Одномерное уравнение теплопроводности. Буй Ван Шань. 6 курс
Содержание
Постановка задачи [ править ]

Решается однородное уравнение теплопроводности на промежутке [math]\left[a\ldots b\right][/math]
С граничными условиями
[math] \begin
и начальным распределением температуры
[math]U(x,0) = U0(x)[/math]
- Где : [math]f(x,t), U0(x), M1(t), M2(t)[/math] — Известные функции
Реализация [ править ]
Конечно-разностная схема [ править ]
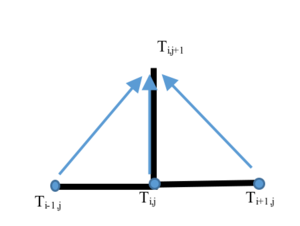
Задача содержит производную по времени первого порядка и производную по пространственной координате второго порядка. Запишем исходное уравнение в виде
Введем равномерную сетку [math]0 \lt x_i \lt L[/math] с шагом разбиения [math]Δx[/math] . Шаг по времени назовем [math]Δt[/math] Построим явную конечно-разностную схему:
Где, [math]U_i[/math] — значение температуры в [math]i[/math] -ом узле.
- Условие сходимости явной схемы: [math]dt\lt dx^2/2[/math] , где dt — шаг по времени, dx — шаг по координате
Применение технологии MPI [ править ]
Разветвление для уравнения теплопроводности осуществляется путем разбиением отрезка интегрирования на некоторые интервалы. На каждом интервале, процесс интегрирования осуществляется отдельным процессом, при этом в связи с использованием явной схемы, соседние процессы должны обменивать крайними значениями, получены на предыдущем шаге, для выполнения следующего шага.
Технология MPI решения стационарного уравнения теплопроводности Текст научной статьи по специальности « Математика»
Аннотация научной статьи по математике, автор научной работы — Миронов В. В., Оверин Н. А.
Параллельные вычисления бурно развивающаяся область современной науки, активно проникающая во все новые и новые стороны нашей жизни. Генетические исследования, прогноз климатических изменений, синтез новых материалов, астрономия, распознавание изображений и многие другие направления деятельности человека просто немыслимы без использования параллельных информационных технологий. Долгое время параллельными вычислениями могли заниматься только разработчики программного обеспечения для серверных машин, суперкомпьютеров и кластеров. Но времена меняются и теперь даже в мобильных телефонах стоят процессоры с несколькими ядрами. В качестве объекта работы выбрана модельная задача, описываемая стационарным уравнением теплопроводности. Предложены два варианта распараллеливания алгоритма решения задачи, описываемой названным уравнением.
Похожие темы научных работ по математике , автор научной работы — Миронов В. В., Оверин Н. А.
Tehnology of MPI of the solution of the stationary equation of heat conductivity
In this work developed two parallel algorithms for finding solutions of the stationary heat conduction equation.
Текст научной работы на тему «Технология MPI решения стационарного уравнения теплопроводности»
Вестник Сыктывкарского университета. Сер. 1. Вып. 18.2013
ТЕХНОЛОГИЯ MPI РЕШЕНИЯ СТАЦИОНАРНОГО УРАВНЕНИЯ ТЕПЛОПРОВОДНОСТИ
Миронов В.В., Оверин H.A.
Параллельные вычисления — бурно развивающаяся область современной науки, активно проникающая во все новые и новые стороны нашей жизни. Генетические исследования, прогноз климатических изменений, синтез новых материалов, астрономия, распознавание изображений и многие другие направления деятельности человека просто немыслимы без использования параллельных информационных технологий.
Долгое время параллельными вычислениями могли заниматься только разработчики программного обеспечения для серверных машин, суперкомпьютеров и кластеров. Но времена меняются и теперь даже в мобильных телефонах стоят процессоры с несколькими ядрами.
В качестве объекта работы выбрана модельная задача, описываемая стационарным уравнением теплопроводности. Предложены два варианта распараллеливания алгоритма решения задачи, описываемой названным уравнением.
1. Постановка задачи
Целью работы является разработка алгоритмов решения стационарного уравнения теплопроводности с использованием параллельных вычислений. Из цели работы вытекают следующие задачи:
1) Постановка задачи стационарного уравнения теплопроводности и разработка численного метода решения уравнения теплопроводности с использованием методов конечных разностей и простых итераций;
2) Модификация алгоритма численного решения уравнения теплопроводности для возможности распараллеливания на несколько процесСОВ!
© Миронов В.В., Оверин H.A., 2013.
3) Реализация параллельного алгоритма численного решения уравнения теплопроводности и анализ эффективности параллельных алгоритмов.
Стационарное двумерное уравнение теплопроводности описывает распространение тепла в пластине, когда температура установилась. Уравнение имеет вид:
Здесь и = п(х, у) функция, описывающая распределение температуры внутри пластины, / = /(х, у) — поток тепла внутри пластины; А = д2/дх2 + д2/ду2 — оператор Лапласа; (х, у) Е П = [0, а] х [0, Ь]; а
формул конечных разностей и метода простой итерации описывается следующеей формулой [1]:
г = 1..Ы — Е 1..М — 1. (1.3)
В формуле (1.3) приняты следующие обозначения: Ы, М — количества узловых точек на отрезках [0, а], [0, Ь] соответствен но, г, ] — номера узловых точек, к — шаг на сетке (считается, что шаг по х равен шагу по у), к — номер итерации.
грешность вычислении Нс1 сетке не станет меньше нэлеред зэд&ннои величины £
ЕЕП? — пЩ Надоели баннеры? Вы всегда можете отключить рекламу.
Метод геометрического параллелелизма и еще немного про MPI
Постановка задачи
Двумерное уравнение теплопроводности задается уравнением: 
а также начальными условиями: 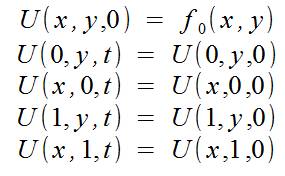
Также учитываем, что мы просчитываем ограниченную область пространства: 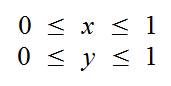
Итогом наших вычислений должен быть двумерный массив, содержащий значения функции U в узлах для некоторого значения времени. Можно решить уравнение аналитически, но это не наш вариант, и поэтому будем решать эту задачу численным методом. Для численного решения сделаем дискретизацию по времени, и получим координатную сетку в пространстве, а по времени получим набор «слоев». Для расчета будем использовать схему «крест». 
Если не вдаваться в подробности этой схемы, то по значению во всех точках «креста» на некотором «временном слое» получим значение в центральной точке на «следующем временном слое». Причем шаги по времени и координатам должны быть согласованны: 
(здесь и далее сетка фиксированная и шаги по пространственным координатам равны h)
Для экономии памяти можно хранить только две сетки по X и Y, одну для текущего временного слоя и для следующего временного слоя. В таком случае после рассчета следующего временного слоя этот слой становится текущим, а в массив прошлого слоя записываются значения следующего временного слоя.
Метод геометрического параллелелизма
Метод геометрического параллелелизма используется для задач в которых можно выделить некоторую геометрическую закономерность и использовать ее для разделения работы между процессорами. В этой задаче сетка для ограниченного пространства можно изобразить как: 
Параллелелизм в этом случае прослеживается довольно хорошо и можно разделить массив на несколько, и каждый новый отдать на рассчет своему исполнителю. 
Вообще-то можно разделить массив и на горизонтальные полосы, принципиальных различий для метода это не внесет, а про различия в реализации скажу позже. Таким образом каждый исполнитель будет считать только свой участок массива.
Подводные камни
Если вернуться к разностной схеме, по которой будем производить рассчет, то становится ясно, что это еще не конец. Из схемы видно, что для рассчета любого элемента сетки нам необходимо знать элементы сбоку от него на предыдущем слое. Это означает, что крайний слой пространственной сетки просчитать не сможем (так как не хватает данных), но если взглянуть на граничные условия, то видно что крайние элементы известны из условий. Но появляется проблема расчета элементов на границе областей исполнителей. Ясно, что придется в процессе пересылать данные между соседними исполнителями. Это можно сделать в виде цикла, который передает по элементу:
(подробнее про передачу по элементам можно прочитать в статьях, упомянутых в начале)
Этот способ не эффективен, поскольку придется устанавливать много соединений(это занимает большое время). Наши потребности может удовлетворить создание пользовательского типа данных. Кроме создания пользовательских структур, MPI может предложить нам несколько видов «масок» для данных: MPI_Type_contiguous и MPI_Type_vector. Первый из них создает тип, описывающий несколько элементов, подряд расположенных в памяти, а второй позволяет создать «шаблон» по которому из последовательно расположенных в памяти элементов выбираются «нужные» элементы, потом пропускаются «ненужные» и повторяется выбор нужных. Их количество фиксированное.
Если отправить этот тип, а в качестве *buf указать начало массива, то получится:
+ 0 0
+ 0 0
+ 0 0
Если указать как *buf второй элемент массива, то получим:
0 + 0
0 + 0
0 + 0
Так можно передать (и принять) только один столбец массива, причем за один вызов MPI_SEND:
Если расположить зоны исполнителей горизонтально, то можно использовать MPI_Type_contiguous или в MPI_Send указывать необходимое число элементов, но это, на мой взгляд, красивее.
Теперь надо понять в каком порядке пересылать эти столбцы. Самый очевидный: пусть исполнители по очереди передают нужный столбец нужному получателю. Тогда получим следующую картину: 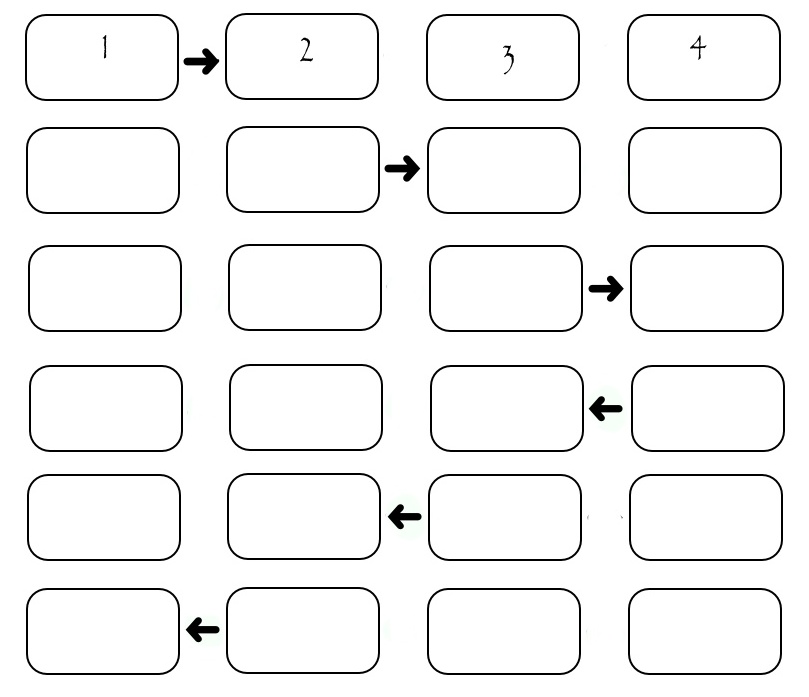
Хоть иллюстрация показывает обмен только между четырьмя исполнителями, можно посчитать, что если на одну передачу затрачивается некоторое SEND_TIME, то для передачи всех столбцов необходимо (2*N-2)*SEND_TIME. Видно, что во время передачи каждого столбца «работают» только два исполнителя, а остальные простаивают. Это не хорошо. Рассмотрим немного измененную схему: в ней исполнители разделены по «четности» их номера. Сначала все четные передают столбец исполнителю с большим номером, потом все четные передают столбец исполнителю с меньшим номером, потом аналогичным образом поступают исполнители с нечетными номерами. Конечно все пересылки происходят только при наличии того, кому пересылать.
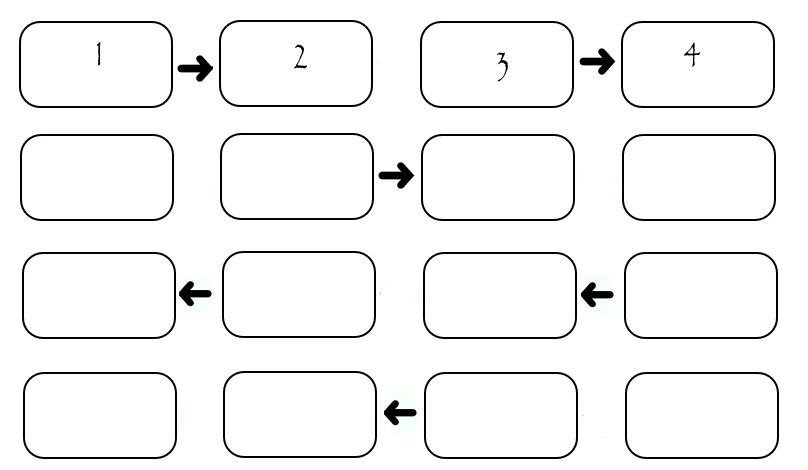
В данном случае передача занимает ровно 4*SEND_TIME вне зависимости от количества исполнителей. На системах с множеством исполнителей это несет в себе значительное превосходство.
(На рисунках про передачу присутствует некоторая ложь: номера исполнителей начинаются с нуля, как в массиве, а на рисунках они пронумерованы в «обычном» порядке: начиная с первого. Т.е. отняв единицу от номера на рисунке получим его номер в программе)
http://cyberleninka.ru/article/n/tehnologiya-mpi-resheniya-statsionarnogo-uravneniya-teploprovodnosti
http://habr.com/ru/post/151744/