Аппроксимация функции одной переменной
Калькулятор использует методы регрессии для аппроксимации функции одной переменной.
Данный калькулятор по введенным данным строит несколько моделей регрессии: линейную, квадратичную, кубическую, степенную, логарифмическую, гиперболическую, показательную, экспоненциальную. Результаты можно сравнить между собой по корреляции, средней ошибке аппроксимации и наглядно на графике. Теория и формулы регрессий под калькулятором.
Если не ввести значения x, калькулятор примет, что значение x меняется от 0 с шагом 1.

Аппроксимация функции одной переменной
Линейная регрессия
Коэффициент линейной парной корреляции:
Средняя ошибка аппроксимации:
Квадратичная регрессия
Система уравнений для нахождения коэффициентов a, b и c:
Коэффициент корреляции:
,
где
Средняя ошибка аппроксимации:
Кубическая регрессия
Система уравнений для нахождения коэффициентов a, b, c и d:
Коэффициент корреляции, коэффициент детерминации, средняя ошибка аппроксимации — используются те же формулы, что и для квадратичной регрессии.
Степенная регрессия
Коэффициент корреляции, коэффициент детерминации, средняя ошибка аппроксимации — используются те же формулы, что и для квадратичной регрессии.
Показательная регрессия
Коэффициент корреляции, коэффициент детерминации, средняя ошибка аппроксимации — используются те же формулы, что и для квадратичной регрессии.
Гиперболическая регрессия
Коэффициент корреляции, коэффициент детерминации, средняя ошибка аппроксимации — используются те же формулы, что и для квадратичной регрессии.
Логарифмическая регрессия
Коэффициент корреляции, коэффициент детерминации, средняя ошибка аппроксимации — используются те же формулы, что и для квадратичной регрессии.
Экспоненциальная регрессия
Коэффициент корреляции, коэффициент детерминации, средняя ошибка аппроксимации — используются те же формулы, что и для квадратичной регрессии.
Вывод формул
Сначала сформулируем задачу:
Пусть у нас есть неизвестная функция y=f(x), заданная табличными значениями (например, полученными в результате опытных измерений).
Нам необходимо найти функцию заданного вида (линейную, квадратичную и т. п.) y=F(x), которая в соответствующих точках принимает значения, как можно более близкие к табличным.
На практике вид функции чаще всего определяют путем сравнения расположения точек с графиками известных функций.
Полученная формула y=F(x), которую называют эмпирической формулой, или уравнением регрессии y на x, или приближающей (аппроксимирующей) функцией, позволяет находить значения f(x) для нетабличных значений x, сглаживая результаты измерений величины y.
Для того, чтобы получить параметры функции F, используется метод наименьших квадратов. В этом методе в качестве критерия близости приближающей функции к совокупности точек используется суммы квадратов разностей значений табличных значений y и теоретических, рассчитанных по уравнению регрессии.
Таким образом, нам требуется найти функцию F, такую, чтобы сумма квадратов S была наименьшей:
Рассмотрим решение этой задачи на примере получения линейной регрессии F=ax+b.
S является функцией двух переменных, a и b. Чтобы найти ее минимум, используем условие экстремума, а именно, равенства нулю частных производных.
Используя формулу производной сложной функции, получим следующую систему уравнений:
Для функции вида частные производные равны:
,
Подставив производные, получим:
Откуда, выразив a и b, можно получить формулы для коэффициентов линейной регрессии, приведенные выше.
Аналогичным образом выводятся формулы для остальных видов регрессий.
Интерполяция данных: соединяем точки так, чтобы было красиво
Как построить график по n точкам? Самое простое — отметить их маркерами на координатной сетке. Однако для наглядности их хочется соединить, чтобы получить легко читаемую линию. Соединять точки проще всего отрезками прямых. Но график-ломаная читается довольно тяжело: взгляд цепляется за углы, а не скользит вдоль линии. Да и выглядят изломы не очень красиво. Получается, что кроме ломаных нужно уметь строить и кривые. Однако тут нужно быть осторожным, чтобы не получилось вот такого: 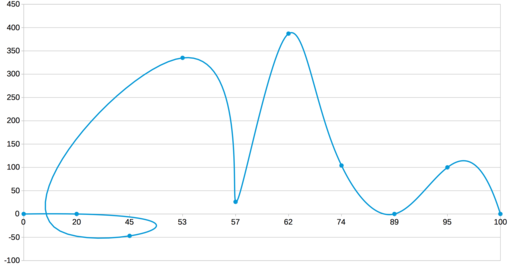
Немного матчасти
Восстановление промежуточных значений функции, которая в данном случае задана таблично в виде точек P1 .  Pn, называется интерполяцией. Есть множество способов интерполяции, но все они могут быть сведены к тому, что надо найти n – 1 функцию для расчёта промежуточных точек на соответствующих сегментах. При этом заданные точки обязательно должны быть вычислимы через соответствующие функции. На основе этого и может быть построен график: 
Функции fi могут быть самыми разными, но чаще всего используют полиномы некоторой степени. В этом случае итоговая интерполирующая функция (кусочно заданная на промежутках, ограниченных точками Pi) называется сплайном.
В разных инструментах для построения графиков — редакторах и библиотеках — задача «красивой интерполяции» решена по-разному. В конце статьи будет небольшой обзор существующих вариантов. Почему в конце? Чтобы после ряда приведённых выкладок и размышлений можно было поугадывать, кто из «серьёзных ребят» какие методы использует.
Ставим опыты
Самый простой пример — линейная интерполяция, в которой используются полиномы первой степени, а в итоге получается ломаная, соединяющая заданные точки.
Давайте добавим немного конкретики. Вот набор точек (взяты почти с потолка):
Результат линейной интерполяции этих точек выглядит так: 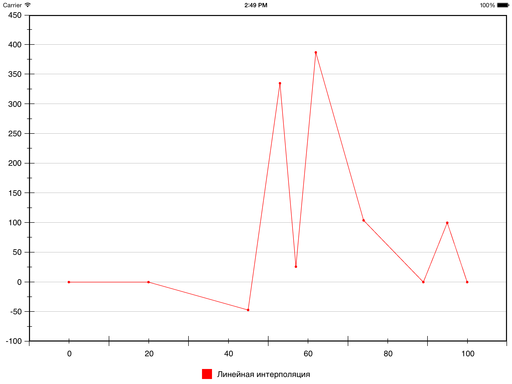
Однако, как отмечалось выше, иногда хочется получить в итоге гладкую кривую.
Что есть гладкость? Бытовой ответ: отсутствие острых углов. Математический: непрерывность производных. При этом в математике гладкость имеет порядок, равный номеру последней непрерывной производной, и область, на которой эта непрерывность сохраняется. То есть, если функция имеет гладкость порядка 1 на отрезке [a; b], это означает, что на [a; b] она имеет непрерывную первую производную, а вот вторая производная уже терпит разрыв в каких-то точках.
У сплайна в контексте гладкости есть понятие дефекта. Дефект сплайна — это разность между его степенью и его гладкостью. Степень сплайна — это максимальная степень использованных в нём полиномов.
Важно отметить, что «опасными» точками у сплайна (в которых может нарушиться гладкость) являются как раз Pi, то есть точки сочленения сегментов, в которых происходит переход от одного полинома к другому. Все остальные точки «безопасны», ведь у полинома на области его определения нет проблем с непрерывностью производных.
Чтобы добиться гладкой интерполяции, нужно повысить степень полиномов и подобрать их коэффициенты так, чтобы в граничных точках сохранялась непрерывность производных.
Традиционно для решения такой задачи используют полиномы третьей степени и добиваются непрерывности первой и второй производной. То, что получается, называют кубическим сплайном дефекта 1. Вот как он выглядит для наших данных: 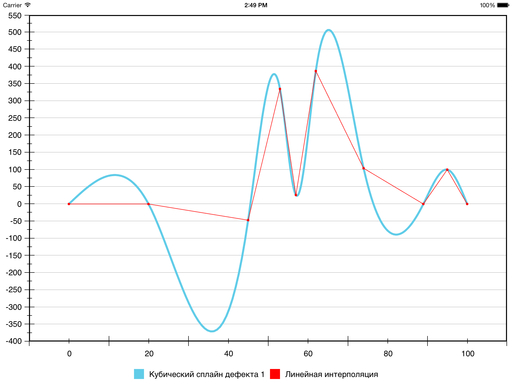
Кривая, действительно, гладкая. Но если предположить, что это график некоторого процесса или явления, который нужно показать заинтересованному лицу, то такой метод, скорее всего, не подходит. Проблема в ложных экстремумах. Появились они из-за слишком сильного искривления, которое было призвано обеспечить гладкость интерполяционной функции. Но зрителю такое поведение совсем не кстати, ведь он оказывается обманут относительно пиковых значений функции. А ради наглядной визуализации этих значений, собственно, всё и затевалось.
Так что надо искать другие решения.
Другое традиционное решение, кроме кубических сплайнов дефекта 1 — полиномы Лагранжа. Это полиномы степени n – 1, принимающие заданные значения в заданных точках. То есть членения на сегменты здесь не происходит, вся последовательность описывается одним полиномом.
Но вот что получается: 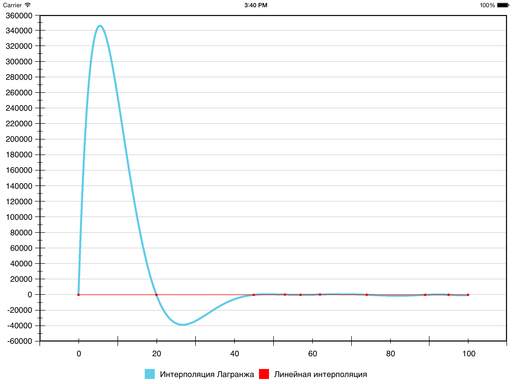
Гладкость, конечно, присутствует, но наглядность пострадала так сильно, что… пожалуй, стоит поискать другие методы. На некоторых наборах данных результат выходит нормальный, но в общем случае ошибка относительно линейной интерполяции (и, соответственно, ложные экстремумы) может получаться слишком большой — из-за того, что тут всего один полином на все сегменты.
В компьютерной графике очень широко применяются кривые Безье, представленные полиномами k-й степени.
Они не являются интерполирующими, так как из k + 1 точек, участвующих в построении, итоговая кривая проходит лишь через первую и последнюю. Остальные k – 1 точек играют роль своего рода «гравитационных центров», притягивающих к себе кривую.
Вот пример кубической кривой Безье: 
Как это можно использовать для интерполяции? На основе этих кривых тоже можно построить сплайн. То есть на каждом сегменте сплайна будет своя кривая Безье k-й степени (кстати, k = 1 даёт линейную интерполяцию). И вопрос только в том, какое k взять и как найти k – 1 промежуточную точку.
Здесь бесконечно много вариантов (поскольку k ничем не ограничено), однако мы рассмотрим классический: k = 3.
Чтобы итоговая кривая была гладкой, нужно добиться дефекта 1 для составляемого сплайна, то есть сохранения непрерывности первой и второй производных в точках сочленения сегментов (Pi), как это делается в классическом варианте кубического сплайна.
Решение этой задачи подробно (с исходным кодом) рассмотрено здесь.
Вот что получится на нашем тестовом наборе: 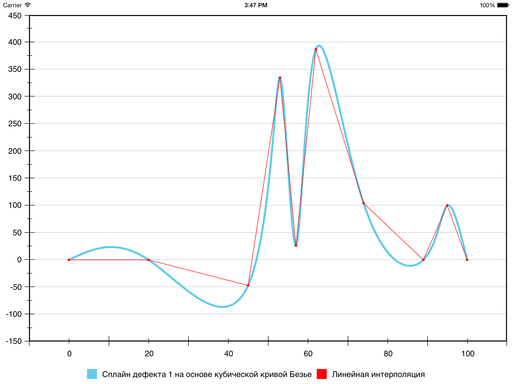
Стало лучше: ложные экстремумы всё ещё есть, но хотя бы не так сильно отличаются от реальных.
Думаем и экспериментируем
Можно попробовать ослабить условие гладкости: потребовать дефект 2, а не 1, то есть сохранить непрерывность одной только первой производной.
Достаточное условие достижения дефекта 2 в том, что промежуточные контрольные точки кубической кривой Безье, смежные с заданной точкой интерполируемой последовательности, лежат с этой точкой на одной прямой и на одинаковом расстоянии: 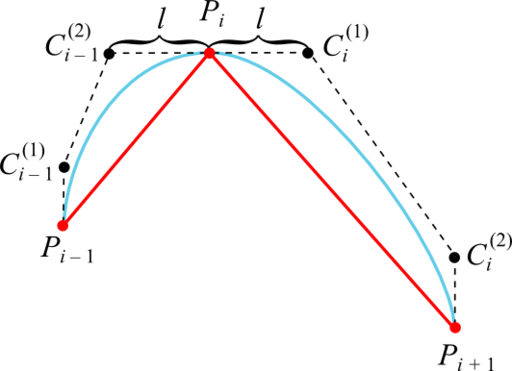
В качестве прямых, на которых лежат точки Ci – 1 (2) , Pi и Ci (1) , целесообразно взять касательные к графику интерполируемой функции в точках Pi. Это гарантирует отсутствие ложных экстремумов, так как кривая Безье оказывается ограниченной ломаной, построенной на её контрольных точках (если эта ломаная не имеет самопересечений).
Методом проб и ошибок эвристика для расчёта расстояния от точки интерполируемой последовательности до промежуточной контрольной получилась такой:
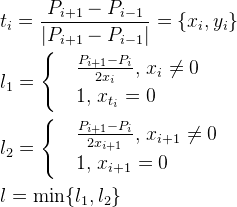
Первая и последняя промежуточные контрольные точки равны первой и последней точке графика соответственно (точки C1 (1) и Cn – 1 (2) совпадают с точками P1 и Pn соответственно).
В этом случае получается вот такая кривая: 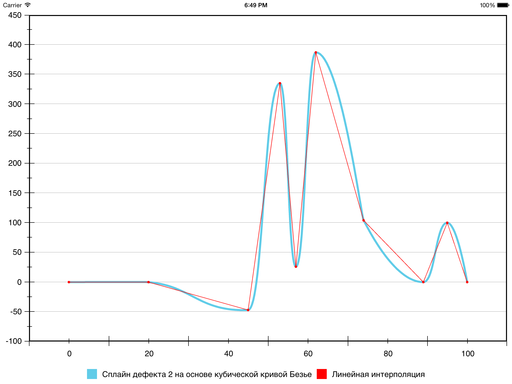
Как видно, ложных экстремумов уже нет. Однако если сравнивать с линейной интерполяцией, местами ошибка очень большая. Можно сделать её ещё меньше, но тут в ход пойдут ещё более хитрые эвристики.
К текущему варианту мы пришли, уменьшив гладкость на один порядок. Можно сделать это ещё раз: пусть сплайн будет иметь дефект 3. По факту, тем самым формально функция не будет гладкой вообще: даже первая производная может терпеть разрывы. Но если рвать её аккуратно, визуально ничего страшного не произойдёт.
Отказываемся от требования равенства расстояний от точки Pi до точек Ci – 1 (2) и Ci (1) , но при этом сохраняем их все лежащими на одной прямой: 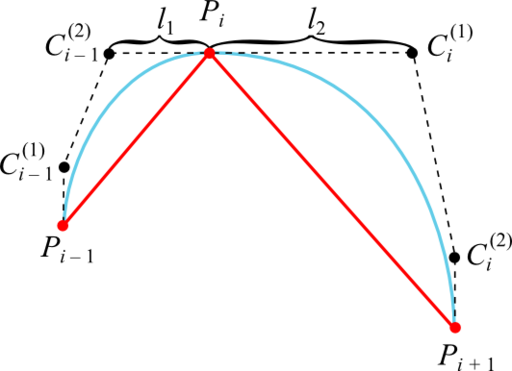
Эвристика для вычисления расстояний будет такой:
Результат получается такой: 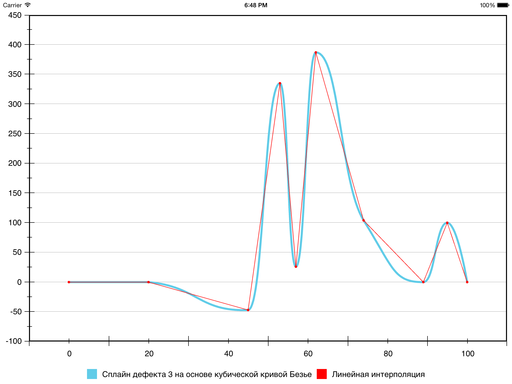
В результате на шестом сегменте ошибка уменьшилась, а на седьмом — увеличилась: кривизна у Безье на нём оказалась больше, чем хотелось бы. Исправить ситуацию можно, принудительно уменьшив кривизну и тем самым «прижав» Безье ближе к отрезку прямой, которая соединяет граничные точки сегмента. Для этого используется следующая эвристика:
Результат следующий: 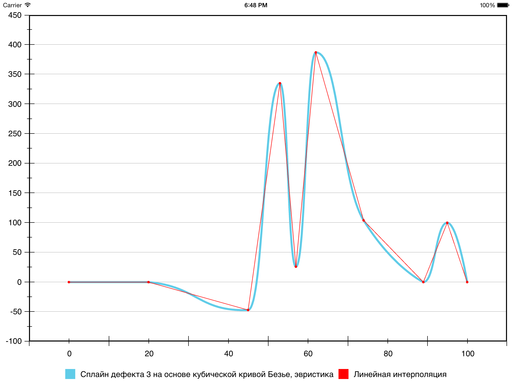
На этом было принято решение признать цель достигнутой.
Может быть, кому-то пригодится код.
А как люди-то делают?
Обещанный обзор. Конечно, перед решением задачи мы посмотрели, кто чем может похвастаться, а уже потом начали разбираться, как сделать самим и по возможности лучше. Но вот как только сделали, не без удовольствия ещё раз прошлись по доступным инструментам и сравнили их результаты с плодами наших экспериментов. Итак, поехали.
MS Excel
Это очень похоже на рассмотренный выше сплайн дефекта 1, основанный на кривых Безье. Правда, в отличие от него в чистом виде, тут всего два ложных экстремума — первый и второй сегменты (у нас было четыре). Видимо, к классическому поиску промежуточных контрольных точек тут добавляются ещё какие-то эвристики. Но ото всех ложных экстремумов они не спасли.
LibreOffice Calc
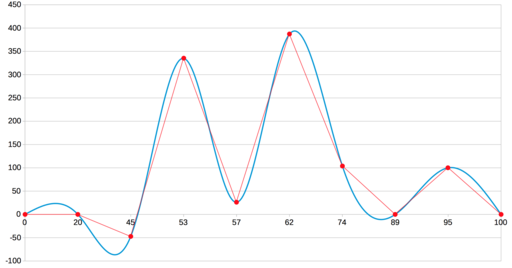
В настройках это названо кубическим сплайном. Очевидно, он тоже основан на Безье, и вот тут уже точная копия нашего результата: все четыре ложных экстремума на месте.
Есть там ещё один тип интерполяции, который мы тут не рассматривали: B-сплайн. Но для нашей задачи он явно не подходит, так как даёт вот такой результат 🙂 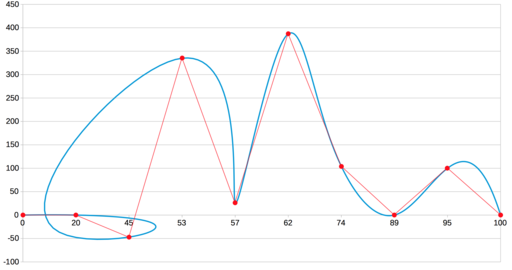
Highcharts, одна из самых популярных JS-библиотек для построения диаграмм
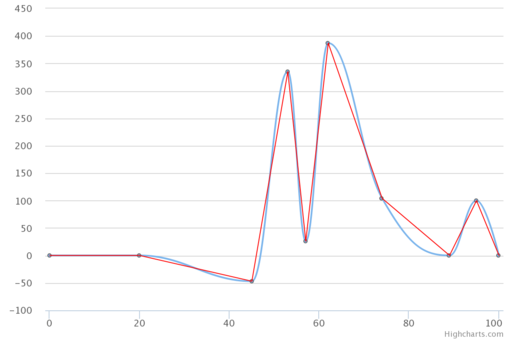
Тут налицо «метод касательных» в варианте равенства расстояний от точки интерполируемой последовательности до промежуточных контрольных. Ложных экстремумов нет, зато есть сравнительно большая ошибка относительно линейной интерполяции (седьмой сегмент).
amCharts, ещё одна популярная JS-библиотека
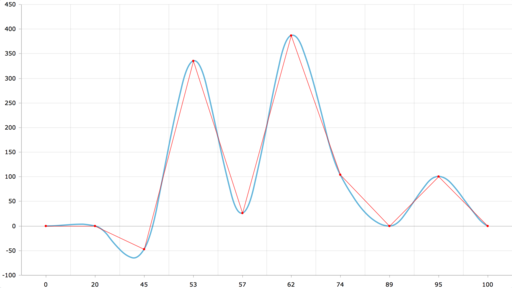
Картина очень похожа на экселевскую, те же два ложных экстремума в тех же местах.
Coreplot, самая популярная библиотека построения графиков для iOS и OS X
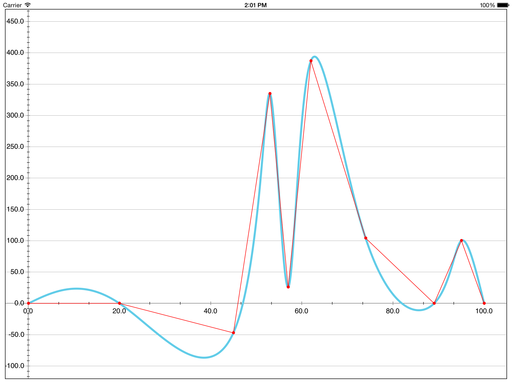
Есть ложные экстремумы и видно, что используется сплайн дефекта 1 на основе Безье.
Библиотека открытая, так что можно посмотреть в код и убедиться в этом.
aChartEngine, вроде как самая популярная библиотека построения графиков для Android
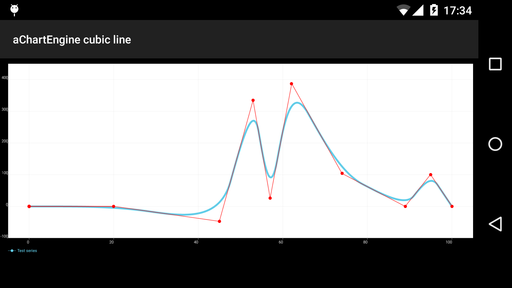
Больше всего похоже на кривую Безье степени n – 1, хотя в самой библиотеке график называется «cubic line». Странно! Как бы то ни было, тут не только присутствуют ложные экстремумы, но и в принципе не выполняются условия интерполяции.
Что такое экспонента в математике для чайников
Экспонента (экспоненциальная функция) — это математическая функция вида y = e×, или у = exp(x), или у = Exp(x) (где основанием степени является число е).
е — это число Эйлера, у него бесконечное количество цифр после запятой, оно трансцендентное и иррациональное. Оно равно округлённо 2,72 (а полностью — 2,718281828459045. ).
Трансцендентным число называется, если оно не удовлетворяет ни одному алгебраическому уравнению. Иррациональным — если его нельзя представить в виде дроби m/n, где n не равно 0.
Несмотря на свою бесконечность, число е является константой. То есть значением, которое никогда не изменяется.
Показательная функция — это математическая функция вида y = a×.
График экспоненты выглядит следующим образом:

Для чего используется экспонента?
Экспонента применяется и в физике, и в технике, и в экономике, особенно при решении задач, связанных с процентами.
Экспоненциальный рост
Мы используем термин экспоненциальный рост, чтобы сказать о стремительном росте чего-либо. Словосочетание чаще всего употребляется по отношению к росту популяции людей или животных/птиц.
Что такое второй замечательный предел
Швейцарский математик Якоб Бернулли (1655–1705 гг.) вывел число е, когда пытался решить финансовый вопрос. В частности, он пытался понять, как должны начисляться проценты на сумму вклада в банке, чтобы это было наиболее прибыльно для владельца денег.
Он также пытался понять, есть ли лимит у дохода, получаемого в процентах, или он будет увеличиваться бесконечно.
Решая эту задачу, он использовал предел последовательности, а именно второй замечательный предел. Формулу для вычисления числа е можно записать следующим образом (где n — это число, стремящееся к бесконечности):
То есть числу е равняется предел, где n стремится к бесконечности, от 1, плюс 1, разделённый на n, и всё возвести в степень n.
Если подставить в данную формулу вместо n какую-нибудь очень большую цифру, можно получить очень хорошее приближение к е.
Например, подставим 1.000.000 и посчитаем на калькуляторе:
(1 + 1/1000000) ^ 1000000 = 2.7182804691
Как видите, с n = 1.000.000 мы получили достаточно хорошее приближение, с правильными 5 знаками после запятой.
Как определить число е?
Помимо второго замечательного предела, существуют и другие способы для определения числа е:
- через сумму ряда;
- через формулу Муавра — Стирлинга;
- другие.
Сумма ряда
Существует мнение, что этот метод использовал сам Эйлер, когда высчитывал е.

Можно получить приближение е, рассчитав первые 7 частей этой суммы:

И эти вычисления дали нам следующий результат:

Этот метод дал нам точных 4 знака после запятой, и его достаточно легко запомнить.
Формула Муавра — Стирлинга
Также называется просто формула Стирлинга:

И в этом случае чем больше n, тем точнее будет результат.
Как запомнить число е
Можно легко запомнить 9 знаков после запятой, если заметить удивительную закономерность: после «2,7» число «1828» появляется дважды (2,7 1828 1828). В 1828 году родились Лев Толстой и Жюль Верн, а Франц Шуберт умер.
Хотите дальше? Можно и дальше! 15 знаков после запятой! Последующие цифры — это градусы углов в равнобедренном прямоугольном треугольнике ( 45°, 90°, 45°): 2,7 1828 1828 45 90 45.
Интересные факты
Экспоненциальную функцию также называют экспонента.
Показательная функция — это функция вида y=a×, где a — заданное число (основание), x — это переменная.
А если основание = е, с переменной x, то математически логарифм записывается как ln, а не как log. И его называют натуральный логарифм (логарифм с основанием е):

Логарифмическая функция, что обратная к показательной функции y = a×, a > 0, a≠1, пишется как  .
.
Производная и первообразная экспоненциальной функции равны ей самой, т. е. (e×)’ = e×, но (a×)’ = (a×)*ln(a).
Якобу Бернулли в расчётах помогал его брат Иоганн. Один из кратеров на Луне носит их имя.
Число Непера и число Эйлера
Число Непера или Неперово число, число Эйлера — это названия для одного и того же числа е.
Шотландский математик Джон Непер придумал логарифмы. Так как число е является основанием натурального логарифма (ln x), то этому числу присвоили имя математика из Шотландии. Хотя Непер и не вычислял его.
Сам символ e был придуман в 1731 году швейцарским математиком Леонардом Эйлером. Эйлер занимался вычислениями алгоритмов и вывел его основание. А точнее основание натурального логарифма, которым и является число е.
Изобретение логарифмов в XVII веке (1614 год) шотландским математиком Джоном Непером стало одним из важнейших событий в истории математики.
Узнайте также, что такое Число Пи и Логарифм.
Константу впервые вычислил швейцарский математик Якоб Бернулли в ходе решения задачи о предельной величине процентного дохода. Он обнаружил, что если исходная сумма $1 и начисляется 100% годовых один раз в конце года, то итоговая сумма будет $2. Но если те же самые проценты начислять два раза в год, то $1 умножается на 1,5 дважды, получая $2,25 (т. е. 1$*50%=1,5$, затем 1,5$*50%=2,25$). Начисления процентов раз в квартал (4 раза в год, т. е. каждый квартал к новой полученной сумме прибавляем 25%) получаем $2,44140625, и так далее. Бернулли показал, что если частоту начисления процентов бесконечно увеличивать, то процентный доход в случае сложного процента будет равен числу 2,718.
Число e всегда волновало меня — не как буква, а как математическая константа. Что число е означает на самом деле?
Разные математические книги и даже моя горячо любимая Википедия описывает эту величественную константу совершенно бестолковым научным жаргоном:
Математическая константа е является основанием натурального логарифма.
Если заинтересуетесь, что такое натуральный логарифм, найдете такое определение:
Натуральный логарифм, ранее известный как гиперболический логарифм, является логарифмом с основанием е, где е – иррациональная константа, приблизительно равная 2.718281828459.
Определения, конечно, правильные. Но понять их крайне сложно. Конечно, Википедия в этом не виновата: обычно математические пояснения сухи и формальны, составляются по всей строгости науки. Из-за этого новичкам сложно осваивать предмет (а когда-то каждый был новичком).
С меня хватит! Сегодня я делюсь своими высокоинтеллектуальными соображениями о том, что такое число е, и чем оно так круто! Отложите свои толстые, наводящие страх математические книжки в сторону!
Число е – это не просто число
Описывать е как «константу, приблизительно равную 2,71828…» — это все равно, что называть число пи «иррациональным числом, приблизительно равным 3,1415…». Несомненно, так и есть, но суть по-прежнему ускользает от нас.
Число пи — это соотношение длины окружности к диаметру, одинаковое для всех окружностей. Это фундаментальная пропорция, свойственная всем окружностям, а следовательно, она участвует в вычислении длины окружности, площади, объема и площади поверхности для кругов, сфер, цилиндров и т.д. Пи показывает, что все окружности связаны, не говоря уже о тригонометрических функциях, выводимых из окружностей (синус, косинус, тангенс).
Число е является базовым соотношением роста для всех непрерывно растущих процессов. Число е позволяет взять простой темп прироста (где разница видна только в конце года) и вычислить составляющие этого показателя, нормальный рост, при котором с каждой наносекундой (или даже быстрее) всё вырастает еще на немного.
Число е участвует как в системах с экспоненциальным, так и постоянным ростом: население, радиоактивный распад, подсчет процентов, и много-много других. Даже ступенчатые системы, которые не растут равномерно, можно аппроксимировать с помощью числа е.
Также, как любое число можно рассматривать в виде «масштабированной» версии 1 (базовой единицы), любую окружность можно рассматривать в виде «масштабированной» версии единичной окружности (с радиусом 1). И любой коэффициент роста может быть рассмотрен в виде «масштабированной» версии е («единичного» коэффициента роста).
Так что число е – это не случайное, взятое наугад число. Число е воплощает в себе идею, что все непрерывно растущие системы являются масштабированными версиями одного и того же показателя.
Понятие экспоненциального роста
Давайте начнем с рассмотрения базовой системы, которая удваивается за определенный период времени. Например:
- Бактерии делятся и «удваиваются» в количестве каждые 24 часа
- Мы получаем вдвое больше лапшинок, если разламываем их пополам
- Ваши деньги каждый год увеличиваются вдвое, если вы получаете 100% прибыли (везунчик!)
И выглядит это примерно так:

Деление на два или удваивание – это очень простая прогрессия. Конечно, мы можем утроить или учетверить, но удваивание более удобно для пояснения.
Математически, если у нас есть х разделений, мы получаем в 2^x раз больше добра, чем было вначале. Если сделано только 1 разбиение, получаем в 2^1 раза больше. Если разбиений 4, у нас получится 2^4=16 частей. Общая формула выглядит так:
Другими словами, удвоение – это 100% рост. Мы можем переписать эту формулу так:
Это то же равенство, мы только разделили «2» на составные части, которыми в сущности и является это число: начальное значение (1) плюс 100%. Умно, да?
Конечно, мы можем подставить и любое другое число (50%, 25%, 200%) вместо 100% и получить формулу роста для этого нового коэффициента. Общая формула для х периодов временного ряда будет иметь вид:
Это просто означает, что мы используем норму возврата, (1 + прирост), «х» раз подряд.
Приглядимся поближе
Наша формула предполагает, что прирост происходит дискретными шагами. Наши бактерии ждут, ждут, а потом бац!, и в последнюю минуту они удваиваются в количестве. Наша прибыль по процентам от депозита магическим образом появляется ровно через 1 год. На основе формулы, написанной выше, прибыль растет ступенчато. Зеленые точки появляются внезапно.
Но мир не всегда таков. Если мы увеличим картинку, мы увидим, что наши друзья-бактерии делятся постоянно:

Зеленый малый не возникает из ничего: он медленно вырастает из синего родителя. После 1 периода времени (24 часа в нашем случае), зеленый друг уже полностью созрел. Повзрослев, он стает полноценным синим членом стада и может создавать новые зеленые клеточки сам.
Эта информация как-то изменит наше уравнение?
Не-а. В случае с бактериями, полусформированные зеленые клетки все же не могут ничего делать, пока не вырастут и совсем не отделятся от своих синих родителей. Так что уравнение справедливо.
http://habr.com/ru/post/264191/
http://4apple.org/chto-takoe-jeksponenta-v-matematike-dlja-chajnikov/