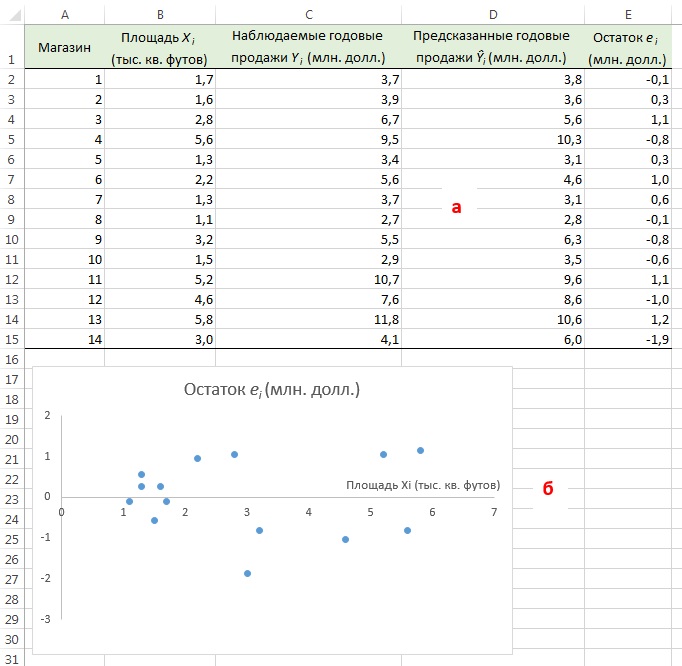
Рис. 9. Остатки ei, вычисленные при решении задачи о сети магазинов Sunflowers
Значения остатков (таблица на рис. 9а) и график остатков (аналог рис. 9б) можно получить непосредственно в процедуре Регрессия Пакета анализа. Просто поставьте соответствующие галки (рис. 10).

Рис. 10. Остатки ei и график остатков полученные с помощью Пакета анализа
Проверка условий. График остатков позволяет оценить вариации ошибок. На рис. 10 нет особых различий между ошибками, соответствующими разным значениям Xi. Следовательно, вариации ошибок при разных значениях Хi приблизительно одинаковы. Рассмотрим гипотетическую ситуацию, в которой это условие не выполняется (рис. 11). На этом рисунке изображен эффект веера: при возрастании значений Хi ошибки увеличиваются. Таким образом, изменчивость значений Yi при разных значениях Хi является непостоянной.

Рис. 11. Пример нарушения условия независимости вариаций ошибок от Xi
Нормальность. Чтобы проверить предположение о нормальном распределении ошибок, построим график нормального распределения на основе точечного графика, на вертикальной оси которого отложены значения остатков, а на горизонтальной оси — соответствующие квантили стандартизованного нормального распределения (подробнее см. Проверка гипотезы о нормальном распределении). Для построения такого графика значения остатков должны быть упорядочены по возрастанию (рис. 12). График нормального распределения может быть построен одним кликом с помощью Пакета анализа Excel – просто поставьте соответствующую галочку в окне Регрессия (см. рис. 10, самый низ окна Регрессия – опция График нормальной вероятности).

Рис. 12. График нормального распределения для остатков
Без визуализации данных (с помощью гистограммы, диаграммы «ствол и листья», блочной диаграммы или графика как на рис. 12) проверить предположение о нормальном распределении ошибок очень трудно. Данные, изображенные на рис. 12, не слишком сильно отличаются от нормального распределения. Устойчивость регрессионного анализа и небольшой объем выборки позволяют утверждать, что условие о нормальном распределении ошибок нарушается незначительно.
Независимость. Предположение о независимости ошибок также проверяется с помощью графика остатков. Данные, собранные на протяжении некоторого периода времени, иногда демонстрируют эффект автокорреляции между последовательными наблюдениями. В таких ситуациях остатки зависят от значений предыдущих остатков. Подобная связь между остатками нарушает предположение о независимости ошибок. Эффект автокорреляции хорошо выявляется на графике. Кроме того, его можно измерить с помощью процедуры Дурбина-Уотсона (см. ниже). Если данные о размерах магазинов и объемах продаж собирались в течение одного и того же периода времени, гипотезу об их независимости проверять не имеет смысла.
Измерение автокорреляции: статистика Дурбина–Уотсона
Одним из основных предположений о регрессионной модели является гипотеза о независимости ее ошибок. Если данные собираются в течение определенного отрезка времени, это условие часто нарушается, поскольку остаток в определенный момент времени может оказаться приблизительно равным предыдущим остаткам. Такое поведение остатков называется автокорреляцией. Если набор данных обладает свойством автокорреляции, корректность регрессионной модели становится весьма сомнительной.
Распознавание автокорреляции с помощью графика остатков. Для выявления автокорреляции необходимо упорядочить остатки по времени и построить их график. Если данные обладают положительной автокорреляцией, на графике возникнут кластеры остатков, имеющие одинаковый знак. В случае отрицательной автокорреляции остатки будут скачкообразно принимать то положительные, то отрицательные значения. Этот вид автокорреляции очень редко встречается в регрессионном анализе, поэтому мы рассмотрим лишь положительную автокорреляцию. Проиллюстрируем ее следующим примером. Предположим, что менеджер магазина, доставляющего товары на дом, пытается предсказать объем продаж по количеству клиентов, совершивших покупки в течение 15 недель (рис. 13).

Рис. 13. Количество клиентов и объемы продаж за 15 недель
Поскольку данные собирались на протяжении 15 последовательных недель в одном и том же магазине, необходимо определить, наблюдается ли эффект автокорреляции. Построим регрессию с использованием Пакета анализа; включим вывод Остатков, но не будем включать График остатков (рис. 14).
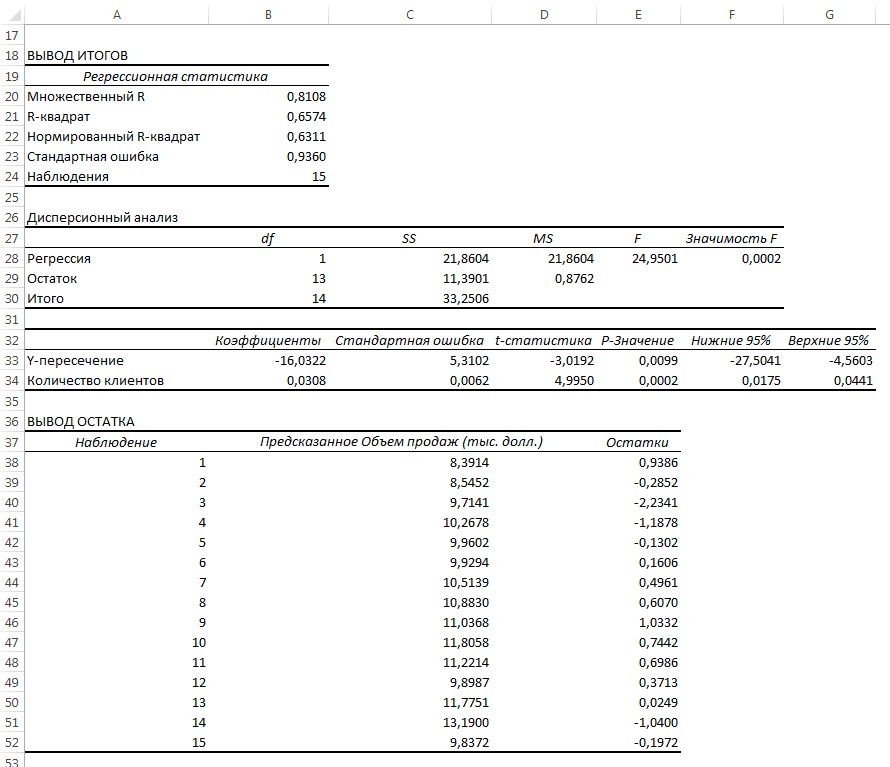
Рис. 14. Параметры линейной регрессии, полученные с использованием Пакета анализа
Анализ рис. 14 показывает, что r 2 = 0,657. Это значит, что 65,7% вариации объемов продаж объясняется изменчивостью количества клиентов. Кроме того, сдвиг b0 переменной Y равен –16,032, а наклон b1 = 0,0308. Однако, прежде чем применять эту модель, необходимо выполнить анализ остатков. Поскольку данные собирались на протяжении 15 последовательных недель, их следует отобразить на графике в том же порядке (рис. 15).

Рис. 15. Зависимость остатков от времени
Анализ рис. 15 показывает, что остатки циклически колеблются вверх и вниз. Эта цикличность является явным признаком автокорреляции. Следовательно, гипотезу о независимости остатков следует отклонить.
Статистика Дурбина-Уотсона. Автокорреляцию можно выявить и измерить с помощью статистики Дурбина-Уотсона. Эта статистика оценивает корреляцию между соседними остатками:

где еi — остаток, соответствующий i-му периоду времени.
Чтобы лучше понять статистику Дурбина-Уотсона, рассмотрим ее составные части. Числитель представляет собой сумму квадратов разностей между соседними остатками, начиная со второго и заканчивая n-м наблюдением. Знаменатель является суммой квадратов остатков. Вот, что по этому поводу написано в Википедии:

где ρ1 – коэффициент автокорреляции; если ρ1 = 0 (нет автокорреляции), D ≈ 2; если ρ1 ≈ 1 (положительная автокорреляции), D ≈ 0; если ρ1 = -1 (отрицательная автокорреляции), D ≈ 4.
На практике применение критерия Дурбина-Уотсона основано на сравнении величины D с критическими теоретическими значениями dL и dU для заданного числа наблюдений n, числа независимых переменных модели k (для простой линейной регрессии k = 1) и уровня значимости α. Если D dU, гипотеза не отвергается (то есть автокорреляция отсутствует); если dL tU = 2,1788 (рис. 19), нулевая гипотеза Н0 отклоняется. С другой стороны, р-значение для Х = 10,6411, вычисляемое по формуле =1-СТЬЮДЕНТ.РАСП(D3;12;ИСТИНА), приближенно равно нулю, поэтому гипотеза Н0 снова отклоняется. Тот факт, что р-значение почти равно нулю, означает, что если бы между размерами магазинов и годовым объемом продаж не существовало реальной линейной зависимости, обнаружить ее с помощью линейной регрессии было бы практически невозможно. Следовательно, между средним годовым объемом продаж в магазинах и их размером существует статистически значимая линейная зависимость.

Рис. 19. Проверка гипотезы о наклоне генеральной совокупности при уровне значимости, равном 0,05, и 12 степенях свободы
Применение F-критерия для наклона. Альтернативным подходом к проверке гипотез о наклоне простой линейной регрессии является использование F-критерия. Напомним, что F-критерий применяется для проверки отношения между двумя дисперсиями (подробнее см. Однофакторный дисперсионный анализ). При проверке гипотезы о наклоне мерой случайных ошибок является дисперсия ошибки (сумма квадратов ошибок, деленная на количество степеней свободы), поэтому F-критерий использует отношение дисперсии, объясняемой регрессией (т.е. величины SSR, деленной на количество независимых переменных k), к дисперсии ошибок (MSE = SYX 2 ).
По определению F-статистика равна среднему квадрату отклонений, обусловленных регрессией (MSR), деленному на дисперсию ошибки (MSE): F = MSR/MSE, где MSR = SSR / k, MSE = SSE/(n– k – 1), k – количество независимых переменных в регрессионной модели. Тестовая статистика F имеет F-распределение с k и n – k – 1 степенями свободы.
При заданном уровне значимости α решающее правило формулируется так: если F > FU, нулевая гипотеза отклоняется; в противном случае она не отклоняется. Результаты, оформленные в виде сводной таблицы дисперсионного анализа, приведены на рис. 20.

Рис. 20. Таблица дисперсионного анализа для проверки гипотезы о статистической значимости коэффициента регрессии
Аналогично t-критерию F-критерий выводится в таблицу при использовании Пакета анализа (опция Регрессия). Полностью результаты работы Пакета анализа приведены на рис. 4, фрагмент, относящийся к F-статистике – на рис. 21.

Рис. 21. Результаты применения F-критерия, полученные с помощью Пакета анализа Excel
F-статистика равна 113,23, а р-значение близко к нулю (ячейка Значимость F). Если уровень значимости α равен 0,05, определить критическое значение F-распределения с одной и 12 степенями свободы можно по формуле FU =F.ОБР(1-0,05;1;12) = 4,7472 (рис. 22). Поскольку F = 113,23 > FU = 4,7472, причем р-значение близко к 0 0, r = – , если b1 2 = 0,904, а b1— +1,670 (см. рис. 4). Поскольку b1 > 0, коэффициент корреляции между объемом годовых продаж и размером магазина равен r = +√0,904 = +0,951. Проверим нулевую гипотезу, утверждающую, что между этими переменными нет корреляции, используя t-статистику:
, если b1 2 = 0,904, а b1— +1,670 (см. рис. 4). Поскольку b1 > 0, коэффициент корреляции между объемом годовых продаж и размером магазина равен r = +√0,904 = +0,951. Проверим нулевую гипотезу, утверждающую, что между этими переменными нет корреляции, используя t-статистику:

При уровне значимости α = 0,05 нулевую гипотезу следует отклонить, поскольку t = 10,64 > 2,1788. Таким образом, можно утверждать, что между объемом годовых продаж и размером магазина существует статистически значимая связь.
При обсуждении выводов, касающихся наклона генеральной совокупности, доверительные интервалы и критерии для проверки гипотез являются взаимозаменяемыми инструментами. Однако вычисление доверительного интервала, содержащего коэффициент корреляции, оказывается более сложным делом, поскольку вид выборочного распределения статистики r зависит от истинного коэффициента корреляции.
Оценка математического ожидания и предсказание индивидуальных значений
В этом разделе рассматриваются методы оценки математического ожидания отклика Y и предсказания индивидуальных значений Y при заданных значениях переменной X.
Построение доверительного интервала. В примере 2 (см. выше раздел Метод наименьших квадратов) регрессионное уравнение позволило предсказать значение переменной Y при заданном значении переменной X. В задаче о выборе места для торговой точки средний годовой объем продаж в магазине площадью 4000 кв. футов был равен 7,644 млн. долл. Однако эта оценка математического ожидания генеральной совокупности является точечной. Ранее для оценки математического ожидания генеральной совокупности была предложена концепция доверительного интервала. Аналогично можно ввести понятие доверительного интервала для математического ожидания отклика при заданном значении переменной X:

где  , = b0 + b1Xi – предсказанное значение переменное Y при X = Xi, SYX – среднеквадратичная ошибка, n – объем выборки, Xi — заданное значение переменной X, µY|X=Xi – математическое ожидание переменной Y при Х = Хi, SSX =
, = b0 + b1Xi – предсказанное значение переменное Y при X = Xi, SYX – среднеквадратичная ошибка, n – объем выборки, Xi — заданное значение переменной X, µY|X=Xi – математическое ожидание переменной Y при Х = Хi, SSX = 
Анализ формулы (13) показывает, что ширина доверительного интервала зависит от нескольких факторов. При заданном уровне значимости возрастание амплитуды колебаний вокруг линии регрессии, измеренное с помощью среднеквадратичной ошибки, приводит к увеличению ширины интервала. С другой стороны, как и следовало ожидать, увеличение объема выборки сопровождается сужением интервала. Кроме того, ширина интервала изменяется в зависимости от значений Xi. Если значение переменной Y предсказывается для величин X, близких к среднему значению  , доверительный интервал оказывается уже, чем при прогнозировании отклика для значений, далеких от среднего.
, доверительный интервал оказывается уже, чем при прогнозировании отклика для значений, далеких от среднего.
Допустим, что, выбирая место для магазина, мы хотим построить 95%-ный доверительный интервал для среднего годового объема продаж во всех магазинах, площадь которых равна 4000 кв. футов:

Следовательно, средний годовой объем продаж во всех магазинах, площадь которых равна 4 000 кв. футов, с 95% -ной вероятностью лежит в интервале от 6,971 до 8,317 млн. долл.
Вычисление доверительного интервала для предсказанного значения. Кроме доверительного интервала для математического ожидания отклика при заданном значении переменной X, часто необходимо знать доверительный интервал для предсказанного значения. Несмотря на то что формула для вычисления такого доверительного интервала очень похожа на формулу (13), этот интервал содержит предсказанное значение, а не оценку параметра. Интервал для предсказанного отклика YX=Xi при конкретном значении переменной Xi определяется по формуле:

Предположим, что, выбирая место для торговой точки, мы хотим построить 95%-ный доверительный интервал для предсказанного годового объема продаж в магазине, площадь которого равна 4000 кв. футов:

Следовательно, предсказанный годовой объем продаж в магазине, площадь которого равна 4000 кв. футов, с 95%-ной вероятностью лежит в интервале от 5,433 до 9,854 млн. долл. Как видим, доверительный интервал для предсказанного значения отклика намного шире, чем доверительный интервал для его математического ожидания. Это объясняется тем, что изменчивость при прогнозировании индивидуальных значений намного больше, чем при оценке математического ожидания.
Подводные камни и этические проблемы, связанные с применением регрессии
Трудности, связанные с регрессионным анализом:
- Игнорирование условий применимости метода наименьших квадратов.
- Ошибочная оценка условий применимости метода наименьших квадратов.
- Неправильный выбор альтернативных методов при нарушении условий применимости метода наименьших квадратов.
- Применение регрессионного анализа без глубоких знаний о предмете исследования.
- Экстраполяция регрессии за пределы диапазона изменения объясняющей переменной.
- Путаница между статистической и причинно-следственной зависимостями.
Широкое распространение электронных таблиц и программного обеспечения для статистических расчетов ликвидировало вычислительные проблемы, препятствовавшие применению регрессионного анализа. Однако это привело к тому, что регрессионный анализ стали применять пользователи, не обладающие достаточной квалификацией и знаниями. Откуда пользователям знать об альтернативных методах, если многие из них вообще не имеют ни малейшего понятия об условиях применимости метода наименьших квадратов и не умеют проверять их выполнение?
Исследователь не должен увлекаться перемалыванием чисел — вычислением сдвига, наклона и коэффициента смешанной корреляции. Ему нужны более глубокие знания. Проиллюстрируем это классическим примером, взятым из учебников. Анскомб показал, что все четыре набора данных, приведенных на рис. 23, имеют одни и те же параметры регрессии (рис. 24).

Рис. 23. Четыре набора искусственных данных

Рис. 24. Регрессионный анализ четырех искусственных наборов данных; выполнен с помощью Пакета анализа (кликните на рисунке, чтобы увеличить изображение)
Итак, с точки зрения регрессионного анализа все эти наборы данных совершенно идентичны. Если бы анализ был на этом закончен, мы потеряли бы много полезной информации. Об этом свидетельствуют диаграммы разброса (рис. 25) и графики остатков (рис. 26), построенные для этих наборов данных.

Рис. 25. Диаграммы разброса для четырех наборов данных
Диаграммы разброса и графики остатков свидетельствуют о том, что эти данные отличаются друг от друга. Единственный набор, распределенный вдоль прямой линии, — набор А. График остатков, вычисленных по набору А, не имеет никакой закономерности. Этого нельзя сказать о наборах Б, В и Г. График разброса, построенный по набору Б, демонстрирует ярко выраженную квадратичную модель. Этот вывод подтверждается графиком остатков, имеющим параболическую форму. Диаграмма разброса и график остатков показывают, что набор данных В содержит выброс. В этой ситуации необходимо исключить выброс из набора данных и повторить анализ. Метод, позволяющий обнаруживать и исключать выбросы из наблюдений, называется анализом влияния. После исключения выброса результат повторной оценки модели может оказаться совершенно иным. Диаграмма разброса, построенная по данным из набора Г, иллюстрирует необычную ситуацию, в которой эмпирическая модель значительно зависит от отдельного отклика (Х8 = 19, Y8 = 12,5). Такие регрессионные модели необходимо вычислять особенно тщательно. Итак, графики разброса и остатков являются крайне необходимым инструментом регрессионного анализа и должны быть его неотъемлемой частью. Без них регрессионный анализ не заслуживает доверия.
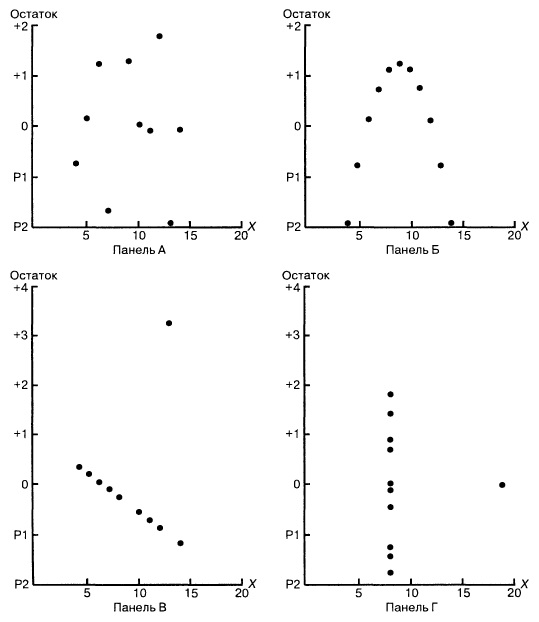
Рис. 26. Графики остатков для четырех наборов данных
Как избежать подводных камней при регрессионном анализе:
- Анализ возможной взаимосвязи между переменными X и Y всегда начинайте с построения диаграммы разброса.
- Прежде чем интерпретировать результаты регрессионного анализа, проверяйте условия его применимости.
- Постройте график зависимости остатков от независимой переменной. Это позволит определить, насколько эмпирическая модель соответствует результатам наблюдения, и обнаружить нарушение постоянства дисперсии.
- Для проверки предположения о нормальном распределении ошибок используйте гистограммы, диаграммы «ствол и листья», блочные диаграммы и графики нормального распределения.
- Если условия применимости метода наименьших квадратов не выполняются, используйте альтернативные методы (например, модели квадратичной или множественной регрессии).
- Если условия применимости метода наименьших квадратов выполняются, необходимо проверить гипотезу о статистической значимости коэффициентов регрессии и построить доверительные интервалы, содержащие математическое ожидание и предсказанное значение отклика.
- Избегайте предсказывать значения зависимой переменной за пределами диапазона изменения независимой переменной.
- Имейте в виду, что статистические зависимости не всегда являются причинно-следственными. Помните, что корреляция между переменными не означает наличия причинно-следственной зависимости между ними.
Резюме. Как показано на структурной схеме (рис. 27), в заметке описаны модель простой линейной регрессии, условия ее применимости и способы проверки этих условий. Рассмотрен t-критерий для проверки статистической значимости наклона регрессии. Для предсказания значений зависимой переменной использована регрессионная модель. Рассмотрен пример, связанный с выбором места для торговой точки, в котором исследуется зависимость годового объема продаж от площади магазина. Полученная информация позволяет точнее выбрать место для магазина и предсказать его годовой объем продаж. В следующих заметках будет продолжено обсуждение регрессионного анализа, а также рассмотрены модели множественной регрессии.
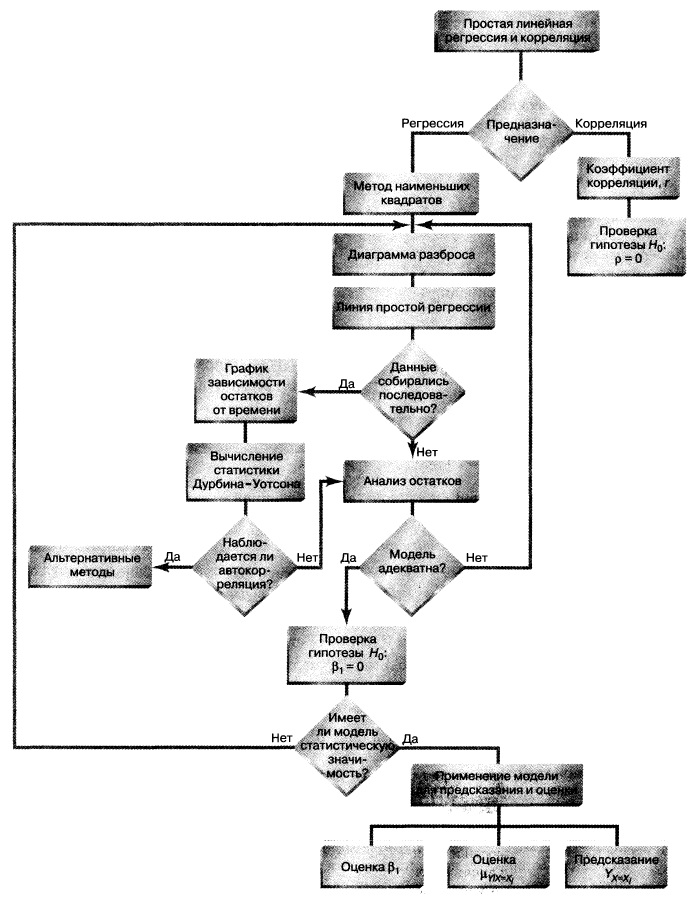
Рис. 27. Структурная схема заметки
[1] Используются материалы книги Левин и др. Статистика для менеджеров. – М.: Вильямс, 2004. – с. 792–872
[2] Если зависимая переменная является категорийной, необходимо применять логистическую регрессию.
Прогнозирование. Регрессионный анализ, его реализация и прогнозирование
МЕТОДИЧЕСКИЕ РЕКОМЕНДАЦИИ
Сущность метода регрессионного анализа
Одним из методов, используемых для прогнозирования, является регрессионный анализ.
Регрессия – это статистический метод, который позволяет найти уравнение, наилучшим образом описывающее совокупность данных, заданных таблицей.
| X | X1 | X2 | … | Xi | … | Xn |
|---|---|---|---|---|---|---|
| Y | Y1 | Y2 | … | Yi | … | Yn |

На графике данные отображаются точками. Регрессия позволяет подобрать к этим точкам кривую у=f(x), которая вычисляется по методу наименьших квадратов и даёт максимальное приближение к табличным данным.
По полученному уравнению можно вычислить (сделать прогноз) значение функции у для любого значения х , как внутри интервала изменения х из таблицы(интерполяция), так и вне его (экстраполяция).
Линейная регрессия
Линейная регрессия дает возможность наилучшим образом провести прямую линию через точки одномерного массива данных (рис.13.1 а). Уравнение с одной независимой переменной, описывающее прямую линию, имеет вид:
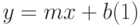
где:x – независимая переменная;
y – зависимая переменная;
m – характеристика наклона прямой;
b – точка пересечения прямой с осью у.
Например, имея данные о реализации товаров за год с помощью линейной регрессии можно получить коэффициенты прямой (1) и, предполагая дальнейший линейный рост, получить прогноз реализации на следующий год.
Нелинейная регрессия
Нелинейная регрессия позволяет подбирать к табличным данным нелинейное уравнение (рис. 13.1 рис. 13.1, б.) – параболу, гиперболу и др. Excel реализует нелинейность в виде экспоненты, т.е. подбирает кривую вида:
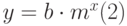 ,
,
которая позволяет наилучшим образом провести экспоненциальную кривую по точкам данных, которые изменяются нелинейно.
Так, например, данные о росте населения почти всегда лучше описываются не прямой линией, а экспоненциальной кривой. При этом нужно помнить, что достоверное прогнозирование возможно только на участках подъёма или спуска кривой (при отрицательных значениях х), т.к. сама кривая (2) изменяется монотонно, без точек перегиба. Например, делать экспоненциальный прогноз для функции, изменяющейся синусоидально, можно только на участках подъёма или спуска функции, для чего её разбивают на соответствующие интервалы.
Множественная регрессия
Множественная регрессия представляет собой анализ более одного набора данных аргумента х и даёт более реалистичные результаты.
Множественный регрессионный анализ также может быть как линейным, так и экспоненциальным. Уравнение регрессии (1) и (2) примут соответственно вид (3) и (4):
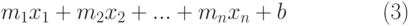 | ( 3) |
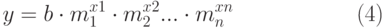 | ( 4) |
С помощью множественной регрессии, например, можно оценить стоимость дома в некотором районе, основываясь на данных его площади, размерах участка земли, этажности, вида из окон и т.д.
Использование функций регрессии
В Excel имеется 5 функций для линейной регрессии: ЛИНЕЙН(…)(LINEST), ТЕНДЕНЦИЯ(…), ПРЕДСКАЗ(…), НАКЛОН(…), СТОШУХ(…)) и 2 функции для экспоненциальной регрессии – ЛГРФПРИБЛ(…) и РОСТ(…).
Рассмотрим некоторые из них.
Функция ЛИНЕЙН((LINEST) вычисляет коэффициент m и постоянную b для уравнения прямой (1). Синтаксис функции:
Известные_значения_у и известные_значения_х – это множество значений у и необязательное множество значений х (их вводить необязательно), которые уже известны для соотношения (1).
Константа – это логическое значение, которое указывает, требуется ли, чтобы константа b была равна 0. Если константа имеет значение ИСТИНА или опущено, то b вычисляется обычным образом.
Статистика – это логическое значение, которое указывает требуется ли вывести дополнительную статистику по регрессии.
Если статистика имеет значение ЛОЖЬ (или 0), то функция ЛИНЕЙН возвращает только значения коэффициентов m и b , в противном случае выводится дополнительная регрессионная статистика в виде табл. 13.1 таблица 13.1:
| mn | mn-1 | … | m2 | m1 | b |
|---|---|---|---|---|---|
| sen | sen-1 | … | se2 | se1 | seb |
| r 2 | sey | … | #Н/Д | #Н/Д | #Н/Д |
| F | df | … | #Н/Д | #Н/Д | #Н/Д |
| ssreg | ssresid | … | #Н/Д | #Н/Д | #Н/Д |
где: se1 , se2,…,sen – стандартные значения ошибок для коэффициентов m1 , m2,…, mn ;
seb – стандартное значение ошибки для постоянной b (seb равно #Н/Д, т.е. «нет допустимого значения», если конст. имеет значение ЛОЖЬ);
r 2 – коэффициент детерминированности. Сравниваются фактические значения у и значения, получаемые из уравнения прямой; по результатам сравнения вычисляется коэффициент детерминированности, нормированный от 0 до 1. Если он равен 1, то имеет место полная корреляция с моделью, т.е. нет различия между фактическим и оценочным значениями у. В противоположном случае, если коэффициент детерминированности равен 0, то уравнение регрессии неудачно для предсказания значений у;
sey – стандартная ошибка для оценки у (предельное отклонение для у);
F – F-cтатистика, или F-наблюдаемое значение. Она используется для определения того, является ли наблюдаемая взаимосвязь между зависимой и независимой переменными случайной или нет;
df – степени свободы. Степени свободы полезны для нахождения F-критических значений в статистической таблице. Для определения уровня надёжности модели нужно сравнить значения в таблице с F-статистикой, возвращаемой функцией ЛИНЕЙН;
ssreg – регрессионная сумма квадратов;
ssresid – остаточная сумма квадратов;
#Н/Д – ошибка, означающая «нет доступного значения».
Любую прямую можно задать её наклоном m и у-пересечением:
Наклон ( m ). Для того, чтобы определить наклон прямой, обычно обозначаемый через m , нужно взять 2 точки прямой (х1,у1) и (х2,у2); тогда наклон равен m=(y2-y1)/(x2-x1 ).
у-пересечение ( b ) прямой, обычно обозначаемое через b , является значение у для точки, в которой прямая пересекает ось у.
Уравнение прямой имеет вид: у=mx+b. Если известны значения m и b , то можно вычислить любую точку на прямой, подставляя значения у или х в уравнение. Можно также использовать функцию ТЕНДЕНЦИЯ ( TREND ) (см. ниже).
Если для функции у имеется только одна независимая переменная х, можно получить наклон и у-пересечение непосредственно, используя следующие формулы:
Точность аппроксимации с помощью прямой, вычисленной функцией ЛИНЕЙН, зависит от степени разброса данных. Чем ближе данные к прямой, тем более точными являются модель, используемая функцией ЛИНЕЙН, и значения, получаемые из уравнения прямой.
В случае экспоненциальной регрессии аналогом функции (5) является функция ЛГРФПРИБЛ(LOGEST):
которая отличается лишь тем, что вычисляет коэффициенты m и b для экспоненциальной кривой (2).
Функция ТЕНДЕНЦИЯ(TREND) имеет вид:
возвращает числовые значения, лежащие на прямой линии, наилучшим образом аппроксимирующие известные табличные данные.
Новые_значения_х – это те, для которых необходимо вычислить соответствующие значения у.
Если параметр новые_значения_х пропущен, то считается, что он совпадает с известными х. Назначение остальных параметров функции ТЕНДЕНЦИЯ совпадает с описанными выше.
В случае экспоненциальной регрессии аналогом функции (7) является функция РОСТ(GROWTH):
возвращает стандартную погрешность регрессии – меру погрешности предсказываемого значения у для заданного значения х.
Правила ввода функций
Формулы(5)-(8) являются табличными, т.е. они заменяют собой несколько обычных формул и возвращают не один результат, а массив результатов. Поэтому необходимо соблюдать следующие правила:
- Перед вводом одной из формул (5)-(8) выведите блок ячеек, точно совпадающей по размеру с величиной возвращаемого формулой массива результатов. Например, при использовании функции ЛИНЕЙН с выводом статистики нужно выделить массив ячеек, равный табл. 13.1, если параметр статистики равен ЛОЖЬ, достаточно выделить одну строку табл. 13.1.
- Наберите функцию в строке формул. При этом слова на русском языке можно набирать строчными буквами, т.к. они являются ключевыми и при вводе Exсel автоматически переведет их в заглавные. Имена ячеек автоматически вводятся латинским шрифтом. Вместо слова ИСТИНА можно вводить числа от 1 до 9 (не 0), а вместо слова ЛОЖЬ – число 0. Если в результате, выполнения функции выводится одно число, можно вводить формулы не вручную, а использовать аппарат Мастера функций.
- Одновременно нажмите клавиши Shift+Ctrl+Enter . Результаты вычислений заполнят выделенные ячейки.
Линия тренда
Excel позволяет наглядно отображать тенденцию данных с помощью линии тренда, которая представляет собой интерполяционную кривую, описывающую отложенные на диаграмме данные.
Для того, чтобы дополнить диаграмму исходных данных линией тренда, необходимо выполнить следующие действия:
- выделить на диаграмме ряд данных, для которого требуется построить линию тренда;
- щелкнуть правой кнопкой мыши и выбрать команду Добавить линию тренда;
- в открывшемся окне задать метод интерполяции (линейный, полиномиальный, логарифмический и т. д.), а также через команду Параметры – другие параметры (например, вывод уравнения кривой тренда, коэффициента детерминированности r 2 , направление и количество периодов для экстраполяции (прогноза) и др.);
- нажать кнопку Закрыть.
Чтобы отобразить на графике (гистограмме и др.) новые, прогнозируемые в результате регрессионного анализа данные, нужно:
- определить их с помощью функции ТЕНДЕНЦИЯ, РОСТ или другим способом,
- выделить на диаграмме нужную кривую, щелкнув по ней правой кнопкой мыши,
- в появившемся окне выбрать команду Выбрать данные…, в появившемся окне выбрать диапазон ячеек с новыми данными вручную или протащив по ним курсор при нажатой левой клавише мыши, нажать ОК.
На диаграмме появится продолжение кривой, построенной по новым данным.
Простая линейная регрессия
Пример 1. Функция ТЕНДЕНЦИЯ(TREND)
а) Предположим, что фирма может приобрести земельный участок в июле. Фирма собирает информацию о ценах за последние 12 месяцев, начиная с марта, на типичный земельный участок. Название первого столбца «Месяц» с данными о номерах месяцев записано в ячейке А1, а второго столбца «Цена» – в ячейке В1. Номера месяцев с 1 по 12 (известные значения х) записаны в ячейки А2…А13. Известные значения у содержат множество известных значений (133 890 руб., 135 000 руб., 135 790 руб., 137 300 руб., 138 130 руб., 139 100 руб., 139 900 руб., 141 120 руб., 141 890 руб., 143 230 руб., 144 000 руб., 145 290 руб.), которые находятся в ячейках В2;В13 соответственно (данные условия). Новые значения х, т.е. числа 13, 14,15,16,17 введём в ячейки А14…А18. Для того чтобы определить ожидаемые значения цен на март, апрель, май, июнь, июль, выделим любой интервал ячеек, например, B14:B18 (по одной ячейке для каждого месяца) и в строке формул введем функцию:
После нажатия клавиш Ctrl+ Shift+Enter данная функция будет выделена как формула вертикального массива, а в ячейках B14:B18 появится результат: <146172;174190;148208;149226;150244>.
Таким образом, в июле фирма может ожидать цену около 150 244 руб.
б) Тот же результат будет получен, если вводить в формулу не все массивы переменных х и у, а использовать часть массивов, которые предусматриваются автоматически по умолчанию. Тогда формула (10) примет вид:
В формуле (11) используется массив по умолчанию (1:2:3:4:5:6:7:8:9:10:11:12) для аргумента «известные_значения_х», соответствующий 12 месяцам, для которых имеются данные по продажам. Он должен был бы быть помещен в формуле (11) между двумя знаками ;;. Массив (13:14:15:16:17) соответствует следующим 5 месяцам, для которых и получен массив результатов (146172:147190:148208:149226:150244).
Элементы массивов разделяет знак «:», который указывает на то, что они расположены по столбцам.
в) Аргумент «новые значения х» можно задать другим массивом ячеек, например, В14:В18, в которые предварительно записаны те же номера месяцев 13,14,15,16,17. Тогда вводимая в строку формул функция примет вид =ТЕНДЕНЦИЯ(В2:В13;;В14:В18).
Пример 2. Функция ЛИНЕЙН
а) Дана таблица изменения температуры в течение шести часов, введённая в ячейки D2 :E7 (табл. 13.2 таблица 13.2).
Требуется определить температуру во время восьмого часа.
| … | D | E |
|---|---|---|
| 1 | х-№часа | у-t о , град. |
| 2 | 1 | 2 |
| 3 | 2 | 3 |
| 4 | 3 | 4 |
| 5 | 4 | 7 |
| 6 | 5 | 12 |
| 7 | 6 | 18 |
Выделим ячейки D8:E12 для вывода результата, введем в строку ввода формулу =ЛИНЕЙН(Е2:Е7;D2:D7;1;1), нажмем клавиши Сtrl+Shift+Enter, в выделенных ячейках появится результат:
| 3,142857 | -3,3333333 |
| 0,540848 | 2,106302 |
| 0,894088 | 2,2625312 |
| 33,76744 | 4 |
| 172,8571 | 20,47619 |
Таким образом, коэффициент m=3,143 со стандартной ошибкой 0,541, а свободный член b=-3,333 со стандартной ошибкой 2,106, т.е. функция, описывающая данные табл. 13.2 таблица 13.2, имеет вид
Стандартные ошибки показывают максимально возможное отклонение параметра от рассчитанной величины. Для у оно составляет 2,263, т.е. реальное значение у может лежать в пределах 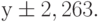 .
.
Точность приближения к табличным данным (коэффициент детерминированности r 2 ) составляет 0,894 или 89,4%, что является высоким показателем. При х=8 получим: у=3,143*8-3,333=21,81 град.
б) Тот же результат можно получить, использовав функцию =ТЕНДЕНЦИЯ(Е2:Е7;;G2:G5) для, например, следующих четырёх часов, предварительно введя в ячейки G2 :G5 числа с 7 до 10. Выделив ячейки Н2:Н5, введя в строку формул эту функцию и нажав Сtrl+Shift+Enter, получим в выделенных ячейках массив <18,667;21,80952;24,95238;28,09524>, т.е. для восьмого часа значение  град.
град.
в) Функция ПРЕДСКАЗ ( FORECAST ) – позволяет предсказать значение у для нового значения х по известным значениям х и у, используя линейное приближение зависимости у=f(x).
Для данных примера 2 ввод формулы =ПРЕДСКАЗ(8;Е2:Е7;D2:D7) выводит в заранее выделенной ячейке результат 21,809. Новое значение х может быть задано не числом, а ячейкой, в которую записано это число.
Отличие функции ПРЕДСКАЗ от функции ТЕНДЕНЦИЯ заключается в том, что ПРЕДСКАЗ прогнозирует значения функции линейного приближения только для одного нового значения х.
Экспоненциальная регрессия
Пример 3
а) Функция ЛГРФПРИБЛ.
Рассмотрим условие примера 2.
Поскольку функция в табл. 13.2 таблица 13.2 носит явно нелинейный характер, целесообразно искать ее приближение в виде не прямой линии, как в примере 2, а в виде нелинейной кривой. Из всех видов нелинейности (гипербола, парабола, и др.) Excel реализует только экспоненциальное приближение вида у=b*mx c помощью функции ЛГРФПРИБЛ, которая рассчитывает для этого уравнения значения b и m .
Выделим для результата блок ячеек F8:G12 , введём в строку формул Функцию =ЛГРФПРИБЛ(Е2:Е7;D2:D7;1;1), нажмем клавиши Сtrl+Shift+Enter, в выделенных ячейках появится результат:
| 1,56628015 | 1,196513 |
| 0,02038299 | 0,07938 |
| 0,99181334 | 0,085268 |
| 484,599687 | 4 |
| 3,52335921 | 0,029083 |
Таким образом, коэффициент m=1,566, а b=1,197, т.е. уравнение приближающей кривой имеет вид:
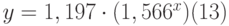
со стандартными ошибками для m, b , и у равными 0,02, 0,079 и 0,085 соответственно. Коэффициент детерминированности r 2 =0,992, т.е. полученное уравнение даёт совпадение с табличными данными с вероятностью 99,2%.
Поскольку интерполяция табл. 13.2 таблица 13.2 экспоненциальной кривой даёт более точное приближение (99,2%) и с меньшими стандартными ошибками для m, b и у, в качестве приближающего уравнения принимаем уравнение (13).
При х=8 получим у=1,197*34,363=41,131 град.
б) Функция РОСТ вычисляет прогнозируемое по экспоненциальному приближению значение у для новых значений х, имеет формат:
Выделим блок ячеек F14: F17 , введём формулу =РОСТ(Е2:Е7;D2:D7;G2:G5;ИСТИНА), в выделенных ячейках появится массив чисел <27,6696434;43,3384133;67,8800967;106,319248>, т.е. при х=8 значение функции у=43,34 град. Это значение немного отличается от вычисленного в п. а), поскольку функция РОСТ использует для расчетов линию экспонециального тренда.
Примечание. При выборе экспоненциальной приближающей кривой следует учитывать, что интерполировать ею можно только участки, где функция монотонно возрастает или убывает (при отрицательном аргументе х), т.е. функцию, имеющую точки перегиба (например, параболу, синусоиду, кривую рис. 2 – т. А и др.) следует разбить на участки монотонного изменения от одной точки перегиба до другой и каждый участок интерполировать отдельно. Для рисунка 2 функцию нужно разбить на 2 участка – от начала до т. А и от т. А до конца кривой.
Множественная линейная регрессия
Пример 4
Предположим, что коммерческий агент рассматривает возможность закупки небольших зданий под офисы в традиционном деловом районе. Агент может использовать множественный регрессионный анализ для оценки цены здания под офис на основе следующих переменных:
у – оценочная цена здания под офис;
х1 – общая площадь в квадратных метрах;
х2 – количество офисов;
х3 – количество входов;
х4 – время эксплуатации здания в годах.
Агент наугад выбирает 11 зданий из имеющихся 1500 и получает следующие данные:
| А | В | С | D | Е | |
|---|---|---|---|---|---|
| 1 | х1— площадь, м2 | х2 – офисы | х3 – входы | х4 – срок, лет | у – цена, у.е. |
| 2 | 2310 | 2 | 2 | 20 | 42000 |
| 3 | 2333 | 2 | 2 | 12 | 144000 |
| 4 | 2356 | 3 | 1,5 | 33 | 151000 |
| 5 | 2379 | 3 | 2 | 43 | 151000 |
| 6 | 2402 | 2 | 3 | 53 | 139000 |
| 7 | 2425 | 4 | 3 | 23 | 169000 |
| 8 | 2448 | 2 | 1,5 | 99 | 126000 |
| 9 | 2471 | 2 | 2 | 34 | 142000 |
| 10 | 2494 | 3 | 3 | 23 | 163000 |
| 11 | 2517 | 4 | 4 | 55 | 169000 |
| 12 | 2540 | 2 | 3 | 22 | 149000 |
«Пол-входа» означает вход только для доставки корреспонденции.
В этом примере предполагается, что существует линейная зависимость между каждой независимой переменной (х1,х2,х3,х4) и зависимой переменной (у), т.е. ценой зданий под офис в данном районе.
- выделим блок ячеек А14:Е18 (в соответствии с табл. 13.1 таблица 13.1),
- введём формулу =ЛИНЕЙН(Е2:Е12;А2:D12;ИСТИНА;ИСТИНА), —
- нажмём клавиши Ctrl+Shift+Enter ,
- в выделенных ячейках появится результат:
| А | В | С | D | E | |
|---|---|---|---|---|---|
| 14 | -234,237 | 2553,210 | 12529,7682 | 27,6413 | 52317,83 |
| 15 | 13,2680 | 530,6691 | 400,066838 | 5,42937 | 12237,36 |
| 16 | 0,99674 | 970,5784 | #Н/Д | #Н/Д | #Н/Д |
| 17 | 459,753 | 6 | #Н/Д | #Н/Д | #Н/Д |
| 18 | 1732393319 | 5652135 | #Н/Д | #Н/Д | #Н/Д |
Уравнение множественной регрессии  теперь может быть получено из строки 14:
теперь может быть получено из строки 14:
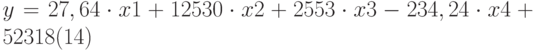
Теперь агент может определить оценочную стоимость здания под офис в том же районе, которое имеет площадь 2500 м 2 , три офиса, два входа, зданию 25 лет, используя следующее уравнение:
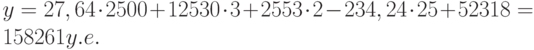
Это значение может быть вычислено с помощью функции ТЕНДЕНЦИЯ:
При интерполяции с помощью функции
для получения уравнения множественной экспоненциальной регрессии выводится результат:
| 0,99835752 | 1,0173792 | 1,0830186 | 1,0001704 | 81510,335 |
| 0,00014837 | 0,0065041 | 0,0048724 | 6,033Е-05 | 0,1365601 |
| 0,99158875 | 0,0105158 | #Н/Д | #Н/Д | #Н/Д |
| 176,832548 | 6 | #Н/Д | #Н/Д | #Н/Д |
| 0,07821851 | 0,0006635 | #Н/Д | #Н/Д | #Н/Д |
| #Н/Д | #Н/Д | #Н/Д | #Н/Д | #Н/Д |
Коэффициент детерминированности здесь составляет 0,992 (99,2%), т.е. меньше, чем при линейной интерполяции, поэтому в качестве основного следует оставить уравнение множественной регрессии (14).
Таким образом, функции ЛИНЕЙН, ЛГРФПРИБЛ, НАКЛОН определяют коэффициенты, свободные члены и статистические параметры для уравнений одномерной и множественной регрессии, а функции ТЕНДЕНЦИЯ, ПРЕДСКАЗ, РОСТ позволяют получить прогноз новых значений без составления уравнения регрессии по значениям тренда.
ЗАДАНИЕ
Вариант задания к данной лабораторной работе включает две задачи. Для каждой из них необходимо составить и определить:
- Таблицу исходных данных, а также значений, полученных методами линейной и экспоненциальной регрессии.
- Коэффициенты в уравнениях прямой и экспоненциальной кривой (функции ЛИНЕЙН и ЛГРФПРИБЛ), напишите уравнения прямой и экспоненциальной кривой для простой и множественной регрессии.
- Погрешности (ошибки) прямой и экспоненциальной кривой, вычислений для коэффициентов и функций, коэффициенты детерминированности. Оценить, какой тип регрессии наилучшим образом подходит для вашего варианта задания.
- Прогноз изменения данных, выполненный с использованием линейной и экспоненциальной регрессии (функции ТЕНДЕНЦИЯ, ПРЕДСКАЗ, РОСТ).
- Построить гистограмму (или график) исходных данных для задачи 1 (одномерная регрессия), отобразить на ней линию тренда, а также соответствующее ей уравнение и коэффициент детерминированности.
Варианты заданий (номер варианта соответствует номеру компьютера).
- На рынке наблюдается стойкое снижение цен на компьютеры. Сделать прогноз, на сколько необходимо будет снизить цену на компьютеры в следующем месяце в вашей фирме, чтобы как минимум сравнять её с ценой на аналогичные компьютеры в конкурирующей фирме, если известна динамика изменения цен на них в конкурирующей фирме за последние 12 месяцев.
Для выполнения задания нужно ввести ряд из 12 ячеек с ценами конкурирующей фирмы, сделать прогноз цены на следующий месяц и др. (см. Задание).
- Известна структура расходов фирмы на рекламу в газетах, на радио, в журналах, на телевидении, на наружную рекламу (в процентах от общей суммы), а также оборот фирмы в каждом за последние 6 месяцев. Какой оборот можно ожидать в следующем месяце, если предполагается следующая структура расходов на рекламу: газеты-40%, журналы-40%, радио-5%, телевидение-14%, наружная реклама-1%.
Для выполнения задания нужно составить таблицу со столбцами вида:
| Месяц | х1-газеты,% | х2-журн.,% | х3-рад.,% | х4-телев.,% | х5-нар. рекл.,% | Оборот, $ |
|---|---|---|---|---|---|---|
| 1 | 37 | 34 | 12 | 10 | 5 | 410000 |
| 2 | 38 | 37 | 10 | 11 | 6 | 411500 |
| 3 | 39 | 38 | 9 | 13 | 7 | 413700 |
| 4 | 40 | 39 | 8 | 15 | 8 | 417050 |
| 5 | 41 | 40 | 7 | 16 | 9 | 420000 |
| 6 | 42 | 42 | 5 | 17 | 10 | 425000 |
и сделать множественный регрессионный прогноз (см. Задание).
- Имеются данные об объеме продаж в расчете на душу населения по хлебу и молоку и данные по годовым доходам на душу за 10 лет. По каждому товару построить модели регрессии для объемов продаж и функции размера доходов. Сделать прогноз о продажах и доходах на следующий год.
Для выполнения задания нужно составить таблицу вида:
| Годы | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| х1-хлеб, кг | 23,5 | 26,7 | 27,9 | 30,1 | 31,5 | 35,7 | 38,3 | 40,1 | 41,5 | 42,8 | |
| х2-молоко, л | 20,45 | 22 | 23,8 | 25,9 | 27,4 | 29 | 33,5 | 36,8 | 38,1 | 39,5 | |
| У-доход, р. | 6600 | 7200 | 8400 | 10500 | 12750 | 14730 | 16240 | 17000 | 18050 | 18250 |
и получить два уравнения – у=f(x1) и у=f(x2), сделать прогноз на следующий год для рядов х1, х2, у и др. (см. Задание).
- Руководство фирмы провело оценку качеств пяти рекламных агентов по следующим признакам: х1 – эрудиция, х2 – знание предметной области. Полученные средние оценки, нормированные от 0 до 1, были сопоставлены с оценками эффективности деятельности агентов (% успешных сделок от количества возможных). Определить эффективность для агента с усреднёнными качествами. Сравнить её со средней эффективностью упомянутых 5 агентов.
Исходные данные нужно ввести в таблицу вида:
| А | В | С | D | E | F | G | |
|---|---|---|---|---|---|---|---|
| 1 | х1-эрудиция | х2-энергичность | х3-люди | х4-внешность | х5-знания | Эффективность | |
| 2 | Агент 1 | 0,8 | 0,2 | 0,4 | 0,6 | 1,0 | 76% |
| 3 | Агент 2 | 0,74 | 0,3 | 0,39 | 0,58 | 0,95 | 78% |
| 4 | Агент 3 | 0,67 | 0,41 | 0,35 | 0,5 | 0,83 | 79% |
| 5 | Агент 6 | 0,59 | 0,59 | 0,33 | 0,47 | 0,8 | 80% |
| 6 | Агент 5 | 0,5 | 0,7 | 0,3 | 0,4 | 0,74 | 81% |
| 7 | Средняя эффективность пяти агентов | ||||||
| 8 | Средний агент | 0,5 | 0,5 | 0,5 | 0,5 | 0,5 | |
Массив ячеек В2-F6 заполняется произвольными числами от 0 до 1, столбец G2 -G6 – процентами удачных сделок по принципу «Чем выше уровень качеств агента, тем выше эффективность его работы», в ячейке G7 должна быть формула для вычисления среднего значения ячеек G2:G6 , в ячейке G8 нужно вычислить значение эффективности для среднего агента по формуле, полученной в результате множественного регрессионного анализа работы пяти агентов. Остальные пункты – см. Задание.
- Автосалон имеет данные о количестве проданных автомобилей «Мерседес» и «БМВ» за последние 4 квартала. Учитывая тенденцию изменения объёма продаж, определить, каких автомобилей нужно закупить больше («Мерседес» или «БМВ») в следующем квартале?
Для выполнения задания нужно составить и заполнить таблицу вида:
| Х | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| Мерседес ( Y1 ) | 10 | 12 | 15 | 18 | |
| БМВ ( Y2 ) | 9 | 10 | 14 | 17 |
сделать прогноз продаж на новый квартал и выполнить другие пункты задания.
- Известны следующие данные о 5 недавно проданных подержанных автомобилях: у – стоимость продажи, х1 – стоимость аналогичного нового автомобиля, х2 – год выпуска, х3 – пробег, х4 – количество капитальных ремонтов, х5 – экспертные заключения о состоянии кузова и техническом состоянии автомобилей (по 10-бальной шкале). Определить, сколько может стоить автомобиль с соответствующими характеристиками: 340 000, 1998г., 140000км., 1, 6 (см. пример 4).
- Определить минимально необходимый тираж журнала и возможный доход от размещения в нём рекламы в следующем месяце, если известны данные об объёмах продаж этого журнала и доходах от размещения рекламы за последние 12 месяцев (считать, что расценки на рекламу не менялись).
Для выполнения задания нужно составить таблицу вида:
| Месяц | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Тираж,тыс. | 100 | 120 | 121,7 | 124,2 | 128 | 130,1 | 133,45 | 136 | 141 | 142,1 | 143,8 | 145 |
| Доход,тыс. руб. | 128 | 135 | 138 | 142 | 147 | 154 | 159 | 161 | 163 | 168 | 170,5 | 172 |
и заполнить ячейки за 12 месяцев условными данными. По этим данным нужно сделать линейный и экспоненциальный прогноз и др. (см. Задание).
- В целях привлечения покупателей и увеличения оборота фирма проводит стратегию ежемесячного снижения цен на свой товар. На основании данных о динамике изменения цен, объемов продаж в данной фирме и ещё в 3 конкурирующих фирмах за последние 12 месяцев сделать прогноз о том, возрастает ли объём продаж у данной фирмы при очередном снижении цен в следующем месяце, если предположить, что цены и объёмы у конкурентов в следующем месяце будут средние за рассматриваемый период.
Для выполнения задания нужно составить таблицу вида:
| Мес. | Фирма | Конкурент 1 | Конкурент 2 | Конкурент 3 | ||||
|---|---|---|---|---|---|---|---|---|
| 1 | У-объём | х1-цена | х2-объём | х3-цена | х4-объём | х5-цена | х6-объём | х7-цена |
| 2 | 10000 | 1875 | 12000 | 1720 | 12500 | 1740 | 11970 | 1700 |
| 3 | 11000 | 1850 | 12340 | 1705 | 12620 | 1735 | 12100 | 1690 |
| 4 | 11570 | 1810 | 12750 | 1675 | 12740 | 1710 | 12350 | 1645 |
| 5 | 11850 | 1750 | 12910 | 1630 | 12960 | 1695 | 12500 | 1615 |
| 6 | 12100 | 1685 | 13100 | 1615 | 13000 | 1674 | 12630 | 1580 |
| 7 | 12340 | 1630 | 13570 | 1600 | 13210 | 1625 | 12920 | 1545 |
| 8 | 12750 | 1615 | 13820 | 1575 | 13320 | 1610 | 13150 | 1520 |
| 9 | 12910 | 1600 | 13980 | 1515 | 13460 | 1560 | 13300 | 1500 |
| 10 | 13100 | 1575 | 14000 | 1500 | 13600 | 1525 | 13610 | 1490 |
| 11 | 13230 | 1530 | 14070 | 1495 | 13780 | 1500 | 13850 | 1485 |
| 12 | 13470 | 1510 | 14120 | 1488 | 13900 | 1460 | 14000 | 1475 |
| 13 | ||||||||
- На основании данных о курсе американского доллара и немецкой марки в первом полугодии сделать прогноз о соотношении данных валют на второе полугодие. Во что будет выгоднее вкладывать деньги в конце года?
Для выполнения задания нужно составить таблицу вида:
| Месяц | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Доллар | 24,5 | 24,9 | 25,7 | 26,9 | 28,0 | 28,8 | 29,3 | 29,7 | 30,5 | 30,9 | 31,8 | |
| Марка | 72,1 | 76,3 | 79,6 | 85,3 | 89,7 | 90,9 | 93,2 | 96,4 | 100,2 | 101,6 | 104,9 |
и сделать линейный прогноз на следующие 6 месяцев и др. (см. Задание).
- Известны данные за последние 6 месяцев о том, сколько раз выходила реклама фирмы, занимающейся недвижимостью, на телевидении – х1, радио – х2, в газетах и журналах – х3, а также количество звонков –у1 и количество совершённых сделок – у2. Какое соотношение количества совершённых сделок к количеству звонков у (в %) можно ожидать в следующем месяце, если известно, сколько раз выйдет реклама в каждом из перечисленных средств массовой информации.
Для выполнения задания нужно составить и заполнить таблицу вида:
| A | B | C | D | E | |
|---|---|---|---|---|---|
| 1 | месяц | х1 | х2 | х3 | y=у2/у1*100% |
| 2 | 1 | 15 | 10 | 24 | 78% |
| 3 | 2 | 16 | 11 | 23 | 80% |
| 4 | 3 | 18 | 12 | 22 | 81% |
| 5 | 4 | 19 | 12 | 22 | 84% |
| 6 | 5 | 21 | 13 | 21 | 85% |
| 7 | 6 | 22 | 14 | 20 | 89% |
| 8 | 7 |
и выполнить применительно к таблице пункты Задания.
- Для некоторого региона известен среднегодовой доход населения, а также данные о структуре расходов (тыс. руб. в год) за последние 5 лет по следующим статьям: питание – х1, жильё – х2, одежда – х3, здоровье – х4, транспорт – х5, отдых – х6, образование – х7. На основании известных данных провести анализ потребительского кредита (или накопления) в следующем 6 году.
Для выполнения задания нужно составить и заполнить таблицу вида
| Годы | х1 | х2 | х3 | х4 | х5 | х6 | х7 | Расход  | Доход | Кредит(Y) |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 5 | 2 | 1,3 | 1 | 0,3 | 5 | 4 | 18,6 | 21,4 | 3,1 |
| 2 | 5,2 | 2,2 | 1,2 | 1,2 | 0,4 | 4,8 | 4,5 | 19,5 | 22 | 2,5 |
| 3 | 5,5 | 2,5 | 1,1 | 1,4 | 0,6 | 4,6 | 4,9 | 20,6 | 23,4 | 2,8 |
| 4 | 5,8 | 2,7 | 0,9 | 1,6 | 1 | 4,2 | 5,6 | 21,8 | 25,8 | 4 |
| 5 | 7 | 3 | 0,8 | 2 | 1,2 | 4 | 6,5 | 24,7 | 26,2 | 1,5 |
| 6 | 7,5 | 3,3 | 0,7 | 2,2 | 1,5 | 3,8 | 7 | 26,5 | 27,5 |
В ячейках столбца 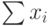 ) должны быть записаны формулы, вычисляющие суммы всех расходов х1+х2+…+х7 в каждом году, в ячейках столбца Доход – соответствующие среднегодовые доходы, в ячейках столбца Кредит – формулы разности содержимого ячеек с ежегодными доходами и затратами, т.е. Кредит = Доход- . Затем для столбца Кредит нужно выполнить регрессионный прогноз на следующий год и другие пункты Задания.
) должны быть записаны формулы, вычисляющие суммы всех расходов х1+х2+…+х7 в каждом году, в ячейках столбца Доход – соответствующие среднегодовые доходы, в ячейках столбца Кредит – формулы разности содержимого ячеек с ежегодными доходами и затратами, т.е. Кредит = Доход- . Затем для столбца Кредит нужно выполнить регрессионный прогноз на следующий год и другие пункты Задания.
- Для 10 однокомнатных квартир, расположенных в одном районе, известны следующие данные: общая площадь – х1, жилая площадь – х2, площадь кухни – х3, наличие балкона – х4, телефона – х5, этаж – х6, а также стоимость – y . Определить, сколько может стоить однокомнатная квартира в этом районе без балкона, без телефона, расположенная на 1-ом этаже, общей площадью 28 м 2 , жилой – 16 м 2 , с кухней 6 м 2 .
| Квартиры | X1 | X2 | X3 | X4 | X5 | Стоимость ( y ) |
|---|---|---|---|---|---|---|
| 1 | 41 | 33 | 7 | 1 | 2 | 42000 |
| 2 | 40 | 30 | 7,7 | 2 | 3 | 40000 |
| 3 | 45 | 37 | 8 | 0 | 5 | 47000 |
| 4 | 46,3 | 34 | 9 | 1 | 6 | 49500 |
| 5 | 50 | 36 | 9 | 1 | 4 | 51000 |
| 6 | 53 | 40 | 9,5 | 1 | 7 | 55000 |
| 7 | 56 | 41 | 10 | 0 | 9 | 62000 |
| 8 | 60 | 47 | 12 | 2 | 10 | 62300 |
| 9 | 65 | 49 | 14 | 2 | 12 | 69000 |
| 10 | 70 | 58 | 14,5 | 2 | 14 | 72000 |
| 11 | 28 | 16 | 6 | 0 | 1 |
- Определить возможный прирост населения (кол-во человек на 1000 населения) в 2011 году, если известны данные о кол-ве родившихся и умерших на 1000 населения в 1997-2006 годах.
| Годы | 1997 | 1998 | 1999 | 2000 | 2001 | 2002 | 2003 | 2004 | 2005 | 2006 | 2011 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Родились | 100 | 110 | 130 | 155 | 170 | 174 | 180 | 185 | 190 | 200 | |
| Умерли | 108 | 115 | 135 | 160 | 178 | 180 | 186 | 190 | 197 | 205 |
- После некоторого спада наметился рост объёмов продаж матричных принтеров. Используя данные об объёмах продаж, ценах на матричные, струйные и лазерные принтеры, а также на их расходные материалы за последние 6 месяцев, определить возможный спрос на матричные принтеры в следующем месяце.
Проанализируйте, связано ли увеличение спроса на матричные принтеры с уменьшением спроса на струйные и лазерные.
| Матричные принтеры | Струйные принтеры | Лазерные принтеры | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Спрос у1 | Цена х1 | Рас.мат. z1 | Спрос у2 | Цена х2 | Рас.мат. z/2 | Спрос у3 | Цена х3 | Рас.мат. z3 | |
| 1 | 56 | 4172 | 174 | 26 | 2384 | 558 | 13 | 12517 | 1558 |
| 2 | 58 | 4250 | 179 | 24 | 2398 | 570 | 11 | 12984 | 1612 |
| 3 | 60 | 4289 | 182 | 23 | 2401 | 598 | 9 | 13259 | 1789 |
| 4 | 65 | 4297 | 194 | 20 | 2456 | 649 | 8 | 13687 | 1865 |
| 5 | 69 | 4305 | 205 | 19 | 2512 | 722 | 7 | 14013 | 1998 |
| 6 | 75 | 4318 | 213 | 18 | 2543 | 768 | 6 | 14587 | 2200 |
| 7 | 4456 | 220 | 17 | 2601 | 779 | 5 | 14789 | 2245 | |
Необходимо сделать прогноз на седьмой месяц по уравнению у1=f(x1,z1), получить уравнение y=(у2,x2, z2, у3, x3, z2 ) и проанализировать его. Если слагаемые у2 и у3 входят в регрессионное уравнение со знаком «-«, то уменьшение спросов у2 и у3 ведёт к увеличению спроса у1.
- Построить прогноз развития спроса населения на телевизоры, если известна динамика продаж телевизоров (тыс. шт.) и динамика численности населения (тыс. чел.) за 10 лет. По данным таблицы сделать прогноз по обоим рядам на следующий год. Выполнить другие пункты задания.
| Годы | 2001 | 2002 | 2003 | 2004 | 2005 | 2006 | 2007 | 2008 | 2009 | 2010 | 2011 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Динамика населения (тыс. чел) | 21,5 | 26,1 | 31,5 | 34,9 | 45,1 | 50,8 | 56 | 59,4 | 63,9 | 67,1 | |
| Динамика продаж (тыс. шт.) | 2,5 | 2,9 | 3,4 | 3,9 | 4,1 | 4,8 | 5 | 5,6 | 5,9 | 6,2 |
- Размещая рекламу в 4-х изданиях, фирма собрала сведения о поступивших на нее откликов – у и сопоставила их с данными об изданиях: х1 – стоимость издания, х2 – стоимость одного блока рекламы, х3 – тираж, х4 – объём аудитории, х5 – периодичность, х6 – наличие телепрограммы. Какое количество откликов можно ожидать на рекламу в издании со следующими характеристиками: 15000 руб., 10$, 1000 экз., 25000 чел., 4 раза в месяц, без телепрограммы.
Пользуясь данными таблицы
| Издания | х1 | х2 | х3 | х4 | х5 | х6 | Отклики, у |
|---|---|---|---|---|---|---|---|
| 1 | 10000 | 13 | 700 | 15000 | 4 | 1 | 108 |
| 2 | 12500 | 12 | 850 | 22000 | 8 | 1 | 115 |
| 3 | 15890 | 11,8 | 960 | 28000 | 10 | 0 | 120 |
| 4 | 17850 | 11 | 1200 | 32000 | 26 | 1 | 128 |
| 5 | 15000 | 10 | 1000 | 25000 | 4 | 0 |
необходимо сделать прогноз при заданных характеристиках.
- Размещая свою рекламу в 2-х печатных изданиях одновременно, фирма собрала сведения о количестве поступивших звонков и количестве заключенных сделок по объявлениям в каждом из указанных изданий за последние 12 месяцев. Определить, в каком из изданий и насколько эффективность размещения рекламы в следующем месяце будет больше?
| Месяцы | Издание 1 | Издание 2 | ||
|---|---|---|---|---|
| Звонки | Сделки | Звонки | Сделки | |
| 1 | 98 | 66 | 112 | 79 |
| 2 | 105 | 72 | 143 | 85 |
| 3 | 105 | 75 | 150 | 90 |
| 4 | 110 | 80 | 130 | 100 |
| 5 | 125 | 90 | 120 | 75 |
| 6 | 140 | 100 | 115 | 80 |
| 7 | 136 | 95 | 128 | 82 |
| 8 | 137 | 87 | 132 | 78 |
| 9 | 145 | 102 | 138 | 88 |
| 10 | 123 | 75 | 143 | 92 |
| 11 | 130 | 79 | 150 | 97 |
| 12 | 139 | 88 | 155 | 97 |
| 13 | ||||
Эффективность определяется как сделки/звонки. Сделать линейный и экспоненциальный прогнозы по обоим изданиям.
- Пусть комплект мягкой мебели (диван + 2 кресла) характеризуется стоимостью комплектующих: х1— деревянные подлокотники, х2 – велюровое покрытие, х3 – кресло-кровать, х4 – угловой диван, х5 – раскладывающийся диван, х6 – место для хранения белья. По данным о стоимости 5 комплектов сделать вывод о возможной стоимости комплекта с обычным раскладывающимся диваном, с местом для белья, без деревянных подлокотников и велюрового покрытия, с креслом кроватью.
Пользуясь данными таблицы
| Признаки | х1 | х2 | х3 | х4 | х5 | х6 | У -стоимость |
|---|---|---|---|---|---|---|---|
| Комплект 1 | 250 | 540 | 2500 | 4300 | 6400 | 800 | 13850 руб. |
| Комплект 2 | 320 | 650 | 3000 | 4800 | 7000 | 980 | 15770 руб. |
| Комплект 3 | 400 | 730 | 3900 | 6000 | 8500 | 1100 | 16730 руб. |
| Комплект 4 | 452 | 1300 | 4300 | 7500 | 9200 | 2050 | 24350 руб. |
| Комплект 5 | 550 | 1750 | 6400 | 12450 | 16700 | 4300 | 42150 руб. |
| Комплект 6 | 670 | 800 | 2750 | 6700 | 8800 | 1000 |
сделать прогноз и выполнить другие пункты задания.
- Для 2-х радиостанций известны данные об изменении объёма аудитории и динамике роста цен за 1 минуту эфирного времени за последние 12 месяцев. Определить, для какой радиостанции стоимость одного контакта со слушателем будет меньше?
| Месяц | Радиостанция 1 | Радиостанция 2 | ||
|---|---|---|---|---|
| Аудитория | Цена 1 мин. | Аудитория | Цена 1 мин. | |
| 1 | 250000 | 8000 | 300000 | 7560 |
| 2 | 540000 | 6500 | 450000 | 6340 |
| 3 | 580000 | 6460 | 490000 | 6250 |
| 4 | 650000 | 6300 | 550000 | 6000 |
| 5 | 730000 | 6060 | 610000 | 5730 |
| 6 | 750000 | 6000 | 690000 | 5300 |
| 7 | 800000 | 5400 | 750000 | 5100 |
| 8 | 840000 | 5320 | 780000 | 5000 |
| 9 | 890000 | 5130 | 870000 | 4700 |
| 10 | 950000 | 5000 | 900000 | 4650 |
| 11 | 1000000 | 4800 | 940000 | 4600 |
| 12 | 1108000 | 4700 | 1025000 | 4540 |
| 13 | ||||
| Контакт | ||||
В строке «Контакт» в ячейках С8 и D8 должны быть записаны формулы = С7/В7 и =Е7/D7 соответственно, вычисляющие стоимость 1 мин. Эфира для одного слушателя в прогнозируемом месяце. Прогноз нужно выполнить для линейного и экспоненциального приближений и выбрать более достоверный, а также сделать другие пункты Задания.
- На основании данных ежемесячных исследований известна динамика рейтинга банка (в условных единицах) за последние 6 месяцев в следующих сферах:
- менеджмент и технология – х1;
- менеджеры и персонал – х2;
- культура банковского обслуживания – х3;
- имидж банка на рынке финансовых услуг – х4;
- реклама банка – х5.
Определить возможное изменение количества вкладчиков данного банка в следующем месяце, если известны значения сфер рейтинга и количество вкладчиков в каждом из рассматриваемых 6 месяцев.
http://baguzin.ru/wp/prostaya-linejnaya-regressiya/
http://intuit.ru/studies/courses/3659/901/lecture/32718