Параллельная реализация на CUDA метода последовательных приближений для численного решения систем обыкновенных дифференциальных уравнений Текст научной статьи по специальности « Математика»
Аннотация научной статьи по математике, автор научной работы — Коробицын В. В., Фролова Ю. В.
Предлагается параллельная реализация метода последовательных приближений с использованием технологии NVIDIA CUDA. Приводятся результаты тестирования алгоритма на видеокарте. Показано влияние значения параметров метода на точность и устойчивость. На примере одной задачи показан способ получения оптимальных значений параметров, обеспечивающих наибольшую скорость вычисления траектории решения системы обыкновенных дифференциальных уравнений.
Похожие темы научных работ по математике , автор научной работы — Коробицын В. В., Фролова Ю. В.
Parallel implementation on CUDA of serial approximation method for numerically solving the system of ordinary differential equations
Parallel implementation for serial approximation method on NVIDIA CUDA technology is suggested. The testing results of algorithm on videocard are discussed. We show, how an accuracy and stability depend on method parameters. The optimal values of method parameters are derived for obtaining the maximum rate of computing the solution trajectory for system of ordinary differential equations.
Текст научной работы на тему «Параллельная реализация на CUDA метода последовательных приближений для численного решения систем обыкновенных дифференциальных уравнений»
Вестн. Ом. ун-та. 2011. № 4. С. 157-163.
В. В. Коробицын, Ю.В. Фролова
ПАРАЛЛЕЛЬНАЯ РЕАЛИЗАЦИЯ НА СиБА МЕТОДА ПОСЛЕДОВАТЕЛЬНЫХ ПРИБЛИЖЕНИЙ ДЛЯ ЧИСЛЕННОГО РЕШЕНИЯ СИСТЕМ ОБЫКНОВЕННЫХ ДИФФЕРЕНЦИАЛЬНЫХ УРАВНЕНИЙ
Предлагается параллельная реализация метода последовательных приближений с использованием технологии МУГОІЛ СИБЛ. Приводятся результаты тестирования алгоритма на видеокарте. Показано влияние значения параметров метода на точность и устойчивость. На примере одной задачи показан способ получения оптимальных значений параметров, обеспечивающих наибольшую скорость вычисления траектории решения системы обыкновенных дифференциальных уравнений.
Ключевые слова: метод Пикара, параллельный алгоритм, технология СИБЛ.
Развитие современной вычислительной техники связано с разработкой параллельных вычислительных систем. Многоядерные процессоры, кластеры и суперкомпьютеры добиваются повышения производительности в основном за счет параллельного решения задач. Однако параллелизм бывает разный: на уровне системы, где каждая исполняемая программа выполняется на физически отдельном ядре процессора, и на уровне отдельного приложения, где сама программа использует возможности параллельного исполнения кода программы на разных процессорах. При этом производительность программ, исполняемых на параллельных системах, во многом зависит от тех алгоритмов, которые используются для решения задачи в параллельном режиме.
Одной из актуальных задач параллельных вычислений является разработка параллельных алгоритмов численного решения систем обыкновенных дифференциальных уравнений (ОДУ). Однако большинство алгоритмов решения систем ОДУ являются последовательными. Поэтому наиболее распространенный вариант распараллеливания заключается в параллельном вычислении правой части системы [1; 5]. Особенно это выгодно, когда размерность системы велика (более 1000) [3; [4]. Такое распараллеливание принято называть распараллеливанием по пространству (parallelism across space). Однако существует и другой подход, который реализует распараллеливание вдоль траектории решения системы. Траектория вычисляется одновременно в нескольких точках. Такое распараллеливание принято называть распараллеливанием по времени (parallelism across time). Одним из первых алгоритмов, который можно так распараллелить, является алгоритм последовательных приближений (метод Пикара).
В данной работе предлагается параллельная реализация метода последовательных приближений. В качестве параллельной платформы выбрана архитектура NVIDIA CUDA, обеспечивающая реализацию параллельных алгоритмов для вычислений на графических (GPU) и спе-
© В.В. Коробицын, Ю.В. Фролова, 2011
циалированных процессорах НУЮ1Л.
Эффективность вычислений на ОРи показана на многих прикладных задачах. Основная задача статьи заключается в изучении влияния значений параметров метода на точность, устойчивость и скорость вычислений. Мы протестировали метод на одной простой модели и получили результаты, которые показывают свойства метода для целого класса задач.
1. Метод последовательных приближений
Метод последовательных приближений обычно используется для теоретических исследований. Практическое применение этого метода для решения задач -процедура довольно утомительная. Приходится многократно вычислять интегралы, если это вообще возможно. В частности, в монографии [2] этот метод характеризуется как чисто теоретический. Однако идея использования метода последовательных приближений высказывалась и ранее [6]. Но не было возможности реализовать идею на практике, поскольку для эффективной реализации требуется компьютер с большим количеством одновременно выполняемых потоков и имеющий общую память. Такой эксперимент стало возможным реализовать сейчас с использованием ОРи, который обладает массовым параллелизмом (свыше 20 000 параллельно выполняемых потоков).
В общем виде метод формулируется так. Необходимо расщепить функцию Л^х) из дифференциального уравнения
= / (и х) = Ш, х) + /2^, х), х (^) = Х0
так, чтобы легко можно было бы решить уравнение вида Сх/dt=/l(t,Х)+c|(t). Тогда, начиная с первого приближения Хэ(^, на каждой 1-ой итерации решаем уравнение
-— = х1+1(0) + х‘(0), х1+1(0 = х0, (1)
получаем последовательность функций х1^), х2(^. равномерно сходящуюся к решению х(^.
В простейшем случае выбирают / = 0, / = /, тогда, проинтегрировав (1), получаем формулу
х’+1(t) = хо + I /(5, х’ (5))&5.
Этот вариант метода имеет название
— метод последовательных приближений Пикара. Последовательность х'(0 равномерно сходится к решению х(0 при вы-
полнении условия Липшица для функции //,х) по второму аргументу.
Этот метод на практике не использовался для решения ОДУ, поскольку требовал большего количества вычислений, чем, например, методы Рунге-Кутты. Однако это верно при реализации линейных алгоритмов, когда вычисления производятся последовательно, шаг за шагом по времени.
При использовании методов Рунге-Кутты невозможно вычислить решение в точке t+h, если неизвестно значение в точке t. Тогда как при вычислениях по методу последовательных приближений при нахождении интеграла значения функции / можно вычислять параллельно для различных точек t, что способствует построению параллельного вычислительного алгоритма.
2. Численная схема метода последовательных приближений
Будем рассматривать задачу Коши для системы из п обыкновенных дифференциальных уравнений первого порядка. Для заданной функции ГК^^К” необходимо найти х:[70; Т] ^К”, удовлетворяющую системе ОДУ
с заданным начальным условием х(^)=х0.
Предполагаем, что функция 1^, х) удовлетворяет условию Липшица по второму аргументу во всей области определения, тогда решение существует и единственно.
Для нахождения численного решения задачи (3) построим метод, основанный на параллельной реализации метода последовательных приближений. Разобъем отрезок Т] на т частей, получим по-
следовательность узлов ^, ^, ^. tm.1 = Т. Обозначим за х/ приближенное значение функции х(0 в точке tj на итерации ‘. В качестве начального приближения возьмем х/ = х0, то есть на нулевой итерации функция х°(0 постоянная. На каждом интервале [г); tj+\] решение будем находить с помощью итерационной процедуры (2). В этой формуле присутствует определенный интеграл, который будем вычислять численно.
В зависимости от выбора квадратурной формулы получим методы различной точности. В частности, если выбрать ме-
тод трапеций, то получим следующую итерационную процедуру:
x;- = x0, x0! = x0 для всех j = 0,i, . m-2, i = i,2. K.
Обращаем внимание на то, что в формуле (4) при вычислении sji отсутствуют значения x на i итерации, что дает возможность производить вычисления для i итерации независимо для всех точек tj одновременно, используя только значения на предыдущей итерации i-i. Этот факт дает возможность параллельной реализации вычисления формулы (4) для всех j одновременно. Вычисление формулы (5) реализуется последовательным алгоритмом. Таким образом, вся итерационная процедура (4)-(5) разбивается на параллельную и последовательную части алгоритма. Но поскольку в последовательной части присутствует только одна операция сложения, а в параллельной -трудоемкое вычисление функции f, предложенный алгоритм должен иметь значительное увеличение скорости вычислений, несмотря на то, что потребуется произвести K итераций.
3. Параллельная реализация численного метода на CUDA
Вычислительная производительность современных видеокарт во много раз превосходит производительность центральных процессоров. Архитектура графических процессоров позволяет производить большое количество параллельно исполняемых потоков вычислений на одном GPU. Кроме того, компания NVIDIA выпускает платы Tesla, предназначенные исключительно для решения вычислительных задач, поддерживающих архитектуру CUDA. Существуют кластерные решения, объединяющие серверы на основе х8б архитектуры и вычислительные узлы c Tesla, так называемые гибридные системы. Для реализации метода последовательных приближений была выбрана технология NVIDIA CUDA.
Рассмотрим реализацию метода последовательных приближений на CUDA [7]. Предполагается, что необходимо вычислить r частных решений (траекторий) системы (З). Поскольку вычисление разных траекторий не требует обмена данными между ними, то траектории можно
вычислять в разных блоках. Поэтому нам потребуется сетка, содержащая r блоков. Внутри каждого блока будет вычисляться только одна траектория. Потоки в блоке разбиваются по размерности системы n и по количеству m одновременно вычисляемых шагов по времени. Таким образом, в одном блоке будет m xn потоков, вычисляемых параллельно и обменивающихся результатами вычислений. Приведенный способ разбиения вычислений по потокам реализует принципы распараллеливания по времени и по пространству, что обеспечивает наибольшую скорость вычислений.
Конфигурация сетки ядра задается параметрами: r — количество вычисляемых траекторий решения, n — размерность системы ОДУ, m — количество шагов по времени в схеме метода. Входные параметры функции: массив х, содержащий векторы начальных данных (r x n элементов), t0 — начальный момент времени, h — величина шага по времени (|h|>0), K — количество итераций приближения (K > 2), stp — количество больших шагов длиной H = (m — 1)h. Выходной параметр -массив у, содержащий векторы решения в момент времени t0 + stpH.
Для обеспечения высокой скорости обмена между потоками эффективно использовать разделяемую память GPU (shared memory). Эта память имеет высокую скорость доступа, но ограничена в объеме. В предлагаемой реализации используется 2 массива (р и s), размещенные в разделяемой памяти. Массив р используется для хранения значений xj, массив s
— для хранения значений правых частей f(t, x;) (j = 0. m — 1). Поскольку каждый элемент Xj имеет размерность задачи n, то размерность массива получается m x n. Для хранения чисел выбран типа float.
Функция ядра odesa реализует следующие этапы:
1) определение индексов потока и занесение начальных значений х0 во все ячейки массива p;
2) вычисление stp шагов длины H по схеме метода;
3) копирование значений найденного решения в массив y.
На каждом вычисляемом шаге (этап 2) производится K итераций, осуществляющих действия:
• вычисление функции правой части системы fk(tj, х/»1) и сохранение ее значений в массиве s;
• вычисление Ху+і по формулам (4)-(5) и сохранение этих значений в массиве р;
• копирование вычисленных значений хКт-1 во все ячейки массива р после завершения К итераций.
В конце каждого этапа и каждого действия этапа 2 производится синхронизация потоков, чтобы следующее действие началось одновременно во всех потоках одного блока.
Вызов функции ядра ойеъа осуществляется из функции ойе$а_$ої\е. Данная функция является интерфейсом для между СРи и ОРи и осуществляет следующие действия:
• выделяет память на устройстве;
• задает конфигурацию ядра;
• копирует начальные данные задачи на устройство;
• копирует результат вычислений с устройства в оперативную память;
• освобождает память на устройстве.
Функция odesa_solve сохраняет результат вычислений в массиве х.
4. Теоретическая оценка
показателей эффективности параллельной реализации
Приведем теоретические оценки показателей эффективности параллельной реализации алгоритма решения систем ОДУ. В качестве последовательного алгоритма возьмем метод Эйлера, имеющий тот же порядок точности, что и предложенная реализация метода последовательных приближений.
Для вычисления г траекторий системы ОДУ размерности п для т шагов интегрирования методом Эйлера потребуется время
Т1(г,п,т) = г п т (/+ ґа + іД где ґ/ — среднее время для вычисления одной компоненты вектор-функции правой части системы, іа и — время выполнения операций сложения и умножения.
Для решения той же задачи методом последовательных приближений за К итераций со схемой трапеций для вычисления определенного интеграла в последовательном режиме получаем
Т 1(г,п,т) = К г п т (/+ 2 ґа + іД
При параллельной реализации на р процессорах имеем
Т р(г,п,т) = К г п т ґ/+2 ґа + ґр + іс) / р, где їо — среднее время синхронизации потоков. Получаем теоретическую оценку ускорения параллельного алгоритма
Tj*( r, n, m) Tp( r, n, m)
Если ^ мало по сравнению с / то ускорение будет стремиться к р. Если сравнить производительность параллельного алгоритма с последовательным методом Эйлера, то получим ускорение
K (tf + 2ta+ tu+ ta)
В этом случае, Бр Не можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
Полученная формула дает приблизительную оценку эффективности параллельной реализации относительно последовательной, поскольку не учитывает нюансы исполнения программ на конкретных аппаратных средствах.
5. Численные эксперименты
Исследование численного алгоритма проводилось на нелинейной модели динамики численности двух взаимодействующих популяций (упрощенная модель Лот-
ки-Вольтерра). Модель описывается системой из двух обыкновенных дифференциальных уравнений:
—1 = ax, — ex, x2 — ax, , dt 1 1 2 1
—2 = уx2 + ^x, x2 — bx\. dt
Рис. 1. Траектория решения системы (7) на фазовой плоскости
В модели использовались следующие параметры: a = 0,25, в = 0,01, у = -0,3,
a = 0,001, b = 0,002. Численное решение вычислялось для траектории с начальными данными: x1(0) = 50, x2(0) = 30 на интервале времени te[0; 100]. Таким образом, были заданы параметры задачи: n = 2, t0 = 0, T = 100, х[0] = 50, х[1] = 30. Траектория на фазовой плоскости (рис. 1) показывает поведение решения задачи. Для оценки производительности метода вычислялось одновременно 8192 траектории. Исследование алгоритма проводилось для следующих значений параметров метода: те<4; 8; 16; 32; 64; 128; 256>, Ke<2; 3; 4; 5; 6; 7; 8; 9>, he[0.00001; 1.0].
Для вычислений мы использовали тип данных float поскольку точность выбранной схемы интегрирования (метод трапеций) невысока. Поэтому использование типа double потребовало бы больше вычислительных затрат с достижением той же точности.
Сначала мы оценили погрешность численного решения при разных заданных параметрах метода. Графики зависимостей (рис. 2) глобальной погрешности E найденного численного решения от выбранного шага интегрирования h при различных значениях параметра m (от 4 до 256) и фиксированном K = 3 показывают поведение погрешности метода. Глобаль-
ная погрешность E оценивалась как максимум отклонений численного решения Xj от точного x(tj) для всех j = 0,1. N: E = max_j |х;- — x(tj)|, здесь N — общее количество вычисленных точек траектории решения. В эксперименте значения точного решения мы вычисляли с помощью метода Рунге-Кутты-Мерсона 5 порядка с шагом, достаточным для получения решения с точностью, требуемой для типа данных float. Далее в тексте под погрешностью мы будем подразумевать глобальную погрешность численного решения, вычисленную именно таким способом.
Рис. 2. Графики зависимости погрешности численного решения Е от выбранного шага интегрирования Л для метода Эйлера (1) и метода последовательных приближений при заданных значениях параметров метода К = 3 и различных т: т = 4 (2), т = 16 (3), т = 64 (4), т = 256 (5)
Для сравнения приведен график зависимости погрешности для метода Эйлера (рис. 2). Все графики приведены в логарифмической шкале (-^ Е показывает порядок погрешности, -^ h — порядок шага интегрирования). Везде в экспериментах мы использовали фиксированную длину шага, что не всегда эффективно при решении ОДУ. Однако это позволяет оценить точность и устойчивость метода в зависимости от выбранного шага.
Приведенные графики демонстрируют поведение погрешности численного решения вблизи границы области сходимости. Когда шаг интегрирования превышает граничное значение области сходимости, происходит быстрый рост погрешности. Обозначим эту величину за h . Так, для т =16 значение на границе области сходимости h «0,12 (-^ h
0,9), для т = 64 получили h « 0,016 (-^ h « 1,8), для т = 256 — к* « 0,002 (-^ к* « 2,7). Когда h Надоели баннеры? Вы всегда можете отключить рекламу.
Уравнение Навье-Стокса и симуляция жидкостей на CUDA
Привет, Хабр. В этой статье мы разберемся с уравнением Навье-Стокса для несжимаемой жидкости, численно его решим и сделаем красивую симуляцию, работающую за счет параллельного вычисления на CUDA. Основная цель — показать, как можно применить математику, лежащую в основе уравнения, на практике при решении задачи моделирования жидкостей и газов.

Уравнение Навье-Стокса для несжимаемой жидкости

Я думаю каждый хоть раз слышал об этом уравнении, некоторые, быть может, даже аналитически решали его частные случаи, но в общем виде эта задачи остается неразрешенной до сих пор. Само собой, мы не ставим в этой статье цель решить задачу тысячелетия, однако итеративный метод применить к ней мы все же можем. Но для начала, давайте разберемся с обозначениями в этой формуле.
Условно уравнение Навье-Стокса можно разделить на пять частей:
 — обозначает скорость изменения скорости жидкости в точке (его мы и будем считать для каждой частицы в нашей симуляции).
— обозначает скорость изменения скорости жидкости в точке (его мы и будем считать для каждой частицы в нашей симуляции).- — перемещение жидкости в пространстве.
- — давление, оказываемое на частицу (здесь — коэффициент плотности жидкости).
- — вязкость среды (чем она больше, тем сильнее жидкость сопротивляется силе, применяемой к ее части), — коэффициент вязкости).
- — внешние силы, которые мы применяем к жидкости (в нашем случае сила будет играть вполне конкретную роль — она будет отражать действия, совершаемые пользователем.
 — обозначает скорость изменения скорости жидкости в точке (его мы и будем считать для каждой частицы в нашей симуляции).
— обозначает скорость изменения скорости жидкости в точке (его мы и будем считать для каждой частицы в нашей симуляции). — перемещение жидкости в пространстве.
— перемещение жидкости в пространстве. — давление, оказываемое на частицу (здесь
— давление, оказываемое на частицу (здесь  — коэффициент плотности жидкости).
— коэффициент плотности жидкости). — вязкость среды (чем она больше, тем сильнее жидкость сопротивляется силе, применяемой к ее части),
— вязкость среды (чем она больше, тем сильнее жидкость сопротивляется силе, применяемой к ее части),  — коэффициент вязкости).
— коэффициент вязкости). — внешние силы, которые мы применяем к жидкости (в нашем случае сила будет играть вполне конкретную роль — она будет отражать действия, совершаемые пользователем.
— внешние силы, которые мы применяем к жидкости (в нашем случае сила будет играть вполне конкретную роль — она будет отражать действия, совершаемые пользователем.Также, так как мы будем рассматривать случай несжимаемой и однородной жидкости, мы имеем еще одно уравнение:  . Энергия в среде постоянна, никуда не уходит, ниоткуда не приходит.
. Энергия в среде постоянна, никуда не уходит, ниоткуда не приходит.
Будет неправильно обделить всех читателей, которые не знакомы с векторным анализом, поэтому заодно и бегло пройдемся по всем операторам, присутствующим в уравнении (однако, настоятельно рекомендую вспомнить, что такое производная, дифференциал и вектор, так как они лежат в основе всего того, о чем пойдет речь ниже).
Начнем мы с с оператора набла, представляющего из себя вот такой вектор (в нашем случае он будет двухкомпонентным, так как жидкость мы будет моделировать в двумерном пространстве):

Оператор набла представляет из себя векторный дифференциальный оператор и может быть применен как к скалярной функции, так и к векторной. В случае скаляра мы получаем градиент функции (вектор ее частных производных), а в случае вектора — сумму частых производных по осям. Главная особенность данного оператора в том, что через него можно выразить основные операции векторного анализа — grad (градиент), div (дивергенция), rot (ротор) и  (оператор Лапласа). Стоит сразу же отметить, что выражение
(оператор Лапласа). Стоит сразу же отметить, что выражение  не равносильно
не равносильно  — оператор набла не обладает коммутативностью.
— оператор набла не обладает коммутативностью.
Как мы увидим далее, эти выражения заметно упрощаются при переходе на дискретное пространство, в котором мы и будем проводить все вычисления, так что не пугайтесь, если на данный момент вам не очень понятно, что же со всем этим делать. Разбив задачу на несколько частей, мы последовательно решим каждую из них и представим все это в виде последовательного применения нескольких функций к нашей среде.
Численное решение уравнения Навье-Стокса
Чтобы представить нашу жидкость в программе, нам необходимо получить математическую репрезентацию состояния каждой частицы жидкости в произвольный момент времени. Самый удобный для этого метод — создать векторное поле частиц, хранящее их состояние, в виде координатной плоскости:
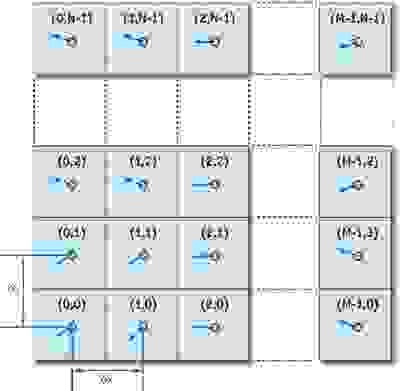
В каждой ячейке нашего двумерного массива мы будем хранить скорость частицы в момент времени  , а расстояние между частицами обозначим за
, а расстояние между частицами обозначим за  и
и  соответственно. В коде же нам будет достаточно изменять значение скорости каждую итерацию, решая набор из нескольких уравнений.
соответственно. В коде же нам будет достаточно изменять значение скорости каждую итерацию, решая набор из нескольких уравнений.
Теперь выразим градиент, дивергенцию и оператор Лапласа с учетом нашей координатной сетки (  — индексы в массиве,
— индексы в массиве,  — взятие соответствующих компонентов у вектора):
— взятие соответствующих компонентов у вектора):
| Оператор | Определение | Дискретный аналог |
| grad |  |  |
| div |  |  |
 |  |  |
| rot |  |  |
Мы можем еще сильнее упростить дискретные формулы векторных операторов, если положим, что  . Данное допущение не будет сильно сказываться на точности алгоритма, однако уменьшает количество операций на каждую итерацию, да и в целом делает выражения приятней взгляду.
. Данное допущение не будет сильно сказываться на точности алгоритма, однако уменьшает количество операций на каждую итерацию, да и в целом делает выражения приятней взгляду.
Перемещение частиц
Данные утверждения работают только в том случае, если мы можем найти ближайшие частицы относительно рассматриваемой на данный момент. Чтобы свести на нет все возможные издержки, связанные с поиском таковых, мы будет отслеживать не их перемещение, а то, откуда приходят частицы в начале итерации путем проекции траектории движения назад во времени (проще говоря, вычитать вектор скорости, помноженный на изменение времени, из текущей позиции). Используя этот прием для каждого элемента массива, мы будем точно уверены, что у любой частицы будут «соседи»:
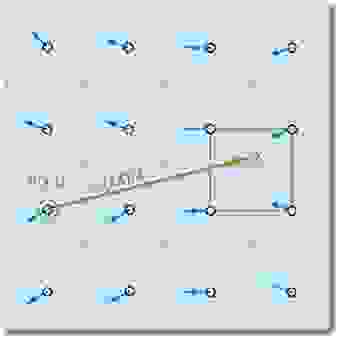
Положив, что  — элемент массива, хранящий состояния частицы, получаем следующую формулу для вычисления ее состояния через время
— элемент массива, хранящий состояния частицы, получаем следующую формулу для вычисления ее состояния через время  (мы полагаем, что все необходимые параметры в виде ускорения и давления уже рассчитаны):
(мы полагаем, что все необходимые параметры в виде ускорения и давления уже рассчитаны):

Заметим сразу же, что при достаточно малом и скорости мы можем так и не выйти за пределы ячейки, поэтому очень важно правильно подобрать ту силу импульса, которую пользователь будет придавать частицам.
Чтобы избежать потери точности в случае попадания проекции на границу клеток или в случае получения нецелых координат, мы будем проводить билинейную интерполяцию состояний четырех ближайших частиц и брать ее за истинное значение в точке. В принципе, такой метод практически не уменьшит точность симуляции, и вместе с тем он достаточно прост в реализации, так что его и будем использовать.
Вязкость

. В таком случае итеративное уравнение для скорости примет следующий вид:

Мы несколько преобразуем данное равенство, приведя его к виду  (стандартный вид системы линейных уравнений):
(стандартный вид системы линейных уравнений):

где  — единичная матрица. Такие преобразования нам необходимы, чтобы в последствии применить метод Якоби для решения нескольких схожих систем уравнений. Его мы также обсудим в дальнейшем.
— единичная матрица. Такие преобразования нам необходимы, чтобы в последствии применить метод Якоби для решения нескольких схожих систем уравнений. Его мы также обсудим в дальнейшем.
Внешние силы

Импульс-вектор легко посчитать как разность между предыдущей позицией мыши и текущей (если такая имелась), и здесь как раз-таки можно проявить креативность. Именно в этой части алгоритма мы можем внедрить добавление цветов в жидкость, ее подсветку и т.п. К внешним силам также можно отнести гравитацию и температуру, и хоть реализовать такие параметры несложно, в данной статье рассматривать их мы не будем.
Давление
Давление в уравнении Навье-Стокса — та сила, которая препятствует частицам заполнять все доступное им пространство после применения к ним какой-либо внешней силы. Сходу его расчет весьма затруднителен, однако нашу задачу можно значительно упростить, применив теорему разложения Гельмгольца.
Назовем  векторное поле, полученное после расчета перемещения, внешних сил и вязкости. Оно будет иметь ненулевую дивергенцию, что противоречит условию несжимаемости жидкости (
векторное поле, полученное после расчета перемещения, внешних сил и вязкости. Оно будет иметь ненулевую дивергенцию, что противоречит условию несжимаемости жидкости ( ), и чтобы это исправить, необходимо рассчитать давление. Согласно теореме разложения Гельмгольца, можно представить как сумму двух полей:
), и чтобы это исправить, необходимо рассчитать давление. Согласно теореме разложения Гельмгольца, можно представить как сумму двух полей:

где  — и есть искомое нами векторное поле с нулевой дивергенцией. Доказательство этого равенства в данной статье приводиться не будет, однако в конце вы сможете найти ссылку с подробным объяснением. Мы же можем применить оператор набла к обоим частям выражения, чтобы получить следующую формулу для расчета скалярного поля давления:
— и есть искомое нами векторное поле с нулевой дивергенцией. Доказательство этого равенства в данной статье приводиться не будет, однако в конце вы сможете найти ссылку с подробным объяснением. Мы же можем применить оператор набла к обоим частям выражения, чтобы получить следующую формулу для расчета скалярного поля давления:

Записанное выше выражение представляет из себя уравнение Пуассона для давления. Его мы также можем решить вышеупомянутым методом Якоби, и тем самым найти последнюю неизвестную переменную в уравнении Навье-Стокса. В принципе, системы линейных уравнений можно решать самыми разными и изощренными способами, но мы все же остановимся на самом простом из них, чтобы еще больше не нагружать данную статью.
Граничные и начальные условия
Любое дифференциальное уравнение, моделируемое на конечной области, требует правильно заданных начальных или граничных условий, иначе мы с очень большой вероятностью получим физически неверный результат. Граничные условия устанавливаются для контролирования поведения жидкости близ краев координатной сетки, а начальные условия задают параметры, которые имеют частицы в момент запуска программы.
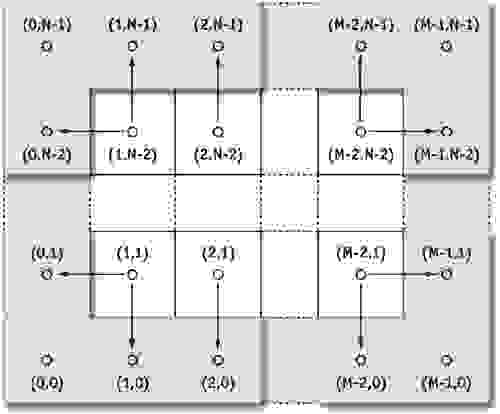
Начальные условия будут весьма простыми — изначально жидкость неподвижна (скорость частиц равна нулю), и давление также равно нулю. Граничные условия будут задаваться для скорости и давления приведенными формулами:


Тем самым, скорость частиц на краях будет противоположна скорости у краев (тем самым они будут отталкиваться от края), а давление равно значению непосредственно рядом с границей. Данные операции следует применить ко всем ограничивающим элементам массива (к примеру, есть размер сетки  , то алгоритм мы применим для клеток, отмеченных на рисунке синим):
, то алгоритм мы применим для клеток, отмеченных на рисунке синим):
Краситель

В формуле  отвечает за пополнение красителем области (возможно, в зависимости от того, куда нажмет пользователь),
отвечает за пополнение красителем области (возможно, в зависимости от того, куда нажмет пользователь),  непосредственно является количество красителя в точке, а
непосредственно является количество красителя в точке, а  — коэффициент диффузии. Решить его не составляет большого труда, так как вся основная работа по выводу формул уже проведена, и достаточно лишь сделает несколько подстановок. Краску можно реализовать в коде как цвет в формате RGB, и в таком случае задача сводится к операциям с несколькими вещественными величинами.
— коэффициент диффузии. Решить его не составляет большого труда, так как вся основная работа по выводу формул уже проведена, и достаточно лишь сделает несколько подстановок. Краску можно реализовать в коде как цвет в формате RGB, и в таком случае задача сводится к операциям с несколькими вещественными величинами.
Завихренность




 есть результат применения ротора к вектору скорости (его определение дано в начале статьи),
есть результат применения ротора к вектору скорости (его определение дано в начале статьи),  — градиент скалярного поля абсолютных значений .
— градиент скалярного поля абсолютных значений .  представляет нормализованный вектор , а
представляет нормализованный вектор , а  — константа, контролирующая, насколько большими будут завихренности в нашей жидкости.
— константа, контролирующая, насколько большими будут завихренности в нашей жидкости.
Метод Якоби для решения систем линейных уравнений

Для нас  — элементы массива, представляющие скалярное или векторное поле.
— элементы массива, представляющие скалярное или векторное поле.  — номер итерации, его мы можем регулировать, чтобы как увеличить точность расчета или наоборот уменьшить, и повысить производительность.
— номер итерации, его мы можем регулировать, чтобы как увеличить точность расчета или наоборот уменьшить, и повысить производительность.
Для расчет вязкости подставляем:  ,
,  ,
,  , здесь параметр
, здесь параметр  — сумма весов. Таким образом, нам необходимо хранить как минимум два векторных поля скоростей, чтобы независимо считать значения одного поля и записывать их в другое. В среднем, для расчета поля скорости методом Якоби необходимо провести 20-50 итераций, что весьма много, если бы мы выполняли вычисления на CPU.
— сумма весов. Таким образом, нам необходимо хранить как минимум два векторных поля скоростей, чтобы независимо считать значения одного поля и записывать их в другое. В среднем, для расчета поля скорости методом Якоби необходимо провести 20-50 итераций, что весьма много, если бы мы выполняли вычисления на CPU.
Для уравнения давления мы сделаем следующую подстановку:  ,
,  ,
,  ,
,  . В результате мы получим значение
. В результате мы получим значение  в точке. Но так как оно используется только для расчета градиента, вычитаемого из поля скорости, дополнительные преобразования можно не выполнять. Для поля давления лучше всего выполнять 40-80 итераций, потому что при меньших числах расхождение становится заметным.
в точке. Но так как оно используется только для расчета градиента, вычитаемого из поля скорости, дополнительные преобразования можно не выполнять. Для поля давления лучше всего выполнять 40-80 итераций, потому что при меньших числах расхождение становится заметным.
Реализация алгоритма
Реализовывать алгоритм мы будем на C++, также нам потребуется Cuda Toolkit (как его установить вы можете прочитать на сайте Nvidia), а также SFML. CUDA нам потребуется для распараллеливания алгоритма, а SFML будет использоваться только для создания окна и отображения картинки на экране (В принципе, это вполне можно написать на OpenGL, но разница в производительности будет несущественна, а вот код увеличится еще строк на 200).
Cuda Toolkit
Сначала мы немного поговорим о том, как использовать Cuda Toolkit для распараллеливания задач. Более подробный гайд предоставляется самой Nvidia, поэтому здесь мы ограничимся только самым необходимым. Также предполагается, что вы смогли установить компилятор, и у вас получилось собрать тестовый проект без ошибок.
Чтобы создать функцию, исполняющуюся на GPU, для начала необходимо объявить, сколько ядер мы хотим использовать, и сколько блоков ядер нужно выделить. Для этого Cuda Toolkit предоставляет нам специальную структуру — dim3, по умолчанию устанавливающую все свои значения x, y, z равными 1. Указывая ее как аргумент при вызове функции, мы можем управлять количеством выделяемых ядер. Так как работаем мы с двумерным массивом, то в конструкторе необходимо установить только два поля: x и y:
где size_x и size_y — размер обрабатываемого массива. Сигнатура и вызов функции выглядят следующим образом (тройные угловые скобки обрабатываются компилятором Cuda):
В самой функции можно восстановить индексы двумерного массива через номер блока и номер ядра в этом блоке по следующей формуле:
Следует отметить, что функция, исполняемая на видеокарте, должна быть обязательно помечена тегом __global__ , а также возвращать void, поэтому чаще всего результаты вычислений записываются в передаваемый как аргумент и заранее выделенный в памяти видеокарты массив.
За освобождение и выделение памяти на видеокарте отвечают функции CudaMalloc и CudaFree. Мы можем оперировать указателями на область памяти, которые они возвращают, но получить доступ к данным из основного кода не можем. Самый простой способ вернуть результаты вычислений — воспользоваться cudaMemcpy, схожей со стандартным memcpy, но умеющей копировать данные с видеокарты в основную память и наоборот.
SFML и рендер окна
Вооружившись всеми этими знаниями, мы наконец можем перейти к непосредственному написанию кода. Для начала давайте создадим файл main.cpp и разместим туда весь вспомогательный код для рендера окна:
строка в начале функции main
создает изображение формата RGBA в виде одномерного массива с константной длиной. Его мы будем передавать вместе с другими параметрами (позиция мыши, разница между кадрами) в функцию computeField. Последняя, как и несколько других функций, объявлены в kernel.cu и вызывают код, исполняемый на GPU. Документацию по любой из функций вы можете найти на сайте SFML, в коде файла не происходит ничего сверхинтересного, поэтому мы не будем надолго на нем останавливаться.
Вычисления на GPU
Чтобы начать писать код под gpu, для начала создадим файл kernel.cu и определим в нем несколько вспомогательных классов: Color3f, Vec2, Config, SystemConfig:
Атрибут __host__ перед именем метода означает, что код может исполнятся на CPU, __device__ , наоборот, обязует компилятор собирать код под GPU. В коде объявляются примитивы для работы с двухкомпонентными векторами, цветом, конфиги с параметрами, которые можно менять в рантайме, а также несколько статических указателей на массивы, которые мы будем использовать как буферы для вычислений.
cudaInit и cudaExit также определяеются достаточно тривиально:
В функции инициализации мы выделяем память под двумерные массивы, задаем массив цветов, которые мы будем использовать для раскраски жидкости, а также устанавливаем в конфиг значения по умолчанию. В cudaExit мы просто освобождаем все буферы. Как бы это парадоксально не звучало, для хранения двумерных массивов выгоднее всего использовать одномерные, обращение к которым будет осуществляться таким выражением:
Начнем реализацию непосредственного алгоритма с функции перемещения частиц. В advect передаются поля oldField и newField (то поле, откуда берутся данные и то, куда они записываются), размер массива, а также дельта времени и коэффициент плотности (используется для того, чтобы ускорить растворение красителя в жидкости и сделать среду не сильно чувствительной к действиям пользователя). Функция билинейной интерполяции реализована классическим образом через вычисление промежуточных значений:
Функцию диффузии вязкости было решено разделить на несколько частей: из главного кода вызывается computeDiffusion, которая вызывает diffuse и computeColor заранее указанное число раз, а затем меняет местами массив, откуда мы берем данные, и тот, куда мы их записываем. Это самый простой способ реализовать параллельную обработку данных, но мы расходует в два раза больше памяти.
Обе функции вызывают вариации метода Якоби. В теле jacobiColor и jacobiVelocity сразу же идет проверка, что текущие элементы не находятся на границе — в этом случае мы должны установить их в соответствии с формулами, изложенными в разделе Граничные и начальные условия.
Применение внешней силы реализовано через единственную функцию — applyForce, принимающую как аргументы позицию мыши, цвет красителя, а также радиус действия. С ее помощью мы можем придать скорость частицам, а также красить их. братная экспонента позволяет сделать область не слишком резкой, и при этом достаточно четкой в указанном радиусе.
Расчет завихренности представляет из себя уже более сложный процесс, поэтому его мы реализуем в computeVorticity и applyVorticity, заметим также, что для них необходимо определить два таких векторных оператора, как curl (ротор) и absGradient (градиент абсолютных значений поля). Чтобы задать дополнительные эффекты вихря, мы умножаем  компоненту вектора градиента на
компоненту вектора градиента на  , а затем нормализируем его, разделив на длину (не забыв при этом проверить, что вектор ненулевой):
, а затем нормализируем его, разделив на длину (не забыв при этом проверить, что вектор ненулевой):
Следующим этапом алгоритма будет вычисление скалярного поля давления и его проекция на поле скорости. Для этого нам потребуется реализовать 4 функции: divergency, которая будет считать дивергенцию скорости, jacobiPressure, реализующую метод Якоби для давления, и computePressure c computePressureImpl, проводящие итеративные вычисления поля:
Проекция умещается в две небольшие функции — project и вызываемой ей gradient для давления. Это, можно сказать, последний этап нашего алгоритма симуляции:
После проекции мы смело можем перейти к отрисовке изображения в буфер и различным пост-эффектам. В функции paint выполняется копирование цветов из поля частиц в массив RGBA. Также была реализована функция applyBloom, которая подсвечивает жидкость, когда на нее наведен курсор и нажата клавиша мыши. Из опыта, такой прием делает картину более приятной и интересной для глаз пользователя, но он вовсе не обязателен.
В постобработке также можно подсвечивать места, в которых жидкость имеет наибольшую скорость, менять цвет в зависимости от вектора движения, добавлять различные эффекты и прочее, но в нашем случае мы ограничимся своеобразным минимумом, ведь даже с ним изображения получаются весьма завораживающими (особенно в динамике):
И под конец у нас осталась одна главная функция, которую мы вызываем из main.cpp — computeField. Она сцепляет воедино все кусочки алгоритма, вызывая код на видеокарте, а также копирует данные с gpu на cpu. В ней же находится и расчет вектора импульса и выбор цвета красителя, которые мы передаем в applyForce:
Заключение
В этой статье мы разобрали численный алгоритм решения уравнения Навье-Стокса и написали небольшую программу-симуляцию для несжимаемой жидкости. Быть может мы и не разобрались во всех тонкостях, но я надеюсь, что материал оказался для вас интересным и полезным, и как минимум послужил хорошим введением в область моделирования жидкостей.
Как автор данной статьи, я буду искренне признателен любым комментариям и дополнениям, и постараюсь ответить на все возникшие у вас вопросы под этим постом.
Дополнительный материал
Весь исходный код, приведенный в данной статье, вы можете найти в моем Github-репозитории. Любые предложения по улучшению приветствуются.
Оригинальный материал, послуживший основой для данной статьи, вы можете прочесть на официальном сайте Nvidia (англ). В нем также представлены примеры реализации частей алгоритма на языке шейдеров:
developer.download.nvidia.com/books/HTML/gpugems/gpugems_ch38.html
Доказательство теоремы разложения Гельмгольца и огромное количество дополнительного материала про механику жидкостей можно найти в данной книге (англ, см. раздел 1.2):
Chorin, A.J., and J.E. Marsden. 1993. A Mathematical Introduction to Fluid Mechanics. 3rd ed. Springer.
Канал одного англоязычного ютубера, делающего качественный контент, связанной с математикой, и решением дифференциальных уравнений в частности (англ). Очень наглядные ролики, помогающие понять суть многих вещей в математике и физике:
3Blue1Brown — YouTube
Differential Equations (3Blue1Brown)
Также выражаю благодарность WhiteBlackGoose за помощь в подготовке материала для статьи.
И под конец небольшой бонус — несколько красивых скриншотов, снятых в программе:

Прямой поток (дефолтные настройки)

Водоворот (большой радиус в applyForce)

Волна (высокая завихренность + диффузия)
Также по многочисленным просьбам добавил видео с работой симуляции:
Решение дифф. уравнений на CUDA на примере задач аэро-гидродинамики. zЛектор: yСахарных Н.А. (ВМиК МГУ, NVidia)Сахарных Н.А. (ВМиК МГУ, NVidia) — презентация
Презентация была опубликована 8 лет назад пользователемГеннадий Важенин
Похожие презентации
Презентация на тему: » Решение дифф. уравнений на CUDA на примере задач аэро-гидродинамики. zЛектор: yСахарных Н.А. (ВМиК МГУ, NVidia)Сахарных Н.А. (ВМиК МГУ, NVidia)» — Транскрипт:
1 Решение дифф. уравнений на CUDA на примере задач аэро-гидродинамики. zЛектор: yСахарных Н.А. (ВМиК МГУ, NVidia)Сахарных Н.А. (ВМиК МГУ, NVidia)
2 План zВведение и постановка задачи zОсновные уравнения zЧисленный метод расщепления zОсобенности реализации zРезультаты и выводы
3 Введение zВычислительные задачи аэро- гидродинамики yМоделирование турбулентных течений zВМиК МГУ, кафедра мат. физики yПасконов В.М., Березин С.Б.
4 Турбулентность Моделирование турбулентности Прямое численное моделирование (DNS) Моделирование крупномасштабных вихрей (LES) Осредненные уравнения Навье-Стокса (RANS) все масштабы турбулентности очень затратный
5 Постановка задачи zТечение вязкой несжимаемой жидкости в 3D канале yКанал заполнен и находится в однородной среде yПроизвольные начальные и граничные условия yНеизвестные величины – скорость и температура
6 Основные уравнения zПолная система уравнений Навье- Стокса в безразмерных величинах yУравнение неразрывности yУравнения движения (Навье-Стокса) yУравнение энергии
7 Обозначения Плотность Скорость Температура Давление zУравнение состояния – газовая постоянная
8 Уравнение неразрывности zИспользуется при выводе остальных уравнений (движения и энергии) zПроверка точности текущего решения
9 Уравнения Навье-Стокса zВторой закон Ньютона: Вязкая жидкость: f – массовые силы (сила тяжести) – тензор вязких напряжений p – давление Невязкая жидкость:
10 Безразмерные уравнения zПараметры подобия yЧисло Рейнольдса yЧисло Прандтля zУравнение состояния для идеального газа/жидкости: – характерная скорость, размер – динамическая вязкость среды – коэффициент теплопроводности – удельная теплоемкость
11 Уравнения движения zБезразмерная форма: yНе рассматриваем массовые силы yУравнение состояния
12 Уравнение энергии zПервый закон термодинамики для объема V: zДиссипативная функция:
13 Финальные уравнения z4 нелинейных уравнения z4 неизвестные величины: yКомпоненты скорости: u, v, w yТемпература: T
14 Численный метод zРасщепление по координатам XYZ
15 Уравнение диффузии z3 дробных шага – X, Y, Z zНеявная конечно-разностная схема
16 Уравнения Навье-Стокса zУравнение для X-компоненты скорости y+ итерации по нелинейности X Y Z
17 Шаг по времени (n-1) time step Splitting by X Splitting by Y Splitting by Z Updating non-linear parameters Global iterations (n) time step (n+1) time step
18 Дробный шаг zЛинейное PDEs N time layer u: x-velocityv: y-velocityw: z-velocityT: temperature N + 1 time layer Sweep Solves many tridiagonal systems independently Next layer Previous layer
19 Дробный шаг zНелинейное PDEs N time layer u: x-velocityv: y-velocityw: z-velocityT: temperature N + ½ time layer N + 1 time layer Update Copy Sweep Solves many tridiagonal systems independently Local iterations Next layer Previous layer
20 Стадии алгоритма zРешение большого количества трехдиагональных СЛАУ zВычисление диссипации в каждой ячейке сетки zОбновление нелинейных параметров
21 Особенности метода zБольшой объем обрабатываемых данных zВысокая арифметическая интенсивность zЛегко параллелится
22 Реализация на CUDA zВсе данные хранятся в памяти GPU y4 скалярных 3D массива для каждой переменной (u, v, w, T) y3 дополнительных 3D массива z
1GB для сетки 192^3 в double
23 Решение трехдиагональных СЛАУ zКаждая нить решает ровно одну трехдиагональную СЛАУ yНа каждом шаге N^2 независимых систем Расщепление XРасщепление YРасщепление Z
24 Метод прогонки zНеобходимо 2 дополнительных массива yхранение: локальная память zПрямой ход yвычисление a[i], b[i] zОбратный ход yx[i] = a[i+1] * x[i+1] + b[i+1]
25 Проблемы реализации zКаждая нить последовательно читает и пишет столбец 3D массива yКоэффициенты и правая часть zY, Z – прогонки coalesced zX – прогонка uncoalesced!
26 Оптимизация прогонки zX – прогонка yТранспонируем входные массивы и запускаем Y-прогонку общая производительность всех прогонок
27 Расчет диссипации zРасчет частных производных по трем направлениям yЛокальный доступ к памяти zКаждая нить обрабатывает столбец данных yПереиспользование расчитанных производных zИспользование разделяемой памяти (?)
28 Оптимизация диссипации zРефакторинг кода yПредварительный расчет некоторых констант, избавление от лишних if z C++ шаблоны для X, Y, Z-диссипации yУменьшение числа регистров, нет лишних обращений к памяти
29 Нелинейные итерации zНеобходимо посчитать полусумму двух 3D массивов zКаждая нить считает сразу для столбца данных – N^2 нитей yВсе чтения/записи coalesced zОптимальный выбор размера блока z80% от пиковой пропускной способности на Tesla C1060
30 Пример кода // boundary conditions switch (dir) < case X: case X_as_Y: bc_x0(…); break; case Y: bc_y0(…); break; case Z: bc_z0(…); break; >a[1] = — c1 / c2; u_next[base_idx] = f_i / c2; // forward trace of sweep int idx = base_idx; int idx_prev; for (int k = 1; k
31 Тест производительности zТестовые данные yСетка 128^3, 192^3 y8 нелинейных итераций zСравнение CPU и GPU yАбсолютное время работы
32 Тест – float time steps/sec 20x 7x 9x
33 Тест – double time steps/sec 10x 4x 5x
34 Тест – float time steps/sec 28x 8x 11x
35 Тест – double time steps/sec 13x 4x 5x
36 Визуализация Векторное поле скоростей uv w T Срез вдоль Х
37 Выводы zВысокая эффективность Tesla в задачах аэро-гидродинамики zПрограммная модель CUDA – удобное средство утилизации ресурсов GPU zПрименение GPU открывает новые возможности для исследования
http://habr.com/ru/post/470742/
http://www.myshared.ru/slide/649270/