Уравнение нелинейной регрессии
Вместе с этим калькулятором также используют следующие:
Уравнение множественной регрессии
Виды нелинейной регрессии
| Вид | Класс нелинейных моделей |
| Нелинейные относительно включенных в анализ объясняющих переменных, но линейные по оцениваемым параметрам |
| Нелинейные по оцениваемым параметрам |
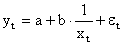
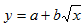
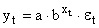
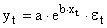

Здесь ε — случайная ошибка (отклонение, возмущение), отражающая влияние всех неучтенных факторов.
Уравнению регрессии первого порядка — это уравнение парной линейной регрессии.
Уравнение регрессии второго порядка это полиномальное уравнение регрессии второго порядка: y = a + bx + cx 2 .
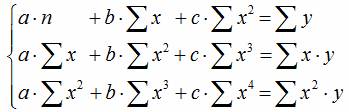
Уравнение регрессии третьего порядка соответственно полиномальное уравнение регрессии третьего порядка: y = a + bx + cx 2 + dx 3 .
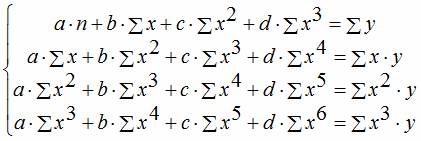
Чтобы привести нелинейные зависимости к линейной используют методы линеаризации (см. метод выравнивания):
- Замена переменных.
- Логарифмирование обеих частей уравнения.
- Комбинированный.
| y = f(x) | Преобразование | Метод линеаризации |
| y = b x a | Y = ln(y); X = ln(x) | Логарифмирование |
| y = b e ax | Y = ln(y); X = x | Комбинированный |
| y = 1/(ax+b) | Y = 1/y; X = x | Замена переменных |
| y = x/(ax+b) | Y = x/y; X = x | Замена переменных. Пример |
| y = aln(x)+b | Y = y; X = ln(x) | Комбинированный |
| y = a + bx + cx 2 | x1 = x; x2 = x 2 | Замена переменных |
| y = a + bx + cx 2 + dx 3 | x1 = x; x2 = x 2 ; x3 = x 3 | Замена переменных |
| y = a + b/x | x1 = 1/x | Замена переменных |
| y = a + sqrt(x)b | x1 = sqrt(x) | Замена переменных |
Пример . По данным, взятым из соответствующей таблицы, выполнить следующие действия:
- Построить поле корреляции и сформулировать гипотезу о форме связи.
- Рассчитать параметры уравнений линейной, степенной, экспоненциальной, полулогарифмической, обратной, гиперболической парной регрессии.
- Оценить тесноту связи с помощью показателей корреляции и детерминации.
- Дать с помощью среднего (общего) коэффициента эластичности сравнительную оценку силы связи фактора с результатом.
- Оценить с помощью средней ошибки аппроксимации качество уравнений.
- Оценить с помощью F-критерия Фишера статистическую надежность результатов регрессионного моделирования. По значениям характеристик, рассчитанных в пп. 4, 5 и данном пункте, выбрать лучшее уравнение регрессии и дать его обоснование.
- Рассчитать прогнозное значение результата, если прогнозное значение фактора увеличится на 15% от его среднего уровня. Определить доверительный интервал прогноза для уровня значимости α=0,05 .
- Оценить полученные результаты, выводы оформить в аналитической записке.
| Год | Фактическое конечное потребление домашних хозяйств (в текущих ценах), млрд. руб. (1995 г. — трлн. руб.), y | Среднедушевые денежные доходы населения (в месяц), руб. (1995 г. — тыс. руб.), х |
| 1995 | 872 | 515,9 |
| 2000 | 3813 | 2281,1 |
| 2001 | 5014 | 3062 |
| 2002 | 6400 | 3947,2 |
| 2003 | 7708 | 5170,4 |
| 2004 | 9848 | 6410,3 |
| 2005 | 12455 | 8111,9 |
| 2006 | 15284 | 10196 |
| 2007 | 18928 | 12602,7 |
| 2008 | 23695 | 14940,6 |
| 2009 | 25151 | 16856,9 |
Решение. В калькуляторе последовательно выбираем виды нелинейной регрессии. Получим таблицу следующего вида.
Экспоненциальное уравнение регрессии имеет вид y = a e bx
После линеаризации получим: ln(y) = ln(a) + bx
Получаем эмпирические коэффициенты регрессии: b = 0.000162, a = 7.8132
Уравнение регрессии: y = e 7.81321500 e 0.000162x = 2473.06858e 0.000162x
Степенное уравнение регрессии имеет вид y = a x b
После линеаризации получим: ln(y) = ln(a) + b ln(x)
Эмпирические коэффициенты регрессии: b = 0.9626, a = 0.7714
Уравнение регрессии: y = e 0.77143204 x 0.9626 = 2.16286x 0.9626
Гиперболическое уравнение регрессии имеет вид y = b/x + a + ε
После линеаризации получим: y=bx + a
Эмпирические коэффициенты регрессии: b = 21089190.1984, a = 4585.5706
Эмпирическое уравнение регрессии: y = 21089190.1984 / x + 4585.5706
Логарифмическое уравнение регрессии имеет вид y = b ln(x) + a + ε
Эмпирические коэффициенты регрессии: b = 7142.4505, a = -49694.9535
Уравнение регрессии: y = 7142.4505 ln(x) — 49694.9535
Равносторонняя гипербола.
Среди класса нелинейных функций, параметры которой без особых затруднений оцениваются МНК, следует назвать хорошо известную в эконометрике равностороннюю гиперболу. Для нее, заменив 1/х на z, получим линейное уравнение регрессии
Гипербола может быть использована не только для характеристики удельных затрат с объемами производства, как уже указывалось ранее. Примером ее использования может служить также взаимосвязь доли расходов на определенные группы товаров (продовольственные, непродовольственные, товары длительного пользования) с общей суммой доходов. Подобного рода взаимосвязи получили название кривых Энгеля. В 1857 году немецкий статистик Энгель сформулировал закономерность – с ростом дохода доля затрат на продовольствие уменьшается. Соответственно, возрастает доля расходов на непродовольственные товары.
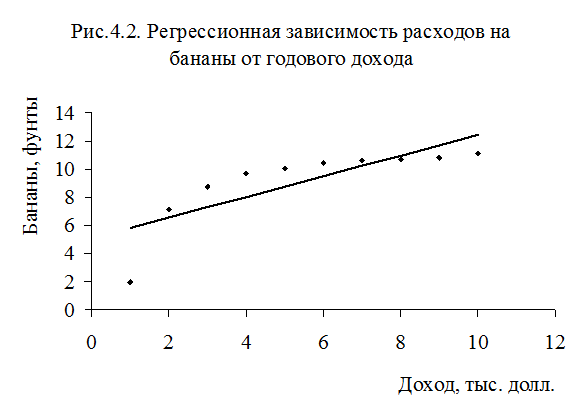
Допустим, вы исследуете соотношение между ежегодным потреблением бананов и годовым доходом, и наблюдения приведены в табл.4. 1, где собраны наблюдения для 10 семей (слайд).
| Семья | Бананы (в фунтах) (у) | Доход (в 1000 долл.) (х) | ( z ) |
| 1,93 | 1,000 | ||
| 7,13 | 0,500 | ||
| 8,78 | 0,333 | ||
| 9,69 | 0,250 | ||
| 10,09 | 0,200 | ||
| 10,42 | 0,167 | ||
| 10,62 | 0,143 | ||
| 10,71 | 0,125 | ||
| 10,79 | 0,111 | ||
| 11,13 | 0,100 |
На слайде (рис.4.2). представлено облако точек, соответствующих наблюдениям, а также график уравнения регрессии между у и х 
 = 5,09 + 0,73 х ; R 2 = 0,64. (4.7.)
= 5,09 + 0,73 х ; R 2 = 0,64. (4.7.)
Стандартные ошибки (1,23) (0,20)
Из рисунка видно, что график уравнения регрессии не вполне соответствует точкам наблюдений, несмотря на то, что коэффициент при х существенно отличается от нуля при однопроцентном уровне значимости. Очевидно, что точки наблюдений лежат на кривой, тогда как уравнение регрессии характеризуется прямой. В данном случае нетрудно заметить, что функциональная зависимость между у и х определена неправильно.
В том случае, если вы не можете представить зависимость в графическом виде ( например, если вы используете множественный регрессионный анализ), понять, что где то допущена ошибка, можно с помощью анализа остатков. В данном случае значения остатков приведены в таблице 4.2.
| Семья | у | е | |
| 1 | 2 | 3 | 4 |
| 1,93 | 5,82 | — 3,90 | |
| 7,13 | 6,56 | 0,57 | |
| 8,78 | 7,29 | 1,49 | |
| 9,69 | 8,03 | 1,67 | |
| 10,09 | 8,76 | 1,33 |
Продолжение табл. 4.2.
| 1 | 2 | 3 | 4 |
| 10,42 | 9,50 | 0,93 | |
| 10,62 | 10,23 | 0,39 | |
| 10,71 | 10,97 | — 0,26 | |
| 10,79 | 11,70 | — 0,91 | |
| 11,13 | 12,43 | — 1,31 |
Положительные или отрицательные, большие или малые остатки должны чередоваться случайным образом. Здесь же, как видно из таблицы, сначала остатки отрицательны, затем они становятся положительными, достигают максимума, а потом снова уменьшаются и становятся отрицательными: это представляется сомнительным.
В данном примере соотношение имеет вид:
у = 12 — 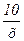 (4.8.)
(4.8.)
где х принимает целые значения от 1 до 10. Если мы знаем это и определим z = 1/ х, то уравнение примет линейный вид (4.7.) . Значение z для каждой семьи уже подсчитано в таблице 4.1. Оценив регрессию между y и z , получим
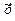 = 12, 08 — 10, 08 z ; R 2 = 0, 9989
= 12, 08 — 10, 08 z ; R 2 = 0, 9989
Стандартные ошибки (0, 04) (0,12 ) (4.9.) Подставив z = 1 / x , имеем
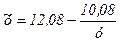 (4.10.)
(4.10.)
С учетом высокого качества оцененного уравнения (4.9.) неудивительно, что соотношение (4.10) близко к истинному уравнению (4.8 ) На слайде (рис. 4.3 и рис. 4.4) показаны регрессионная зависимость и точки наблюдений для у, х и z.
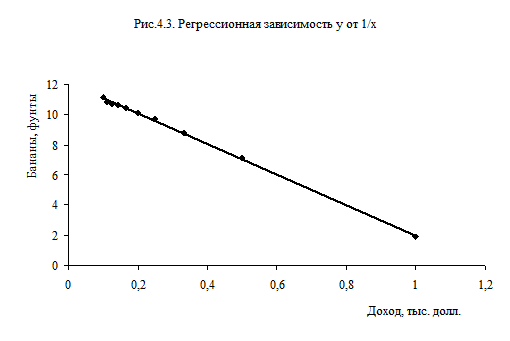 |
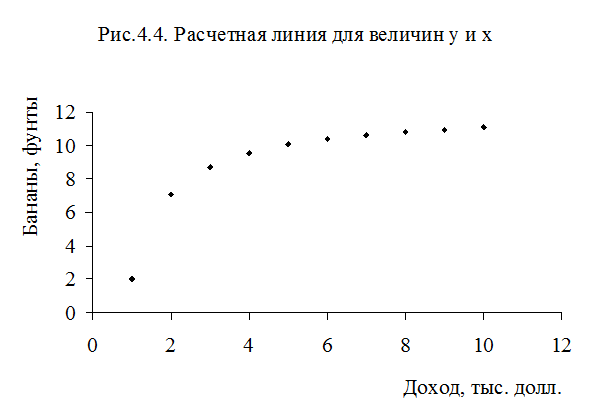
Улучшение качества уравнения, измеряемого с помощью коэффициента R 2 , отражено в более полном соответствии графиков. Сравните графики на рис.4.2. и 4.4.
Степенная функция.
Рассмотрим далее функции вида
которые являются нелинейными как по параметрам, так и по переменным. Данное соотношение может быть преобразовано в линейное уравнение путем использования логарифмов, знакомых вам из курса математики. Ниже приведем основные свойства логарифмов, которые помогут вам в преобразованиях нелинейных уравнений.
Основные правила гласят :
1. Если у = х z , то log y = log x + log z .
2. Если y = x / z , то log y = log x — log z.
3. Если y = x n , то log y = n log x.
Эти правила могут применяться вместе для преобразования более сложных выражений. Например, если у = a х b , то по правилу 1 :
log y = log a + log x b и по правилу 3
Если обозначить у 1 = log (y) , z = log x и a 1 = log a , то уравнение (4.11) можно переписать в следующем виде:
у 1 = a 1 + b z (4.12)
Процедура оценивания регрессии теперь будет следующей. Сначала вычислим у 1 и z для каждого наблюдения путем взятия логарифмов от исходных значений. Вы можете сделать это на компьютере с помощью имеющейся статистической программы. Затем оценим регрессионную зависимость у 1 от z. Коэффициент при z будет представлять собой непосредственную оценку b. Постоянный член является оценкой a 1 , то есть log a. Для получения оценки a необходимо взять антилогарифм, то есть выполнить обратное действие.
Дата добавления: 2015-11-06 ; просмотров: 1598 ; ЗАКАЗАТЬ НАПИСАНИЕ РАБОТЫ
Равносторонняя гипербола.
Линейная модель.
Уравнение однофакторной (парной) линейной регрессии имеет вид:
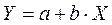
Для нашего примера:
Y – Валовый доход растениеводства, приходящийся на 100 га пашни, тыс. руб. (результативный признак);
Х – Доля трактористов – машинистов в общей численности работников, занятых в сельскохозяйственном производстве, % (факторный признак).
Для нахождения параметров a и b линейной регрессии можно решить систему нормальных уравнений относительно a и b.
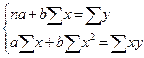

Для расчета параметров уравнения регрессии можно также воспользоваться готовыми формулами, полученными путем преобразования уравнений системы:
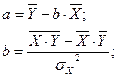
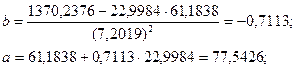
Уравнение принимает вид: 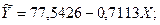
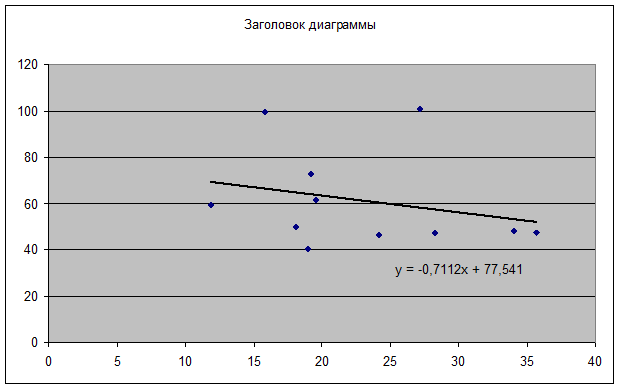
Рис. 2. Влияние доли трактористов – машинистов в общей численности работников, занятых в сельскохозяйственном производстве, на валовый доход растениеводства, приходящийся на 100 га пашни.
Коэффициент -0,7113 стоящий перед Х, называется коэффициентом регрессии. По знаку этого коэффициента судят о направлении связи. Если знак «+» – связь прямая; «-» – связь обратная. Величина коэффициента регрессии показывает, на сколько в среднем изменится величина результативного признака Y при изменении факторного признака Х на единицу. В данном случае с увеличением доли трактористов – машинистов в общей численности работников, занятых в сельскохозяйственном производстве, на 1 % валовый доход растениеводства, приходящийся на 100 га пашни, уменьшается в среднем на 0,7113 тыс. руб.
Коэффициент регрессии применяется для расчета среднего коэффициента эластичности, который показывает: на сколько процентов в среднем по совокупности изменится результат Y от своей средней величины при изменении фактора X на 1% от своего среднего значения.
Коэффициент эластичности рассчитывается по формуле:
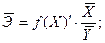
В нашем случае 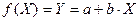
И формула коэффициента эластичности парной линейной регрессии принимает вид:
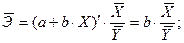
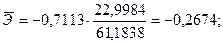
С увеличением доли трактористов – машинистов в общей численности работников, занятых в сельскохозяйственном производстве, на 1 % валовый доход растениеводства, приходящийся на 100 га пашни, уменьшается в среднем на 0,26749%.
При линейной корреляции между Х и Y исчисляют парный линейный коэффициент корреляции r. Он принимает значения в интервале –1 £ r £ 1. Знак коэффициента корреляции показывает направление связи: «+» – связь прямая, «–» – связь обратная. Абсолютная величина характеризует степень тесноты связи.
Коэффициент парной линейной корреляции рассчитаем по формуле:
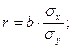
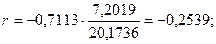
Линейный коэффициент парной корреляции показывает, что связь между долей трактористов – машинистов в общей численности работников, занятых в сельскохозяйственном производстве, и валовым доходом растениеводства, приходящийся на 100 га пашни, обратная и слабая.
Изменение результативного признака Y обусловлено вариацией факторного признака X. Долю дисперсии, объясняемую регрессией, в общей дисперсии результативного признака характеризует коэффициент детерминации D.
Коэффициент детерминации рассчитывается по формуле:
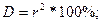
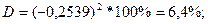
Следовательно, вариация валового дохода растениеводства, приходящийся на 100 га пашни, на 6,4% объясняется вариацией доли трактористов – машинистов в общей численности работников, занятых в сельскохозяйственном производстве, а остальные 93,6% вариации валового дохода растениеводства, приходящийся на 100 га пашни, обусловлены изменением других, не учтенных в модели факторов.
Для практического использования корреляционно-регрессионных моделей большое значение имеет их адекватность, т.е. соответствие фактическим статистическим данным. Корреляционно-регрессионный анализ проводится обычно по ограниченному объему статистической совокупности. Поэтому показатели регрессии и корреляции – параметры уравнения регрессии, коэффициенты корреляции и детерминации могут быть искажены действием случайных факторов. Чтобы проверить насколько эти показатели характерны для генеральной совокупности, являются ли они результатом действия случайных величин, необходимо проверить адекватность построенных статистических моделей.
Оценим модель через среднюю ошибку аппроксимации.
Средняя ошибка аппроксимации – среднее отклонение расчетных значений от фактических:
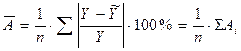
Допустимый предел значений 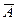 — не более 8 – 10%.
— не более 8 – 10%.
Выполним вспомогательные расчеты (табл.6).
Таблица 6. Исходные данные, необходимые для определения показателей аппроксимации.
| № хозяйства | Доля трактористов-машинистов в общей численности работников, занятых в сельскохозяйственном производстве, % | Валовый доход растениеводства, приходящийся на 100 га пашни, тыс.руб. | Расчетные величины | |||
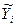 | 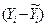 | 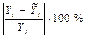 | 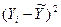 | 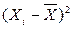 | ||
| 34,0426 | 48,2162 | 53,3288883 | -5,11268832 | 10,6036733 | 26,1395818 | 121,975157 |
| 24,1935 | 46,3568 | 60,3337919 | -13,9769919 | 30,1508989 | 195,356302 | 1,42835093 |
| 28,2486 | 47,4703 | 57,4497127 | -9,97941268 | 21,0224344 | 99,5886775 | 27,5649819 |
| 18,9850 | 40,5136 | 64,0381953 | -23,5245953 | 58,0659219 | 553,406586 | 16,1070877 |
| 27,1845 | 100,7356 | 58,2065248 | 42,52907524 | 42,2185158 | 1808,72224 | 17,5237377 |
| 11,9266 | 59,4603 | 69,0582897 | -9,59798971 | 16,1418454 | 92,1214064 | 122,58395 |
| 19,5652 | 61,4004 | 63,6255439 | -2,22514394 | 3,62398931 | 4,95126553 | 11,7866126 |
| 18,1208 | 49,7596 | 63,9008582 | 8,871941755 | 12,1912882 | 78,7113505 | 14,5944143 |
| 15,8228 | 99,1870 | 64,652834 | -14,893234 | 29,9303733 | 221,808419 | 23,790627 |
| 19,1781 | 72,7728 | 66,2872238 | 32,89977621 | 33,1694438 | 1082,39527 | 51,4887135 |
| 35,7143 | 47,1492 | 52,1399373 | -4,99073732 | 10,5849883 | 24,907459 | 161,695038 |
 | 252,9819 | 673,0219 | 673,0218 | 267,703373 | 4188,10856 | 570,53867 |
| сред. знач. | 22,9984 | 61,1838 | 61,1838 | 24,3366702 |
Средняя ошибка аппроксимации равна 24,3%. т.е. в среднем расчетные значения валового дохода растениеводства, приходящийся на 100 га пашни, отличаются от фактических на 24,3367%, что не входит в допустимый предел.
Оценим модель через F-критерий Фишера. F-критерий Фишера необходим для проверки нулевой гипотезы о статистической незначимости уравнения регрессии и показателя тесноты связи (r).
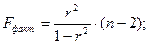
Выдвинем H0 о статистической незначимости полученного уравнения регрессии и показателя тесноты связи.
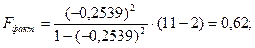
Сравним фактическое значение F-критерия с табличным. Для этого выпишем из таблицы «Значения F-Фишера при уровне значимости α=0,05» табличное значение.
k1 – число факторных признаков в модели
n – число единиц совокупности
В нашем примере k1 =1, k2 = 11-1-1 = 9
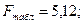
Так как Fфакт 2.1051
lgY = 10 2.1051 *(-0.25295)lgX
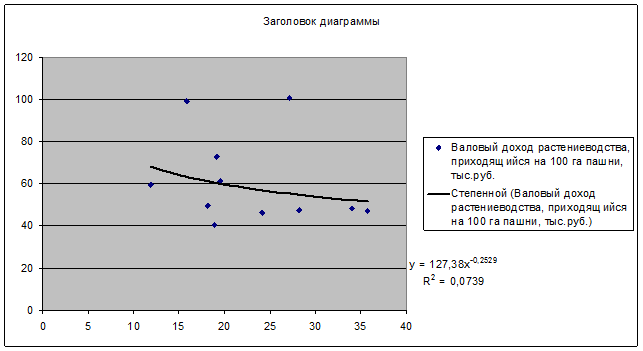
Рис. 4. Влияние доли трактористов – машинистов в общей численности работников, занятых в сельскохозяйственном производстве, на валовый доход растениеводства, приходящийся на 100 га пашни.
Коэффициент эластичности рассчитывается по формуле:
В нашем случае 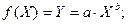
И формула коэффициента эластичности парной линейной регрессии принимает вид:
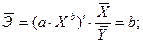
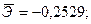
С увеличением доли трактористов – машинистов в общей численности работников, занятых в сельскохозяйственном производстве, на 1 % валовый доход растениеводства, приходящийся на 100 га пашни, уменьшается в среднем на 0,2617%.
Для нелинейной парной корреляции рассчитывается индекс корреляции:
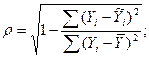
Для расчета индекса корреляции выполним вспомогательные расчеты (таблица 10).
Таблица 10. Расчетные величины, необходимые для расчета индекса корреляции и определения показателей аппроксимации
| № хозяйства | Доля тракторис-тов-машинистов в общей численности работников, занятых в сельскохозяйственном производстве, % | Валовый доход растениеводства, приходящийся на 100 га пашни, тыс.руб. | Расчетные величины | ||||||
| | 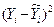 | 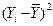 | 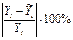 | 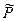 | 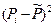 | 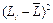 | |||
| 34,0426 | 48,2162 | 52,190896 | 15,79820936 | 168,1586498 | 8,243486908 | 1,717595 | 0,0012 | 0,036853 | |
| 24,1935 | 46,3568 | 56,900057 | 111,1602591 | 219,839929 | 22,74371089 | 1,755113 | 0,0079 | 0,001905 | |
| 28,2486 | 47,4703 | 54,71292 | 52,45554041 | 188,0600823 | 15,2571602 | 1,73809 | 0,0038 | 0,012309 | |
| 18,9850 | 40,5136 | 60,498539 | 399,3977771 | 427,257168 | 49,32896301 | 1,781745 | 0,0303 | 0,0038 | |
| 27,1845 | 100,7356 | 55,246899 | 2069,221877 | 1564,344883 | 45,15652912 | 1,742308 | 0,0681 | 0,008887 | |
| 11,9266 | 59,4603 | 68,047648 | 73,74254765 | 2,97045225 | 14,44215403 | 1,832813 | 0,0034 | 0,06945 | |
| 19,5652 | 61,4004 | 60,039622 | 1,85171669 | 0,04691556 | 2,216236331 | 1,778438 | 0,0001 | 0,002359 | |
| 18,1208 | 49,7596 | 60,343875 | 154,4781809 | 134,304921 | 17,0790806 | 1,780633 | 0,0066 | 0,003277 | |
| 15,8228 | 99,1870 | 61,215697 | 131,2421549 | 130,5123456 | 23,02288773 | 1,786863 | 0,0081 | 0,006703 | |
| 19,1781 | 72,7728 | 63,351922 | 1284,152795 | 1444,24321 | 36,1288049 | 1,80176 | 0,0379 | 0,019816 | |
| 35,7143 | 47,1492 | 51,561859 | 19,47156064 | 196,9699972 | 9,358926842 | 1,712329 | 0,0015 | 0,04528 | |
| | 252,9819 | 673,0219 | 644,1099 | 4312,97262 | 4476,708554 | 242,97794 | 19,4277 | 0,1689 | 0,21064 |
| сред. знач. | 22,9984 | 61,1838 | — | — | — | 22,0889 |
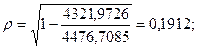
Индекс корреляции показывает, что между долей трактористов – машинистов в общей численности работников, занятых в сельскохозяйственном производстве, и валовым доходом растениеводства, приходящийся на 100 га пашни, слабая.
Коэффициент детерминации для нелинейных функций рассчитывается по формуле:
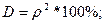
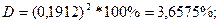
Следовательно, вариация валового дохода растениеводства, приходящийся на 100 га пашни, на 3,6575% объясняется вариацией доли трактористов – машинистов в общей численности работников, занятых в сельскохозяйственном производстве, а остальные 96,3425% вариации валового дохода растениеводства, приходящийся на 100 га пашни, обусловлены изменением других, не учтенных в модели факторов.
Оценим модель через среднюю ошибку аппроксимации:
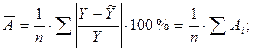
Средняя ошибка аппроксимации равна 22,1%, т.е. в среднем расчетные значения валового дохода растениеводства, приходящийся на 100 га пашни, отличаются от фактических на 22,0889%, что не входит в допустимый предел. Данная модель имеет наименьшую ошибку аппроксимации.
Оценим модель через F-критерий Фишера. F-критерий Фишера необходим для проверки нулевой гипотезы о статистической незначимости уравнения регрессии и показателя тесноты связи.
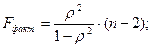
Выдвинем H0 о статистической незначимости полученного уравнения регрессии и показателя тесноты связи.
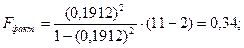
Сравним фактическое значение F-критерия с табличным. Для этого выпишем из таблицы «Значения F-Фишера при уровне значимости α=0,05» табличное значение.
Так как Fфакт 2 ) для нее максимальное
| № п/п | Модель | Средняя ошибка аппроксимации | R 2 (ρ 2 ) |
| | 24,33 | 0,064 | |
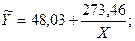 | 25,104 | 0,045 | |
| Y=127.3836*X -0.25295 | 22,0889 | 0,037 |
По условию задачи прогнозное значение фактора составляет 125% от его среднего уровня 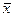 =22,9984:
=22,9984:
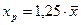 =1,25∙22,9984=28,7479
=1,25∙22,9984=28,7479
и прогнозное значение среднедушевого прожиточного минимума в день при этом составит:
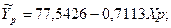
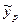 = 77,5426-0,7113*28,7479= 57,0942
= 77,5426-0,7113*28,7479= 57,0942
Если доля машинистов-трактористов составит 125% от среднего уровня =22,9984, то валовой доход растениеводства, приходящийся на 100 га пашни составит 57,0942 тыс. руб.
Оценить точность прогноза, рассчитав ошибку прогноза и его доверительный интервал
Найдем ошибку прогноза:
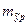 =
= 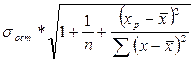
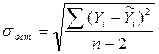
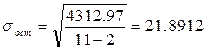
= 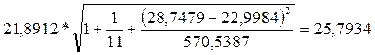 тыс.руб.
тыс.руб.
Далее строится доверительный интервал прогноза при уровне значимости g=0,05:
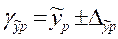 ;
;
предельная ошибка прогноза, которая в 95% случаев не будет превышена, составит:
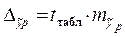 =2,2622∙25,7934=58,35
=2,2622∙25,7934=58,35
Доверительный интервал прогноза
Нижняя граница интервала:
Верхняя граница интервала:
Выполненный прогноз валового дохода растениеводства, приходящийся на 100 га пашни является неточным, так как в доверительный интервал входит 0.
http://helpiks.org/5-98042.html
http://poisk-ru.ru/s15375t23.html