Об авторегрессионном оценивании спектральной плотности стационарного сигнала
Методы спектрального оценивания стационарных случайных процессов, основанные на быстром преобразовании Фурье (БПФ), хорошо известны и широко применяются в инженерной практике. К их недостаткам следует отнести, в частности, высокую дисперсию (низкую точность) оценки при недостаточно длительном интервале наблюдения за процессом, что визуально обычно проявляется в сильной «изрезанности» графика спектральной плотности мощности(СПМ). Одним из альтернативных методов спектрального оценивания является авторегрессионный метод, рассмотренный на примере ниже, который в инженерной практике известен гораздо меньше. Метод во многих случаях позволяет сравнительно просто получить гораздо более качественную оценку СПМ (рис.1), а иногда и более глубокие сведения об исследуемом случайном процессе.
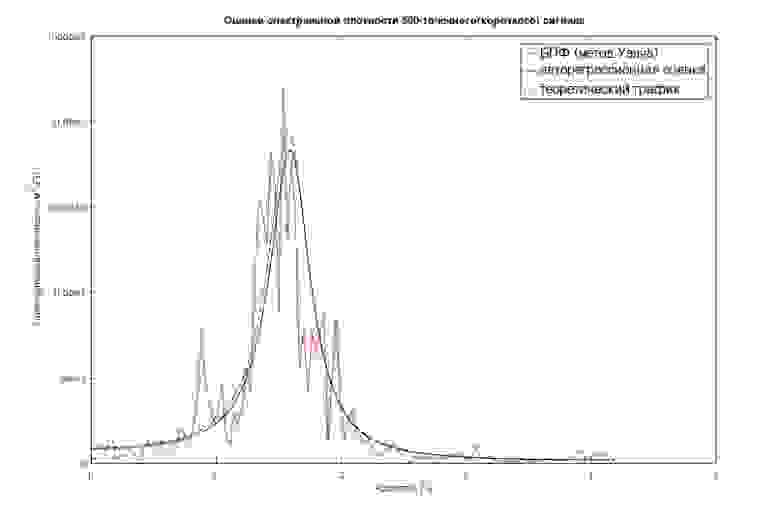
Рис.1 Классическая и авторегрессионная оценка СПМ «короткого» процесса
Для демонстрационных целей был синтезирован дискретно-временной сигнал (последовательность) x[i]. Сигнал смоделирован при помощи ARMA-модели (цифрового фильтра), имитирующей свойства механической системы (1) — перемещение материальной точки x(t) в «одномассовом» осцилляторе с параметрами m=1 кг, c= 100 Н/м, k=2,5 кг/с, и силовым возмущением — гауссовым «белым»(с учетом дискретизации) шумом f(t) с дисперсией 1 Н 2 , интервал дискретизации по времени Δt=0,12 с.
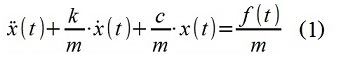
Построена модель (2). Способ построения модели уже рассматривался ранее здесь .
x[i] — 0.6388· x[i-1] + 0.7408· x[i-2] = 0.009667·f[i-1] (2)
С помощью (2) синтезирована последовательность в 50 тыс. отсчетов, для чего использован генератор нормально-распределенной случайной величины randn( ) общеизвестной программной среды.
После завершения моделирования процесса x[i], количественные параметры модели (2) предполагаются неизвестными — для исследования доступен только сам процесс и, в какой-то мере, сведения о свойствах модели в самых общих чертах.
Было проведено спектральное оценивание 50000-точечной последовательности методом Уэлча, размер сегмента принят равным 256 отсчетам, применено окно Хэмминга и 60% перекрытие сегментов. Среднеквадратичное отклонение такой оценки, исходя из того, что последовательность имеет длину около 200 неперекрывающихся сегментов, может быть примерно оценено, как
Далее, предполагая, что в реальных условиях в эксперименте для исследования доступна гораздо менее длинная последовательность, проведены исследования только по первым 500 отсчетам этого сигнала.
Получена оценка методом Уэлча с теми же параметрами. СКО такой оценки
70%, заметна очень сильная «изрезанность» графика (рис.2).
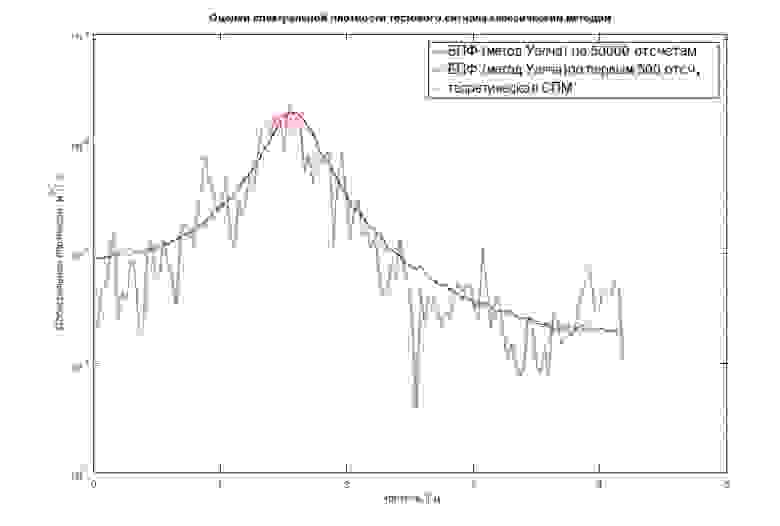
Рис.2 Оценивание СПМ «длинного» и «короткого» процессов классическими методом
Исходя из того, что примерный вид функции (графика) СПМ процесса нам известен (например, исходя из известной физической природы процесса — одномассовый осциллятор под белым шумом, либо из оценивания аналогичных процессов, для которых доступны более длинные реализации), принято решение об оценивании с помощью модели авторегрессии второго порядка (AR(2), или =ARMA(2,0)).
Определение порядка модели — весьма важный момент, ошибка в порядке может повлечь очень грубые ошибки в результатах оценивания. Существуют методы, здесь пока не рассматриваемые, помогающие в определении порядка модели на основании только самого анализируемого процесса.
Оценивание параметров модели поизведено с помощью известных уравнений Юла-Уолкера для авторегрессионного процесса (несущественно модифицированных с целью некоторого упрощения структуры скрипта ):
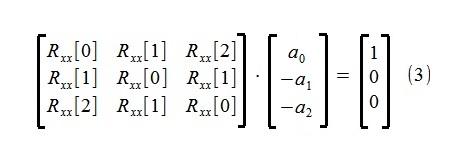
Как видно из уравнений, для определения параметров понадобятся только три первых члена авторегрессионной последовательности Rxx[0], Rxx[1], Rxx[2], которые и были оценены по исходной 500-точечной последовательности x[i] корелограммным методом, СКО такой оценки
(Кстати, видно, что «минусы» перед a1, a2 2и т.д, крайне неудобны. Они и появились-то из-за преимущественно «предсказательного» использования ARMA-моделей в экономике, в более ранних «инженерных» источниках их нет. Уже сомневаюсь, что надо было здесь использовать такое понимание AR-коэффициентов.)
Корреляционная матрица в (3) на практике всегда имеет строгое диагональное преобладание | Rxx[0] | >| Rxx[i] |, в том числе по причине присутствия шумов наблюдения, вследствие чего трудностей с ее обращением (нахождением решения(3)) не возникает.
(Для пояснения вопроса о величине статистической ошибки моделирования интересно упомянуть, например, оценку Rxx[0] =2.2606e-04 м 2 , полученную по 500 отсчетам, в сравнении с полученными корелограммной оценкой дисперсии по 50000 отсчетам, = 2.4238e-04 м 2 и оценкой по подынтегральной площади СПМ, полученной методом Уэлча по 50000 отсчетам (рис.2), = 2.4232e-04 м 2 )
После подстановки найденных оценок Rxx[i] имеем:

Определены следующие параметры модели a0=11325.9; a1=7090.1; a2=-8411.5; Как видно из (3), дисперсией гипотетического вхоящего белого шума здесь задались =1, определив вместо нее коэффициент усиления a0. Авторегрессионная оценка СПМ построена путем преобразования Фурье над последовательностью коэффициентов a0, a1, a2:
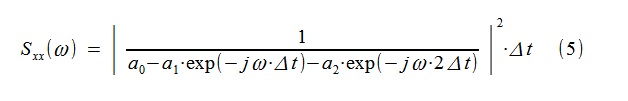
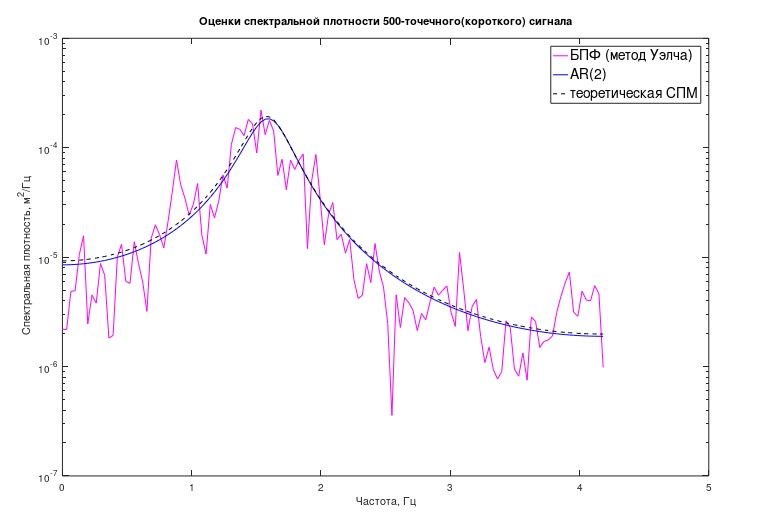
Рис.3 Классическая и авторегрессионная оценка СПМ «короткого» процесса
Таким же образом, по выражению, аналогичному (5), был ранее построен и «теоретический» график СПМ, только коэффициенты модели там, естественно, были взяты иные (из (2)).
Из графика видно, что AR-оценка СПМ получилась весьма близка к теоретически ожидаемой. Помимо графика, есть возможность попытаться оценить некоторые аналитические характеристики процесса и связанной с ним механической системы. В данном случае это «полюса» модели, численно характеризующие частоты «резонансных» пиков модели и связанные с ними «добротности».
Из (5) находим соотношение для поиска разрывов передаточной функции нашей модели, используя преобразование Лапласа (заменяя jω на λ=-ε+ jω):
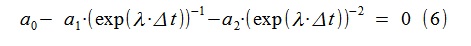
Для полученной AR- модели таким способом вычислены λ1,2= -1.5427 ± j· 10.1514, что весьма близко к исходной модели, использованной для генерации процесса
λ1,2теор=-1.2500 ± j · 9.9216 (т.е положения резонансного пика соответственно, 1,615 Гц (в теории) и 1,579 Гц (определено)).
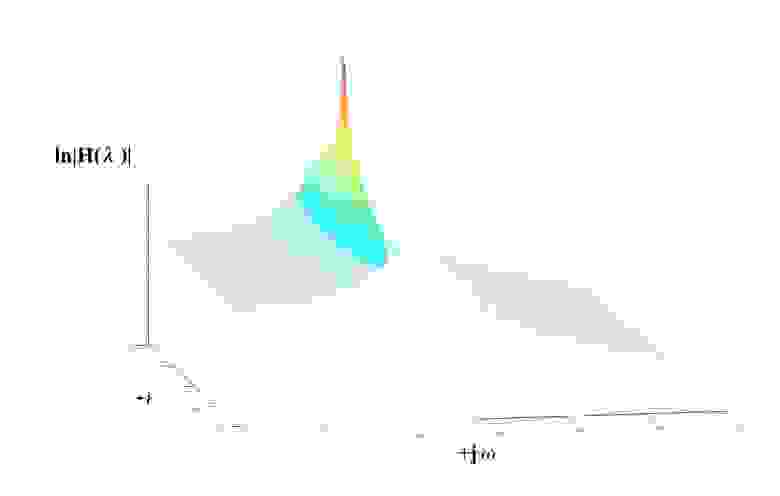
Рис.4 О понятии «полюсов»
Несколько замечаний и рекомендаций в заключение.
- «Избыточный» (слишком большой) порядок AR-модели обычно гораздо менее опасен, чем недостаточный, с точки зрения риска получения оценки СПМ с грубыми ошибками.
- Как правило, AR-моделирование позволяет довольно точно определить резонансные частоты jωk и гораздо мене точно — ширины соответствующих им «пиков» -εk
- ARMA — модель может получиться гораздо меньшего порядка (размера), чем AR-модель, к чему вроде бы следует стремиться для повышения точности модели, по мнению многих источников. Однако оценивание MA-части модели гораздо более затруднительно и может вообще включать в себя первым этапом получение AR-модели большого порядка с целью ее дальнейшего преобразования в MA-часть. В связи с этим источниками высказывается также альтернативное мнение о целесообразности применения для целей спектрального оценивания именно AR-моделей, пусть и большего порядка.
- Для очень коротких, а также для нестационарных процессов вместо матрицы оценок автокорреляционной функции в (3) обычно используют матрицу ковариаций.
- Для подробного изучения вопроса авторегрессионного спктрального оценивания можно рекомендовать С.Л. Марпл-мл. «Цифровой спектральный анализ и его приложения», М., Мир, 1990
Система уравнений юла уолкера служит для
До недавнего времени (середины 80-х годов прошлого века) существовало несколько общепризнанных методов прогнозирования временных рядов:
- Эконометрические
- Регрессионные
- Методы Бокса-Дженкинса (ARIMA, ARMA)
Однако, начиная с конца 80-х годов, в научной литературе был опубликован ряд статей по нейросетевой тематике, в которых был приведен эффективный алгоритм обучения нейронных сетей и доказана возможность их использования для самого широкого круга задач.
Эти статьи возродили интерес к нейросетям в научном сообществе и последние очень скоро стали широко использоваться при исследованиях в самых разных областях науки от экспериментальной физики и химии до экономики.
Кстати, некоторые сотрудники компании «Нейропроект» начали заниматься нейронными сетями именно в то время, используя их для обработки результатов физических экспериментов.
Отчасти из-за относительной сложности и недетерминированности нейронных сетей и генетических алгоритмов, эти технологии не сразу вышли за рамки чисто научного применения. Тем не менее, с течением времени уровень доверия к новым технологиям повышался и со стороны бизнеса. С начала 90-х годов начали регулярно появляться сообщения об установках нейросетевых систем в разных компаниях, банках, корпоративных институтах. Причем сфера использования новых технологий была очень многогранной — оценка рисков, контроль технологических процессов, управлние роботами и многое другое.
Одним из самых успешных приложений нейронных сетей было прогнозирование временных рядов. Причем самым массовым было
- Прогнозирование на финансовых рынках
- Прогнозирование продаж
В настоящее время можно с уверенностью сказать, что использование нейронных сетей при прогнозировании дает ощутимое преимущество по сравнению с более простыми статистическими методами.
Методы прогнозирования, основанные на сглаживании, экспоненциальном сглаживании и скользящем среднем
«Наивные» модели прогнозирования
При создании «наивных» моделей предполагается, что некоторый последний период прогнозируемого временного ряда лучше всего описывает будущее этого прогнозируемого ряда, поэтому в этих моделях прогноз, как правило, является очень простой функцией от значений прогнозируемой переменной в недалеком прошлом.
Самой простой моделью является
что соответствует предположению, что «завтра будет как сегодня».
Вне всякого сомнения, от такой примитивной модели не стоит ждать большой точности. Она не только не учитывает механизмы, определяющие прогнозируемые данные (этот серьезный недостаток вообще свойственен многим статистическим методам прогнозирования), но и не защищена от случайных флуктуаций, она не учитывает сезонные колебания и тренды. Впрочем, можно строить «наивные» модели несколько по-другому
такими способами мы пытаемся приспособить модель к возможным трендам
это попытка учесть сезонные колебания
Средние и скользящие средние
Самой простой моделью, основанной на простом усреднении является
и в отличии от самой простой «наивной» модели, которой соответствовал принцип «завтра будет как сегодня», этой модели соответствует принцип «завтра будет как было в среднем за последнее время». Такая модель, конечно более устойчива к флуктуациям, поскольку в ней сглаживаются случайные выбросы относительно среднего. Несмотря на это, этот метод идеологически настолько же примитивен как и «наивные» модели и ему свойственны почти те же самые недостатки.
В приведенной выше формуле предполагалось, что ряд усредняется по достаточно длительному интервалу времени. Однако как правило, значения временного ряда из недалекого прошлого лучше описывают прогноз, чем более старые значения этого же ряда. Тогда можно использовать для прогнозирования скользящее среднее
Смысл его заключается в том, что модель видит только ближайшее прошлое (на T отсчетов по времени в глубину) и основываясь только на этих данных строит прогноз.
При прогнозировании довольно часто используется метод экспоненциальных средних , который постоянно адаптируется к данным за счет новых значений. Формула, описывающая эту модель записывается как
где Y(t+1) – прогноз на следующий период времени
Y(t) – реальное значение в момент времени t
^Y(t) – прошлый прогноз на момент времени t
a – постоянная сглаживания (0 a
В этом методе есть внутренний параметр a , который определяет зависимость прогноза от более старых данных, причем влияние данных на прогноз экспоненциально убывает с «возрастом» данных. Зависимость влияния данных на прогноз при разных коэффициентах a приведена на графике.

Видно, что при a ->1, экспоненциальная модель стремится к самой простой «наивной» модели. При a ->0, прогнозируемая величина становится равной предыдущему прогнозу.
Если производится прогнозирование с использованием модели экспоненциального сглаживания, обычно на некотором тестовом наборе строятся прогнозы при a =[0.01, 0.02, . 0.98, 0.99] и отслеживается, при каком a точность прогнозирования выше. Это значение a затем используется при прогнозировании в дальнейшем.
Хотя описанные выше модели («наивные» алгоритмы, методы, основанные на средних, скользящих средних и экспоненциального сглаживания) используются при бизнес-прогнозировании в не очень сложных ситуациях, например, при прогнозировании продаж на спокойных и устоявшихся западных рынках, мы не рекомендуем использовать эти методы в задачах прогнозирования в виду явной примитивности и неадекватности моделей.
Вместе с этим хотелось бы отметить, что описанные алгоритмы вполне успешно можно использовать как сопутствующие и вспомогательные для предобработки данных в задачах прогнозирования. Например, для прогнозирования продаж в большинстве случаев необходимо проводить декомпозицию временных рядов (т.е. выделять отдельно тренд, сезонную и нерегулярную составляющие). Одним из методов выделения трендовых составляющих является использование экспоненциального сглаживания.
Методы Хольта и Брауна
В середине прошлого века Хольт предложил усовершенствованный метод экспоненциального сглаживания, впоследствии названный его именем. В предложенном алгоритме значения уровня и тренда сглаживаются с помощью экспоненциального сглаживания. Причем параметры сглаживания у них различны.
Здесь первое уравнение описывает сглаженный ряд общего уровня.
Второе уравнение служит для оценки тренда.
Третье уравнение определяет прогноз на p отсчетов по времени вперед.
Постоянные сглаживания в методе Хольта идеологически играют ту же роль, что и постоянная в простом экспоненциальном сглаживании. Подбираются они, например, путем перебора по этим параметрам с каким-то шагом. Можно использовать и менее сложные в смысле количества вычислений алгоритмы. Главное, что всегда можно подобрать такую пару параметров, которая дает большую точность модели на тестовом наборе и затем использовать эту пару параметров при реальном прогнозировании.
Частным случаем метода Хольта является метод Брауна, когда a =ß.
Метод Винтерса
Хотя описанный выше метод Хольта (метод двухпараметрического экспоненциального сглаживания) и не является совсем простым (относительно «наивных» моделей и моделей, основанных на усреднении), он не позволяет учитывать сезонные колебания при прогнозировании. Говоря более аккуратно, этот метод не может их «видеть» в предыстории. Существует расширение метода Хольта до трехпараметрического экспоненциального сглаживания. Этот алгоритм называется методом Винтерса. При этом делается попытка учесть сезонные составляющие в данных. Система уравнений, описывающих метод Винтерса выглядит следующим образом:

Дробь в первом уравнении служит для исключения сезонности из Y(t). После исключения сезонности алгоритм работает с «чистыми» данными, в которых нет сезонных колебаний. Появляются они уже в самом финальном прогнозе, когда «чистый» прогноз, посчитанный почти по методу Хольта умножается на сезонный коэффициент.
Регрессионные методы прогнозирования
Наряду с описанными выше методами, основанными на экспоненциальном сглаживании, уже достаточно долгое время для прогнозирования используются регрессионные алгоритмы. Коротко суть алгоритмов такого класса можно описать так.
Существует прогнозируемая переменная Y (зависимая переменная) и отобранный заранее комплект переменных, от которых она зависит — X1, X2, . XN (независимые переменные). Природа независимых переменных может быть различной. Например, если предположить, что Y — уровень спроса на некоторый продукт в следующем месяце, то независимыми переменными могут быть уровень спроса на этот же продукт в прошлый и позапрошлый месяцы, затраты на рекламу, уровень платежеспособности населения, экономическая обстановка, деятельность конкурентов и многое другое. Главное — уметь формализовать все внешние факторы, от которых может зависеть уровень спроса в числовую форму.
Модель множественной регрессии в общем случае описывается выражением

В более простом варианте линейной регрессионной модели зависимость зависимой переменной от независимых имеет вид: 
Здесь  — подбираемые коэффициенты регрессии,
— подбираемые коэффициенты регрессии,  — компонента ошибки. Предполагается, что все ошибки независимы и нормально распределены.
— компонента ошибки. Предполагается, что все ошибки независимы и нормально распределены.
Для построения регрессионных моделей необходимо иметь базу данных наблюдений примерно такого вида:
независимые
зависимая
С помощью таблицы значений прошлых наблюдений можно подобрать (например, методом наименьших квадратов) коэффициенты регрессии, настроив тем самым модель.
При работе с регрессией надо соблюдать определенную осторожность и обязательно проверить на адекватность найденные модели. Существуют разные способы такой проверки. Обязательным является статистический анализ остатков, тест Дарбина-Уотсона. Полезно, как и в случае с нейронными сетями, иметь независимый набор примеров, на которых можно проверить качество работы модели.
Методы Бокса-Дженкинса (ARIMA)
В середине 90-х годов прошлого века был разработан принципиально новый и достаточно мощный класс алгоритмов для прогнозирования временных рядов. Большую часть работы по исследованию методологии и проверке моделей была проведена двумя статистиками, Г.Е.П. Боксом (G.E.P. Box) и Г.М. Дженкинсом (G.M. Jenkins). С тех пор построение подобных моделей и получение на их основе прогнозов иногда называться методами Бокса-Дженкинса. Более подробно иерархию алгоритмов Бокса-Дженкинса мы рассмотрим чуть ниже, пока же отметим, что в это семейство входит несколько алгоритмов, самым известным и используемым из них является алгоритм ARIMA. Он встроен практически в любой специализированный пакет для прогнозирования. В классическом варианте ARIMA не используются независимые переменные. Модели опираются только на информацию, содержащуюся в предыстории прогнозируемых рядов, что ограничивает возможности алгоритма. В настоящее время в научной литературе часто упоминаются варианты моделей ARIMA, позволяющие учитывать независимые переменные. В данном учебнике мы их рассматривать не будем, ограничившись только общеизвестным классическим вариантом. В отличие от рассмотренных ранее методик прогнозирования временных рядов, в методологии ARIMA не предполагается какой-либо четкой модели для прогнозирования данной временной серии. Задается лишь общий класс моделей, описывающих временной ряд и позволяющих как-то выражать текущее значение переменной через ее предыдущие значения. Затем алгоритм, подстраивая внутренние параметры, сам выбирает наиболее подходящую модель прогнозирования. Как уже отмечалось выше, существует целая иерархия моделей Бокса-Дженкинса. Логически ее можно определить так
AR(p) -авторегрессионая модель порядка p.
Модель имеет вид:
где
Y(t)-зависимая переменная в момент времени t. f_0, f_1, f_2, . f_p — оцениваемые параметры. E(t) — ошибка от влияния переменных, которые не учитываются в данной модели. Задача заключается в том, чтобы определить f_0, f_1, f_2, . f_p. Их можно оценить различными способами. Правильнее всего искать их через систему уравнений Юла-Уолкера, для составления этой системы потребуется расчет значений автокорреляционной функции. Можно поступить более простым способом — посчитать их методом наименьших квадратов.
MA(q) -модель со скользящим средним порядка q.
Модель имеет вид:
Где Y(t)-зависимая переменная в момент времени t. w_0, w_1, w_2, . w_p — оцениваемые параметры.
Нейросетевые модели бизнес-прогнозирования
В настоящее время, на наш взгляд, самым перспективным количественным методом прогнозирования является использование нейронных сетей. Можно назвать много преимуществ нейронных сетей над остальными алгоритмами, ниже приведены два основных.
При использовании нейронных сетей легко исследовать зависимость прогнозируемой величины от независимых переменных. Например, есть предположение, что продажи на следующей неделе каким-то образом зависят от следующих параметров:
- продаж в последнюю неделю
- продаж в предпоследнюю неделю
- времени прокрутки рекламных роликов (TRP)
- количества рабочих дней
- температуры
- .
Кроме того, продажи носят сезонный характер, имеют тренд и как-то зависят от активности конкурентов.
Хотелось бы построить систему, которая бы все это естесственным образом учитывала и строила бы краткосрочные прогнозы.
В такой постановке задачи большая часть классических методов прогнозирования будет просто несостоятельной. Можно попробовать построить систему на основе нелинейной множественной регрессии, или вариации сезонного алгоритма ARIMA, позволяющей учитывать внешние параметры, но это будут модели скорее всего малоэффективные (за счет субъективного выбора модели) и крайне негибкие.
Используя же даже самую простую нейросетевую архитектуру (персептрон с одним скрытым слоем) и базу данных (с продажами и всеми параметрами) легко получить работающую систему прогнозирования. Причем учет, или не учет системой внешних параметров будет определяться включением, или исключением соответствующего входа в нейронную сеть.
Более искушенный эксперт может с самого начала воспользоваться каким-либо алгоритмом определения важности (например, используя Нейронную сеть с общей регрессией и генетической подстройкой) и сразу определить значимость входных переменных, чтобы потом исключить из рассмотрения мало влияющие параметры.
Еще одно серьезное преимущество нейронных сетей состоит в том, что эксперт не является заложником выбора математической модели поведения временного ряда. Построение нейросетевой модели происходит адаптивно во время обучения, без участия эксперта. При этом нейронной сети предъявляются примеры из базы данных и она сама подстраивается под эти данные.
Недостатком нейронных сетей является их недетерминированность. Имеется в виду то, что после обучения имеется «черный ящик», который каким-то образом работает, но логика принятия решений нейросетью совершенно скрыта от эксперта. В принципе, существуют алгоритмы «извлечения знаний из нейронной сети», которые формализуют обученную нейронную сеть до списка логических правил, тем самым создавая на основе сети экспертную систему. К сожалению, эти алгоритмы не встраиваются в нейросетевые пакеты, к тому же наборы правил, которые генерируются такими алгоритмами достаточно объемные. Подробнее об этом можно почитать в книге А.А. Ежова, С.А. Шумского «Нейрокомпьютинг и его применения в экономике и бизнесе».
Тем не менее, для людей, умеющих работать с нейронными сетями и знающими нюансы настройки, обучения и применения, в практических задачах непрозрачность нейронных сетей не является сколь-нибудь серьезным недостатком.
Использование многослойных персептронов
Самый простой вариант применения искусственных нейронных сетей в задачах бизнес-прогнозирования — использование обычного персептрона с одним, двумя, или (в крайнем случае) тремя скрытыми слоями. При этом на входы нейронной сети обычно подается набор параметров, на основе которого (по мнению эксперта) можно успешно прогнозировать. Выходом обычно является прогноз сети на будущий момент времени.

Рассмотрим пример прогнозирования продаж. На рисунке представлен график, отражающий историю продаж некого продукта по неделям. В данных явно заметна выраженная сезонность. Для простоты предположим, что никаких других нужных данных у нас нет. Тогда сеть логично строить следующим образом. Для прогнозирования на будущую неделю надо подавать данные о продажах за последние недели, а также данные о продажах в течении нескольких недель подряд год назад, чтобы сеть видела динамику продаж один сезон назад, когда эта динамика была похожа на настоящую за счет сезонности.
Если входных параметров много, крайне рекомендуется не сбрасывать их сразу в нейронную сеть, а попытаться вначале провести предобработку данных, для того чтобы понизить их размерность, или представить в правильном виде. Вообще, предобработка данных — отдельная большая тема, которой следует уделить достаточно много времени, так как это ключевой этап в работе с нейронной сетью. В большинстве практических задач по прогнозированию продаж предобработка состоит из разных частей. Вот лишь один пример.
Пусть в предыдущем примере у нас есть не только историческая база данных о продажах продукта, которые мы прогнозируем, но и данные о его рекламе на телевидении. Эти данные могут выглядеть следующим образом

По оси времени отложены номера недель и рекламные индексы для каждой недели. Видно, что в шестнадцатую и семнадцатую недели рекламы не было вообще. Очевидно, что неправильно данные о рекламе подавать в сеть (если это не рекуррентная нейронная сеть) в таком виде, поскольку определяет продажи не сама реклама как таковая, а образы и впечатления в сознании покупателя, которые эта реклама создает. И такая реклама имеет продолжительное действие — даже через несколько месяцев после окончания рекламы на телевидении люди будут помнить продукт и покупать его, хотя, скорее всего, продажи будут постепенно падать. Поэтому пытаясь подавать в сеть такие данные о рекламе мы делаем неправильную постановку задачи и, как минимум, усложним сети процесс обучения.
При использовании многослойных нейронных сетей в бизнес-прогнозировании в общем и прогнозировании продаж в частности полезно также помнить о том, что нужно аккуратно делать нормировку и что для выходного нейрона лучше использовать линейную передаточную функцию. Обобщающие свойства от этого немного ухудшаются, но сеть будет намного лучше работать с данными, содержащими тренд.
Использование нейронных сетей с общей регрессией GRNN и GRNN-GA
Еще одной часто используемой нейросетевой архитектурой, используемой в бизнес-прогнозировании является нейронная сеть с общей регрессией. Несмотря на то что принцип обучения и применения таких сетей в корне отличается от обычных персептронов, внешне сеть используется таким же образом, как и обычный персептрон. Говоря другими словами, это совместимые архитектуры в том смысле, что в работающей системе прогнозирования можно заменить работающий персептрон на сеть с общей регрессией и все будет работать. Не потребуется проводить никаких дополнительных манипуляций с данными.
Если персептрон во время обучения запоминал предъявляемые примеры постепенно подстраивая свои внутренние параметры, то сети с общей регрессией запоминают примеры в буквальном смысле. Каждому примеру — отдельный нейрон в скрытом слое сети, а затем, во время применения сеть сравнивает предъявляемый пример с примерами, которые она помнит. Смотрит, на какие из них текущий пример похож и в какой степени и на основе этого сравнения выдаст ответ.
Отсюда следует первый недостаток такой архитектуры — когда база данных о продажах, или других величинах, которые мы прогнозируем велика, сеть станет слишком большой и будет медленно работать. С этим можно бороться предварительной кластеризацией базы данных.
Анализ временных рядов 1
Дата публикации Mar 8, 2019

Анализ данных временных рядов является неотъемлемой частью работы любого ученого, особенно в области количественной торговли. Финансовые данные являются наиболее запутанными данными временных рядов и часто кажутся ошибочными. Тем не менее, на основе этих нескольких статей я создам основу для анализа таких временных рядов, сначала используя хорошо обоснованные теории, а затем углубившись в более экзотические, современные подходы, такие как машинное обучение. Итак, начнем!
ARIMA Модель
Первая модель, которую мы собираемся обсудить, — это модель ARIMA. Он обозначает модель авторегрессивного интегрированного скользящего среднего. Да, это много, чтобы принять. Однако, по сути, он просто объединяет две более простые модели, модель авторегрессии и скользящую среднюю, обе из которых мы рассмотрим ниже. Перед этим нам необходимо установить концепцию стационарности, так как это важно для возможности точно моделировать и прогнозировать временные ряды.
стационарность
Концепция стационарности происходит от случайных процессов, и иногда результатом этих случайных процессов является белый шум. Ниже приводится широкое определение стационарности:
Стационарный временной ряд — это временной ряд, статистические свойства которого, такие как среднее значение и стандартное отклонение, не зависят от времени.
Для тех, кто имеет опыт работы со статистикой и стохастикой, следующее будет более формальным определением
Пусть

является кумулятивной функцией распределения безусловного совместного распределения

Однако в большинстве приложений мы не проверяем стационарность вручную, используя стохастик. Мы используем такие тесты, как тест Дикки-Фуллера и Аугментированный тест Дикки-Фуллера.
Существует также более слабое понятие стационарности, которое в большинстве случаев является достаточным для удовлетворения. Эта слабая стационарность определяется как ожидаемое значение, и ковариация временного ряда не изменяется со временем.
Модель авторегрессии (AR)
Модель авторегрессии концептуально проста: она использует значения запаздывания в качестве регрессоров для простой модели линейной регрессии для текущего / следующего временного шага. Формально это:


Модель AR может выглядеть аналогично обычной регрессии наименьших квадратов (OLS), где предыдущие временные шаги являются регрессорами, а текущее значение x является прогнозируемой переменной. Я думаю, что нам следует уделить время, чтобы понять разницу между регрессией OLS и моделью AR. Рассмотрим следующую проблему OLS:
У вас есть данные X и Y, и вы хотите найти оценку OLS формулы регрессии в форме:

Цель OLS — найти оценку бета-версии, которая минимизирует суммарную квадратичную ошибку. Другими словами, найти минимум

Разложив его и дифференцируя уравнение, мы можем найти стационарную точку, которая оказывается

Это решение для оценки OLS. Однако ключевая проблема в применении этого метода к моделям AR состоит в том, что данные X и Y не находятся в хороших матрицах, и их трудно преобразовать в такие матрицы каждый раз, когда мы работаем с данными. Таким образом, альтернативный метод используется для нахождения коэффициентов лаговых переменных в моделях AR. Прежде чем мы посмотрим на методы, чтобы найти коэффициенты, мы рассмотрим другие компоненты модели ARIMA.
Модель скользящего среднего (MA)
Модель скользящего среднего учитывает предыдущие термины ошибок и использует ее для моделирования текущего значения временного ряда. Формально,

Модель MA выглядит очень похоже на модель AR. Однако есть несколько ключевых отличий, на которые следует обратить внимание:
- Члены ошибки в модели MA непосредственно влияют на текущее значение временного ряда, тогда как в модели AR член ошибки от предыдущих временных шагов присутствует только неявно.
- Члены ошибки в модели MA влияют только на временной ряд для q шагов в будущем, но в модели AR члены ошибки влияют на временной ряд на бесконечное время в будущем.
Это ключевое отличие дает нам естественное расширение модели путем их объединения. Именно это и есть модель ARMA. Разница между моделью ARMA и моделью ARIMA заключается в интеграции. В контексте временных рядов интеграция относится к степени разницы, необходимой для того, чтобы сделать временной ряд стационарным временным рядом. Таким образом, если у нас есть временной ряд y, и мы различие его d раз, и пусть это будет называться х, нам просто нужно применить две вышеупомянутые модели вместе, чтобы получить следующую модель ARIMA:

Теперь, когда мы понимаем нашу модель ARIMA, мы можем приступить к изучению того, как оцениваются коэффициенты.
Оценка коэффициентов
Существует несколько методов для расчета коэффициентов модели, и мы рассмотрим два из них. Первый метод использует набор уравнений, называемых уравнениями Юла-Уокера. Уравнения Юла-Уокера основаны на методе моментов в статистике Сначала рассмотрим модель AR, поэтому рассмотрим автоковариации модели AR (p):


Мы можем записать это в матричной форме, чтобы получить:
http://masters.donntu.org/2007/kita/filatova/library/t4.htm
http://www.machinelearningmastery.ru/time-series-analysis-1-9f4360f43110/