Уравнение нелинейной регрессии
Вместе с этим калькулятором также используют следующие:
Уравнение множественной регрессии
Виды нелинейной регрессии
| Вид | Класс нелинейных моделей |
| Нелинейные относительно включенных в анализ объясняющих переменных, но линейные по оцениваемым параметрам |
| Нелинейные по оцениваемым параметрам |
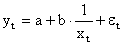
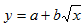
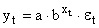
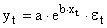

Здесь ε — случайная ошибка (отклонение, возмущение), отражающая влияние всех неучтенных факторов.
Уравнению регрессии первого порядка — это уравнение парной линейной регрессии.
Уравнение регрессии второго порядка это полиномальное уравнение регрессии второго порядка: y = a + bx + cx 2 .
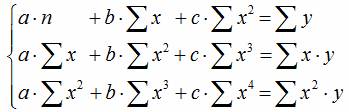
Уравнение регрессии третьего порядка соответственно полиномальное уравнение регрессии третьего порядка: y = a + bx + cx 2 + dx 3 .
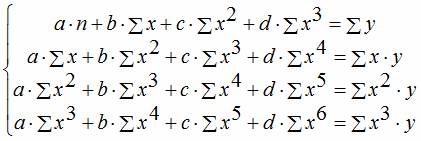
Чтобы привести нелинейные зависимости к линейной используют методы линеаризации (см. метод выравнивания):
- Замена переменных.
- Логарифмирование обеих частей уравнения.
- Комбинированный.
| y = f(x) | Преобразование | Метод линеаризации |
| y = b x a | Y = ln(y); X = ln(x) | Логарифмирование |
| y = b e ax | Y = ln(y); X = x | Комбинированный |
| y = 1/(ax+b) | Y = 1/y; X = x | Замена переменных |
| y = x/(ax+b) | Y = x/y; X = x | Замена переменных. Пример |
| y = aln(x)+b | Y = y; X = ln(x) | Комбинированный |
| y = a + bx + cx 2 | x1 = x; x2 = x 2 | Замена переменных |
| y = a + bx + cx 2 + dx 3 | x1 = x; x2 = x 2 ; x3 = x 3 | Замена переменных |
| y = a + b/x | x1 = 1/x | Замена переменных |
| y = a + sqrt(x)b | x1 = sqrt(x) | Замена переменных |
Пример . По данным, взятым из соответствующей таблицы, выполнить следующие действия:
- Построить поле корреляции и сформулировать гипотезу о форме связи.
- Рассчитать параметры уравнений линейной, степенной, экспоненциальной, полулогарифмической, обратной, гиперболической парной регрессии.
- Оценить тесноту связи с помощью показателей корреляции и детерминации.
- Дать с помощью среднего (общего) коэффициента эластичности сравнительную оценку силы связи фактора с результатом.
- Оценить с помощью средней ошибки аппроксимации качество уравнений.
- Оценить с помощью F-критерия Фишера статистическую надежность результатов регрессионного моделирования. По значениям характеристик, рассчитанных в пп. 4, 5 и данном пункте, выбрать лучшее уравнение регрессии и дать его обоснование.
- Рассчитать прогнозное значение результата, если прогнозное значение фактора увеличится на 15% от его среднего уровня. Определить доверительный интервал прогноза для уровня значимости α=0,05 .
- Оценить полученные результаты, выводы оформить в аналитической записке.
| Год | Фактическое конечное потребление домашних хозяйств (в текущих ценах), млрд. руб. (1995 г. — трлн. руб.), y | Среднедушевые денежные доходы населения (в месяц), руб. (1995 г. — тыс. руб.), х |
| 1995 | 872 | 515,9 |
| 2000 | 3813 | 2281,1 |
| 2001 | 5014 | 3062 |
| 2002 | 6400 | 3947,2 |
| 2003 | 7708 | 5170,4 |
| 2004 | 9848 | 6410,3 |
| 2005 | 12455 | 8111,9 |
| 2006 | 15284 | 10196 |
| 2007 | 18928 | 12602,7 |
| 2008 | 23695 | 14940,6 |
| 2009 | 25151 | 16856,9 |
Решение. В калькуляторе последовательно выбираем виды нелинейной регрессии. Получим таблицу следующего вида.
Экспоненциальное уравнение регрессии имеет вид y = a e bx
После линеаризации получим: ln(y) = ln(a) + bx
Получаем эмпирические коэффициенты регрессии: b = 0.000162, a = 7.8132
Уравнение регрессии: y = e 7.81321500 e 0.000162x = 2473.06858e 0.000162x
Степенное уравнение регрессии имеет вид y = a x b
После линеаризации получим: ln(y) = ln(a) + b ln(x)
Эмпирические коэффициенты регрессии: b = 0.9626, a = 0.7714
Уравнение регрессии: y = e 0.77143204 x 0.9626 = 2.16286x 0.9626
Гиперболическое уравнение регрессии имеет вид y = b/x + a + ε
После линеаризации получим: y=bx + a
Эмпирические коэффициенты регрессии: b = 21089190.1984, a = 4585.5706
Эмпирическое уравнение регрессии: y = 21089190.1984 / x + 4585.5706
Логарифмическое уравнение регрессии имеет вид y = b ln(x) + a + ε
Эмпирические коэффициенты регрессии: b = 7142.4505, a = -49694.9535
Уравнение регрессии: y = 7142.4505 ln(x) — 49694.9535
Теснота связи нелинейных уравнений регрессии
Регрессионный анализ позволяет приближенно определить форму связи между результативным и факторными признаками, а также решить вопрос о том, значима ли эта связь. Вид функции, с помощью которой приближенно выражается форма связи, выбирают заранее, исходя из содержательных соображений или визуального анализа данных. Математическое решение задачи основано на методе наименьших квадратов.
Суть метода наименьших квадратов. Рассмотрим содержание метода на конкретном примере. Пусть имеются данные о сборе хлеба на душу населения по совокупности черноземных губерний. От каких факторов зависит величина этого сбора? Вероятно, определяющее влияние на величину сбора хлеба оказывает величина посева и уровень урожайности. Рассмотрим сначала зависимость величины сбора хлеба на душу населения от размера посева на душу ( столбцы 1 и 2 табл .4 ) Попытаемся представить интересующую нас зависимость с помощью прямой линии. Разумеется, такая линия может дать только приближенное представление о форме реальной статистической связи. Постараемся сделать это приближение наилучшим. Оно будет тем лучше, чем меньше исходные данные будут отличаться от соответствующих точек, лежащих на линии. Степень близости может быть выражена величиной суммы квадратов отклонении, реальных значений от, расположенных на прямой. Использование именно квадратов отклонений (не просто отклонений) позволяет суммировать отклонения различных знаков без их взаимного погашения и дополнительно обеспечивает сравнительно большее внимание, уделяемое большим отклонениям. Именно этот критерий (минимизация суммы квадратов отклонений) положен в основу метода наименьших квадратов.
В вычислительном аспекте метод наименьших квадратов сводится к составлению и решению системы так называемых нормальных уравнений. Исходным этапом для этого является подбор вида функции, отображающей статистическую связь.
Тип функции в каждом конкретном случае можно подобрать путем прикидки на графике исходных данных подходящей, т. е. достаточно хорошо приближающей эти данные, линии. В нашем случае связь между сбором хлеба на душу и величиной посева на душу может быть изображена с помощью прямой линии ( рис. 14 ) и записана в виде
где у—величина сбора хлеба на душу (результативный признак или зависимая переменная); x—величина посева на душу (факторный признак или независимая переменная); a o и a 1 — параметры уравнения, которые могут быть найдены методом наименьших квадратов.
Для нахождения искомых параметров нужно составить систему уравнений, которая в данном случае будет иметь вид
Полученная система может быть решена известным из школьного курса методом Гаусса. Искомые параметры системы из двух нормальных уравнений можно вычислить и непосредственно с помощью последовательного использования нижеприведенных формул:
где y i — i-e значение результативного признака; x i — i-e значение факторного признака; и — средние арифметические результативного и факторного признаков соответственно; n— число значений признака y i , или, что то же самое, число значений признака x i .
Пример 9. Найдем уравнение линейной связи между величиной сбора хлеба (у) и размером посева (х) по данным табл. 4. Проделав необходимые вычисления, получим из (6.17):
Таким образом, уравнение связи, или, как принято говорить, уравнение регрессии, выглядит следующим образом:
Интерпретация коэффициента регрессии. Уравнение регрессии не только определяет форму анализируемой связи, но и показывает, в какой степени изменение одного признака сопровождается изменением другого признака.
Коэффициент при х, называемый коэффициентом регрессии, показывает, на какую величину в среднем изменяется результативный признак у при изменении факторного признака х на единицу.
В примере 9 коэффициент регрессии получился равным 24,58. Следовательно, с увеличением посева, приходящегося на душу, на одну десятину сбор хлеба на душу населения в среднем увеличивается на 24,58 пуда.
Средняя и предельная ошибки коэффициента регрессии. Поскольку уравнения регрессии рассчитываются, как правило, для выборочных данных, обязательно встают вопросы точности и надежности полученных результатов. Вычисленный коэффициент регрессии, будучи выборочным, с некоторой точностью оценивает соответствующий коэффициент регрессии генеральной совокупности. Представление об этой точности дает средняя ошибка коэффициента регрессии ( ), рассчитываемая по формуле
у i , — i-e значение результативного признака; ŷ i — i-e выравненное значение, полученное из уравнения (6.15); x i —i-e значение факторного признака; σ x —среднее квадратическое отклонение х; n — число значений х или, что то же самое, значений у; m—число факгорных признаков (независимых переменных).
В формуле (6.18), в частности, формализовано очевидное положение: чем больше фактические значения отклоняются от выравненных, тем большую ошибку следует ожидать; чем меньше число наблюдений, на основе которых строится уравнение, тем больше будет ошибка.
Средняя ошибка коэффициента регрессии является основой для расчета предельной ошибки. Последняя показывает, в каких пределах находится истинное значение коэффициента регрессии при заданной надежности результатов. Предельная ошибка коэффициента регрессии вычисляется аналогично предельной ошибке средней арифметической (см. гл. 5), т. е. как t где t—величина, числовое значение которой определяется в зависимости от принятого уровня надежности.
Пример 10. Найти среднюю и предельную ошибки коэффициента регрессии, полученного в примере 9.
Для расчета прежде всего подсчитаем выравненные значения ŷ i для чего в уравнение регрессии, полученное в примере 9, подставим конкретные значения x i :
ŷ i = 17,6681 +24,5762*0,91 = 40,04 и т. д.
Затем вычислим отклонения фактических значений у i , от выравненных и их квадраты
Далее, подсчитав средний по черноземным губерниям посев на душу ( =0,98), отклонения фактических значений x i от этой средней, квадраты отклонений и среднее квадратическое отклонение , получим все необходимые составляющие формул (618) и (619):
Таким образом, средняя ошибка коэффициента регрессии равна 2,89, что составляет 12% от вычисленного коэффициента
Задавшись уровнем надежности, равным 0,95, найдем по табл. 1 приложения соответствующее ему значение t=1,96, рассчитаем предельную ошибку 1,96*2,89=5,66 и пределы коэффициента регрессии для принятого уровня надежности ( В случае малых выборок величина t находится из табл. 2 приложения. ). Нижняя граница коэффициента регрессии равна 24,58-5,66=18,92, а верхняя граница 24,58+5,66=30,24
Средняя квадратическая ошибка линии регрессии. Уравнение регрессии представляет собой функциональную связь, при которой по любому значению х можно однозначно определить значение у. Функциональная связь лишь приближенно отражает связь реальную, причем степень этого приближения может быть различной и зависит она как от свойств исходных данных, так и от выбора вида функции, по которой производится выравнивание.
На рис. 15 представлены два различных случая взаимоотношения между двумя признаками. В обоих случаях предполагаемая связь описывается одним и тем же уравнением, но во втором случае соотношение между признаками х и у достаточно четко выражено и уравнение, по-видимому, довольно хорошо описывает это соотношение, тогда как в первом случае сомнительно само наличие сколько-нибудь закономерного соотношения между признаками. И в том, и в другом случаях, несмотря на их существенное различие, метод наименьших квадратов дает одинаковое уравнение, поскольку этот метод нечувствителен к потенциальным возможностям исходного материала вписаться в ту или иную схему. Кроме того, метод наименьших квадратов применяется для расчета неизвестных параметров заранее выбранного вида функции, и вопрос о выборе наиболее подходящего для конкретных данных вида функции в рамках этого метода не ставится и не решается. Таким образом, при пользовании методом наименьших квадратов открытыми остаются два важных вопроса, а именно: существует ли связь и верен ли выбор вида функции, с помощью которой делается попытка описать форму связи.
Чтобы оценить, насколько точно уравнение регрессии описывает реальные соотношения между переменными, нужно ввести меру рассеяния фактических значений относительно вычисленных с помощью уравнения. Такой мерой служит средняя квадратическая ошибка регрессионного уравнения, вычисляемая по приведенной выше формуле (6.19).
Пример 11. Определить среднюю квадратическую ошибку уравнения, полученного в примере 9.
Промежуточные расчеты примера 10 дают нам среднюю квадратическую ошибку уравнения. Она равна 4,6 пуда.
Этот показатель аналогичен среднему квадратическому отклонению для средней. Подобно тому, как по величине среднего квадратического отклонения можно судить о представительности средней арифметической (см. гл. 5), по величине средней квадратической ошибки регрессионного уравнения можно сделать вывод о том, насколько показательна для соотношения между признаками та связь, которая выявлена уравнением. В каждом конкретном случае фактическая ошибка может оказаться либо больше, либо меньше средней. Средняя квадратическая ошибка уравнения показывает, насколько в среднем мы ошибемся, если будем пользоваться уравнением, и тем самым дает представление о точности уравнения. Чем меньше σ y.x , тем точнее предсказание линии регрессии, тем лучше уравнение регрессии описывает существующую связь. Показатель σ y.x позволяет различать случаи, представленные на рис. 15. В случае б) он окажется значительно меньше, чем в случае а). Величина σ y.x зависит как от выбора функции, так и от степени описываемой связи.
Варьируя виды функций для выравнивания и оценивая результаты с помощью средней квадратической ошибки, можно среди рассматриваемых выбрать лучшую функцию, функцию с наименьшей средней ошибкой. Но существует ли связь? Значимо ли уравнение регрессии, используемое для отображения предполагаемой связи? На эти вопросы отвечает определяемый ниже критерий значи-мости регрессии.
Мерой значимости линии регрессии может служить следующее соотношение:
где ŷ i —i-e выравненное значение; —средняя арифметическая значений y i ; σ y.x —средняя квадратическая ошибка регрессионного уравнения, вычисляемая по формуле (6.19); n—число сравниваемых пар значений признаков; m—число факторных признаков.
Действительно, связь тем больше, чем значительнее мера рассеяния признака, обусловленная регрессией, превосходит меру рассеяния отклонений фактических значений от выравненных.
Соотношение (6.20) позволяет решить вопрос о значимости регрессии. Регрессия значима, т. е. между признаками существует линейная связь, если для данного уровня значимости вычисленное значение F ф [m,n-(m+1)] превышает критическое значение F кр [m,n-(m+1)], стоящее на пересечении m-го столбца и [n—(m+1)]-й строки специальной таблицы ( см. табл. 4 приложения ).
Пример 12. Выясним, связаны ли сбор хлеба на душу населения и посев на душу населения линейной зависимостью.
Воспользуемся F-критерием значимости регрессии. Подставив в формулу (6.20) данные табл. 4 и результат примера 10, получим
Обращаясь к таблице F-распределения для Р=0,95 (α=1—Р=0,5) и учитывая, что n=23, m =1, в табл. 4А приложения на пересечения 1-го столбца и 21-й строки находим критическое значение F кр , равное 4,32 при степени надежности Р=0,95. Поскольку вычисленное значение F ф существенно превосходит по величине F кр , то обнаруженная линейная связь существенна, т. е. априорная гипотеза о наличии линейной связи подтвердилась. Вывод сделан при степени надежности P=0,95. Между прочим, вывод в данном случае останется прежним, если надежность повысить до Р=0,99 (соответствующее значение F кр =8,02 по табл. 4Б приложения для уровня значимости α=0,01).
Коэффициент детерминации. С помощью F-критерия мы Установили, что существует линейная зависимость между величиной сбора хлеба и величиной посева на душу. Следовательно, можно утверждать, что величина сбора хлеба, приходящегося на душу, линейно зависит от величины посева на душу. Теперь уместно поставить уточняющий вопрос — в какой степени величина посева на душу определяет величину сбора хлеба на душу? На этот вопрос можно ответить, рассчитав, какая часть вариации результативного признака может быть объяснена влиянием факторного признака.
Оно показывает долю разброса, учитываемого регрессией, в общем разбросе результативного признака и носит название коэффициента детерминации. Этот показатель, равный отношению факторной вариации к полной вариации признака, позволяет судить о том, насколько «удачно» выбран вид функции ( Отметим, что по смыслу коэффициент детерминации в регрессионном анализе соответствует квадрату корреляционного отношения для корреляционной таблицы (см. § 2). ). Проведя расчеты, основанные на одних и тех же исходных данных, для нескольких типов функций, мы можем из них выбрать такую, которая дает наибольшее значение R 2 и, следовательно, в большей степени, чем другие функции, объясняет вариацию результативного признака. Действительно, при расчете R 2 для одних и тех же данных, но разных функций знаменатель выражения (6.21) остается неизменным, а числитель показывает ту часть вариации результативного признака, которая учитывается выбранной функцией. Чем больше R 2 , т. е. чем больше числитель, тем больше изменение факторного признака объясняет изменение результативного признака и тем, следовательно, лучше уравнение регрессии, лучше выбор функции.
Наконец, отметим, что введенный ранее, при изложении методов корреляционного анализа, коэффициент детерминации совпадает с определенным здесь показателем, если выравнивание производится По прямой линии. Но последний показатель (R 2 ) имеет более широкий спектр применения и может использоваться в случае связи, отличной от линейной ( см. § 4 данной главы ).
Пример 13. Рассчитать коэффициент детерминации для уравнения, полученного в примере 9.
Вычислим R 2 , воспользовавшись формулой (6.21) и данными табл. 4:
Итак, уравнение регрессии почти на 78% объясняет колебания сбора хлеба на душу. Это немало, но, По-видимому, можно улучшить модель введением в нее еще одного фактора.
Случай двух независимых переменных. Простейший случай множественной регрессии. В предыдущем изложении регрессионного анализа мы имели дело с двумя признаками — результативным и факторным. Но на результат действует обычно не один фактор, а несколько, что необходимо учитывать для достаточно полного анализа связей.
В математической статистике разработаны методы множественной регрессии ( Регрессия называется множественной, если число независимых переменных, учтенных в ней, больше или равно двум. ), позволяющие анализировать влияние на результативный признак нескольких факторных. К рассмотрению этих методов мы и переходим.
Возвратимся к примеру 9. В нем была определена форма связи между величиной сбора хлеба на душу и размером посева на душу. Введем в анализ еще один фактор — уровень урожайности (см. столбец З табл. 4). Без сомнения, эта переменная влияет на сбор хлеба на душу. Но в какой степени влияет? Насколько обе независимые переменные определяют сбор хлеба на душу в черноземных губерниях? Какая из переменных — посев на душу или урожайность — оказывает определяющее влияние на сбор хлеба? Попытаемся ответить на эти вопросы.
После добавления второй независимой переменной уравнение регрессии будет выглядеть так:
где у—сбор хлеба на душу; х 1 —размер посева на душу; x 2 —урожай с десятины (в пудах); а 0 , а 1 , а 2 —параметры, подлежащие определению.
Для нахождения числовых значений искомых параметров, как и в случае одной независимой переменной, пользуются методом наименьших квадратов. Он сводится к составлению и решению системы нормальных уравнений, которая имеет вид
Когда система состоит из трех и более нормальных уравнений, решение ее усложняется. Существуют стандартные программы расчета неизвестных параметров регрессионного уравнения на ЭВМ. При ручном счете можно воспользоваться известным из школьного курса методом Гаусса.
Пример 14. По данным табл. 4 описанным способом найдем параметры a 0 , а 1 , а 2 уравнения (6.22). Получены следующие результаты: a 2 =0,3288, a 1 =28,7536, a 0 =-0,2495.
Таким образом, уравнение множественной регрессии между величиной сбора хлеба на душу населения (у), размером посева на душу (x 1 ) и уровнем урожайности (х 2 ) имеет вид:
у=-0,2495+28,7536x 1 +0,3288x 2 .
Интерпретация коэффициентов уравнения множественной регрессии. Коэффициент при х 1 в полученном уравнении отличается от аналогичного коэффициента в уравнении примера 9.
Коэффициент при независимой переменной в уравнении простой регрессии отличается от коэффициента при соответствующей переменной в уравнении множественной регрессии тем, что в последнем элиминировано влияние всех учтенных в данном уравнении признаков.
Коэффициенты уравнения множественной регрессии поэтому называются частными или чистыми коэффициентами регрессии.
Частный коэффициент множественной регрессии при х 1 показывает, что с увеличением посева на душу на 1 дес. и при фиксированной урожайности сбор хлеба на душу населения вырастает в среднем на 28,8 пуда. Частный коэффициент при x 2 показывает, что при фиксированном посеве на душу увеличение урожая на единицу, т. е. на 1 пуд с десятины, вызывает в среднем увеличение сбора хлеба на душу на 0,33 пуда. Отсюда можно сделать вывод, что увеличение сбора хлеба в черноземных губерниях России идет, в основном, за счет расширения посева и в значительно меньшей степени—за счет повышения урожайности, т. е. экстенсивная форма развития зернового хозяйства является господствующей.
Введение переменной х 2 в уравнение позволяет уточнить коэффициент при х 1 . Конкретно, коэффициент оказался выше (28,8 против 24,6), когда в изучаемой связи вычленилось влияние урожайности на сбор хлеба.
Однако выводы, полученные в результате анализа коэффициентов регрессии, не являются пока корректными, поскольку, во-первых, не учтена разная масштабность факторов, во-вторых, не выяснен вопрос о значимости коэффициента a 2 .
Величина коэффициентов регрессии изменяется в зависимости от единиц измерения, в которых представлены переменные. Если переменные выражены в разном масштабе измерения, то соответствующие им коэффициенты становятся несравнимыми. Для достижения сопоставимости коэффициенты регрессии исходного уравнения стандартизуют, взяв вместо исходных переменных их отношения к собственным средним квадратическим отклонениям. Тогда уравнение (6.22) приобретает вид
Сравнивая полученное уравнение с уравнением (6.22), определяем стандартизованные частные коэффициенты уравнения, так называемые бета-коэффициенты, по формулам:
где β 1 и β 2 —бета-коэффициенты; а 1 и а 2 —коэффициенты регрессии исходного уравнения; σ у , , и — средние квадратические отклонения переменных у, х 1 и х 2 соответственно.
Вычислив бета-коэффициенты для уравнения, полученного в примере 14:
видим, что вывод о преобладании в черноземной полосе россии экстенсивной формы развития хозяйства над интенсивной остается в силе, так как β 1 значительно больше, чем β 2 .
Оценка точности уравнения множественной регрессии.
Точность уравнения множественной регрессии, как и в случае уравнения с одной независимой переменной, оценивается средней квадратической ошибкой уравнения. Обозначим ее , где подстрочные индексы указывают, что результативным признаком в уравнении является у, а факторными признаками х 1 и x 2 . Для расчета средней квадратической ошибки уравнения множественной регрессии применяется приведенная выше формула (6.19).
Пример 15. Оценим точность полученного в примере 14 уравнения регрессии.
Воспользовавшись формулой (6.19) и данными табл. 4, вычислим среднюю квадратическую ошибку уравнения:
Оценка полезности введения дополнительной переменной. Точность уравнения регрессии тесно связана с вопросом ценности включения дополнительных членов в это уравнение.
Сравним средние квадратические ошибки, рассчитанные для уравнения с одной переменной х 1 (пример 11) и для уравнения с двумя независимыми переменными х 1 и х 2 . Включение в уравнение новой переменной (урожайности) уменьшило среднюю квадратическую ошибку почти вдвое.
Можно провести сравнение ошибок с помощью коэффициентов вариации
где σ f —средняя квадратическая ошибка регрессионного уравнения; —средняя арифметическая результативного признака.
Для уравнения, содержащего одну независимую переменную:
Для уравнения, содержащего две независимые переменные:
Итак, введение независимой переменной «урожайность» уменьшило среднюю квадратическую ошибку до величины порядка 7,95% среднего значения зависимой переменной.
Наконец, по формуле (6.21) рассчитаем коэффициент детерминации
Он показывает, что уравнение регрессии на 81,9% объясняет колебания сбора хлеба на душу населения. Сравнивая полученный результат (81,9%) с величиной R 2 для однофакторного уравнения (77,9%), видим, что включение переменной «урожайность» заметно увеличило точность уравнения.
Таким образом, сравнение средних квадратических ошибок уравнения, коэффициентов вариации, коэффициентов детерминации, рассчитанных до и после введения независимой переменной, позволяет судить о полезности включения этой переменной в уравнение. Однако следует быть осторожными в выводах при подобных сравнениях, поскольку увеличение R 2 или уменьшение σ и V σ не всегда имеют приписываемый им здесь смысл. Так, увеличение R 2 может объясняться тем фактом, что число рассматриваемых параметров в уравнении приближается к числу объектов наблюдения. Скажем, весьма сомнительными будут ссылки на увеличение R 2 или уменьшение σ, если в уравнение вводится третья или четвертая независимая переменная и уравнение строится на данных по шести, семи объектам.
Полезность включения дополнительного фактора можно оценить с помощью F-критерия.
Частный F-критерий показывает степень влияния дополнительной независимой переменной на результативный признак и может использоваться при решении вопроса о добавлении в уравнение или исключении из него этой независимой переменной.
Разброс признака, объясняемый уравнением регрессии (6.22), можно разложить на два вида: 1) разброс признака, обусловленный независимой переменной х 1 , и 2) разброс признака, обусловленный независимой переменной x 2 , когда х 1 уже включена в уравнение. Первой составляющей соответствует разброс признака, объясняемый уравнением (6.15), включающим только переменную х 1 . Разность между разбросом признака, обусловленным уравнением (6.22), и разбросом признака, обусловленным уравнением (6.15), определит ту часть разброса, которая объясняется дополнительной независимой переменной x 2 . Отношение указанной разности к разбросу признака, регрессией не объясняемому, представляет собой значение частного критерия. Частный F-критерий называется также последовательным, если статистические характеристики строятся при последовательном добавлении переменных в регрессионное уравнение.
Пример 16. Оценить полезность включения в уравнение регрессии дополнительной переменной «урожайность» (по данным и результатам примеров 12 и 15).
Разброс признака, объясняемый уравнением множественной регрессии и рассчитываемый как сумма квадратов разностей выравненных значений и их средней, равен 1623,8815. Разброс признака, объясняемый уравнением простой регрессии, составляет 1545,1331.
Разброс признака, регрессией не объясняемый, определяется квадратом средней квадратической ошибки уравнения и равен 10,9948 (см. пример 15).
Воспользовавшись этими характеристиками, рассчитаем частный F-критерий
С уровнем надежности 0,95 (α=0,05) табличное значение F (1,20), т. е. значение, стоящее на пересечении 1-го столбца и 20-й строки табл. 4А приложения, равно 4,35. Рассчитанное значение F ф значительно превосходит табличное, и, следовательно, включение в уравнение переменной «урожайность» имеет смысл.
Таким образом, выводы, сделанные ранее относительно коэффициентов регрессии, вполне правомерны.
Важным условием применения к обработке данных метода множественной регрессии является отсутствие сколько-нибудь значительной взаимосвязи между факторными признаками. При практическом использовании метода множественной регрессии, прежде чем включать факторы в уравнение, необходимо убедиться в том, что они независимы.
Если один из факторов зависит линейно от другого, то система нормальных уравнений, используемая для нахождения параметров уравнения, не разрешима. Содержательно этот факт можно толковать так: если факторы х 1 и x 2 связаны между собой, то они действуют на результативный признак у практически как один фактор, т. е. сливаются воедино и их влияние на изменение у разделить невозможно. Когда между независимыми переменными уравнения множественной регрессии имеется линейная связь, следствием которой является неразрешимость системы нормальных уравнений, то говорят о наличии мультиколлинеарности.
На практике вопрос о наличии или об отсутствии мультиколлинеарности решается с помощью показателей взаимосвязи. В случае двух факторных признаков используется парный коэффициент корреляции между ними: если этот коэффициент по абсолютной величине превышает 0,8, то признаки относят к числу мультиколлинеарных. Если число факторных признаков больше двух, то рассчитываются множественные коэффициенты корреляции. Фактор признается мультиколлинеарным, если множественный коэффициент корреляции, характеризующий совместное влияние на этот фактор остальных факторных признаков, превзойдет по величине коэффициент множественной корреляции между результативным признаком и совокупностью всех независимых переменных.
Самый естественный способ устранения мультиколлинеарности — исключение одного из двух линейно связанных факторных признаков. Этот способ прост, но не всегда приемлем, так как подлежащий исключению фактор может оказывать на зависимую переменную особое влияние. В такой ситуации применяются более сложные методы избавления от мультиколлинеарности ( См.: Мот Ж. Статистические предвидения и решения на предприятии. М., 1966; Ковалева Л. Н. Многофакторное прогнозирование на основе рядов динамики. М., 1980. ).
Выбор «наилучшего» уравнения регрессии. Эта проблема связана с двойственным отношением к вопросу о включении в регрессионное уравнение независимых переменных. С одной стороны, естественно стремление учесть все возможные влияния на результативный признак и, следовательно, включить в модель полный набор выявленных переменных. С другой стороны, возрастает сложность расчетов и затраты, связанные с получением максимума информации, могут оказаться неоправданными. Нельзя забывать и о том, что для построения уравнения регрессии число объектов должно в несколько раз превышать число независимых переменных. Эти противоречивые требования приводят к необходимости компромисса, результатом которого и является «наилучшее» уравнение регрессии. Существует несколько методов, приводящих к цели: метод всех возможных регрессий, метод исключения, метод включения, шаговый регрессионный и ступенчатый регрессионный методы.
Метод всех возможных регрессий заключается в переборе и сравнении всех потенциально возможных уравнений. В качестве критерия сравнения используется коэффициент детерминации R 2 . «Наилучшим» признается уравнение с наибольшей величиной R 2 . Метод весьма трудоемок и предполагает использование вычислительных машин.
Методы исключения и включения являются усовершенствованными вариантами предыдущего метода. В методе исключения в качестве исходного рассматривается регрессионное уравнение, включающее все возможные переменные. Рассчитывается частный F-критерий для каждой из переменных, как будто бы она была последней переменной, введенной в регрессионное уравнение. Минимальная величина частного F-критерия (F min ) сравнивается с критической величиной (F кр ), основанной на заданном исследователем уровне значимости. Если F min >F кр , то уравнение остается без изменения. Если F min кр , то переменная, для которой рассчитывался этот частный F-критерий, исключается. Производится перерасчет уравнения регрессии для оставшихся переменных, и процедура повторяется для нового уравнения регрессии. Исключение из рассмотрения уравнений с незначимыми переменными уменьшает объем вычислений, что является достоинством этого метода по сравнению с предыдущим.
Метод включения состоит в том, что в уравнение включаются переменные по степени их важности до тех пор, пока уравнение не станет достаточно «хорошим». Степень важности определяется линейным коэффициентом корреляции, показывающим тесноту связи между анализируемой независимой переменной и результативным признаком: чем теснее связь, тем больше информации о результирующем признаке содержит данный факторный признак и тем важнее, следовательно, введение этого признака в уравнение.
Процедура начинается с отбора факторного признака, наиболее тесно связанного с результативным признаком, т. е. такого факторного признака, которому соответствует максимальный по величине парный линейный коэффициент корреляции. Далее строится линейное уравнение регрессии, содержащее отобранную независимую переменную. Выбор следующих переменных осуществляется с помощью частных коэффициентов корреляции, в которых исключается влияние вошедших в модель факторов. Для каждой введенной переменной рассчитывается частный F-критерий, по величине которого судят о том, значим ли вклад этой переменной. Как только величина частного F-критерия, относящаяся к очередной переменной, оказывается незначимой, т. е. эффект от введения этой переменной становится малозаметным, процесс включения переменных заканчивается. Метод включения связан с меньшим объемом вычислений, чем предыдущие методы. Но при введении новой переменной нередко значимость включенных ранее переменных изменяется. Метод включения этого не учитывает, что является его недостатком. Модификацией метода включения, исправляющей этот недостаток, является шаговый регрессионный метод.
Шаговый регрессионный метод кроме процедуры метода включения содержит анализ переменных, включенных в уравнение на предыдущей стадии. Потребность в таком анализе возникает в связи с тем, что переменная, обоснованно введенная в уравнение на ранней стадии, может оказаться лишней из-за взаимосвязи ее с переменными, позднее включенными в уравнение. Анализ заключается в расчете на каждом этапе частных F-критериев для каждой переменной уравнения и сравнении их с величиной F кр , точкой F-распределения, соответствующей заданному исследователем уровню значимости. Частный F-критерий показывает вклад переменной в вариацию результативного признака в предположении, что она вошла в модель последней, а сравнение его с F кр позволяет судить о значимости рассматриваемой переменной с учетом влияния позднее включенных факторов. Незначимые переменные из уравнения исключаются.
Рассмотренные методы предполагают довольно большой объем вычислений и практически неосуществимы без ЭВМ. Для реализации ступенчатого регрессионного метода вполне достаточно малой вычислительной техники.
Ступенчатый регрессионный метод включает в себя такую последовательность действий. Сначала выбирается наиболее тесно связанная с результативным признаком переменная и составляется уравнение регрессии. Затем находят разности фактических и выравненных значений и эти разности (остатки) рассматриваются как значения результативной переменной. Для остатков подбирается одна из оставшихся независимых переменных и т. д. На каждой стадии проверяется значимость регрессии. Как только обнаружится незначимость, процесс прекращается и окончательное уравнение получается суммированием уравнений, полученных на каждой стадии за исключением последней.
Ступенчатый регрессионный метод менее точен, чем предыдущие, но не столь громоздок. Он оказывается полезным в случаях, когда необходимо внести содержательные правки в уравнение. Так, для изучения факторов, влияющих на цены угля в Санкт-Петербурге в конце XIX— начале XX в., было получено уравнение множественной регрессии. В него вошли следующие переменные: цены угля в Лондоне, добыча угля в России и экспорт из России. Здесь не обосновано появление в модели такого фактора, как добыча угля, поскольку Санкт-Петербург работал исключительно на импортном угле. Модели легко придать экономический смысл, если независимую переменную «добыча» заменить независимой переменной «импорт». Формально такая замена возможна, поскольку между импортом и добычей существует тесная связь. Пользуясь ступенчатым методом, исследователь может совершить эту замену, если предпочтет содержательно интерпретируемый фактор.
§ 4. Нелинейная регрессия и нелинейная корреляция
Построение уравнений нелинейной регрессии. До сих пор мы, в основном, изучали связи, предполагая их линейность. Но не всегда связь между признаками может быть достаточно хорошо представлена линейной функцией. Иногда для описания существующей связи более пригодными, а порой и единственно возможными являются более сложные нелинейные функции. Ограничимся рассмотрением наиболее простых из них.
Одним из простейших видов нелинейной зависимости является парабола, которая в общем виде может быть представлена функцией (6.2):
Неизвестные параметры а 0 , а 1 , а 2 находятся в результате решения следующей системы уравнений:
Дает ли преимущества описание связи с помощью параболы по сравнению с описанием, построенным по гипотезе линейности? Ответ на этот вопрос можно получить, рассчитав последовательный F-критерий, как это делалось в случае множественной регрессии (см. пример 16).
На практике для изучения связей используются полиномы более высоких порядков (3-го и 4-го порядков). Составление системы, ее решение, а также решение вопроса о полезности повышения порядка функции для этих случаев аналогичны описанным. При этом никаких принципиально новых моментов не возникает, но существенно увеличивается объем расчетов.
Кроме класса парабол для анализа нелинейных связей можно применять и другие виды функций. Для расчета неизвестных параметров этих функций рекомендуется использовать метод наименьших квадратов, как наиболее мощный и широко применяемый.
Однако метод наименьших квадратов не универсален, поскольку он может использоваться только при условии, что выбранные для выравнивания функции линейны по отношению к своим параметрам. Не все функции удовлетворяют этому условию, но большинство применяемых на практике с помощью специальных преобразований могут быть приведены к стандартной форме функции с линейными параметрами.
Рассмотрим некоторые простейшие способы приведения функций с нелинейными параметрами к виду, который позволяет применять к ним метод наименьших квадратов.
Функция не является линейной относительно своих параметров.
Прологарифмировав обе части приведенного равенства
получим функцию, линейную относительно своих новых параметров:
Кроме логарифмирования для приведения функций к нужному виду используют обратные величины.
с помощью следующих переобозначений:
может быть приведена к виду
Подобные преобразования расширяют возможности использования метода наименьших квадратов, увеличивая число функций, к которым этот метод применим.
Измерение тесноты связи при криволинейной зависимости. Рассмотренные ранее линейные коэффициенты корреляции оценивают тесноту взаимосвязи при линейной связи между признаками. При наличии криволинейной связи указанные меры связи не всегда приемлемы. Разберем подобную ситуацию на примере.
Пример 17. В 1-м и 2-м столбцах табл. 5 приведены значения результативного признака у и факторного признака х (данные условные). Поставив вопрос о тесноте связи между ними, рассчитаем парный линейный коэффициент корреляции по формуле (6.3). Он оказался равным нулю, что свидетельствует об отсутствии линейной связи. Тем не менее связь между признаками существует, более того, она является функциональной и имеет вид
Для измерения тесноты связи при криволинейной зависимости используется индекс корреляции, вычисляемый по формуле
где у i —i-e значение результативного признака; ŷ i —i-e выравненное значение этого признака; —среднее арифметическое значение результативного признака.
Числитель формулы (6.27) характеризует разброс выравненных значений результативного признака. Поскольку изменения выравненных, т. е. вычисленных по уравнению регрессии, значений признака происходят только в результате изменения факторного признака х. то числитель измеряет разброс результативного признака, обусловленный влиянием на него факторного признака. Знаменатель же измеряет разброс признака-результата, который определен влиянием на него всех факторов, в том числе и учтенного. Таким образом, индекс корреляции оценивает участие данного факторного признака в общем действии всего комплекса факторов, вызывающих колеблемость результативного признака, тем самым определяя тесноту зависимости признака у от признака х. При этом, если признак х не вызывает никаких изменений признака у, то числитель и, следовательно, индекс корреляции равны 0. Если же линия регрессии полностью совпадает с фактическими данными, т. е. признаки связаны функционально, как в примере 17, то индекс корреляции равен 1. В случае линейной зависимости между х и у индекс корреляции численно равен линейному коэффициенту корреляции г. Квадрат индекса корреляции совпадает с введенным ранее (6.21) коэффициентом детерминации. Если же вопрос о форме связи не ставится, то роль коэффициента детерминации играет квадрат корреляционного отношения η 2 y/x (6.12).
Таковы основные принципы и условия, методика и техника применения корреляционного и регрессионного анализа. Их подробное рассмотрение обусловлено тем, что они являются высокоэффективными и потому очень широко применяемыми методами анализа взаимосвязей в объективном мире природы и общества. Корреляционный и регрессионный анализ широко и успешно применяются и в исторических исследованиях.
Оценка корреляции для нелинейной регрессии
Оценка тесноты корреляционной зависимости в случае нелинейной регрессии производится с помощью индекса корреляции (R):
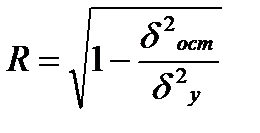 , (39.1)
, (39.1)
где 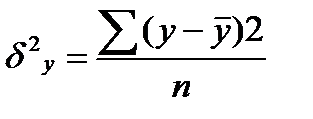 ,
, 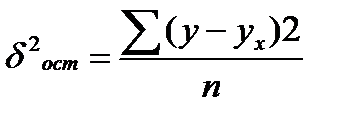 ,
, 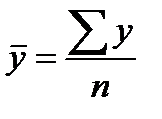 (39.2)
(39.2)
y¯x значения результативного признака, рассчитанные по уравнению регрессии.
Величина данного показателя находится в границах: 0≤ R ≤ 1 , чем она ближе к единице, тем теснее связь рассматриваемых признаков, тем надежнее найденное уравнение регрессии.
Следует помнить, что если для линейной зависимости имеет место равенство: ryx =rxy , то при криволинейной зависимости y=f(x) Ryx не равен Rxy.
Величина R 2 называется индексом детерминации.
Оценка существенности индекса корреляции проводится, так же как и оценка надежности коэффициента корреляции. Индекс детерминации используется для проверки существенности в целом уравнения нелинейной регрессии по F-критерию Фишера:
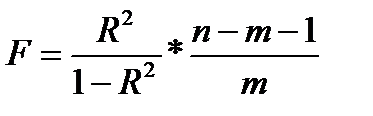 , (39.3)
, (39.3)
где R 2 — индекс детерминации;
n — число наблюдений;
m — число параметров при переменных х.
Индекс детерминации R 2 yx можно сравнивать с коэффициентом детерминации r 2 yx для обоснования возможности применения линейной функции.
Если величина (R 2 yx — r 2 yx) не превышает 0,1, то предположение о линейной форме связи считается оправданным. В противном случае проводится оценка существенности различия между R 2 yx и r 2 yx , вычисленных по одним и тем же исходным данным, через t — критерий Стьюдента:
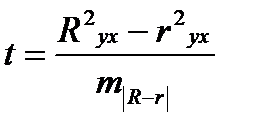 , (39.4)
, (39.4)
где 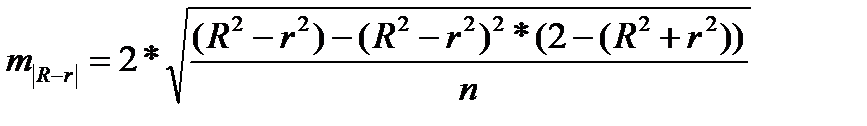 , (39.5)
, (39.5)
Если t факт> t табл, то различия между Ryx и ryx существенны и замена нелинейной регрессии линейной — невозможна. Практически, если t ≤ 2, то различия между Ryx и ryx несущественны, и, следовательно, возможно применение линейной регрессии.
Фактические значения результативного признака отличаются от теоретических, рассчитанных по уравнению регрессии, т.е. y и yx. Чем меньше это отличие, тем ближе теоретические значения подходят к эмпирическим данным, лучше качество модели. Чтобы иметь общее представление о качестве модели из относительных отклонений по каждому наблюдению, определяют среднюю ошибку аппроксимации:
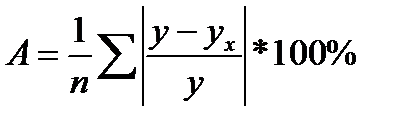 (39.6)
(39.6)
Существует и другая формула определения средней ошибки аппроксимации:
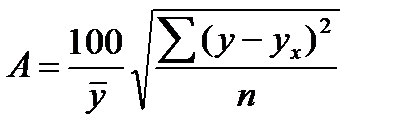 , (39.7)
, (39.7)
где 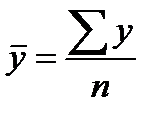 . (39.8)
. (39.8)
Ошибка аппроксимации в пределах 5-7% свидетельствует о хорошем подборе модели к исходным данным.
Возможность построения нелинейных моделей, как с помощью их приведения к линейному виду, так и путем использования нелинейной регрессии, значительно повышает универсальность регрессионного анализа, но и усложняет задачу исследователя.
Возникает вопрос: с чего начать — с линейной зависимости или с нелинейной, и если с последней, то, какого типа.
Если ограничиться парной регрессией, то можно построить график наблюдений у и х и принять решение. Однако очень часто несколько разных нелинейных функцией приблизительно соответствуют наблюдениям, если они лежать на некоторой кривой. А в случае множествен6ной регрессии невозможно даже построить график.
37. Проверка гипотезы о значимости нелинейной модели регрессии. Проверка гипотезы о линейной зависимости между переменными модели регрессии
Хотя во многих практических случаях моделирование экономических зависимостей линейными уравнениями дает вполне удовлетворительный результат, однако ограничиться рассмотрением лишь линейных регрессионных моделей невозможно. Так близость линейного коэффициента корреляции к нулю еще не значит, что связь между соответствующими экономическими переменными отсутствует. При слабой линейной связи может быть очень тесной, например, не линейная связь. Поэтому необходимо рассмотреть и нелинейные регрессии, построение и анализ которых имеют свою специфику.
В случае, когда между экономическими явлениями существует нелинейные соотношения, то они выражаются с помощью соответствующих нелинейных эконометрических моделей.
38. Двухфакторная производственная функция Кобба-Дугласа
Производственная функцию Кобба –Дугласа выглядит следующим образом:
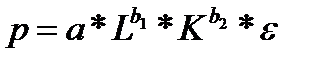 (44.1)
(44.1)
где Р –объем продукции
L— затраты труда;
К — величина капитала;
Логарифмируя ее, получим линейное в логарифмах уравнение
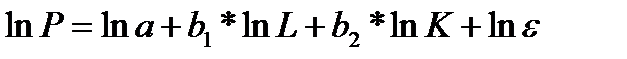 (44.2)
(44.2)
Оценив параметры этого уравнения по МНК, можно найти теоретические значения объема продукции Р^ и соответственно остаточную сумму квадратов Σ (Р — Р^) 2 которая используется в расчете индекса детерминации:
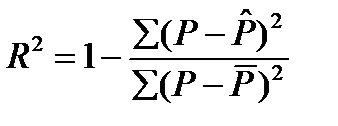 (44.3)
(44.3)
Следует помнить, что МНК применяется не к исходным данным продукции, а к их логарифмам. Поэтому в индексе корреляции с общей суммой квадратов Σ (Р — Р¯) 2 сравнивается остаточная дисперсия, которая определена по теоретическим значениям логарифмов продукции:
Σ (Р — антилогарифм (ln Р)) 2 . Т.е. Р^ находится в следствии потенцированиия ln Р.
39. Отбор факторов для экономертических моделей
Хотя теоретически регрессионная модель позволяет учесть любое число факторов, практически в этом нет необходимости. Отбор факторов производится на основе качественного теоретико-экономического анализа, который обычно осуществляется в две стадии: на первой подбираются факторы исходя из сущности проблемы; на второй – на основе показателей корреляции определяют t-статистики для параметров регрессии. Коэффициенты интеркорреляции (т. е. корреляции между объясняющими переменными) позволяют исключать из модели дублирующие факторы. Считается, что две переменных явно коллинеарны, т. е. находятся между собой в линейной зависимости, если 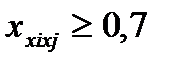 . Если факторы явно коллинеарны, то они дублируют друг друга и один из них рекомендуется исключить из регрессии. Предпочтение при этом отдается не фактору, более тесно связанному с результатом, а тому фактору, который при достаточно тесной связи с результатом имеет наименьшую тесноту связи с другими факторами. В этом требовании проявляется специфика множественной регрессии как метода исследования комплексного воздействия факторов в условиях их независимости друг от друга. Наибольшие трудности в использовании аппарата множественной регрессии возникают при наличии мультиколлинеарности факторов, когда более чем два фактора связаны между собой линейной зависимостью. Наличие мультиколлинеарности факторов может означать, что некоторые факторы будут всегда действовать в унисон. В результате вариация в исходных данных перестает быть полностью независимой, и нельзя оценить воздействие каждого фактора в отдельности. Чем сильнее мультиколлинеарность факторов, тем менее надежна оценка распределения суммы объясненной вариации по отдельным факторам с помощью метода наименьших квадратов (МНК). Включение в модель мультиколлинеарныхфакторов нежелательно в силу следующих последствий:
. Если факторы явно коллинеарны, то они дублируют друг друга и один из них рекомендуется исключить из регрессии. Предпочтение при этом отдается не фактору, более тесно связанному с результатом, а тому фактору, который при достаточно тесной связи с результатом имеет наименьшую тесноту связи с другими факторами. В этом требовании проявляется специфика множественной регрессии как метода исследования комплексного воздействия факторов в условиях их независимости друг от друга. Наибольшие трудности в использовании аппарата множественной регрессии возникают при наличии мультиколлинеарности факторов, когда более чем два фактора связаны между собой линейной зависимостью. Наличие мультиколлинеарности факторов может означать, что некоторые факторы будут всегда действовать в унисон. В результате вариация в исходных данных перестает быть полностью независимой, и нельзя оценить воздействие каждого фактора в отдельности. Чем сильнее мультиколлинеарность факторов, тем менее надежна оценка распределения суммы объясненной вариации по отдельным факторам с помощью метода наименьших квадратов (МНК). Включение в модель мультиколлинеарныхфакторов нежелательно в силу следующих последствий:
1. затрудняется интерпретация параметров множественной регрессии как характеристик действия факторов в «чистом» виде, ибо факторы коррелированы; параметры линейной регрессии теряют экономический смысл;
2. оценки параметров ненадежны, обнаруживают большие стандартные ошибки и меняются с изменением объема наблюдений. Для оценки мультиколлинеарности факторов может использоваться определитель матрицы парных коэффициентов корреляции между факторами.
Если бы факторы не коррелировали между собой, то матрица парных коэффициентов корреляции между факторами была бы единичной матрицей. Для включающего три объясняющих переменных уравнения: y=a+b1x1+b2+b3x3+e.Матрица коэф-в корреляции м/у факторами имела бы определитель равный
Det 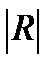 =1, т.к. rx1x1=rx2x2=1 и rx1x2=rx1x3=rx2x3=0.
=1, т.к. rx1x1=rx2x2=1 и rx1x2=rx1x3=rx2x3=0.
Если м/у факторами сущ-ет полная линейная зависимость и все коэф-ты корреляции =1, то определитель такой матрицы =0. Чем ближе к нулю определитель матрицы межфакторной корреляции, тем сильнее мультиколлинеарность факторов и ненадежнее результаты множественной регрессии. И, наоборот, чем ближе к единице определитель матрицы межфакторной корреляции, тем меньше мультиколлинеарность факторов.
40. Метод наименьших квадратов для двухфакторной производственной функции.
Метод наименьших квадратов.Некоторые более общие типы регрессионных моделей рассмотрены в разделе Основные типы нелинейных моделей. После выбора модели возникает вопрос: каким образом можно оценить эти модели? Если вы знакомы с методами линейной регрессии (описанными в разделе Множественная регрессия) или дисперсионного анализа (описанными в разделе Дисперсионный анализ), то вы знаете, что все эти методы используют оценивание по методу наименьших квадратов. Основной смысл этого метода заключается в минимизации суммы квадратов отклонений наблюдаемых значений зависимой переменной от значений, предсказанных моделью. (Термин наименьшие квадраты впервые был использован в работе Лежандра — Legendre, 1805.)
Функция потерь.В стандартной множественной регрессии оценивание коэффициентов регрессии происходит “подбором” коэффициентов, минимизирующих дисперсию остатков (сумму квадратов остатков). Любые отклонения наблюдаемых величин от предсказанных означают некоторые потери в точности предсказаний, например, из-за случайного шума (ошибок). Поэтому можно сказать, что цель метода наименьших квадратов заключается в минимизации функции потерь. В этом случае, функция потерь определяется как сумма квадратов отклонений от предсказанных значений (термин функция потерь был впервые использован в работе Вальда — Wald, 1939). Когда эта функция достигает минимума, вы получаете те же оценки для параметров (свободного члена, коэффициентов регрессии), как, если бы мы использовали Множественную регрессию. Полученные оценки называются оценками по методу наименьших квадратов.
Продолжая в том же духе, можно рассмотреть другие функции потерь. Например, при минимизации функции потерь, почему бы вместо суммы квадратов отклонений не рассмотреть сумму модулей отклонений? В самом деле, иногда это бывает полезно для уменьшения влияния выбросов. Влияние, оказываемое крупными остатками на всю сумму, существенно увеличивается при их возведении в квадрат. Однако если вместо суммы квадратов взять сумму модулей выбросов, влияние остатков на результирующую регрессионную кривую существенно уменьшится.
Существуют несколько методов, которые могут быть использованы для минимизации различных видов функций пот
41. Двухфакторная производственная функция Солоу
Производственная функция – это зависимость между набором факторов производства и максимально возможным объемом продукта, производимым с помощью данного набора факторов.
Производственная функция всегда конкретна, т.е. предназначается для данной технологии. Новая технология – новая производительная функция.
С помощью производственной функции определяется минимальное количество затрат, необходимых для производства данного объема продукта.
Производственные функции, независимо от того, какой вид производства ими выражается, обладают следующими общими свойствами:
1) Увеличение объема производства за счет роста затрат только по одному ресурсу имеет предел (нельзя нанимать много рабочих в одно помещение – не у всех будут места).
2) Факторы производства могут быть взаимодополняемы (рабочие и инструменты) и взаимозаменяемы (автоматизация производства).
В наиболее общем виде производственная функция выглядит следующим образом:
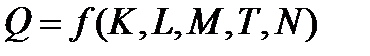 ,
,
где 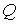 — объем выпуска;
— объем выпуска;
K- капитал (оборудование);
М- сырье, материалы;
Т – технология;
N – предпринимательские способности.
Наиболее простой является двухфакторная модель производственной функции Кобба – Дугласа, с помощью которой раскрывается взаимосвязь труда (L) и капитала (К). Эти факторы взаимозаменяемы и взаимодополняемы
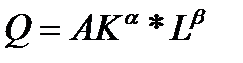 ,
,
где А – производственный коэффициент, показывающий пропорциональность всех функций и изменяется при изменении базовой технологии (через 30-40 лет);
K, L- капитал и труд;
α, β -коэффициенты эластичности объема производства по затратам капитала и труда.
Если 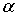 = 0,25, то рост затрат капитала на 1% увеличивает объем производства на 0,25%.
= 0,25, то рост затрат капитала на 1% увеличивает объем производства на 0,25%.
На основе анализа коэффициентов эластичности в производственной функции Кобба — Дугласа можно выделить:
1) пропорционально возрастающую производственную функцию, когда
α + β =1(Q=K 0,5 *L 0,2 ) .
2) непропорционально – возрастающую α + β > 1 (Q = K 0,9 *L 0,8 );
3) убывающую α + β 0,4 *L 0,2 ).
Рассмотрим короткий период деятельности фирмы, в котором из двух факторов переменным является труд. В такой ситуации фирма может увеличить производство за счет использования большего количества трудовых ресурсов. График производственной функции Кобба – Дугласа с одной переменной изображен на рис. 10.1 (кривая ТРн).
В краткосрочном периоде действует закон убывающей предельной производительности.
Закон убывающей предельной производительности действует в краткосрочном временном интервале, когда один производственный фактор остается неизменным. Действие закона предполагает неизменное состояние техники и технологии производства, если в производственном процессе будут применены новейшие изобретения и другие технические усовершенствования, то рост объема выпуска может быть достигнут при использовании тех же самых производственных факторов. То есть технический прогресс может изменить границы действия закона.
Если капитал является фиксированным фактором, а труд – переменным, то фирма может увеличить производство за счет использования большего количества трудовых ресурсов. Но по закону убывающей предельной производительности, последовательное увеличение переменного ресурса при неизменности других ведет к убывающей отдаче данного фактора, то есть к снижению предельного продукта или предельной производительности труда. Если же наем рабочих будет продолжаться, то в конечном итоге, они будут мешать друг другу (предельная производительность станет отрицательной) и объем выпуска сократится.
Предельная производительность труда (предельный продукт труда – MPL) – это прирост объема производства от каждой последующей единицы труда
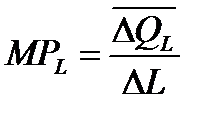 ,
,
т.е. прирост производительности к совокупному продукту (TPL)
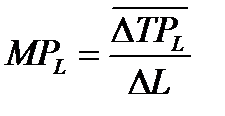 .
.
Аналогично определяется предельный продукт капитала MPK.
Основываясь на законе убывающей производительности, проанализируем взаимосвязь общего (TPL), среднего (АPL) и предельного продуктов (MPL) (рис. 10.1).
В движении кривой общего продукта (ТР) можно выделить три этапа. На этапе 1 она поднимается вверх ускоряющимися темпами, так как предельность продукта (MP) возрастает (каждый новый рабочий приносит больше продукции, чем предыдущий) и достигает максимума в точке А, то есть скорость роста функции максимальна. После точки А (этап 2) в силу действия закона убывающей отдачи, кривая MP падает, то есть каждый нанятый рабочий дает меньшее приращение общего продукта по сравнению с предшествующим, поэтому темп роста ТР после ТС замедляется. Но пока МР будет положительным, ТР будет все равно увеличиваться и достигнет максимума при МР=0.
На 3 этапе, когда количество рабочих становится избыточным по отношению к фиксированному капиталу (станки), МР приобретает отрицательное значение, поэтому ТР начинает снижаться.
Конфигурация кривой среднего продукта АР также обусловлена динамикой кривой МР. На 1 этапе обе кривые растут, пока приращение объема выпуска от вновь нанятых рабочих будет большим, чем средняя производительность (АРL) ранее нанятых рабочих. Но после точки А (max MP), когда четвертый рабочий добавляет к совокупному продукту (ТР) меньше чем третий, МР уменьшается, поэтому средняя выработка четырех рабочих также сокращается.
Производственные функции Солоу, представляют собой одно из ближайших обобщений многофакторных функций с постоянной и одинаковой эластичностью замены факторов.
42. Гомоскедастичность и гетероскедастичность остатков модели регрессии. Последствия гетероскедастичности
С определения гомоскедастичности и гетероскедастичности остатков модели регрессии строиться график зависимости остатков ei от теоретических значений результативного признака:
Если на графике получена горизонтальная полоса, то остатки ei представляют собой случайные величины и МНК оправдан, теоретические значения ух хорошо аппроксимируют фактические значения у.
Возможны варианты: если ei зависит от уx, то: 1.остатки ei не случайны.2. остатки ei, не имеют постоянной дисперсии. 3. Остатки ei носят систематический характер в данном случае отрицательные значения ei, соответствуют низким значениям ух, а положительные — высоким значениям. В этих случаях необходимо либо применять другую функцию, либо вводить дополнительную информацию.
Гомоскедастичность остатков означает, что дисперсия остатков ei одинакова для каждого значения х.Если это условие применения МНК не соблюдается, то имеет место гетероскедастичность. Наличие гетероскедастичности можно наглядно видеть из поля корреляции. а — дисперсия остатков растет по мере увеличения х; б — дисперсия остатков достигает максимальной величины при средних значениях переменной х и уменьшается при минимальных и максимальных значениях х; в — максимальная дисперсия остатков при малых значениях х и дисперсия остатков однородна по мере увеличения значений х. Графики гомо- и гетеро-ти.
Оценка отсутствия автокорреляции остатков(т.е. значения остатков ei распределены независимо друг от друга). Автокорреляция остатков означает наличие корреляции между остатками текущих и предыдущих (последующих) наблюдений. Коэффициент корреляции между ei и ej , где ei — остатки текущих наблюдений, ej — остатки предыдущих наблюдений, может быть определен по обычной формуле линейного коэффициента корреляции 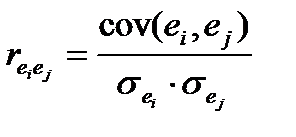 . (51.1)
. (51.1)
Если этот коэффициент окажется существенно отличным от нуля, то остатки автокоррелированы и функция плотности вероятности F(e) зависит j-й точки наблюдения и от распределения значений остатков в других точках наблюдения. Для регрессионных моделей по статической информации автокорреляция остатков может быть подсчитана, если наблюдения упорядочены по фактору х. Отсутствие автокорреляции остаточных величин обеспечивает состоятельность и эффективность оценок коэффициентов регрессии. Особенно актуально соблюдение данной предпосылки МНК при построении регрессионных моделей по рядам динамики, где ввиду наличия тенденции последующие уровни динамического ряда, как правило, зависят от своих предыдущих уровней.
При нарушении гомоскедастичности и наличии автокорреляции ошибок рекомендуется традиционный МНК заменять обобщенным методом. Обобщенный МНК применяется к преобразованным данным и позволяет получать оценки, которые обладают не только свойством несмещенности, но и имеют меньшие выборочные дисперсии. Обобщенный МНК для корректировки гетероскедастичности. В общем виде для уравнения yi=a+bxi+ei при 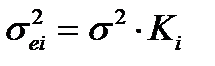 где Ki – коэффициент пропорциональности. Модель примет вид: yi=
где Ki – коэффициент пропорциональности. Модель примет вид: yi= 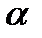 +
+ 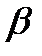 xi+
xi+ 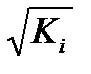 ei .
ei .
В ней остаточные величины гетероскедастичны. Предполагая в них отсутствие автокорреляции, можно перейти к уравнению с гомоскедастичными остатками, поделив все переменные, зафиксированные в ходе i-го наблюдения на 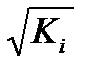 . Тогда дисперсия остатков будет величиной постоянной. От регрессии у по х перейдем к регрессии на новых переменных: y/
. Тогда дисперсия остатков будет величиной постоянной. От регрессии у по х перейдем к регрессии на новых переменных: y/ 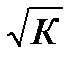 и х/ . Уравнение регрессии примет вид:
и х/ . Уравнение регрессии примет вид: 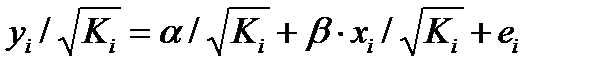 . (51.2)
. (51.2)
По отношению к обычной регрессии уравнение с новыми, преобразованными переменными представляет собой взвешенную регрессию, в которой переменные у и х взяты с весами 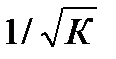 . Коэф-т регрессии b можно определить как
. Коэф-т регрессии b можно определить как 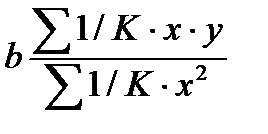 (51.3)
(51.3)
Как видим, при использовании обобщенного МНК с целью корректировки гетероскедастичности коэффициент регрессии b представляет собой взвешенную величину по отношению к обычному МНК с весами 1/К.Аналогичный подход возможен не только для уравнения парной, но и для множественной регрессии. Модель примет вид:
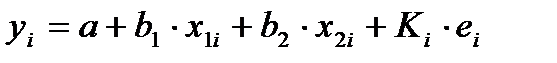 . (51.4)
. (51.4)
Модель с преобразованными переменными составит
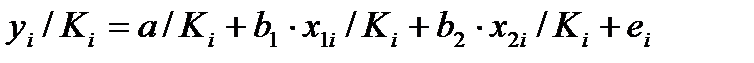 . (51.5)
. (51.5)
Это уравнение не содержит свободного члена, применяя обычный МНК получим:
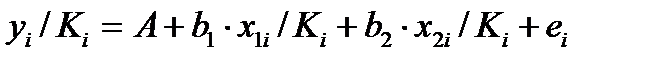 (51.5)
(51.5)
Применение в этом случае обобщенного МНК приводит к тому, что наблюдения с меньшими значениями преобразованных переменных х/К имеют при определении параметров регрессии относительно больший вес, чем с первоначальными переменными.
43. Тест Глейзера обнаружения гетероскедастичности остатков модели регрессии
Наличие гетероскедастичности в отдельных случаях может привести к смущенности оценок коэффициентов регрессии, хотя несмещенности оценок коэффициентов регрессии в основном зависит от соблюдения второй предпосылки МНК, т. е. независимости остатков и величин факторов. Гетероскедастичность будет сказываться на уменьшении эффективности оценок bi,. В частности, становится затруднительным использование формулы стандартной ошибки коэффициента регрессии mbi, предполагающую единую дисперсию остатков для любых значений фактора.
Тест Глейзера основывается на регрессии абсолютных значений остатков | ε | , т.е. рассматривается функция | εi| = a +bxi c + ui ,. Регрессия | εi| от xi cстроится при разных значениях параметра с, и далее отбирается та функция, для которой коэффициент регрессии b оказывается наиболее значимым, т.е. имеет место наибольшее значение (критерия Стьюдента или F-критерия Фишера и R 2 .
При обнаружении гетероскедастичности остатков регрессии ставится цель ее устранения, чему служит применение обобщенного метода наименьших квадратов
44. Тест Голдфелда-Квандта обнаружения гетероскедастичности остатков модели регрессии
При малом объеме выборки, для оценки гетероскедастичности используют метод Гольфреда — Квандта, разработанный в 1965 г. Гольдфельд и Квандт рассмотрели однофакторную линейную модель, для которой дисперсия остатков возрастает пропорционально Квадрату фактора. Для того чтобы оценить нарушение гомоскедастичности они предложили параметрический тест. Данный тест заключается в следующих стадиях:
1) Упорядочение n наблюдений по мере возрастания переменной х.
2) Исключение из рассмотрения С центральных наблюдений;
при этом (n — С)/ 2 > р, где р — число оцениваемых параметров.
3) Разделение совокупности из ( n — С) наблюдений на две группы (соответственно с малыми и большими значениями факторах) и определение по каждой из групп уравнений регрессии.
4) Определение остаточной суммы квадратов для первой (S1) и второй (S2) групп и нахождение их отношения R=S1/S2, где S1> S2.
При выполнении нулевой гипотезы о гомоскедастичности от ношение R будет удовлетворять F-критерию с (n — С- 2р) : 2 степенями свободы для каждой остаточной суммы квадратов. Чем сильнее R превышает табличное значение F -критерия тем более нарушена предпосылка о равенстве дисперсий остаточных величин.
45. Устранение гетероскедастичности остатков модели регрессии
Автокорреляция остатков может быть вызвана следующими причинами:
1) Ошибками измерения при первоначальном сборе данных по результативному признаку;
2) Неправильно выбранная формулировка исходной модель.
При формировании модели мог быть упущен из виду фактор, оказывающий существенное влияние на результат. В итоге влияние этого фактора отражается в остатках в виде автокорреляции остатков. Часто этим фактором является показатель времени. Кроме того, в качестве таких существенных факторов могут выступать лаговые значения переменных включенных в модель. Либо модель не учитывает несколько равнозначных факторов, которые оказывают совместное влияние при совпадении тенденций и циклов колебаний. От истинной автокорреляции остатков следует отличать ситуации, когда причина автокорреляции заключается в неправильной спецификации функциональной формы модели. В этом случае следует изменить форму связи факторных и результативного признаков, а не использовать специальные методы расчета параметров уравнения регрессии при наличии автокорреляции остатков.
46. Автокорреляция остатков модели регрессии. Последствия автокорреляции. Автокорреляционная функция
В соответствии с третьей предпосылкой МНК требуется, чтобы дисперсия остатков была гомоскедастичной. Это значит, что для каждого значения фактора хj остатки i имеют одинаковую дисперсию. Если это условие применения МНК не соблюдается, то имеет место гетероскедастичность.
Наличие гомоскедастичности или гетероскедастичности можно видеть и по рассмотренному выше графику зависимости остатков от теоретических значений результативного признака уx.
Для множественной регрессии данный вид графиков является наиболее приемлемым визуальным способом изучения гомо- и гетероскедастичности.
При построении регрессионных моделей чрезвычайно важно соблюдение четвертой предпосылки МНК – отсутствие автокорреляции остатков, т.е. значения i распределены независимо друг от друга.
Автокорреляция остатков означает наличие корреляции между остатками текущих и предыдущих (последующих) наблюдений.
Отсутствие автокорреляции остатков обеспечивает состоятельность и эффективность оценок коэффициентов регрессии.
Предпосылка о нормальном распределении остатков позволяет проводить проверку параметров регрессии и корреляции с помощью критериев t и F. Вместе с тем оценки регрессии, найденные с применением МНК, обладает хорошими свойствами даже при отсутствии нормального распределения остатков.
При несоблюдении основных предпосылок МНК приходится корректировать модель, изменяя ее спецификацию, добавлять (исключать) некоторые факторы и т.д.
При нарушении гомоскедастичности и наличии автокорреляции ошибок рекомендуется традиционный МНК заменять обобщенным МНК.
Обобщенный МНК применяется к преобразованным данным и позволяет получать оценки, которые обладают не только свойством несмещенности, но и имеют меньшие выборочные дисперсии
47. Критерий Дарбина-Уотсона обнаружения автокорреляции остатков модели регрессии
Существуют два наиболее распространенных метода определения автокорреляции остатков:
1) путем построения графика зависимости остатков от времени и визуальное определение наличия или отсутствия автокорреляции; 2) использование критерия Дарбина-Уотсона и расчет величины
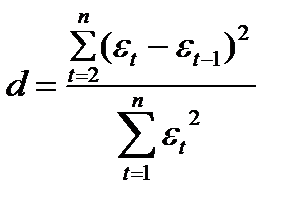 (56.1)
(56.1)
d – отношение суммы квадратов разностей последовательных занчений остатков к остаточной сумме квадратов по модели регрессии. Чащен всего критерий Дарбина –Уотсона указывается наряду с коэффициентом детерминации, значениями t- и F-критерия
Алгоритм выявления автокорреляции остатков на основе критерия Дарбина-Уотсона следующий. Выдвигается гипотеза Н0 об отсутствии автокорреляции остатков. Альтернативные гипотезы и состоят, соответственно, в наличии положительной или отрицательной автокорреляции в остатках. Далее по специальным таблицам определяются критические значения критерия Дарбина-Уотсона dL и dU для заданного числа наблюдений n, числа независимых переменных модели k и уровня значимости 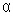 . По этим значениям числовой промежуток [0;4] разбивают на пять отрезков. Принятие или отклонение каждой из гипотез с вероятностью (1-) производится на основе данных, приведенных в таблице 5.1.
. По этим значениям числовой промежуток [0;4] разбивают на пять отрезков. Принятие или отклонение каждой из гипотез с вероятностью (1-) производится на основе данных, приведенных в таблице 5.1.
Таблица 47.1 Механизм проверки гипотезы о наличии автокорреляции остатков.
| Есть положительная автокорреляция остатков. Н0 отклоняется. С вероятностью Р=(1-) принимается гипотеза Н1 | Зона неопределенности | Нет оснований отклонять Н0 (автокорреляция остатков отсутствует) | Зона неопределенности | Есть отрицательная автокорреляция остатков. Н0 отклоняется. С вероятностью Р=(1- ) принимается гипотеза |
| 0 dL dU 2 4-dU 4-dL 4 |
Если фактическое значение критерия Дарбина-Уотсона попадает в зону неопределенности, то на практике предполагают существование автокорреляции остатков и отклоняют гипотезу Н0.
Есть несколько существенных ограничений на применение критерия Дарбина – Уотсона:
— он непременим к модели авторегрессии;
— данный критерий можно использовать только для выявления автокорреляции остатков 1-го порядка;
— критерий дает достоверные результаты только для больших выборок.
http://masters.donntu.org/2005/kita/tokarev/library/linreg.htm
http://helpiks.org/3-55677.html