Лекции по дисциплине «Эконометрика» (заочное отделение) (стр. 2 )
 | Из за большого объема этот материал размещен на нескольких страницах: 1 2 3 4 |

Параметр формально является значением Y при X = 0. Он может не иметь экономического содержания. Интерпретировать можно лишь знак при параметре . Если > 0, то относительное изменение результата происходит медленнее, чем изменение фактора. Иными словами, вариация по фактору X выше вариации для результата Y. Также считают, что включает в себя неучтенные в модели факторы.
По итогам 2008 года были собраны данные по прибыли и оборачиваемости оборотных средств 500 торговых предприятий г. Челябинска. Результаты наблюдения сведены в таблицу.
Годовая прибыль предприятия, млн. руб.
Годовая оборачиваемость оборотных средств, раз
Требуется построить зависимость прибыли предприятий от оборачиваемости оборотных средств и оценить качество полученного уравнения.
Пусть y – прибыль предприятия, x – оборачиваемость оборотных средств.
На основе исходных данных были рассчитаны следующие показатели:
Уровень доверия возьмем q=0,95 или 95%.

1. Стандартные ошибки оценок , . намного больше =0,39, следовательно, низкая точность коэффициента . очень мала по сравнению с , следовательно, высокая точность коэффициента .
2. Интервальные оценки коэффициентов уравнения регрессии.
n – 2 = 500 – 2 = 498;
α:  →
→  → очень низкая точность коэффициента;
→ очень низкая точность коэффициента;
β:  →
→  → высокая точность коэффициента.
→ высокая точность коэффициента.
3. Значимость коэффициентов регрессии.
 = >1,96 → коэффициент значим;
= >1,96 → коэффициент значим;
 = >1,96 → коэффициент значим.
= >1,96 → коэффициент значим.
4. Стандартная ошибка регрессии. Se=0,91, по сравнению со средним значением =34,5 ошибка невысокая, точность уравнения хорошая.
5. Коэффициент детерминации. R2 = rxy2=0,782=0,6084 не очень близко к 1, качество подгонки среднее.
6. Средняя ошибка аппроксимации. A=11%, качество подгонки уравнения среднее.
Экономическая интерпретация: при увеличении оборачиваемости оборотных средств предприятия на 1 раз в год средняя годовая прибыль увеличится на 5,86 млн. руб.
Тема 6. Нелинейная парная регрессия
Часто на практике между зависимой и независимыми переменными существует нелинейная форма взаимосвязи. В этом случае существует два выхода:
1) подобрать к анализируемым переменным преобразование, которое бы позволило представить существующую зависимость в виде линейной функции;
2) применить нелинейный метод наименьших квадратов.
Основные нелинейные регрессионные модели и приведение их к линейной форме
1. Экспоненциальное уравнение  .
.
Если прологарифмировать левую и правую части данного уравнения, то получится
 .
.
Это уравнение является линейным, но вместо y в левой части стоит ln y.
В данном случае параметр β1 имеет следующий экономический смысл: при увеличении переменной x на единицу переменная y в среднем увеличится примерно на 100·β% (более точно: y увеличится в  раз).
раз).
2. Логарифмическое уравнение  .
.
Переход к линейному уравнению осуществляется заменой переменной x на X=lnx..
Параметр β1 имеет следующий экономический смысл: для увеличения y на единицу необходимо увеличить переменную x в  раз, т. е. примерно на
раз, т. е. примерно на  .
.
3. Гиперболическое уравнение  .
.
В этом случае необходимо сделать замену переменных x на  . Для гиперболической зависимости нет простой интерпретации коэффициента регрессии β1.
. Для гиперболической зависимости нет простой интерпретации коэффициента регрессии β1.
4. Степенное уравнение  .
.
Прологарифмировав левую и правую части данного уравнения, получим
 .
.
Заменив соответствующие ряды их логарифмами, получится линейная регрессия.
Экономический смысл параметра β1: если значение переменной x увеличить на 1%, то y увеличится на β1%.
5. Показательное уравнение  (β1>0, β1≠1).
(β1>0, β1≠1).
Прологарифмировав левую и правую части уравнения, получим
 .
.
Проведя замены Y=ln y и B1=ln β1, получится линейная регрессия.
Экономический смысл параметра β1: при увеличении переменной x на единицу переменная y в среднем увеличится в β1 раз.
Тема 7. Множественная линейная регрессия: определение и оценка параметров
1. Понятие множественной линейной регрессии
Модель множественной линейной регрессии является обобщением парной линейной регрессии и представляет собой следующее выражение:
 , t=1. n,
, t=1. n,
где yt – значение зависимой переменной для наблюдения t,
xit – значение i-й независимой переменной для наблюдения t,
εt – значение случайной ошибки для наблюдения t,
n – число наблюдений,
m – число независимых переменных x.
2. Матричная форма записи множественной линейной регрессии
Уравнение множественной линейной регрессии можно записать в матричной форме:
 ,
,
где  ,
,  ,
,  ,
,  .
.
3. Основные предположения
2.  для всех наблюдений;
для всех наблюдений;
3.  = const для всех наблюдений;
= const для всех наблюдений;
4.  ;
;
В случае выполнения вышеперечисленных гипотез модель называется нормальной линейной регрессионной.
4. Метод наименьших квадратов
Параметры уравнения множественной регрессии оцениваются, как и в парной регрессии, методом наименьших квадратов (МНК):  .
.
Чтобы найти минимум этой функции необходимо вычислить производные по каждому из параметров и приравнять их к нулю, в результате получается система уравнений, решение которой в матричном виде следующее:
 →
→  .
.
 ,
,

5. Теорема Гаусса-Маркова
Если выполнены предположения 1-5 из пункта 3, то оценки , полученные методом наименьших квадратов, имеют наименьшую дисперсию в классе линейных несмещенных оценок, то есть являются несмещенными, состоятельными и эффективными.
Тема 8. Множественная линейная регрессия: оценка качества
1. Общая схема проверки качества парной регрессии
Адекватность модели – остатки должны удовлетворять условиям теоремы Гаусса-Маркова.
Основные показатели качества коэффициентов регрессии:
1. Стандартные ошибки оценок (анализ точности определения оценок).
2. Интервальные оценки коэффициентов уравнения регрессии (построение доверительных интервалов).
3. Значимость коэффициентов регрессии (проверка гипотез относительно коэффициентов регрессии).
Основные показатели качества уравнения регрессии в целом:
1. Стандартная ошибка регрессии Se (анализ точности уравнения регрессии).
2. Значимость уравнения регрессии в целом (проверка гипотезы относительно всех коэффициентов регрессии).
3. Коэффициент детерминации R2 (проверка качества подгонки уравнения к исходным данным).
4. Скорректированный коэффициент детерминации R2adj (проверка качества подгонки уравнения к исходным данным).
5. Средняя ошибка аппроксимации (проверка качества подгонки уравнения к эмпирическим данным).
2. Стандартные ошибки оценок
Стандартные ошибки коэффициентов регрессии – это средние квадратические отклонения коэффициентов регрессии от их истинных значений.
 ,
,
где 
 — диагональные элементы матрицы
— диагональные элементы матрицы  ,
,
 .
.
Стандартная ошибка является оценкой среднего квадратического отклонения коэффициента регрессии от его истинного значения. Чем меньше стандартная ошибка тем точнее оценка.
3. Интервальные оценки коэффициентов множественной линейной регрессии
Доверительные интервалы для коэффициентов регрессии определяются следующим образом:
1. Выбирается уровень доверия q (0,9; 0,95 или 0,99).
2. Рассчитывается уровень значимости g = 1 – q.
3. Рассчитывается число степеней свободы n – m – 1, где n – число наблюдений, m – число независимых переменных.
4. Определяется критическое значение t-статистики (tкр) по таблицам распределения Стьюдента на основе g и n – m – 1.
5. Рассчитывается доверительный интервал для параметра  :
:
 .
.
Доверительный интервал показывает, что истинное значение параметра с вероятностью q находится в данных пределах.
Чем меньше доверительный интервал относительно коэффициента, тем точнее полученная оценка.
4. Значимость коэффициентов регрессии
Процедура оценки значимости коэффициентов осуществляется аналогичной парной регрессии следующим образом:
1. Рассчитывается значение t-статистики для коэффициента регрессии по формуле  .
.
2. Выбирается уровень доверия q ( 0,9; 0,95 или 0,99).
3. Рассчитывается уровень значимости g = 1 – q.
4. Рассчитывается число степеней свободы n – m – 1, где n – число наблюдений, m – число независимых переменных.
5. Определяется критическое значение t-статистики (tкр) по таблицам распределения Стьюдента на основе g и n – m – 1.
6. Если  , то коэффициент является значимым на уровне значимости g. В противном случае коэффициент не значим (на данном уровне g).
, то коэффициент является значимым на уровне значимости g. В противном случае коэффициент не значим (на данном уровне g).
t-тесты обеспечивают проверку значимости предельного вклада каждой переменной при допущении, что все остальные переменные уже включены в модель.
5. Стандартная ошибка регрессии
Стандартная ошибка регрессии Se показывает, насколько в среднем фактические значения зависимой переменной y отличаются от ее расчетных значений
 .
.
Используется как основная величина для измерения качества модели (чем она меньше, тем лучше).
Значения Se в однотипных моделях с разным числом наблюдений и (или) переменных сравнимы.
6. Оценка значимости уравнения регрессии в целом
Уравнение значимо, если есть достаточно высокая вероятность того, что существует хотя бы один коэффициент, отличный от нуля.
Имеются альтернативные гипотезы:
Если принимается гипотеза H0, то уравнение статистически незначимо. В противном случае говорят, что уравнение статистически значимо.
Значимость уравнения регрессии в целом осуществляется с помощью F-статистики.
Оценка значимости уравнения регрессии в целом основана на тождестве дисперсионного анализа:
 Þ
Þ
TSS – общая сумма квадратов отклонений
ESS – объясненная сумма квадратов отклонений
RSS – необъясненная сумма квадратов отклонений
F-статистика представляет собой отношение объясненной суммы квадратов (в расчете на одну независимую переменную) к остаточной сумме квадратов (в расчете на одну степень свободы)

n – число выборочных наблюдений, m – число независимых переменных.
При отсутствии линейной зависимости между зависимой и независимой переменными F-статистика имеет F-распределение Фишера-Снедекора со степенями свободы k1 = m, k2 = n – m –1.
Процедура оценки значимости уравнения осуществляется следующим образом:
7. Рассчитывается значение F-статистики по формуле  .
.
8. Выбирается уровень доверия q ( 0,9; 0,95 или 0,99).
9. Рассчитывается уровень значимости g = 1 – q.
10. Рассчитывается число степеней свободы n – m – 1, где n – число наблюдений, m – число независимых переменных.
11. Определяется критическое значение F-статистики (Fкр) по таблицам распределения Фишера на основе g и n – m – 1.
12. Если  , то уравнение является значимым на уровне значимости g. В противном случае уравнение не значимо (на данном уровне g).
, то уравнение является значимым на уровне значимости g. В противном случае уравнение не значимо (на данном уровне g).
В парной регрессии F-статистика равна квадрату t-статистики:  , а значимость коэффициента регрессии и значимость уравнения в целом эквивалентны.
, а значимость коэффициента регрессии и значимость уравнения в целом эквивалентны.
Качество оценки уравнения можно проверить путем расчета коэффициента детерминации R2, который показывает степень соответствия найденного уравнения экспериментальным данным.
 .
.
Коэффициент R2 показывает долю дисперсии переменной y, объясненную регрессией, в общей дисперсии y.
Коэффициент детерминации лежит в пределах 0 £ R2 £ 1.
Чем ближе R2 к 1, тем выше качество подгонки уравнения к статистическим данным.
Чем ближе R2 к 0, тем ниже качество подгонки уравнения к статистическим данным.
Коэффициенты R2 в разных моделях с разным числом наблюдений и переменных несравнимы.
8. Скорректированный коэффициент детерминации R2adj
Низкое значение R2 не свидетельствует о плохом качестве модели, и может объясняться наличием существенных факторов, не включенных в модель
R2 всегда увеличивается с включением новой переменной. Поэтому его необходимо корректировать, и рассчитывают скорректированный коэффициент детерминации

Если R2adj выходит за пределы интервала [0;1], то его использовать нельзя.
Если при добавлении новой переменной в модель увеличивается не только R2, но и R2adj, то можно считать, что вклад этой переменной в повышение качества модели существенен.
9. Средняя ошибка аппроксимации
Средняя ошибка аппроксимации (средняя абсолютная процентная ошибка) – показывает в процентах среднее отклонение расчетных значений зависимой переменной от фактических значений yi

Если A ≤ 10%, то качество подгонки уравнения считается хорошим. Чем меньше значение A, тем лучше.
10. Использование показателей качества коэффициентов и уравнения регрессии для интерпретации и корректировки модели
В случае незначимости уравнения, необходимо устранить ошибки модели. Наиболее распространенными являются следующие ошибки:
— неправильно выбран вид функции регрессии;
— в модель включены незначимые регрессоры;
— в модели отсутствуют значимые регрессоры.
После устранения ошибок требуется заново оценить параметры уравнения и его качество, продолжая этот процесс до тех пор, пока качество уравнения не станет удовлетворительным. Если после поделанных процедур, мы не достигли требуемого уровня значимости, то необходимо устранять другие ошибки (спецификации, классификации, наблюдения и т. д., см. тему 3, п. 6).
11. Интерпретация множественной линейной регрессии
Коэффициент регрессии при переменной xi показывает, на сколько увеличится среднее значение зависимой переменной y при увеличении xi на 1, при условии постоянства других переменных.
В апреле 2006 года были собраны данные по стоимости 200 двухкомнатных квартир в Металлургическом районе г. Челябинска, их жилой площади, площади кухни и расстоянии до центра города (пл. Революции). Результаты наблюдения сведены в таблицу.
Стандартные ошибки оценок коэффициентов уравнения регрессии
Стандартная ошибка оценки, также известная как стандартная ошибка уравнения регрессии, определяется следующим образом (см. (6.23)) [c.280]
Стандартная ошибка уравнения регрессии, Эта статистика SEE представляет собой стандартное отклонение фактических значений теоретических значений У. [c.650]
Что такое стандартная ошибка уравнения регрессии ).Какие допущения лежат в основе парной регрессии 10. Что такое множественная регрессия [c.679]
Следующий этап корреляционного анализа — расчет уравнения связи (регрессии). Решение проводится обычно шаговым способом. Сначала в расчет принимается один фактор, который оказывает наиболее значимое влияние на результативный показатель, потом второй, третий и т.д. И на каждом шаге рассчитываются уравнение связи, множественный коэффициент корреляции и детерминации, /»»-отношение (критерий Фишера), стандартная ошибка и другие показатели, с помощью которых оценивается надежность уравнения связи. Величина их на каждом шаге сравнивается с предыдущей. Чем выше величина коэффициентов множественной корреляции, детерминации и критерия Фишера и чем ниже величина стандартной ошибки, тем точнее уравнение связи описывает зависимости, сложившиеся между исследуемыми показателями. Если добавление следующих факторов не улучшает оценочных показателей связи, то надо их отбросить, т.е. остановиться на том уравнении, где эти показатели наиболее оптимальны. [c.149]
Прогнозное значение ур определяется путем подстановки в уравнение регрессии ух =а + Ьх соответствующего (прогнозного) значения хр. Вычисляется средняя стандартная ошибка прогноза [c.9]
В линейной регрессии обычно оценивается значимость не только уравнения в целом, но и отдельных его параметров. С этой целью по каждому из параметров определяется его стандартная ошибка ть и та. [c.53]
В прогнозных расчетах по уравнению регрессии определяется предсказываемое (ур) значение как точечный прогноз ух при хр =хь т. е. путем подстановки в уравнение регрессии 5 = а + b х соответствующего значения х. Однако точечный прогноз явно не реален. Поэтому он дополняется расчетом стандартной ошибки ух, т. е. Шух, и соответственно интервальной оценкой прогнозного значения (у ) [c.57]
Чтобы понять, как строится формула для определения величин стандартной ошибки ух, обратимся к уравнению линейной регрессии ух = а + b х. Подставим в это уравнение выражение параметра а [c.57]
При прогнозировании на основе уравнения регрессии следует помнить, что величина прогноза зависит не только от стандартной ошибки индивидуального значения у, но и от точности прогноза значения фактора х. Его величина может задаваться на основе анализа других моделей исходя из конкретной ситуации, а также из анализа динамики данного фактора. [c.61]
В скобках указаны стандартные ошибки параметров уравнения регрессии. [c.327]
В скобках указаны стандартные ошибки параметров уравнения регрессии. Определим по этому уравнению расчетные значения >>, ,, а затем параметры уравнения регрессии (7.44). Получим следующие результаты [c.328]
На каждом шаге рассматриваются уравнение регрессии, коэффициенты корреляции и детерминации, F-критерий, стандартная ошибка оценки и другие оценочные показатели. После каждого шага перечисленные оценочные показатели сравниваются с [c.39]
Проблемы с методологией регрессии. Методология регрессии — это традиционный способ уплотнения больших массивов данных и их сведения в одно уравнение, отражающее связь между мультипликаторами РЕ и финансовыми фундаментальными переменными. Но данный подход имеет свои ограничения. Во-первых, независимые переменные коррелируют друг с другом . Например, как видно из таблицы 18,2, обобщающей корреляцию между коэффициентами бета, ростом и коэффициентами выплат для всех американских фирм, быстрорастущие фирмы обычно имеют большой риск и низкие коэффициенты выплат. Обратите внимание на отрицательную корреляцию между коэффициентами выплат и ростом, а также на положительную корреляцию между коэффициентами бета и ростом. Эта мультиколлинеарность делает мультипликаторы регрессии ненадежными (увеличивает стандартную ошибку) и, возможно, объясняет ошибочные знаки при коэффициентах и крупные изменения этих мультипликаторов в разные периоды. Во-вторых, регрессия основывается на линейной связи между мультипликаторами РЕ и фундаментальными переменными, и данное свойство, по всей вероятности, неадекватно. Анализ остаточных явлений, связанных с корреляцией, может привести к трансформациям независимых переменных (их квадратов или натуральных логарифмов), которые в большей степени подходят для объяснения мультипликаторов РЕ. В-третьих, базовая связь между мультипликаторами РЕ и финансовыми переменными сама по себе не является стабильной. Если же эта связь смещается из года в год, то прогнозы, полученные из регрессионного уравнения, могут оказаться ненадежными для более длительных периодов времени. По всем этим причинам, несмотря на полезность регрессионного анализа, его следует рассматривать только как еще один инструмент поиска подлинного значения ценности. [c.649]
На рисунке 16.6 явно просматривается четкая линейная зависимость объема частного потребления от величины располагаемого дохода. Уравнение парной линейной регрессии, оцененное по этим данным, имеет вид С= -217,6 + 1,007 Yf Стандартные ошибки для свободного члена и коэффициента парной регрессии равны, соответственно, 28,4 и 0,012, а -статистики — -7,7 и 81 9. Обе они по модулю существенно превышают 3, следовательно, их статистическая значимость весьма высока. Впрочем, несмотря на то, что здесь удалось оценить статистически значимую линейную функцию потребления, в ней нарушены сразу две предпосылки Кейнса — уровень автономного потребления С0 оказался отрицательным, а предель- [c.304]
Стандартные ошибки свободного члена и коэффициента регрессии равны, соответственно, 84,7 и 0,46 их /-статистики — (-21,4 и 36,8). По абсолютной величине /-статистики намного превышают 3, и это свидетельствует о высокой надежности оцененных коэффициентов. Коэффициент детерминации /Р уравнения равен 0,96, то есть объяснено 96% дисперсии объема потребления. И в то же время уже по рисунку видно, что оцененная рефессия не очень хоро- [c.320]
Эта стандартная ошибка S у, равная 0,65, указывает отклонение фактических данных от прогнозируемых на основании использования воздействующих факторов j i и Х2 (влияние среди покупателей бабушек с внучками и высокопрофессионального вклада Шарика). В то же время мы располагаем обычным стандартным отклонением Sn, равным 1,06 (см. табл.8), которое было рассчитано для одной переменной, а именно сами текущие значения уги величина среднего арифметического у, которое равно 6,01. Легко видеть, что S у tTa6n. В противном случае доверять полученной оценке параметра нет оснований. [c.139]
Для определения профиля посетителей магазинов местного торгового центра, не имеющих определенной цели (browsers), маркетологи использовали три набора независимых переменных демографические, покупательское поведение психологические. Зависимая переменная представляет собой индекс посещения магазина без определенной цели, индекс (browsing index). Методом ступенчатой включающей все три набора переменных, выявлено, что демографические факторы — наиболее сильные предикторы, определяющие поведение покупателей, не преследующих конкретных целей. Окончательное уравнение регрессии, 20 из 36 возможных переменных, включало все демографические переменные. В следующей таблице приведены коэффициенты регрессии, стандартные ошибки коэффициентов, а также их уровни значимости. [c.668]
Смотреть страницы где упоминается термин Стандартная ошибка уравнения регрессии
Маркетинговые исследования Издание 3 (2002) — [ c.650 ]
Пример нахождения статистической значимости коэффициентов регрессии
Числитель в этой формуле может быть рассчитан через коэффициент детерминации и общую дисперсию признака-результата:  .
.
Для параметра a критерий проверки гипотезы о незначимом отличии его от нуля имеет вид:
,
где — оценка параметра регрессии, полученная по наблюдаемым данным;
μa – стандартная ошибка параметра a.
Для линейного парного уравнения регрессии: .
Для проверки гипотезы о незначимом отличии от нуля коэффициента линейной парной корреляции в генеральной совокупности используют следующий критерий: , где ryx — оценка коэффициента корреляции, полученная по наблюдаемым данным; mr – стандартная ошибка коэффициента корреляции ryx.
Для линейного парного уравнения регрессии: .
В парной линейной регрессии между наблюдаемыми значениями критериев существует взаимосвязь: t ( b =0) = t (r=0).
Пример №1 . Уравнение имеет вид y=ax+b
1. Параметры уравнения регрессии.
Средние значения
Связь между признаком Y фактором X сильная и прямая
Уравнение регрессии
Коэффициент детерминации
R 2 = 0.73 2 = 0.54, т.е. в 54% случаев изменения х приводят к изменению y . Другими словами — точность подбора уравнения регрессии — средняя.
| x | y | x 2 | y 2 | x ∙ y | y(x) | (y-y cp ) 2 | (y-y(x)) 2 | (x-x p ) 2 |
| 69 | 124 | 4761 | 15376 | 8556 | 128.48 | 491.36 | 20.11 | 367.36 |
| 83 | 133 | 6889 | 17689 | 11039 | 141.4 | 173.36 | 70.56 | 26.69 |
| 92 | 146 | 8464 | 21316 | 13432 | 149.7 | 0.03 | 13.71 | 14.69 |
| 97 | 153 | 9409 | 23409 | 14841 | 154.32 | 46.69 | 1.73 | 78.03 |
| 88 | 138 | 7744 | 19044 | 12144 | 146.01 | 66.69 | 64.21 | 0.03 |
| 93 | 159 | 8649 | 25281 | 14787 | 150.63 | 164.69 | 70.13 | 23.36 |
| 74 | 145 | 5476 | 21025 | 10730 | 133.1 | 1.36 | 141.68 | 200.69 |
| 79 | 152 | 6241 | 23104 | 12008 | 137.71 | 34.03 | 204.21 | 84.03 |
| 105 | 168 | 11025 | 28224 | 17640 | 161.7 | 476.69 | 39.74 | 283.36 |
| 99 | 154 | 9801 | 23716 | 15246 | 156.16 | 61.36 | 4.67 | 117.36 |
| 85 | 127 | 7225 | 16129 | 10795 | 143.25 | 367.36 | 263.91 | 10.03 |
| 94 | 155 | 8836 | 24025 | 14570 | 151.55 | 78.03 | 11.91 | 34.03 |
| 1058 | 1754 | 94520 | 258338 | 155788 | 1754 | 1961.67 | 906.57 | 1239.67 |
Значимость коэффициента корреляции
По таблице Стьюдента находим Tтабл
Tтабл (n-m-1;a) = (10;0.05) = 1.812
Поскольку Tнабл > Tтабл , то отклоняем гипотезу о равенстве 0 коэффициента корреляции. Другими словами, коэффициента корреляции статистически — значим.
Анализ точности определения оценок коэффициентов регрессии
S a = 0.2704
Доверительные интервалы для зависимой переменной
Рассчитаем границы интервала, в котором будет сосредоточено 95% возможных значений Y при неограниченно большом числе наблюдений и X = 88,16
(128.06;163.97)
Проверка гипотез относительно коэффициентов линейного уравнения регрессии
1) t-статистика
Статистическая значимость коэффициента регрессии a подтверждается (3.41>1.812).
Статистическая значимость коэффициента регрессии b подтверждается (2.7>1.812).
Доверительный интервал для коэффициентов уравнения регрессии
Определим доверительные интервалы коэффициентов регрессии, которые с надежность 95% будут следующими (tтабл=1.812):
(a — tтабл·S a; a + tтабл·Sa)
(0.4325;1.4126)
(b — tтабл·S b; b + tтабл·Sb)
(21.3389;108.3164)
2) F-статистики
Fkp = 4.96
Поскольку F > Fkp, то коэффициент детерминации статистически значим.
Пример №2 . По территориям региона приводятся данные за 199Х г.;
| Среднедневная заработная плата, руб., у | ||
| 1 | 78 | 133 |
| 2 | 82 | 148 |
| 3 | 87 | 134 |
| 4 | 79 | 154 |
| 5 | 89 | 162 |
| 6 | 106 | 195 |
| 7 | 67 | 139 |
| 8 | 88 | 158 |
| 9 | 73 | 152 |
| 10 | 87 | 162 |
| 11 | 76 | 159 |
| 12 | 115 | 173 |
1. Построить линейное уравнение парной регрессии у от х.
2. Рассчитать линейный коэффициент парной корреляции и среднюю ошибку аппроксимации.
3. Оценить статистическую значимость параметров регрессии и корреляции.
4. Выполнить прогноз заработной платы у при прогнозном значении среднедушевого прожиточного минимума х , составляющем 107% от среднего уровня.
5. Оценить точность прогноза, рассчитав ошибку прогноза и его доверительный интервал.
Решение находим с помощью калькулятора.
Использование графического метода .
Этот метод применяют для наглядного изображения формы связи между изучаемыми экономическими показателями. Для этого в прямоугольной системе координат строят график, по оси ординат откладывают индивидуальные значения результативного признака Y, а по оси абсцисс — индивидуальные значения факторного признака X.
Совокупность точек результативного и факторного признаков называется полем корреляции.
На основании поля корреляции можно выдвинуть гипотезу (для генеральной совокупности) о том, что связь между всеми возможными значениями X и Y носит линейный характер.
Линейное уравнение регрессии имеет вид y = bx + a + ε
Здесь ε — случайная ошибка (отклонение, возмущение).
Причины существования случайной ошибки:
1. Невключение в регрессионную модель значимых объясняющих переменных;
2. Агрегирование переменных. Например, функция суммарного потребления – это попытка общего выражения совокупности решений отдельных индивидов о расходах. Это лишь аппроксимация отдельных соотношений, которые имеют разные параметры.
3. Неправильное описание структуры модели;
4. Неправильная функциональная спецификация;
5. Ошибки измерения.
Так как отклонения εi для каждого конкретного наблюдения i – случайны и их значения в выборке неизвестны, то:
1) по наблюдениям xi и yi можно получить только оценки параметров α и β
2) Оценками параметров α и β регрессионной модели являются соответственно величины а и b, которые носят случайный характер, т.к. соответствуют случайной выборке;
Тогда оценочное уравнение регрессии (построенное по выборочным данным) будет иметь вид y = bx + a + ε, где ei – наблюдаемые значения (оценки) ошибок εi, а и b соответственно оценки параметров α и β регрессионной модели, которые следует найти.
Для оценки параметров α и β — используют МНК (метод наименьших квадратов).
Система нормальных уравнений.
Для наших данных система уравнений имеет вид
12a+1027b=1869
1027a+89907b=161808
Из первого уравнения выражаем а и подставим во второе уравнение. Получаем b = 0.92, a = 76.98
Уравнение регрессии: y = 0.92 x + 76.98 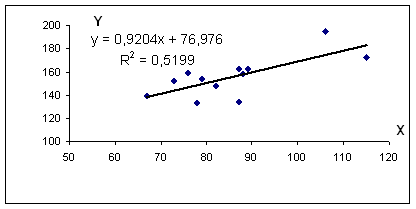
1. Параметры уравнения регрессии.
Выборочные средние.
Коэффициент корреляции
Рассчитываем показатель тесноты связи. Таким показателем является выборочный линейный коэффициент корреляции, который рассчитывается по формуле:
Линейный коэффициент корреляции принимает значения от –1 до +1.
Связи между признаками могут быть слабыми и сильными (тесными). Их критерии оцениваются по шкале Чеддока:
0.1 0 – прямая связь, иначе — обратная). В нашем примере связь прямая.
Коэффициент эластичности.
Коэффициенты регрессии (в примере b) нежелательно использовать для непосредственной оценки влияния факторов на результативный признак в том случае, если существует различие единиц измерения результативного показателя у и факторного признака х.
Для этих целей вычисляются коэффициенты эластичности и бета — коэффициенты. Коэффициент эластичности находится по формуле:
Он показывает, на сколько процентов в среднем изменяется результативный признак у при изменении факторного признака х на 1%. Он не учитывает степень колеблемости факторов.
Коэффициент эластичности меньше 1. Следовательно, при изменении среднедушевого прожиточного минимума в день на 1%, среднедневная заработная плата изменится менее чем на 1%. Другими словами — влияние среднедушевого прожиточного минимума Х на среднедневную заработную плату Y не существенно.
Бета – коэффициент показывает, на какую часть величины своего среднего квадратичного отклонения изменится в среднем значение результативного признака при изменении факторного признака на величину его среднеквадратического отклонения при фиксированном на постоянном уровне значении остальных независимых переменных:
Т.е. увеличение x на величину среднеквадратического отклонения этого показателя приведет к увеличению средней среднедневной заработной платы Y на 0.721 среднеквадратичного отклонения этого показателя.
1.4. Ошибка аппроксимации.
Оценим качество уравнения регрессии с помощью ошибки абсолютной аппроксимации.
Поскольку ошибка меньше 15%, то данное уравнение можно использовать в качестве регрессии.
Коэффициент детерминации.
Квадрат (множественного) коэффициента корреляции называется коэффициентом детерминации, который показывает долю вариации результативного признака, объясненную вариацией факторного признака.
Чаще всего, давая интерпретацию коэффициента детерминации, его выражают в процентах.
R 2 = 0.72 2 = 0.5199, т.е. в 51.99 % случаев изменения среднедушевого прожиточного минимума х приводят к изменению среднедневной заработной платы y. Другими словами — точность подбора уравнения регрессии — средняя. Остальные 48.01% изменения среднедневной заработной платы Y объясняются факторами, не учтенными в модели.
| y 2 | x·y | y(x) | (y i — y ) 2 | (y-y(x)) 2 | (x i — x ) 2 | |y-y x |:y | |||
| 78 | 133 | 6084 | 17689 | 10374 | 148,77 | 517,56 | 248,7 | 57,51 | 0,1186 |
| 82 | 148 | 6724 | 21904 | 12136 | 152,45 | 60,06 | 19,82 | 12,84 | 0,0301 |
| 87 | 134 | 7569 | 17956 | 11658 | 157,05 | 473,06 | 531,48 | 2,01 | 0,172 |
| 79 | 154 | 6241 | 23716 | 12166 | 149,69 | 3,06 | 18,57 | 43,34 | 0,028 |
| 89 | 162 | 7921 | 26244 | 14418 | 158,89 | 39,06 | 9,64 | 11,67 | 0,0192 |
| 106 | 195 | 11236 | 38025 | 20670 | 174,54 | 1540,56 | 418,52 | 416,84 | 0,1049 |
| 67 | 139 | 4489 | 19321 | 9313 | 138,65 | 280,56 | 0,1258 | 345,34 | 0,0026 |
| 88 | 158 | 7744 | 24964 | 13904 | 157,97 | 5,06 | 0,0007 | 5,84 | 0,0002 |
| 73 | 152 | 5329 | 23104 | 11096 | 144,17 | 14,06 | 61,34 | 158,34 | 0,0515 |
| 87 | 162 | 7569 | 26244 | 14094 | 157,05 | 39,06 | 24,46 | 2,01 | 0,0305 |
| 76 | 159 | 5776 | 25281 | 12084 | 146,93 | 10,56 | 145,7 | 91,84 | 0,0759 |
| 115 | 173 | 13225 | 29929 | 19895 | 182,83 | 297,56 | 96,55 | 865,34 | 0,0568 |
| 1027 | 1869 | 89907 | 294377 | 161808 | 1869 | 3280,25 | 1574,92 | 2012,92 | 0,6902 |
2.1. Значимость коэффициента корреляции.
По таблице Стьюдента с уровнем значимости α=0.05 и степенями свободы k=10 находим tкрит:
tкрит = (10;0.05) = 1.812
где m = 1 — количество объясняющих переменных.
Если tнабл > tкритич, то полученное значение коэффициента корреляции признается значимым (нулевая гипотеза, утверждающая равенство нулю коэффициента корреляции, отвергается).
Поскольку tнабл > tкрит, то отклоняем гипотезу о равенстве 0 коэффициента корреляции. Другими словами, коэффициент корреляции статистически — значим.
В парной линейной регрессии t 2 r = t 2 b и тогда проверка гипотез о значимости коэффициентов регрессии и корреляции равносильна проверке гипотезы о существенности линейного уравнения регрессии.
2.3. Анализ точности определения оценок коэффициентов регрессии.
Несмещенной оценкой дисперсии возмущений является величина:
S 2 y = 157.4922 — необъясненная дисперсия (мера разброса зависимой переменной вокруг линии регрессии).
12.5496 — стандартная ошибка оценки (стандартная ошибка регрессии).
S a — стандартное отклонение случайной величины a.
Sb — стандартное отклонение случайной величины b.
2.4. Доверительные интервалы для зависимой переменной.
Экономическое прогнозирование на основе построенной модели предполагает, что сохраняются ранее существовавшие взаимосвязи переменных и на период упреждения.
Для прогнозирования зависимой переменной результативного признака необходимо знать прогнозные значения всех входящих в модель факторов.
Прогнозные значения факторов подставляют в модель и получают точечные прогнозные оценки изучаемого показателя.
(a + bxp ± ε)
где
Рассчитаем границы интервала, в котором будет сосредоточено 95% возможных значений Y при неограниченно большом числе наблюдений и X p = 94
(76.98 + 0.92*94 ± 7.8288)
(155.67;171.33)
С вероятностью 95% можно гарантировать, что значения Y при неограниченно большом числе наблюдений не выйдет за пределы найденных интервалов.
2.5. Проверка гипотез относительно коэффициентов линейного уравнения регрессии.
1) t-статистика. Критерий Стьюдента.
Проверим гипотезу H0 о равенстве отдельных коэффициентов регрессии нулю (при альтернативе H1 не равно) на уровне значимости α=0.05.
tкрит = (10;0.05) = 1.812
Поскольку 3.2906 > 1.812, то статистическая значимость коэффициента регрессии b подтверждается (отвергаем гипотезу о равенстве нулю этого коэффициента).
Поскольку 3.1793 > 1.812, то статистическая значимость коэффициента регрессии a подтверждается (отвергаем гипотезу о равенстве нулю этого коэффициента).
Доверительный интервал для коэффициентов уравнения регрессии.
Определим доверительные интервалы коэффициентов регрессии, которые с надежность 95% будут следующими:
(b — tкрит Sb; b + tкрит Sb)
(0.9204 — 1.812·0.2797; 0.9204 + 1.812·0.2797)
(0.4136;1.4273)
С вероятностью 95% можно утверждать, что значение данного параметра будут лежать в найденном интервале.
(a-ta)
(76.9765 — 1.812·24.2116; 76.9765 + 1.812·24.2116)
(33.1051;120.8478)
С вероятностью 95% можно утверждать, что значение данного параметра будут лежать в найденном интервале.
2) F-статистики. Критерий Фишера.
Проверка значимости модели регрессии проводится с использованием F-критерия Фишера, расчетное значение которого находится как отношение дисперсии исходного ряда наблюдений изучаемого показателя и несмещенной оценки дисперсии остаточной последовательности для данной модели.
Если расчетное значение с k1=(m) и k2=(n-m-1) степенями свободы больше табличного при заданном уровне значимости, то модель считается значимой.
где m – число факторов в модели.
Оценка статистической значимости парной линейной регрессии производится по следующему алгоритму:
1. Выдвигается нулевая гипотеза о том, что уравнение в целом статистически незначимо: H0: R 2 =0 на уровне значимости α.
2. Далее определяют фактическое значение F-критерия:
где m=1 для парной регрессии.
3. Табличное значение определяется по таблицам распределения Фишера для заданного уровня значимости, принимая во внимание, что число степеней свободы для общей суммы квадратов (большей дисперсии) равно 1 и число степеней свободы остаточной суммы квадратов (меньшей дисперсии) при линейной регрессии равно n-2.
4. Если фактическое значение F-критерия меньше табличного, то говорят, что нет основания отклонять нулевую гипотезу.
В противном случае, нулевая гипотеза отклоняется и с вероятностью (1-α) принимается альтернативная гипотеза о статистической значимости уравнения в целом.
Табличное значение критерия со степенями свободы k1=1 и k2=10, Fkp = 4.96
Поскольку фактическое значение F > Fkp, то коэффициент детерминации статистически значим (Найденная оценка уравнения регрессии статистически надежна).
http://economy-ru.info/info/75588/
http://math.semestr.ru/corel/prim3.php