Пример нахождения статистической значимости коэффициентов регрессии
Числитель в этой формуле может быть рассчитан через коэффициент детерминации и общую дисперсию признака-результата:  .
.
Для параметра a критерий проверки гипотезы о незначимом отличии его от нуля имеет вид:
,
где — оценка параметра регрессии, полученная по наблюдаемым данным;
μa – стандартная ошибка параметра a.
Для линейного парного уравнения регрессии: .
Для проверки гипотезы о незначимом отличии от нуля коэффициента линейной парной корреляции в генеральной совокупности используют следующий критерий: , где ryx — оценка коэффициента корреляции, полученная по наблюдаемым данным; mr – стандартная ошибка коэффициента корреляции ryx.
Для линейного парного уравнения регрессии: .
В парной линейной регрессии между наблюдаемыми значениями критериев существует взаимосвязь: t ( b =0) = t (r=0).
Пример №1 . Уравнение имеет вид y=ax+b
1. Параметры уравнения регрессии.
Средние значения
Связь между признаком Y фактором X сильная и прямая
Уравнение регрессии
Коэффициент детерминации
R 2 = 0.73 2 = 0.54, т.е. в 54% случаев изменения х приводят к изменению y . Другими словами — точность подбора уравнения регрессии — средняя.
| x | y | x 2 | y 2 | x ∙ y | y(x) | (y-y cp ) 2 | (y-y(x)) 2 | (x-x p ) 2 |
| 69 | 124 | 4761 | 15376 | 8556 | 128.48 | 491.36 | 20.11 | 367.36 |
| 83 | 133 | 6889 | 17689 | 11039 | 141.4 | 173.36 | 70.56 | 26.69 |
| 92 | 146 | 8464 | 21316 | 13432 | 149.7 | 0.03 | 13.71 | 14.69 |
| 97 | 153 | 9409 | 23409 | 14841 | 154.32 | 46.69 | 1.73 | 78.03 |
| 88 | 138 | 7744 | 19044 | 12144 | 146.01 | 66.69 | 64.21 | 0.03 |
| 93 | 159 | 8649 | 25281 | 14787 | 150.63 | 164.69 | 70.13 | 23.36 |
| 74 | 145 | 5476 | 21025 | 10730 | 133.1 | 1.36 | 141.68 | 200.69 |
| 79 | 152 | 6241 | 23104 | 12008 | 137.71 | 34.03 | 204.21 | 84.03 |
| 105 | 168 | 11025 | 28224 | 17640 | 161.7 | 476.69 | 39.74 | 283.36 |
| 99 | 154 | 9801 | 23716 | 15246 | 156.16 | 61.36 | 4.67 | 117.36 |
| 85 | 127 | 7225 | 16129 | 10795 | 143.25 | 367.36 | 263.91 | 10.03 |
| 94 | 155 | 8836 | 24025 | 14570 | 151.55 | 78.03 | 11.91 | 34.03 |
| 1058 | 1754 | 94520 | 258338 | 155788 | 1754 | 1961.67 | 906.57 | 1239.67 |
Значимость коэффициента корреляции
По таблице Стьюдента находим Tтабл
Tтабл (n-m-1;a) = (10;0.05) = 1.812
Поскольку Tнабл > Tтабл , то отклоняем гипотезу о равенстве 0 коэффициента корреляции. Другими словами, коэффициента корреляции статистически — значим.
Анализ точности определения оценок коэффициентов регрессии
S a = 0.2704
Доверительные интервалы для зависимой переменной
Рассчитаем границы интервала, в котором будет сосредоточено 95% возможных значений Y при неограниченно большом числе наблюдений и X = 88,16
(128.06;163.97)
Проверка гипотез относительно коэффициентов линейного уравнения регрессии
1) t-статистика
Статистическая значимость коэффициента регрессии a подтверждается (3.41>1.812).
Статистическая значимость коэффициента регрессии b подтверждается (2.7>1.812).
Доверительный интервал для коэффициентов уравнения регрессии
Определим доверительные интервалы коэффициентов регрессии, которые с надежность 95% будут следующими (tтабл=1.812):
(a — tтабл·S a; a + tтабл·Sa)
(0.4325;1.4126)
(b — tтабл·S b; b + tтабл·Sb)
(21.3389;108.3164)
2) F-статистики
Fkp = 4.96
Поскольку F > Fkp, то коэффициент детерминации статистически значим.
Пример №2 . По территориям региона приводятся данные за 199Х г.;
| Среднедневная заработная плата, руб., у | ||
| 1 | 78 | 133 |
| 2 | 82 | 148 |
| 3 | 87 | 134 |
| 4 | 79 | 154 |
| 5 | 89 | 162 |
| 6 | 106 | 195 |
| 7 | 67 | 139 |
| 8 | 88 | 158 |
| 9 | 73 | 152 |
| 10 | 87 | 162 |
| 11 | 76 | 159 |
| 12 | 115 | 173 |
1. Построить линейное уравнение парной регрессии у от х.
2. Рассчитать линейный коэффициент парной корреляции и среднюю ошибку аппроксимации.
3. Оценить статистическую значимость параметров регрессии и корреляции.
4. Выполнить прогноз заработной платы у при прогнозном значении среднедушевого прожиточного минимума х , составляющем 107% от среднего уровня.
5. Оценить точность прогноза, рассчитав ошибку прогноза и его доверительный интервал.
Решение находим с помощью калькулятора.
Использование графического метода .
Этот метод применяют для наглядного изображения формы связи между изучаемыми экономическими показателями. Для этого в прямоугольной системе координат строят график, по оси ординат откладывают индивидуальные значения результативного признака Y, а по оси абсцисс — индивидуальные значения факторного признака X.
Совокупность точек результативного и факторного признаков называется полем корреляции.
На основании поля корреляции можно выдвинуть гипотезу (для генеральной совокупности) о том, что связь между всеми возможными значениями X и Y носит линейный характер.
Линейное уравнение регрессии имеет вид y = bx + a + ε
Здесь ε — случайная ошибка (отклонение, возмущение).
Причины существования случайной ошибки:
1. Невключение в регрессионную модель значимых объясняющих переменных;
2. Агрегирование переменных. Например, функция суммарного потребления – это попытка общего выражения совокупности решений отдельных индивидов о расходах. Это лишь аппроксимация отдельных соотношений, которые имеют разные параметры.
3. Неправильное описание структуры модели;
4. Неправильная функциональная спецификация;
5. Ошибки измерения.
Так как отклонения εi для каждого конкретного наблюдения i – случайны и их значения в выборке неизвестны, то:
1) по наблюдениям xi и yi можно получить только оценки параметров α и β
2) Оценками параметров α и β регрессионной модели являются соответственно величины а и b, которые носят случайный характер, т.к. соответствуют случайной выборке;
Тогда оценочное уравнение регрессии (построенное по выборочным данным) будет иметь вид y = bx + a + ε, где ei – наблюдаемые значения (оценки) ошибок εi, а и b соответственно оценки параметров α и β регрессионной модели, которые следует найти.
Для оценки параметров α и β — используют МНК (метод наименьших квадратов).
Система нормальных уравнений.
Для наших данных система уравнений имеет вид
12a+1027b=1869
1027a+89907b=161808
Из первого уравнения выражаем а и подставим во второе уравнение. Получаем b = 0.92, a = 76.98
Уравнение регрессии: y = 0.92 x + 76.98 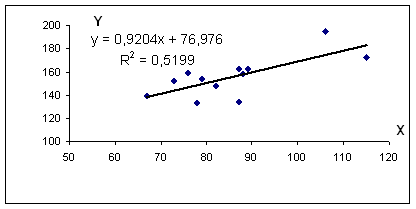
1. Параметры уравнения регрессии.
Выборочные средние.
Коэффициент корреляции
Рассчитываем показатель тесноты связи. Таким показателем является выборочный линейный коэффициент корреляции, который рассчитывается по формуле:
Линейный коэффициент корреляции принимает значения от –1 до +1.
Связи между признаками могут быть слабыми и сильными (тесными). Их критерии оцениваются по шкале Чеддока:
0.1 0 – прямая связь, иначе — обратная). В нашем примере связь прямая.
Коэффициент эластичности.
Коэффициенты регрессии (в примере b) нежелательно использовать для непосредственной оценки влияния факторов на результативный признак в том случае, если существует различие единиц измерения результативного показателя у и факторного признака х.
Для этих целей вычисляются коэффициенты эластичности и бета — коэффициенты. Коэффициент эластичности находится по формуле:
Он показывает, на сколько процентов в среднем изменяется результативный признак у при изменении факторного признака х на 1%. Он не учитывает степень колеблемости факторов.
Коэффициент эластичности меньше 1. Следовательно, при изменении среднедушевого прожиточного минимума в день на 1%, среднедневная заработная плата изменится менее чем на 1%. Другими словами — влияние среднедушевого прожиточного минимума Х на среднедневную заработную плату Y не существенно.
Бета – коэффициент показывает, на какую часть величины своего среднего квадратичного отклонения изменится в среднем значение результативного признака при изменении факторного признака на величину его среднеквадратического отклонения при фиксированном на постоянном уровне значении остальных независимых переменных:
Т.е. увеличение x на величину среднеквадратического отклонения этого показателя приведет к увеличению средней среднедневной заработной платы Y на 0.721 среднеквадратичного отклонения этого показателя.
1.4. Ошибка аппроксимации.
Оценим качество уравнения регрессии с помощью ошибки абсолютной аппроксимации.
Поскольку ошибка меньше 15%, то данное уравнение можно использовать в качестве регрессии.
Коэффициент детерминации.
Квадрат (множественного) коэффициента корреляции называется коэффициентом детерминации, который показывает долю вариации результативного признака, объясненную вариацией факторного признака.
Чаще всего, давая интерпретацию коэффициента детерминации, его выражают в процентах.
R 2 = 0.72 2 = 0.5199, т.е. в 51.99 % случаев изменения среднедушевого прожиточного минимума х приводят к изменению среднедневной заработной платы y. Другими словами — точность подбора уравнения регрессии — средняя. Остальные 48.01% изменения среднедневной заработной платы Y объясняются факторами, не учтенными в модели.
| y 2 | x·y | y(x) | (y i — y ) 2 | (y-y(x)) 2 | (x i — x ) 2 | |y-y x |:y | |||
| 78 | 133 | 6084 | 17689 | 10374 | 148,77 | 517,56 | 248,7 | 57,51 | 0,1186 |
| 82 | 148 | 6724 | 21904 | 12136 | 152,45 | 60,06 | 19,82 | 12,84 | 0,0301 |
| 87 | 134 | 7569 | 17956 | 11658 | 157,05 | 473,06 | 531,48 | 2,01 | 0,172 |
| 79 | 154 | 6241 | 23716 | 12166 | 149,69 | 3,06 | 18,57 | 43,34 | 0,028 |
| 89 | 162 | 7921 | 26244 | 14418 | 158,89 | 39,06 | 9,64 | 11,67 | 0,0192 |
| 106 | 195 | 11236 | 38025 | 20670 | 174,54 | 1540,56 | 418,52 | 416,84 | 0,1049 |
| 67 | 139 | 4489 | 19321 | 9313 | 138,65 | 280,56 | 0,1258 | 345,34 | 0,0026 |
| 88 | 158 | 7744 | 24964 | 13904 | 157,97 | 5,06 | 0,0007 | 5,84 | 0,0002 |
| 73 | 152 | 5329 | 23104 | 11096 | 144,17 | 14,06 | 61,34 | 158,34 | 0,0515 |
| 87 | 162 | 7569 | 26244 | 14094 | 157,05 | 39,06 | 24,46 | 2,01 | 0,0305 |
| 76 | 159 | 5776 | 25281 | 12084 | 146,93 | 10,56 | 145,7 | 91,84 | 0,0759 |
| 115 | 173 | 13225 | 29929 | 19895 | 182,83 | 297,56 | 96,55 | 865,34 | 0,0568 |
| 1027 | 1869 | 89907 | 294377 | 161808 | 1869 | 3280,25 | 1574,92 | 2012,92 | 0,6902 |
2.1. Значимость коэффициента корреляции.
По таблице Стьюдента с уровнем значимости α=0.05 и степенями свободы k=10 находим tкрит:
tкрит = (10;0.05) = 1.812
где m = 1 — количество объясняющих переменных.
Если tнабл > tкритич, то полученное значение коэффициента корреляции признается значимым (нулевая гипотеза, утверждающая равенство нулю коэффициента корреляции, отвергается).
Поскольку tнабл > tкрит, то отклоняем гипотезу о равенстве 0 коэффициента корреляции. Другими словами, коэффициент корреляции статистически — значим.
В парной линейной регрессии t 2 r = t 2 b и тогда проверка гипотез о значимости коэффициентов регрессии и корреляции равносильна проверке гипотезы о существенности линейного уравнения регрессии.
2.3. Анализ точности определения оценок коэффициентов регрессии.
Несмещенной оценкой дисперсии возмущений является величина:
S 2 y = 157.4922 — необъясненная дисперсия (мера разброса зависимой переменной вокруг линии регрессии).
12.5496 — стандартная ошибка оценки (стандартная ошибка регрессии).
S a — стандартное отклонение случайной величины a.
Sb — стандартное отклонение случайной величины b.
2.4. Доверительные интервалы для зависимой переменной.
Экономическое прогнозирование на основе построенной модели предполагает, что сохраняются ранее существовавшие взаимосвязи переменных и на период упреждения.
Для прогнозирования зависимой переменной результативного признака необходимо знать прогнозные значения всех входящих в модель факторов.
Прогнозные значения факторов подставляют в модель и получают точечные прогнозные оценки изучаемого показателя.
(a + bxp ± ε)
где
Рассчитаем границы интервала, в котором будет сосредоточено 95% возможных значений Y при неограниченно большом числе наблюдений и X p = 94
(76.98 + 0.92*94 ± 7.8288)
(155.67;171.33)
С вероятностью 95% можно гарантировать, что значения Y при неограниченно большом числе наблюдений не выйдет за пределы найденных интервалов.
2.5. Проверка гипотез относительно коэффициентов линейного уравнения регрессии.
1) t-статистика. Критерий Стьюдента.
Проверим гипотезу H0 о равенстве отдельных коэффициентов регрессии нулю (при альтернативе H1 не равно) на уровне значимости α=0.05.
tкрит = (10;0.05) = 1.812
Поскольку 3.2906 > 1.812, то статистическая значимость коэффициента регрессии b подтверждается (отвергаем гипотезу о равенстве нулю этого коэффициента).
Поскольку 3.1793 > 1.812, то статистическая значимость коэффициента регрессии a подтверждается (отвергаем гипотезу о равенстве нулю этого коэффициента).
Доверительный интервал для коэффициентов уравнения регрессии.
Определим доверительные интервалы коэффициентов регрессии, которые с надежность 95% будут следующими:
(b — tкрит Sb; b + tкрит Sb)
(0.9204 — 1.812·0.2797; 0.9204 + 1.812·0.2797)
(0.4136;1.4273)
С вероятностью 95% можно утверждать, что значение данного параметра будут лежать в найденном интервале.
(a-ta)
(76.9765 — 1.812·24.2116; 76.9765 + 1.812·24.2116)
(33.1051;120.8478)
С вероятностью 95% можно утверждать, что значение данного параметра будут лежать в найденном интервале.
2) F-статистики. Критерий Фишера.
Проверка значимости модели регрессии проводится с использованием F-критерия Фишера, расчетное значение которого находится как отношение дисперсии исходного ряда наблюдений изучаемого показателя и несмещенной оценки дисперсии остаточной последовательности для данной модели.
Если расчетное значение с k1=(m) и k2=(n-m-1) степенями свободы больше табличного при заданном уровне значимости, то модель считается значимой.
где m – число факторов в модели.
Оценка статистической значимости парной линейной регрессии производится по следующему алгоритму:
1. Выдвигается нулевая гипотеза о том, что уравнение в целом статистически незначимо: H0: R 2 =0 на уровне значимости α.
2. Далее определяют фактическое значение F-критерия:
где m=1 для парной регрессии.
3. Табличное значение определяется по таблицам распределения Фишера для заданного уровня значимости, принимая во внимание, что число степеней свободы для общей суммы квадратов (большей дисперсии) равно 1 и число степеней свободы остаточной суммы квадратов (меньшей дисперсии) при линейной регрессии равно n-2.
4. Если фактическое значение F-критерия меньше табличного, то говорят, что нет основания отклонять нулевую гипотезу.
В противном случае, нулевая гипотеза отклоняется и с вероятностью (1-α) принимается альтернативная гипотеза о статистической значимости уравнения в целом.
Табличное значение критерия со степенями свободы k1=1 и k2=10, Fkp = 4.96
Поскольку фактическое значение F > Fkp, то коэффициент детерминации статистически значим (Найденная оценка уравнения регрессии статистически надежна).
Лекция 7. Парная регрессия. Оценка статистической значимости параметров уравнения и модели в целом.
ТЕМА 4. СТАТИСТИЧЕСКИЕ МЕТОДЫ ИЗУЧЕНИЯ СВЯЗЕЙ
Уравнение регрессии —этоаналитическое представление корреляционной зависимости. Уравнение регрессии описывает гипотетическую функциональную зависимость между условным средним значением результативного признака и значением признака – фактора (факторов), т.е. основную тенденцию зависимости.
Парная корреляционная зависимость описывается уравнением парной регрессии, множественная корреляционная зависимость – уравнением множественной регрессии.
Признак-результат в уравнении регрессии – это зависимая переменная (отклик, объясняемая переменная), а признак-фактор – независимая переменная (аргумент, объясняющая переменная).
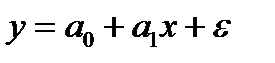 Простейшим видом уравнения регрессии является уравнение парной линейной зависимости:
Простейшим видом уравнения регрессии является уравнение парной линейной зависимости:
где y – зависимая переменная (признак-результат); x – независимая переменная (признак-фактор); 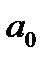 и
и  – параметры уравнения регрессии;
– параметры уравнения регрессии; 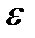 — ошибка оценивания.
— ошибка оценивания.
В качестве уравнения регрессии могут быть использованы различные математические функции. Частое практическое применение находят уравнения линейной зависимости, параболы, гиперболы, степной функции и др.
Как правило, анализ начинается с оценки линейной зависимости, поскольку результаты легко поддаются содержательной интерпретации. Выбор типа уравнения связи – достаточно ответственный этап анализа. В «докомпьютерную» эпоху эта процедура была сопряжена с определенными сложностями и требовала от аналитика знания свойств математических функций. В настоящее время на базе специализированных программ можно оперативно построить множество уравнений связи и на основе формальных критериев осуществить выбор лучшей модели (однако математическая грамотность аналитика не утратила своей актуальности).
Гипотезу о типе корреляционной зависимости можно выдвинуть по результатам построения поля корреляции (см. лекцию 6). Исходя из характера расположения точек на графике (координаты точек соответствуют значениям зависимой и независимой переменных), выявляется тенденция связи между признаками (показателями). Если линия регрессии проходит через все точки поля корреляции, то эта свидетельствует о функциональной связи. В практике социально-экономических исследований такую картину наблюдать не приходится, поскольку присутствует статистическая (корреляционная) зависимость. В условиях корреляционной зависимости при нанесении линии регрессии на диаграмму рассеивания наблюдается отклонение точек поля корреляции от линии регрессии, что демонстрирует, так называемые, остатки или ошибки оценивания (см. рисунок 7.1).
Наличие ошибки уравнения связано с тем, что:
§ не все факторы, влияющие на результат, учитываются в уравнении регрессии;
§ может быть неверно выбранаформа связи — уравнение регрессии;
§ не все факторы включены в уравнение.
Построить уравнение регрессии – означает рассчитать значения его параметров. Уравнение регрессии строится на основе фактических значений анализируемых признаков. Расчет параметров, как правило, выполняется с использованием метода наименьших квадратов (МНК).
Суть МНКсостоит в том, что удается получить такие значения параметров уравнения, при которых минимизируется сумма квадратов отклонений теоретических значений признака-результата (рассчитанных на основе уравнения регрессии), от фактических его значений:
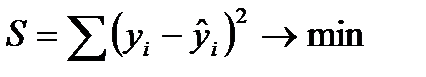 ,
,
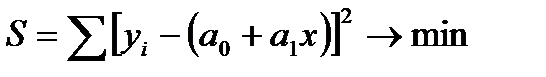 , (7.2)
, (7.2)
 где
где 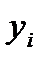 — фактическое значение признака-результата у i-й единицы совокупности;
— фактическое значение признака-результата у i-й единицы совокупности; 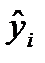 — значение признака-результата у i-й единицы совокупности, полученное по уравнению регрессии ( ).
— значение признака-результата у i-й единицы совокупности, полученное по уравнению регрессии ( ).
Т.о., решается задача на экстремум, то есть необходимо найти, при каких значениях параметров, функция S достигает минимума.
Проводя дифференцирование, приравнивая частные производные нулю:
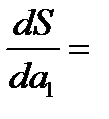

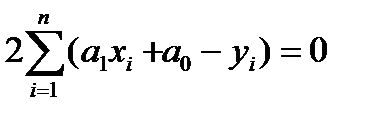

и далее, решая систему нормальных уравнений, находят значения параметров и :
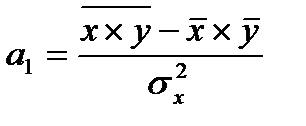 , (7.3)
, (7.3)
 , (7.4)
, (7.4)
где 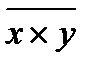 — среднее произведение значений фактора и результата;
— среднее произведение значений фактора и результата; 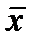 — среднее значение признака — фактора;
— среднее значение признака — фактора; 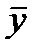 — среднее значение признака -результата;
— среднее значение признака -результата; 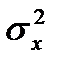 — дисперсия признака-фактора.
— дисперсия признака-фактора.
Параметр 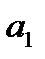 в уравнении регрессии характеризует угол наклона линии регрессии на графике. Этот параметр называют коэффициентом регрессии и его величина характеризует, на сколько единиц своего измерения изменится признак-результат при изменении признака-фактора на единицу своего измерения. Знак при коэффициенте регрессии отражает направленность зависимости (прямая или обратная) и совпадает со знаком коэффициента корреляции (в условиях парной зависимости).
в уравнении регрессии характеризует угол наклона линии регрессии на графике. Этот параметр называют коэффициентом регрессии и его величина характеризует, на сколько единиц своего измерения изменится признак-результат при изменении признака-фактора на единицу своего измерения. Знак при коэффициенте регрессии отражает направленность зависимости (прямая или обратная) и совпадает со знаком коэффициента корреляции (в условиях парной зависимости).
В рамках рассматриваемого примера, в программе STATISTICA рассчитаны параметры уравнения регрессии, описывающего зависимость между уровнем среднедушевых денежных доходов населения и величиной валового регионального продукта на душу населения в регионах России, см. таблицу 7.1.
Таблица 7.1 — Расчет и оценка параметров уравнения, описывающего зависимостьмежду уровнем среднедушевых денежных доходов населения и величиной валового регионального продукта на душу населения в регионах России, 2013 г.
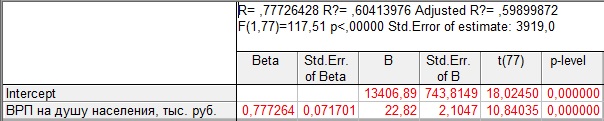
В графе «В» таблицы содержатся значения параметров уравнения парной регрессии, следовательно, можно записать: 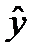 = 13406,89 + 22,82 x.Данное уравнение описывает тенденцию связи между анализируемыми характеристиками. Параметр — это коэффициент регрессии. В данном случае он равен 22,82 и характеризует следующее: при увеличении ВРП на душу населения на 1 тыс.рублей среднедушевые денежные доходы в среднем возрастают (на что указывает знак «+») на 22,28 руб.
= 13406,89 + 22,82 x.Данное уравнение описывает тенденцию связи между анализируемыми характеристиками. Параметр — это коэффициент регрессии. В данном случае он равен 22,82 и характеризует следующее: при увеличении ВРП на душу населения на 1 тыс.рублей среднедушевые денежные доходы в среднем возрастают (на что указывает знак «+») на 22,28 руб.
Параметр 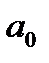 уравнения регрессии в социально-экономических исследованиях, как правило, содержательно не интерпретируется. Формально он отражает величину признака — результата при условии, что признак — фактор равен нулю. Параметр характеризует расположение линии регрессии на графике, см. рисунок 7.1.
уравнения регрессии в социально-экономических исследованиях, как правило, содержательно не интерпретируется. Формально он отражает величину признака — результата при условии, что признак — фактор равен нулю. Параметр характеризует расположение линии регрессии на графике, см. рисунок 7.1.
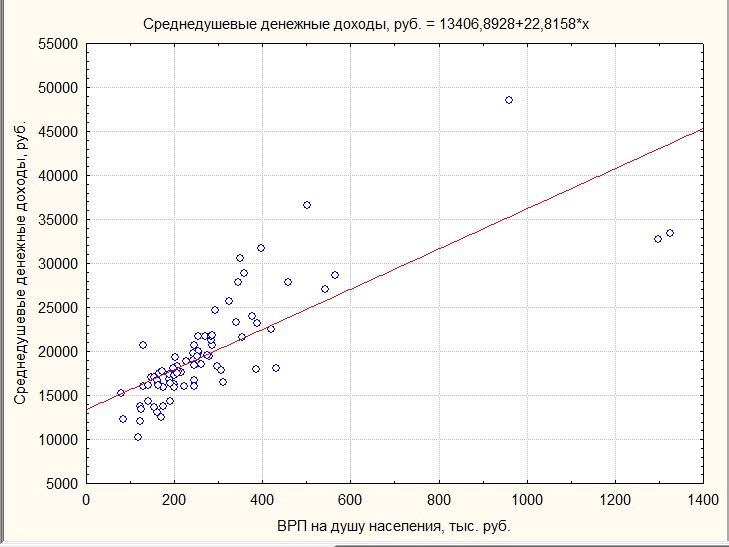
Рисунок 7.1 — Поле корреляции и линия регрессии, отражающие зависимость уровня среднедушевых денежных доходов населения в регионах России и величины ВРП на душу населения
Значение параметра соответствует точке пересечения линии регрессии с осью Y, при X=0.
Построение уравнения регрессии сопровождается оценкой статистической значимости уравнения в целом и его параметров. Необходимость таких процедур связана с ограниченным объемом данных, что может препятствовать действию закона больших чисел и, следовательно, выявлению истинной тенденции во взаимосвязи анализируемых показателей. Кроме того, любую исследуемую совокупность можно рассматривать как выборку из генеральной совокупности, а характеристики, полученные в ходе анализа, как оценку генеральных параметров.
Оценка статистической значимости параметров и уравнения в целом – это обоснование возможности использования построенной модели связи для принятия управленческих решений и прогнозирования (моделирования).
Статистическая значимость уравнения регрессиив целом оценивается с использованием F-критерия Фишера, который представляет собой отношение факторной и остаточных дисперсий, рассчитанных на одну степень свободы:
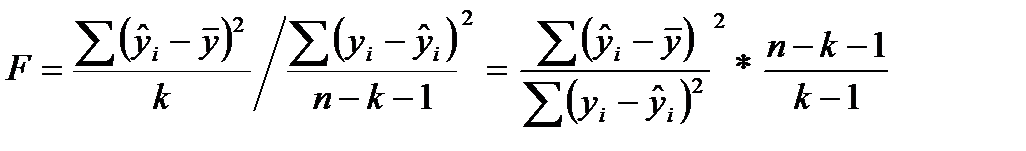 (7.5)
(7.5)
где 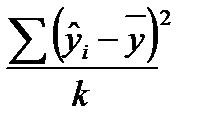 — факторная дисперсия признака — результата; k – число степеней свободы факторной дисперсии (число факторов в уравнении регрессии);
— факторная дисперсия признака — результата; k – число степеней свободы факторной дисперсии (число факторов в уравнении регрессии); 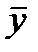 — среднее значение зависимой переменной;
— среднее значение зависимой переменной; 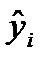 — теоретическое (полученной по уравнению регрессии) значение зависимой переменной у i – й единицы совокупности;
— теоретическое (полученной по уравнению регрессии) значение зависимой переменной у i – й единицы совокупности; 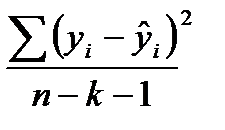 — остаточная дисперсии признака — результата; n – объем совокупности; n-k-1 – число степеней свободы остаточной дисперсии.
— остаточная дисперсии признака — результата; n – объем совокупности; n-k-1 – число степеней свободы остаточной дисперсии.
Величина F-критерия Фишера, согласно формуле, характеризует соотношение между факторной и остаточной дисперсиями зависимой переменной, демонстрируя, по существу, во сколько раз величина объясненной части вариации превышает необъясненную.
F-критерий Фишера табулирован, входом в таблицу является число степеней свободы факторной и остаточной дисперсий. Сравнение расчетного значения критерия с табличным (критическим) позволяет ответить на вопрос: статистически значима ли та часть вариации признака-результата, которую удается объяснить факторами, включенными в уравнение данного вида. Если 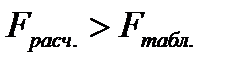 , то уравнение регрессии признается статистически значимым и, соответственно, статистически значим и коэффициент детерминации. В противном случае (
, то уравнение регрессии признается статистически значимым и, соответственно, статистически значим и коэффициент детерминации. В противном случае ( 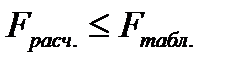 ), уравнение – статистически незначимо, т.е. вариация учтенных в уравнении факторов не объясняет статистически значимой части вариации признака-результата, либо не верно выбрано уравнение связи.
), уравнение – статистически незначимо, т.е. вариация учтенных в уравнении факторов не объясняет статистически значимой части вариации признака-результата, либо не верно выбрано уравнение связи.
Оценка статистической значимости параметров уравнения осуществляется на основе t-статистики, которая рассчитывается как отношение модуля параметров уравнения регрессии к их стандартным ошибкам (  ):
):
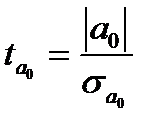 , где
, где 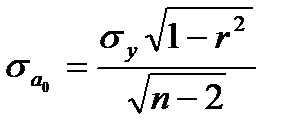 ; (7.6)
; (7.6)
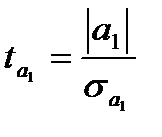 , где
, где 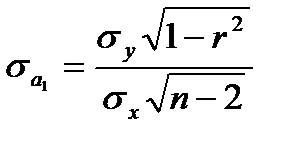 ; (7.7)
; (7.7)
где 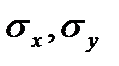 — стандартные отклонения признака — фактора и признака — результата;
— стандартные отклонения признака — фактора и признака — результата; 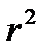 — коэффициент детерминации.
— коэффициент детерминации.
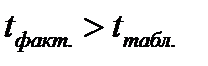 В специализированных статистических программах расчет параметров всегда сопровождается расчетом значений их стандартных (среднеквадратических) ошибок и t-статистики (см. таблицу 7.1). Расчетное значение t-статистики сравнивается с табличным, если объем изучаемой совокупности менее 30 единиц (безусловно малая выборка), следует обратиться к таблице t- распределения Стьюдента, если объем совокупности большой, следует воспользоваться таблицей нормального распределения (интеграла вероятностей Лапласа). Параметр уравнения признается статистически значимым, если .
В специализированных статистических программах расчет параметров всегда сопровождается расчетом значений их стандартных (среднеквадратических) ошибок и t-статистики (см. таблицу 7.1). Расчетное значение t-статистики сравнивается с табличным, если объем изучаемой совокупности менее 30 единиц (безусловно малая выборка), следует обратиться к таблице t- распределения Стьюдента, если объем совокупности большой, следует воспользоваться таблицей нормального распределения (интеграла вероятностей Лапласа). Параметр уравнения признается статистически значимым, если .
Оценка параметров на основе t-статистики, по существу, является проверкой нулевой гипотезы о равенстве генеральных параметров нулю (H0: 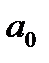 =0; H0:
=0; H0: 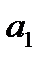 =0;), то есть о статистически не значимой величине параметров уравнения регрессии. Уровень значимости гипотезы, как правило, принимается:
=0;), то есть о статистически не значимой величине параметров уравнения регрессии. Уровень значимости гипотезы, как правило, принимается:  = 0,05. Если расчетный уровень значимости меньше 0,05 , то нулевая гипотеза отвергается и принимается альтернативная — о статистической значимости параметра.
= 0,05. Если расчетный уровень значимости меньше 0,05 , то нулевая гипотеза отвергается и принимается альтернативная — о статистической значимости параметра.
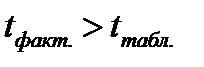 Продолжим рассмотрение примера. В таблице 7.1 в графе «B» приведены значения параметров, в графе Std.Err.ofB — величины стандартных ошибок параметров ( ), в графе t(77 – число степеней свободы) рассчитаны значения t — статистики с учетом числа степеней свободы. Для оценки статистической значимости параметров расчетные значения t — статистик необходимо сравнить с табличным значением. Заданному уровню значимости (0,05) в таблице нормального распределения соответствует t = 1,96. Поскольку
Продолжим рассмотрение примера. В таблице 7.1 в графе «B» приведены значения параметров, в графе Std.Err.ofB — величины стандартных ошибок параметров ( ), в графе t(77 – число степеней свободы) рассчитаны значения t — статистики с учетом числа степеней свободы. Для оценки статистической значимости параметров расчетные значения t — статистик необходимо сравнить с табличным значением. Заданному уровню значимости (0,05) в таблице нормального распределения соответствует t = 1,96. Поскольку 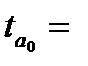 18,02,
18,02,  10,84, т.е. , следует признать статистическую значимость полученных значений параметров, т.е. эти значения сформированы под влиянием не случайных факторов и отражают тенденцию связи между анализируемыми показателями.
10,84, т.е. , следует признать статистическую значимость полученных значений параметров, т.е. эти значения сформированы под влиянием не случайных факторов и отражают тенденцию связи между анализируемыми показателями.
Для оценки статистической значимости уравнения в целом обратимся к значению F-критерия Фишера (см. таблицу 7.1). Расчетное значение F-критерия = 117,51, табличное значение критерия, исходя из соответствующего числа степеней свободы (для факторной дисперсии d.f. =1, для остаточной дисперсииd.f. =77), равно 4,00 (см. приложение. ). Таким образом,  , следовательно, уравнение регрессии в целом статистически значимо. В такой ситуации можно говорить и о статистической значимости величины коэффициента детерминации, т.е. вариация среднедушевых доходов населения в регионах России на 60 процентов может быть объяснена вариацией объемов валового регионального продукта на душу населения.
, следовательно, уравнение регрессии в целом статистически значимо. В такой ситуации можно говорить и о статистической значимости величины коэффициента детерминации, т.е. вариация среднедушевых доходов населения в регионах России на 60 процентов может быть объяснена вариацией объемов валового регионального продукта на душу населения.
Проводя оценку статистической значимости уравнения регрессии и его параметров, можем получить различное сочетание результатов.
· Уравнение по F-критерию статистически значимо и все параметры уравнения по t-статистике тоже статистически значимы. Данное уравнение может быть использовано как для принятия управленческих решений (на какие факторы следует воздействовать, чтобы получить желаемый результат), так и для прогнозирования поведения признака-результата при тех или иных значениях факторов.
· По F-критерию уравнение статистически значимо, но незначимы параметры (параметр) уравнения. Уравнение может быть использовано для принятия управленческих решений (касающихся тех факторов, по которым получено подтверждение статистической значимости их влияния), но уравнение не может быть использовано для прогнозирования.
· Уравнение по F-критерию статистически незначимо. Уравнение не может быть использовано. Следует продолжить поиск значимых признаков-факторов или аналитической формы связи аргумента и отклика.
Если подтверждена статистическая значимость уравнения и его параметров, то может быть реализован, так называемый, точечный прогноз, т.е. получена оценка значения признака-результата (y) при тех или иных значениях фактора (x).
Совершенно очевидно, что прогнозное значение зависимой переменной, рассчитанное на основе уравнения связи, не будет совпадать с фактическим ее значением ( 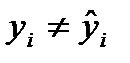 ).Графически эта ситуация подтверждается тем, что не все точки поля корреляции лежат на линии регрессии,лишь при функциональной связи линия регрессии пройдет через все точки диаграммы рассеивания. Наличие расхождений между фактическими и теоретическими значениями зависимой переменной связано, прежде всего, с самой сутью корреляционной зависимости:одновременно на результат воздействует множество факторов, из которых только часть может быть учтена в конкретном уравнении связи. Кроме того, может быть неверно выбрана форма связи результата и фактора (тип уравнения регрессии). В связи с этим возникает вопрос, насколько информативно построенное уравнение связи. На этот вопрос отвечают два показателя: коэффициент детерминации (о нем уже говорилось выше) и стандартная ошибка оценивания.
).Графически эта ситуация подтверждается тем, что не все точки поля корреляции лежат на линии регрессии,лишь при функциональной связи линия регрессии пройдет через все точки диаграммы рассеивания. Наличие расхождений между фактическими и теоретическими значениями зависимой переменной связано, прежде всего, с самой сутью корреляционной зависимости:одновременно на результат воздействует множество факторов, из которых только часть может быть учтена в конкретном уравнении связи. Кроме того, может быть неверно выбрана форма связи результата и фактора (тип уравнения регрессии). В связи с этим возникает вопрос, насколько информативно построенное уравнение связи. На этот вопрос отвечают два показателя: коэффициент детерминации (о нем уже говорилось выше) и стандартная ошибка оценивания.
Разность между фактическими и теоретическими значениями зависимой переменной называют отклонениями или ошибками, или остатками. На основе этих величин рассчитывается остаточная дисперсия. Квадратный корень из остаточной дисперсии и является среднеквадратической (стандартной) ошибкой оценивания:
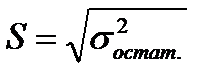 =
= 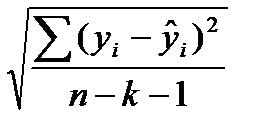 (7.8)
(7.8)
Стандартная ошибка уравнения измеряется в тех же единицах, что и прогнозируемый показатель. Если ошибки уравнения подчиняются нормальному распределению (при больших объемах данных), то 95 процентов значений должны находиться от линии регрессии на расстоянии, не превышающем 2S (исходя из свойства нормального распределения — правила трех сигм). Величина стандартной ошибки оценивания используется при расчете доверительных интервалов при прогнозировании значения признака — результата для конкретной единицы совокупности.
В практических исследованиях часто возникает необходимость в прогнозе среднего значения признака — результата при том или ином значении признака — фактора. В этом случае в расчете доверительного интервала для среднего значения зависимой переменной( 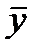 )
)
учитывается величина средней ошибки:
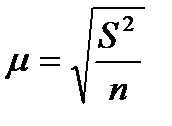 (7.9)
(7.9)
Использование разных величин ошибок объясняется тем, что изменчивость уровней показателей у конкретных единиц совокупности гораздо выше, чем изменчивость среднего значения, следовательно, ошибка прогноза среднего значения меньше.
Доверительный интервал прогноза среднего значения зависимой переменной:
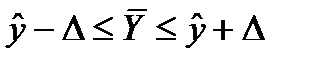 , (7.10)
, (7.10)
где 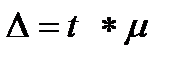 — предельная ошибка оценки (см. теорию выборки); t – коэффициент доверия, значение которого находится в соответствующей таблице, исходя из принятого исследователем уровня вероятности (числа степеней свободы) (см. теорию выборки).
— предельная ошибка оценки (см. теорию выборки); t – коэффициент доверия, значение которого находится в соответствующей таблице, исходя из принятого исследователем уровня вероятности (числа степеней свободы) (см. теорию выборки).
Доверительный интервал для прогнозируемого значения признака-результата может быть рассчитан и с учетом поправки на смещение (сдвиг) линии регрессии. Величина поправочного коэффициента определяется:
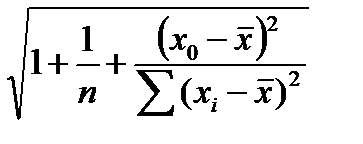 (7.11)
(7.11)
где 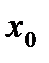 — значение признака-фактора, исходя из которого, прогнозируется значение признака-результата.
— значение признака-фактора, исходя из которого, прогнозируется значение признака-результата.
 Отсюда следует, что чем больше значение отличается от среднего значения признака-фактора, тем больше величина корректирующего коэффициента, тем больше ошибка прогноза. С учетом данного коэффициента доверительный интервал прогноза будет рассчитываться:
Отсюда следует, что чем больше значение отличается от среднего значения признака-фактора, тем больше величина корректирующего коэффициента, тем больше ошибка прогноза. С учетом данного коэффициента доверительный интервал прогноза будет рассчитываться:
На точность прогноза на основе уравнения регрессии могут влиять разные причины. Прежде всего, следует учитывать, что оценка качества уравнения и его параметров проводится, исходя из предположения о нормальном распределении случайных остатков. Нарушение этого допущения может быть связано с наличием резко отличающихся значений в данных, с неравномерной вариацией, с наличием нелинейной зависимости. В этом случае качество прогноза снижается. Второй момент, о котором следует помнить, — значения факторов, учитываемые при прогнозировании результата, не должны выходить за пределы размаха вариации данных, на основе которых построено уравнение.
Проверка значимости регрессии с помощью дисперсионного анализа (F-тест)
history 26 января 2019 г.
- Группы статей
- Статистический анализ
Проведем проверку значимости простой линейной регрессии с помощью процедуры F -тест.
Disclaimer : Данную статью не стоит рассматривать, как пересказ главы из учебника по статистике. Статья не обладает ни полнотой, ни строгостью изложения положений статистической науки. Эта статья – о применении MS EXCEL для целей Регрессионного анализа. Теоретические отступления приведены лишь из соображения логики изложения. Использование данной статьи для изучения Регрессии – плохая идея.
Проверку значимости взаимосвязи переменных в рамках модели простой линейной регрессии можно провести разными, но эквивалентными между собой, способами:
Проверку значимости взаимосвязи переменных в рамках модели простой линейной регрессии можно провести разными, но эквивалентными между собой, способами:
Процедуру F -теста рассмотрим на примере простой линейной регрессии , когда прогнозируемая переменная Y зависит только от одной переменной Х.
Чтобы определить может ли предложенная модель линейной регрессии быть использована для адекватного описания значений переменной Y, дисперсию наблюдаемых данных анализируют методом Дисперсионного анализа (ANOVA for Simple Regression) . Дисперсия данных разбивается на компоненты, которые затем используются в F -тесте для определения значимости регрессии.
F -тест для проверки значимости регрессии НЕ относится к простым и интуитивно понятным процедурам. Вероятно, это связано с тем, что для проведения F -теста требуется быть знакомым с определенным количеством статистических понятий и нужно неплохо разбираться в связанных с ними статистических методах. Нам потребуются понятия из следующих разделов статистики:
Можно, конечно, рассмотреть F -тест формально:
- вычислить на основании выборки значение тестовойFстатистики;
- сравнить полученное значение со значением, соответствующему заданному уровню значимости ;
- в зависимости от соотношения этих величин принять решение о значимости вычисленной линейной регрессии
В этой статье ставится более амбициозная задача – разобраться в самом подходе, на котором основан F -тест . Сначала введем несколько определений, которые используются в процедуре F -теста , затем рассмотрим саму процедуру.
Примечание : Для тех, кому некогда, незачем или просто не хочется разбираться в теоретических выкладках предлагается сразу перейти к вычислительной части .
Определения, необходимые для F -теста
Согласно определению дисперсии , дисперсия выборки прогнозируемой переменной Y определяется формулой:
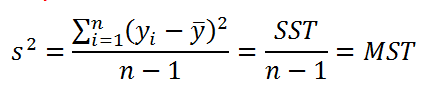
В формуле используется ряд сокращений:
- SST (Total Sum of Squares) – это просто компактное обозначение Суммы Квадратов отклонений от среднего (такое сокращение часто используется в зарубежной литературе).
- MST (Total Mean Square) – Среднее Суммы Квадратов отклонений (еще одно общеупотребительное сокращение).
Примечание : Необходимо иметь в виду, что с одной стороны величины MST и SST являются случайными величинами, вычисленными на основании выборки, т.е. статистиками . Однако с другой стороны, при проведении регрессионного анализа по данным имеющейся выборки вычисляются их конкретные значения. В этом случае величины MST и SST являются просто числами.
Значение n-1 в вышеуказанной формуле равно числу степеней свободы ( DF ) , которое относится к дисперсии выборки (одна степень свободы у n величин yi потеряна в результате наличия ограничения 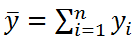 , связывающего все значения выборки). Число степеней свободы у величины SST также имеет специальное обозначение: DFT (DF Total).
, связывающего все значения выборки). Число степеней свободы у величины SST также имеет специальное обозначение: DFT (DF Total).
Как видно из формулы, отношение величин SST и DFT обозначается как MST. Эти 3 величины обычно выдаются в таблице результатов дисперсионного анализа в различных прикладных статистических программах (в том числе и в надстройке Пакет анализа, инструмент Регрессия ).
Значение SST, характеризующую общую изменчивость переменной Y, можно разбить на 2 компоненты:
- Изменчивость объясненную моделью (Explained variation), обозначается SSR
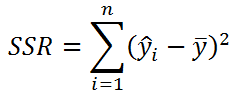
- Необъясненную изменчивость (Unexplained variation), обозначается SSЕ
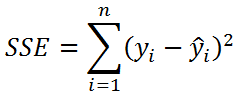
Известно , что справедливо равенство:
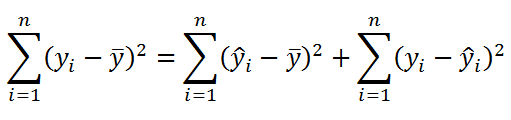
Величинам SSR и SSE также сопоставлены степени свободы . У SSR одна степень свободы , т.к. она однозначно определяется одним параметром – наклоном линии регрессии a (напомним, что мы рассматриваем простую линейную регрессию ). Это очевидно из формулы:
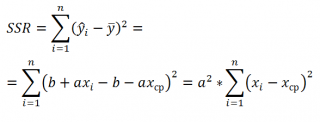
Примечание: Очевидность наличия только одной степени свободы проистекает из факта, что переменная Х – контролируемая (не является случайной величиной).
Число степеней свободы величины SSR имеет специальное обозначение: DFR (для простой регрессии DFR=1, т.к. число независимых переменных Х равно 1) . По аналогии с MST, отношение этих величин также часто обозначают MSR = SSR / DFR .
У SSE число степеней свободы равно n -2 , которое обозначается как DFE (или DFRES — residual degrees of freedom). Двойка вычитается, т.к. изменчивость переменной yi имеет 2 ограничения, связанные с оценкой 2-х параметров линейной модели ( а и b ): ŷi=a*xi+b
Отношение этих величин также часто обозначают MSE = SSE / DFE .
MSR и MSE имеют размерность дисперсий, хотя корректней их называть средними значениями квадратов отклонений. Тем не менее, ниже мы их будем «дисперсиями», т.к. они отображают меру разброса: MSE – меру разброса точек наблюдений относительно линии регрессии, MSR показывает насколько линия регрессии совпадает с горизонтальной линией среднего значения Y.
Примечание : Напомним, что MSE (Mean Square of Errors) является оценкой дисперсии s 2 ошибки, подробнее см. статью про линейную регрессию , раздел Стандартная ошибка регрессии .
Число степеней свободы обладает свойством аддитивности: DFT = DFR + DFE . В этом можно убедиться, составив соответствующее равенство n -1=1+( n -2)
Наконец, определившись с определениями, переходим к рассмотрению самой процедуры F -тест .
Процедура F -теста
Сущность F -теста при проверке значимости регрессии заключается в том, чтобы сравнить 2 дисперсии : объясненную моделью (MSR) и необъясненную (MSE). Если эти дисперсии «примерно равны», то регрессия незначима (построенная модель не позволяет объяснить поведение прогнозируемой Y в зависимости от значений переменной Х). Если дисперсия, объясненная моделью (MSR) «существенно больше», чем необъясненная, то регрессия значимая .
Примечание : Чтобы быстрее разобраться с процедурой F -теста рекомендуется вспомнить процедуру проверки статистических гипотез о равенстве дисперсий 2-х нормальных распределений (т.е. двухвыборочный F-тест для дисперсий ).
Чтобы пояснить вышесказанное изобразим на диаграммах рассеяния 2 случая:
- регрессия значима (в этом случае имеем значительный наклон прямой) и
- регрессия незначима (линия регрессии близка к горизонтальной прямой).
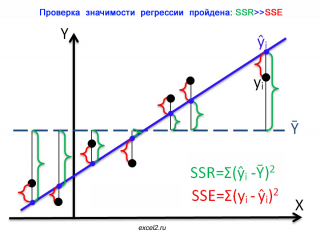
На первой диаграмме показан случай, когда регрессия значима:
- Зеленым цветом выделены расстояния от среднего значения до линии регрессии , вычисленные для каждого хi. Сумма квадратов этих расстояний равна SSR;
- Красным цветом выделены расстояния от линии регрессии до соответствующих точек наблюдений . Сумма квадратов этих расстояний равна SSЕ.
Из диаграммы видно, что в случае значимой регрессии, сумма квадратов «зеленых» расстояний, гораздо больше суммы квадратов «красных». Понятно, что их отношение будет гораздо больше 1. Следовательно, и отношение дисперсий MSR и MSE будет гораздо больше 1 (не забываем, что SSE нужно разделить еще на соответствующее количество степеней свободы n-2).
В случае значимой регрессии точки наблюдений будут находиться вдоль линии регрессии. Их разброс вокруг этой линии описываются ошибками регрессии, которые были минимизированы посредством процедуры МНК . Очевидно, что разброс точек относительно линии регрессии значительно меньше, чем относительно горизонтальной линии, соответствующей среднему значению Y.
Совершенно другую картину мы можем наблюдать в случае незначимой регрессии.
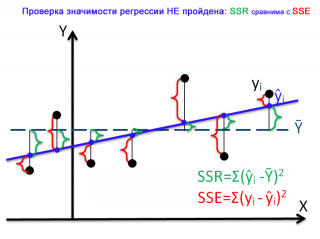
Очевидно, что в этом случае, сумма квадратов «зеленых» расстояний, примерно соответствует сумме квадратов «красных». Это означает, что объясненная дисперсия примерно соответствует величине необъясненной дисперсии (MSR/MSE будет близко к 1).
Если ответ о значимости регрессии практически очевиден для 2-х вышеуказанных крайних ситуаций, то как сделать правильное заключение для промежуточных углов наклона линии регрессии?
Понятно, что если вычисленное на основании выборки значение MSR/MSE будет существенно больше некоторого критического значения, то регрессия значима, если нет, то не значима. Очевидно, что это значение должно быть больше 1, но как определить это критическое значение статистически обоснованным методом ?
Вспомним, что для формулирования статистического вывода (т.е. значима регрессия или нет) используют проверку гипотез . Для этого формулируют 2 гипотезы: нулевую Н 0 и альтернативную Н 1 . Для проверки значимости регрессии в качестве нулевой гипотезы Н 0 принимают, что связи нет, т.е. наклон прямой a=0. В качестве альтернативной гипотезы Н 1 принимают, что a <>0.
Примечание : Даже если связи между переменными нет (a=0), то вычисленная на основании данных выборки оценка наклона — величина а , из-за случайности выборки будет близка, но все же отлична от 0.
По умолчанию принимается, что нулевая гипотеза верна – связи между переменными нет. Если это так, то:
- MSR/MSE будет близко к 1;
- Случайная величина F = MSR/MSE будет иметь F-распределениесо степенями свободы 1 (в числителе) и n-2 (знаменателе). F является тестовой статистикой для проверки значимости регрессии.
Примечание : MSR и MSE являются случайными величинами (т.к. они получены на основе случайной выборки). Соответственно, выражение F=MSR/MSE, также является случайной величиной, которая имеет свое распределение, среднее значение и дисперсию .
Ниже приведен график плотности вероятности F-распределения со степенями свободы 1 (в числителе) и 59 (знаменателе). 59=61-2, 61 наблюдение минус 2 степени свободы.
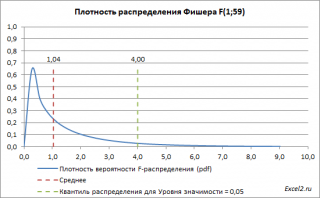
Если нулевая гипотеза верна, то значение F 0 =MSR/MSE, вычисленное на основании выборки, должно быть около ее среднего значения (т.е. около 1,04). Если F 0 будет существенно больше 1 (чем больше F0 отклоняется в сторону больших значений, тем это маловероятней), то это будет означать, что F не имеет F-распределение , а, следовательно, нулевую гипотезу нужно отклонить и принять альтернативную, утверждающую, что связь между переменными есть (значима).
Обычно предполагают, что если вероятность, того что F -статистика приняла значение F0 составляет менее 5%, то это событие маловероятно и нулевую гипотезу необходимо отклонить. 5% — это заданный исследователем уровень значимости , который может быть, например, 1% или 10%.
Значение статистики F0 может быть вычислено на основании выборки:
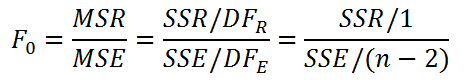
Вычисления в MS EXCEL
В MS EXCEL критическое значение для заданного уровня значимости F1-альфа, 1, n-2 можно вычислить по формуле = F.ОБР(1- альфа;1; n-2) или = F.ОБР.ПХ(альфа;1; n-2) . Другими словами требуется вычислить верхний альфа-квантиль F-распределения с соответствующими степенями свободы .
Таким образом, при значении статистики F0> F1-альфа, 1, n-2 мы имеем основание для отклонения нулевой гипотезы.
Значение F 0 можно вычислить на основании значений выборки по вышеуказанной формуле или с помощью функции ЛИНЕЙН() :
В случае простой регрессии значение F0 также равно квадрату t-статистики, которую мы использовали при проверке двусторонней гипотезе о равенстве 0 коэффициента регрессии .
Проверку значимости регрессии можно также осуществить через вычисление p-значения. В этом случае вычисляют вероятность того, что случайная величина F примет значение F0 (это и есть p-значение), затем сравнивают p-значение с заданным уровнем значимости . Если p-значение больше уровня значимости, то нулевую гипотезу нет оснований отклонить, и регрессия незначима.
В MS EXCEL для проверки гипотезы используя p -значение используйте формулу = F.РАСП.ПХ(F0;1;n-2) файл примера , где показано эквивалентность всех подходов проверки значимости регрессии).
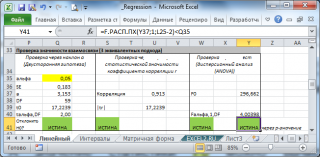
В программах статистики результаты процедуры F -теста выводят с помощью стандартной таблицы дисперсионного анализа . В файле примера такая таблица приведена на листе Таблица, которая построена на основе результатов, возвращаемых инструментом Регрессия надстройки Пакета анализа MS EXCEL .
http://poisk-ru.ru/s43427t9.html
http://excel2.ru/articles/proverka-znachimosti-regressii-s-pomoshchyu-dispersionnogo-analiza-f-test