Эффективность МНК-оценок метода наименьших квадратов
Свойство эффективности оценок неизвестных параметров модели регрессии, полученных методом наименьших квадратов, доказывается с помощью теоремы Гаусса-Маркова.
Сделаем следующие предположения о модели парной регрессии:
1) факторная переменная xi – неслучайная или детерминированная величина, которая не зависит от распределения случайной ошибки модели регрессии βi;
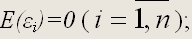
2) математическое ожидание случайной ошибки модели регрессии равно нулю во всех наблюдениях:
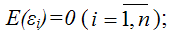
3) дисперсия случайной ошибки модели регрессии постоянна для всех наблюдений:;
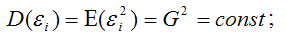
4) между значениями случайных ошибок модели регрессии в любых двух наблюдениях отсутствует систематическая взаимосвязь, т. е. случайные ошибки модели регрессии не коррелированны между собой (ковариация случайных ошибок любых двух разных наблюдений равна нулю):
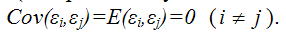
Это условие выполняется в том случае, если исходные данные не являются временными рядами;
5) на основании третьего и четвёртого условий часто добавляется пятое условие, заключающееся в том, что случайная ошибка модели регрессии – это случайная величина, подчиняющейся нормальному закону распределения с нулевым математическим ожиданием и дисперсией G 2 : εi
Если выдвинутые предположения справедливы, то оценки неизвестных параметров модели парной регрессии, полученные методом наименьших квадратов, имеют наименьшую дисперсию в классе всех линейных несмещённых оценок, т. е. МНК-оценки можно считать эффективными оценками неизвестных параметров β0и β1.
Если выдвинутые предположения справедливы для модели множественной регрессии, то оценки неизвестных параметров данной модели регрессии, полученные методом наименьших квадратов, имеют наименьшую дисперсию в классе всех линейных несмещённых оценок, т. е. МНК-оценки можно считать эффективными оценками неизвестных параметров β0…βn.
Для обозначения дисперсий МНК-оценок неизвестных параметров модели регрессии используется матрица ковариаций.
Матрицей ковариаций МНК-оценок параметров линейной модели парной регрессии называется выражение вида:
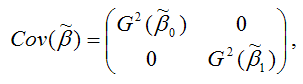
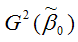 – дисперсия МНК-оценки параметра модели регрессии β0;
– дисперсия МНК-оценки параметра модели регрессии β0;
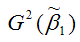 – дисперсия МНК-оценки параметра модели регрессии β1.
– дисперсия МНК-оценки параметра модели регрессии β1.
Матрицей ковариаций МНК-оценок параметров линейной модели множественной регрессии называется выражение вида:
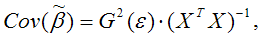
где G 2 (ε) – это дисперсия случайной ошибки модели регрессии ε.
Для линейной модели парной регрессии дисперсии оценок неизвестных параметров определяются по формулам:
1) дисперсия МНК-оценки коэффициента модели регрессии β0:
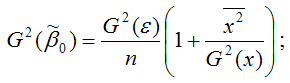
2) дисперсия МНК-оценки коэффициента модели регрессии β1:
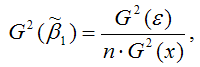
где G 2 (ε) – дисперсия случайной ошибки уравнения регрессии β;
G 2 (x) – дисперсия независимой переменой модели регрессии х;
n – объём выборочной совокупности.
В связи с тем, что на практике значение дисперсии случайной ошибки модели регрессии G 2 (ε) неизвестно, для вычисления матрицы ковариаций МНК-оценок применяют оценку дисперсии случайной ошибки модели регрессии S2(ε).
Для линейной модели парной регрессии оценка дисперсии случайной ошибки определяется по формуле:
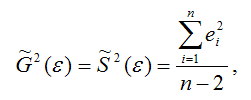
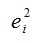 – это остатки регрессионной модели, которые рассчитываются как
– это остатки регрессионной модели, которые рассчитываются как
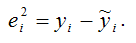
Тогда оценка дисперсии МНК-оценки коэффициента β0 линейной модели парной регрессии будет определяться по формуле:
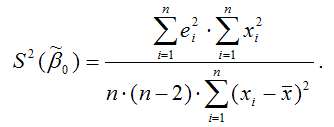
Оценка дисперсии МНК-оценки коэффициента β1 линейной модели парной регрессии будет определяться по формуле:
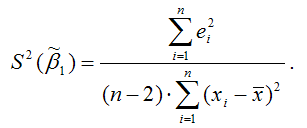
Для модели множественной регрессии общую формулу расчёта матрицы ковариаций МНК-оценок коэффициентов на основе оценки дисперсии случайной ошибки модели регрессии можно записать следующим образом:
Оценка параметров уравнения регреcсии. Пример
Задание:
По группе предприятий, выпускающих один и тот же вид продукции, рассматриваются функции издержек:
y = α + βx;
y = α x β ;
y = α β x ;
y = α + β / x;
где y – затраты на производство, тыс. д. е.
x – выпуск продукции, тыс. ед.
Требуется:
1. Построить уравнения парной регрессии y от x :
- линейное;
- степенное;
- показательное;
- равносторонней гиперболы.
2. Рассчитать линейный коэффициент парной корреляции и коэффициент детерминации. Сделать выводы.
3. Оценить статистическую значимость уравнения регрессии в целом.
4. Оценить статистическую значимость параметров регрессии и корреляции.
5. Выполнить прогноз затрат на производство при прогнозном выпуске продукции, составляющем 195 % от среднего уровня.
6. Оценить точность прогноза, рассчитать ошибку прогноза и его доверительный интервал.
7. Оценить модель через среднюю ошибку аппроксимации.
1. Уравнение имеет вид y = α + βx
1. Параметры уравнения регрессии.
Средние значения
Связь между признаком Y фактором X сильная и прямая
Уравнение регрессии
Коэффициент детерминации
R 2 =0.94 2 = 0.89, т.е. в 88.9774 % случаев изменения х приводят к изменению y. Другими словами — точность подбора уравнения регрессии — высокая
| x | y | x 2 | y 2 | x ∙ y | y(x) | (y- y ) 2 | (y-y(x)) 2 | (x-x p ) 2 |
| 78 | 133 | 6084 | 17689 | 10374 | 142.16 | 115.98 | 83.83 | 1 |
| 82 | 148 | 6724 | 21904 | 12136 | 148.61 | 17.9 | 0.37 | 9 |
| 87 | 134 | 7569 | 17956 | 11658 | 156.68 | 95.44 | 514.26 | 64 |
| 79 | 154 | 6241 | 23716 | 12166 | 143.77 | 104.67 | 104.67 | 0 |
| 89 | 162 | 7921 | 26244 | 14418 | 159.9 | 332.36 | 4.39 | 100 |
| 106 | 195 | 11236 | 38025 | 20670 | 187.33 | 2624.59 | 58.76 | 729 |
| 67 | 139 | 4489 | 19321 | 9313 | 124.41 | 22.75 | 212.95 | 144 |
| 88 | 158 | 7744 | 24964 | 13904 | 158.29 | 202.51 | 0.08 | 81 |
| 73 | 152 | 5329 | 23104 | 11096 | 134.09 | 67.75 | 320.84 | 36 |
| 87 | 162 | 7569 | 26244 | 14094 | 156.68 | 332.36 | 28.33 | 64 |
| 76 | 159 | 5776 | 25281 | 12084 | 138.93 | 231.98 | 402.86 | 9 |
| 115 | 173 | 13225 | 29929 | 19895 | 201.86 | 854.44 | 832.66 | 1296 |
| 0 | 0 | 0 | 16.3 | 20669.59 | 265.73 | 6241 | ||
| 1027 | 1869 | 89907 | 294377 | 161808 | 1869 | 25672.31 | 2829.74 | 8774 |
Примечание: значения y(x) находятся из полученного уравнения регрессии:
y(1) = 4.01*1 + 99.18 = 103.19
y(2) = 4.01*2 + 99.18 = 107.2
. . .
2. Оценка параметров уравнения регрессии
Значимость коэффициента корреляции
По таблице Стьюдента находим Tтабл
Tтабл (n-m-1;α/2) = (11;0.05/2) = 1.796
Поскольку Tнабл > Tтабл , то отклоняем гипотезу о равенстве 0 коэффициента корреляции. Другими словами, коэффициента корреляции статистически — значим.
Анализ точности определения оценок коэффициентов регрессии
S a = 0.1712
Доверительные интервалы для зависимой переменной
Рассчитаем границы интервала, в котором будет сосредоточено 95% возможных значений Y при неограниченно большом числе наблюдений и X = 1
(-20.41;56.24)
Проверка гипотез относительно коэффициентов линейного уравнения регрессии
1) t-статистика
Статистическая значимость коэффициента регрессии a подтверждается
Статистическая значимость коэффициента регрессии b не подтверждается
Доверительный интервал для коэффициентов уравнения регрессии
Определим доверительные интервалы коэффициентов регрессии, которые с надежность 95% будут следующими (tтабл=1.796):
(a — tтабл·Sa; a + tтабл·S a)
(1.306;1.921)
(b — tтабл·S b; b + tтабл·Sb)
(-9.2733;41.876)
где t = 1.796
2) F-статистики
Fkp = 4.84
Поскольку F > Fkp, то коэффициент детерминации статистически значим
лекции по эконометрике. Основные понятия и определения эконометрики
| Название | Основные понятия и определения эконометрики |
| Анкор | лекции по эконометрике.doc |
| Дата | 24.03.2018 |
| Размер | 0.78 Mb. |
| Формат файла |  |
| Имя файла | лекции по эконометрике.doc |
| Тип | Документы #17143 |
| страница | 2 из 4 |
Подборка по базе: Тест 5. Основные понятия математической статистики. Вариационные, Основные понятия и определения в области организации вычислитель, Менеджмент. Основные модели принятия решений.Модели принятия реш, Реферат на тему Основные законы древней греции.docx, Анкета определения частоты и степени замерзания,Бербин.docx, Средства измерений и их основные элементы.pptx, Базовые понятия и классификация систем управления базами данных , Т-1 Основные требования законодательства Российской Федерации об, Диплом Структура расходов (затрат) на производство и реализацию , Устройство и основные элементы конструкции машины постоянного то4. СТАТИСТИЧЕСКИЕ СВОЙСТВА ОЦЕНОК КОЭФФИЦИЕНТОВМЛРМ. Для того чтобы оценки, полученные по МНК, давали «наилучшие» результаты, мы потребуем от остаточного члена или ошибки и от X выполнения следующих условий (предположения относительно того, как генерируются наблюдения):
В матричной форме:
1-5 — КЛРМ, 1-6 — НЛРМ, условия 1-6 — условия Гаусса-Маркова. В случае НЛРМ условие 5. эквивалентно условию статистической независимости ошибок для разных наблюдений. Действительно, если две нормально распределенные величины не коррелированны, то они независимы. Обсудим эти условия.
Это условие состоит в том, что математическое ожидание случайного члена равно нулю в любом наблюдении. Иногда случайный член бывает положительным, иногда отрицательным, но он не должен иметь смещения ни в одном возможном направлении. Надо сказать, что если в уравнение включается постоянный член, то бывает разумным предположить, что первое условие выполняется автоматически, т. к. роль константы и состоит в определении любой систематической составляющей в Y, которую не учитывают объясняющие переменные (если спецификация модели выбрана правильно). Иллюстрация: предположим, что
Таким образом, исходная модель эквивалентна новой модели с ошибкой, имеющей нулевое математическое ожидание и другим свободным членом. 4. Второе условие говорит нам о том, что дисперсии ошибок постоянны для всех наблюдений. Иногда случайный член будет больше, иногда меньше, иногда больше, но не должно быть априорной причины для того, чтобы он порождал большую ошибку в одних наблюдениях, чем в других. Условие независимости ошибок от номера наблюдения называют гомоскедастичностью. Случай, когда условие гомоскедастичности нарушается, называется гетероскедастичностью. Этот случай можно иногда наблюдать графически: Рисунок 1. рисунок про > 0 и Несмещенность . Несмещенной называют статистическую оценку Q*, математическое ожидание которой равно истинному значению оцениваемого параметра, т. е. M(Q*) = Q, Оценку, которая не удовлетворяет этому свойству, называют смещенной. Смещенность оценки означает присутствие в оценке систематических ошибок (ошибок одного знака), т. е. смещенная оценка завышает или занижает истинное значение параметра. Если оценка смещена, то QM(Q*) есть смещение. Как правило, эконометристов более интересует состоятельность оценки, чем ее Несмещенность. Смещенная, но состоятельная оценка может не равняться истинному значению в среднем, но с ростом выборки будет приближаться к истинному значению параметра. Пример несмещенной, но неэффективной оценкой и смещенной, но эффективной на рисунке. Свойство 1. Линейная зависимость оценок от наблюдаемых значений Y.
поскольку
Легко убедится, что
Аналогично преобразовывая выражение для
Для доказательства мы использовали 2 и 3.
Аналогично выводится формула для . Подобным образом можно отыскать ковариацию:
(пользовались тем, что матрица, обратная к симметричной, так же симметричная) посмотреть, что еще здесь надо пользовались 3, 4 и 5.
В условиях 1-5 МНК-оценки МЛРМ представляют собой наилучшие линейные несмещенные оценки, т. е. в классе линейных несмещенных оценок МНК-оценки обладают наименьшей дисперсией. Best Linear Unbaised Estimation (BLUE) Важность теоремы Гаусса-Маркова. Мы можем придумать много оценок возможных для коэффициентов , в частности, можем придумать много линейных оценок, т. е. таких оценок, которые выражаются в виде взвешенного среднего наблюдений объясняемой переменной. Некоторые из этих оценок могут быть несмещенными как, например, «наивная» оценка. Так вот, оценки коэффициентов уравнения по методу наименьших квадратов в случае классической парной модели – это наилучшие оценки в том смысле, что среди всех возможных линейных несмещенных оценок эти оценки имеют наименьшую дисперсию. BestLinearUnbiasedEstimator – BLUE Вопрос нахождения такой оценки будет возникать в нашем курсе снова и снова, т. к. мы увидим, что при нарушении условий Гаусса-Маркова МНК-оценки уже не будут «BLUE». В этом случае наша цель будет заключатся в построении других оценок, не МНК, которые уже будут «BLUR». Свойство 5. Итак, оценка
Для парной модели
Стандартные отклонения коэффициентов регрессии, вычисленные на основе предыдущей формулы, приводятся в результатах регрессии практически во всех статистических пакетах. В предположениях НЛРМ Свойство 7. В случае НРЛМ Свойство 8. В условиях НЛРМ оценки ПРОВЕРКА ГИПОТЕЗ ОТНОСИТЕЛЬНО КОЭФФИЦИЕНТОВ РЕГРЕССИИ. 1. H0: = 0, или учитывая, что H0: M Поскольку
Вычисляем наблюдаемое значение критерия tнабл/. Для проверки нулевой гипотезы при различных альтернативных гипотезах: tкр находим из таблиц критических точек распределения Стьюдента с N—k—1 степенями свободы для выбранного уровня значимости и учитывая, что критическая область двусторонняя —
Если же у нас критерий односторонний, то все сохраняется, за исключением критического значения статистики. Его мы ищем по таблицам критических точек распределения Стьюдента с N—k-1 степенями свободы для выбранного уровня значимости и учитывая, что критическая область односторонняя — Особенно просто критерий выглядит в случае, когда i0 = 0, т. е. в случае, когда мы хотим убедиться в значимости этого коэффициента и таким образом убедиться в наличии связи между Y и Xi: Если мы теперь рассмотрим неравенство
Разрешим это неравенство относительно :
Не говорят, что доверительный интервал содержит с вероятностью содержит истинное значение параметра . Поскольку истинное значение параметра существует независимо от нас, а доверительный интервал мы строим, т. о. не попадает в доверительный интервал, а доверительный интервал с той или иной вероятностью попадает на .
Пусть константа включена в число регрессоров. Процедура разделения вариации переменной Y на две составляющие позволяет провести нам тест на существование линейной зависимости между переменной Y и переменными X1,…,Xk. Н0: Таким образом, справедливость нулевой гипотезы означает, что ни одна из переменных X1,…,Xkне помогает нам объяснить вариацию Y. Эта гипотеза позволяет нам судить о значимости регрессии в целом. Эта гипотеза об отсутствии линейной связи между Y и X1,…,Xk. Проверка нулевой гипотезы осуществляется при помощи следующего критерия:
При справедливости нулевой гипотезы данная статистика имеет распределение Фишера с числом степеней свободы числителя k и знаменателя N—k-1. Если нулевая гипотеза верна, то следует ожидать, что RSS, R 2 и, следовательно, F, близки к нулю. Таким образом, если значение F-статистики велико, мы нулевую гипотезу отвергаем. Граничное значение, начиная с которого мы отвергаем гипотезу, находится из таблиц распределения Фишера для выбранного уровня значимости и числу степеней свободы числителя k и знаменателя N-k-1 — Итак, при помощи F-статистики мы проверяем значимость коэффициента детерминации. Если F-статистика незначимо отличается от нуля, это означает, что объясняющие переменные, участвующие в модели на самом деле не очень-то нам помогают объяснит вариацию переменной Y. Для парного случая F – статистика выглядит следующим образом: Сравнивая предыдущее выражение и выражение для t-статистики коэффициента наклона, получим, что F= t 2 :
Таким образом, проверка гипотезы Н0: = 0 , используя F и t-статистики, дает для одномерной регрессионной модели дает тождественные результаты. При помощи F-статистики мы теперь умеем проверять гипотезу о том, что все коэффициенты при объясняющих переменных равны нулю. Иногда возникают ситуации, когда нам необходимо проверить гипотезу о том, что нулю равны не все коэффициенты при объясняющих переменных, а некоторые из них. В этом случае осуществляется следующая процедура. Рассмотрим модель множественной регрессии: Назовем эту модель моделью без ограничений (UR), поскольку здесь мы не делаем никаких ограничений на возможные значения коэффициентов регрессии. Предположим, что мы хотим протестировать гипотезу о том, что q последних коэффициентов регрессии одновременно равны нулю. Т. е. мы хотим проверить гипотезу о том, что
нулевая гипотеза выглядит следующим образом: Н0: В случае, если эта гипотеза справедлива, то истинная модель выглядит следующим образом: Назовем эту модель моделью с ограничениями (R –restricted model). Оценим обе эти модели и посчитаем сумму квадратов остатков в модели с ограничениями и в модели без ограничений – ESSR и ESSUR соответственно. ESSR всегда больше, чем ESSUR. Этот результат эквивалентен тому, что R 2 всегда увеличивается при добавлении в модель новых объясняющих переменных. Если нулевая гипотеза справедлива, выбрасывание из уравнения q последних объясняющих переменных несильно скажется на объясняющих качествах уравнения, и ESSR будет ненамного отличатся от ESSUR. Таким образом, если нулевая гипотеза справедлива, разница ESSR — ESSUR будет ненамного отличатся от нуля. Статистический критерий для проверки нулевой гипотезы следующий:
При справедливости нулевой гипотезы данная статистика имеет распределение Фишера с числом степеней свободы числителя q и знаменателя N—k-1. Если нулевая гипотеза справедлива, выбрасывание из уравнения q последних объясняющих переменных несильно скажется на объясняющих качествах уравнения, и ESSR будет ненамного отличатся от ESSUR. Таким образом, если нулевая гипотеза справедлива, разница ESSR — ESSUR. будет ненамного отличатся от нуля. Следовательно, F-статистика будет достаточно мала. Граничное значение, при котором нулевую гипотезу отвергают, зависит от выбранного уровня значимости . Оно находится из таблиц распределения Фишера для выбранного уровня значимости и числу степеней свободы числителя q и знаменателя N—k-1. Таким образом, если мы нулевую гипотезу отвергаем, то делаем вывод о том, что наши переменные действительно оказывают влияние на переменную Y и включение их в модель существенно повышает объясняющую силу уравнения. Похожий подход – рассмотрение регрессии с ограничение регрессии без ограничений – можно применить и для проверки гипотезы о наличии линейных связей между коэффициентами. Например, нам может понадобиться в ходе нашего исследования проверить гипотезу о равенстве между собой нескольких коэффициентов регрессии.
Предположим, мы рассматриваем и оцениваем функцию потребления:
Рассмотрим сначала первый случай. Суть подхода к проверке таких гипотез такая же, как и в предыдущем пункте. Мы оцениваем две регрессии регрессию без ограничений и регрессию с ограничениями, составляем F статистику и проверяем ее значимость при помощи таблиц распределения Фишера. Рассмотрим сначала первый случай. Нулевая гипотеза: H0: Модель без ограничений: модель с ограничениями: Во втором случае моделью с ограничениями будет следующая модель:
Здесь мы просто подставили в исходную модель выражение для 2: Статистический критерий для проверки нулевой гипотезы следующий:
При справедливости нулевой гипотезы данная статистика имеет распределение Фишера с числом степеней свободы числителя q и знаменателя N—k-1, где q чисто ограничений, накладываемых на коэффициенты. В нашем случае оно равно 1. В статистических пакетах проверка гипотезы о наличии линейных ограничений на коэффициенты называется тестом Вальда (Wald test). Рассмотрим эту гипотезу в общем виде: H матрица размера Для проверки такой гипотезы используется статистика Вальда: При справедливости нулевой гипотезы эта статистика распределена асимптотически как Ту же самую гипотезу можно проверить при помощи статистики Фишера, вычислив суммы квадратов остатков для моделей с ограничением и модели без ограничений. Как связаны между собой эти статистики? Оказывается, что
Предположим, что мы рассматриваем регрессионное уравнение источники: http://math.semestr.ru/corel/prim4.php http://topuch.ru/osnovnie-ponyatiya-i-opredeleniya-ekonometriki/index2.html |
 мы с вами можем рассматривать как случайные величины. Действительно, при повторении наблюдений над экономическим объектом – получении выборок того же самого объема N при тех же самых значениях объясняющей переменной X значение результирующего параметра Y будет варьироваться за счет случайного члена , а, следовательно, будут варьироваться зависящие от y1,…,yN значения оценок. Если же X – случайная величина, то тогда вариация оценок будет зависеть и от вариации X. Таким образом, свойства коэффициентов регрессии будут существенным образом зависеть от свойств случайного члена и от свойств X, если X— случайная величина.
мы с вами можем рассматривать как случайные величины. Действительно, при повторении наблюдений над экономическим объектом – получении выборок того же самого объема N при тех же самых значениях объясняющей переменной X значение результирующего параметра Y будет варьироваться за счет случайного члена , а, следовательно, будут варьироваться зависящие от y1,…,yN значения оценок. Если же X – случайная величина, то тогда вариация оценок будет зависеть и от вариации X. Таким образом, свойства коэффициентов регрессии будут существенным образом зависеть от свойств случайного члена и от свойств X, если X— случайная величина. — спецификация модели;
— спецификация модели; ;
; , дисперсия ошибки не зависит от номера наблюдения;
, дисперсия ошибки не зависит от номера наблюдения; при i k, т. е. некоррелированность ошибок разных наблюдений;
при i k, т. е. некоррелированность ошибок разных наблюдений; , т. е. . i –нормально распределенная случайная величина со средним 0 и дисперсией
, т. е. . i –нормально распределенная случайная величина со средним 0 и дисперсией  .
. ,
,  — матрица ковариаций вектора ;
— матрица ковариаций вектора ; , т. е.
, т. е.  имеют совместное нормальное распределение со средним 0 и матрицей ковариаций
имеют совместное нормальное распределение со средним 0 и матрицей ковариаций  (разьяснение про матрицу ковариаций)
(разьяснение про матрицу ковариаций) .
. , тогда
, тогда

 — автокорреляционный процесс первого порядка – типичный вид данных представлен на рисунке 2.
— автокорреляционный процесс первого порядка – типичный вид данных представлен на рисунке 2.
 в силу того, что
в силу того, что
 , если X — детерминированный вектор, то w – детерминированный вектор (при повторении выборок значения не меняются).
, если X — детерминированный вектор, то w – детерминированный вектор (при повторении выборок значения не меняются).
 , мы получим
, мы получим

 , т. е.
, т. е. 
 ,
,

 .
.

 .
. — из предыдущего пункта.
— из предыдущего пункта.

 , где a ii — i-й диагональный элемент матрицы
, где a ii — i-й диагональный элемент матрицы 
 используем
используем  :
: — несмещенная оценка
— несмещенная оценка  является несмещенной оценкой дисперсии
является несмещенной оценкой дисперсии 

 ,
, 

 — без доказательства.
— без доказательства. или
или  , где
, где  . Поэтому
. Поэтому  . Далее,
. Далее,  и оценки
и оценки  .
. . Далее, если
. Далее, если , то мы говорим, что у нас нет оснований отвергнуть нулевую гипотезу, если же
, то мы говорим, что у нас нет оснований отвергнуть нулевую гипотезу, если же , то мы нулевую гипотезу отвергаем.
, то мы нулевую гипотезу отвергаем. . Выполняется следующее соотношение между односторонними и двусторонними критическими точками:
. Выполняется следующее соотношение между односторонними и двусторонними критическими точками: =
= 
 tстатистика i-го коэффициента МЛРМ. Значение этой статистики приводятся почти всеми статистическими пакетами.
tстатистика i-го коэффициента МЛРМ. Значение этой статистики приводятся почти всеми статистическими пакетами.



 — доверительный интервал для параметра i с уровнем надежности . В этом случае говорят, что доверительный интервал с вероятностью покрывает истинное значение параметра i.
— доверительный интервал для параметра i с уровнем надежности . В этом случае говорят, что доверительный интервал с вероятностью покрывает истинное значение параметра i.

 . Таким образом, если
. Таким образом, если  , мы нулевую гипотезу отвергаем, делаем вывод о том, что хотя бы одна из объясняющих переменных, участвующих в модели, действительно линейно влияет на переменную Y.
, мы нулевую гипотезу отвергаем, делаем вывод о том, что хотя бы одна из объясняющих переменных, участвующих в модели, действительно линейно влияет на переменную Y. — Упражнение
— Упражнение .
. «длинная регрессия».
«длинная регрессия». . Перепишем предыдущее уравнение следующим образом:
. Перепишем предыдущее уравнение следующим образом:
 «короткая регрессия»
«короткая регрессия»
 , где XL трудовые доходы, а XNL нетрудовые доходы. В этом случае нам может понадобиться проверить гипотезу о том, что предельные склонности к потреблению равны между собой (
, где XL трудовые доходы, а XNL нетрудовые доходы. В этом случае нам может понадобиться проверить гипотезу о том, что предельные склонности к потреблению равны между собой ( ) или гипотезу о том, что общая предельная склонность к потреблению равна 1 (
) или гипотезу о том, что общая предельная склонность к потреблению равна 1 ( ).
). ;
; .
. .
.
 .
. означает, что
означает, что  .
. , где q число ограничений, r вектор из q компонент.
, где q число ограничений, r вектор из q компонент.
 . Для проверки нулевой гипотезы находим критическую точку распределения
. Для проверки нулевой гипотезы находим критическую точку распределения  , то мы нулевую гипотезу отвергаем, если
, то мы нулевую гипотезу отвергаем, если  , то говорим, что нет оснований отвергнуть нулевую гипотезу.
, то говорим, что нет оснований отвергнуть нулевую гипотезу. . В пакете Eviews приводятся наблюдаемые значения обеих статистик и значения Probability для каждой из них.
. В пакете Eviews приводятся наблюдаемые значения обеих статистик и значения Probability для каждой из них. и данные для его оценки содержат наблюдения для разных по качеству объектов: для мужчин и женщин, для белых и черных. вопрос, который нас может здесь заинтересовать, следующий – верно ли, что рассматриваемая модель совпадает для двух выборок, относящихся к объектам разного качества? Ответить на этот вопрос можно при помощи теста Чоу.
и данные для его оценки содержат наблюдения для разных по качеству объектов: для мужчин и женщин, для белых и черных. вопрос, который нас может здесь заинтересовать, следующий – верно ли, что рассматриваемая модель совпадает для двух выборок, относящихся к объектам разного качества? Ответить на этот вопрос можно при помощи теста Чоу.