Множественная линейная регрессия. Улучшение модели регрессии
Понятие множественной линейной регрессии
Множественная линейная регрессия — выраженная в виде прямой зависимость среднего значения величины Y от двух или более других величин X 1 , X 2 , . X m . Величину Y принято называть зависимой или результирующей переменной, а величины X 1 , X 2 , . X m — независимыми или объясняющими переменными.
В случае множественной линейной регрессии зависимость результирующей переменной одновременно от нескольких объясняющих переменных описывает уравнение или модель
 ,
,
где  — коэффициенты функции линейной регрессии генеральной совокупности,
— коэффициенты функции линейной регрессии генеральной совокупности,
 — случайная ошибка.
— случайная ошибка.
Функция множественной линейной регрессии для выборки имеет следующий вид:
 ,
,
где  — коэффициенты модели регрессии выборки,
— коэффициенты модели регрессии выборки,
 — ошибка.
— ошибка.
Уравнение множественной линейной регрессии и метод наименьших квадратов
Коэффициенты модели множественной линейной регресии, так же, как и для парной линейной регрессии, находят при помощи метода наименьших квадратов.
Разумеется, мы будем изучать построение модели множественной регрессии и её оценивание с использованием программных средств. Но на экзамене часто требуется привести формулы МНК-оценки (то есть оценки по методу наименьших квадратов) коэффициентов уравнения множественной линейной регрессии в скалярном и в матричном видах.
МНК-оценка коэффиентов уравнения множественной регрессии в скалярном виде
Метод наименьших квадратов позволяет найти такие значения коэффициентов, что сумма квадратов отклонений будет минимальной. Для нахождения коэффициентов решается система нормальных уравнений

Решение системы можно получить, например, методом Крамера:
 .
.
Определитель системы записывается так:

МНК-оценка коэффиентов уравнения множественной регрессии в матричном виде
Данные наблюдений и коэффициенты уравнения множественной регрессии можно представить в виде следующих матриц:

Формула коэффициентов множественной линейной регрессии в матричном виде следующая:
 ,
,
где  — матрица, транспонированная к матрице X,
— матрица, транспонированная к матрице X,
 — матрица, обратная к матрице
— матрица, обратная к матрице  .
.
Решая это уравнение, мы получим матрицу-столбец b, элементы которой и есть коэффициенты уравнения множественной линейной регрессии, для нахождения которых и был изобретён метод наименьших квадратов.
Построение наилучшей (наиболее качественной) модели множественной линейной регрессии
Пусть при обработке данных некоторой выборки в пакете программных средств STATISTICA получена первоначальная модель множественной линейной регрессии. Предстоит проанализировать полученную модель и в случае необходимости улучшить её.
Качество модели множественной линейной регрессии оценивается по тем же показателям качества, что и в случае модели парной линейной регрессии: коэффициент детерминации  , F-статистика (статистика Фишера), сумма квадратов остатков RSS, стандартная ошибка регрессии (SEE). В случае множественной регрессии следует использовать также скорректированный коэффициент детерминации (adjusted ), который применяется при исключении или добавлении в модель наблюдений или переменных.
, F-статистика (статистика Фишера), сумма квадратов остатков RSS, стандартная ошибка регрессии (SEE). В случае множественной регрессии следует использовать также скорректированный коэффициент детерминации (adjusted ), который применяется при исключении или добавлении в модель наблюдений или переменных.
Важный показатель качества модели линейной регрессии — проверка на выполнение требований Гаусса-Маркова к остаткам. В качественной модели линейной регрессии выполняются все условия Гаусса-Маркова:
- условие 1: математическое ожидание остатков равно нулю для всех наблюдений ( ε(e i ) = 0 );
- условие 2: теоретическая дисперсия остатков постоянна (равна константе) для всех наблюдений ( σ²(e i ) = σ²(e i ), i = 1, . n );
- условие 3: отсутствие систематической связи между остатками в любых двух наблюдениях;
- условие 4: отсутствие зависимости между остатками и объясняющими (независимыми) переменными.
В случае выполнения требований Гаусса-Маркова оценка коэффициентов модели, полученная методом наименьших квадратов является
Затем необходимо провести анализ значимости отдельных переменных модели множественной линейной регрессии с помощью критерия Стьюдента.
В случае наличия резко выделяющихся наблюдений (выбросов) нужно последовательно по одному исключить их из модели и проанализировать наличие незначимых переменных в модели и, в случае необходимости исключить их из модели по одному.
В исследованиях поведения человека, как и во многих других, чтобы они претендовали на объективность, важно не только установить зависимость между факторами, но и получить все необходимые статистические показатели для результата проверки соответствующей гипотезы.
Кроме того, требуется на основе тех же данных построить две нелинейные модели регрессии — с квадратами двух наиболее значимых переменных и с логарифмами тех же наиболее значимых переменных. Они также будут сравниваться с линейными моделями, полученных на разных шагах.
Также требуется построить модели с применением пошаговых процедур включения (FORWARD STEPWISE) и исключения (BACKWARD STEPWISE).
Все полученные модели множественной регрессии нужно сравнить и выбрать из них наилучшую (наиболее качественную). Теперь разберём перечисленные выше шаги последовательно и на примере.
Оценка качества модели множественной линейной регрессии в целом
Пример. Задание 1. Получено следующее уравнение множественной линейной регрессии:
и следующие показатели качества описываемой этим уравнением модели:
| adj. | RSS | SEE | F | p-level |
| 0,426 | 0,279 | 2,835 | 1,684 | 2,892 | 0,008 |
Сделать вывод о качестве модели в целом.
Ответ. По всем показателям модель некачественная. Значение не стремится к единице, а значение скорректированного ещё более низкое. Значение RSS, напротив, высокое, а p-level — низкое.
Для анализа на выполнение условий Гаусса-Маркова воспользуемся диаграммой рассеивания наблюдений (для увеличения рисунка щёлкнуть по нему левой кнопкой мыши):

Результаты проверки графика показывают: условие равенства нулю математического ожидания остатков выполняется, а условие на постоянство дисперсии — не выполняется. Достаточно невыполнения хотя бы одного условия Гаусса-Маркова, чтобы заключить, что оценка коэффициентов модели линейной регрессии не является несмещённой, эффективной и состоятельной.
Анализ значимости коэффициентов модели множественной линейной регрессии
С помощью критерия Стьюдента проверяется гипотеза о том, что соответствующий коэффициент незначимо отличается от нуля, и соответственно, переменная при этом коэффициенте имеет незначимое влияние на зависимую переменную. В свою очередь, в колонке p-level выводится вероятность того, что основная гипотеза будет принята. Если значение p-level больше уровня значимости α, то основная гипотеза принимается, иначе – отвергается. В нашем примере установлен уровень значимости α=0,05.
Пример. Задание 2. Получены следующие значения критерия Стьюдента (t) и p-level, соответствующие переменным уравнения множественной линейной регрессии:
| Перем. | Знач. коэф. | t | p-level |
| X1 | 0,129 | 2,386 | 0,022 |
| X2 | -0,286 | -2,439 | 0,019 |
| X3 | -0,037 | -0,238 | 0,813 |
| X4 | 0,15 | 1,928 | 0,061 |
| X5 | 0,328 | 0,548 | 0,587 |
| X6 | -0,391 | -0,503 | 0,618 |
| X7 | -0,673 | -0,898 | 0,375 |
| X8 | -0,006 | -0,07 | 0,944 |
| X9 | -1,937 | -2,794 | 0,008 |
| X10 | -1,233 | -1,863 | 0,07 |
Сделать вывод о значимости коэффициентов модели.
Ответ. В построенной модели присутствуют коэффициенты, которые незначимо отличаются от нуля. В целом же у переменной X8 коэффициент самый близкий к нулю, а у переменной X9 — самое высокое значение коэффициента. Коэффициенты модели линейной регрессии можно ранжировать по мере убывания незначимости с возрастанием значения t-критерия Стьюдента.
Исключение резко выделяющихся наблюдений
Пример. Задание 3. Выявлены несколько резко выделяющихся наблюдений (выбросов, то есть наблюдений с нетипичными значениями): 10, 3, 4 (соответствуют строкам исходной таблицы данных). Эти наблюдения следует последовательно исключить из модели и по мере исключения заполнить таблицу с показателями качества модели. Исключили наблюдение 10 — заполнили значение показателей, далее исключили наблюдение 3 — заполнили и так далее. По мере исключения STATISTICA будет выдавать переменные, которые остаются значимыми в модели множественной линейной регрессии — они будут выделены красном цветом. Те, что не будут выделены красным цветом — незначимые переменные и их также нужно внести в соответствующую ячейку таблицы. По завершении исключения выбросов записать уравнение конечной множественной линейной регрессии.
| № | adj. | SEE | F | p- level | незнач. пер. |
| 10 | 0,411 | 2,55 | 2,655 | 0,015 | X3, X4, X5, X6, X7, X8, X10 |
| 3 | 0,21 | 2,58 | 2,249 | 0,036 | X3, X4, X5, X6, X7, X8, X10 |
| 4 | 0,16 | 2,61 | 1,878 | 0,082 | X3, X4, X5, X6, X7, X8, X10 |
Уравнение конечной множественной линейной регрессии:
Случается однако, когда после исключения некоторого наблюдения исключение последующих наблюдений приводит к ухудшению показателей качества модели. Причина в том, что с исключением слишком большого числа наблюдений выборка теряет информативность. Поэтому в таких случаях следует вовремя остановиться.
Исключение незначимых переменных из модели
Пример. Задание 4. По мере исключения из модели множественной линейной регрессии переменных с незначимыми коэффициентами (получены при выполнении предыдущего задания, занесены в последнюю колонку таблицы) заполнить таблицу с показателями качества модели. Последняя колонка, обозначенная звёздочкой — список переменных, имеющих значимое влияние на зависимую переменную. Эти переменные STATISTICA будет выдавать выделенными красным цветом. По завершении исключения незначимых переменных записать уравнение конечной множественной линейной регрессии.
| Искл. пер. | adj. | SEE | F | p- level | * |
| X3 | 0,18 | 1,71 | 2,119 | 0,053 | X4, X5, X6, X7, X8, X10 |
| X4 | 0,145 | 1,745 | 1,974 | 0,077 | X5, X6, X7, X8, X10 |
| X5 | 0,163 | 2,368 | 2,282 | 0,048 | X6, X7, X8, X10 |
| X6 | 0,171 | 2,355 | 2,586 | 0,033 | X7, X8, X10 |
| X7 | 0,167 | 2,223 | 2,842 | 0,027 | X8, X10 |
| X8 | 0,184 | 1,705 | 3,599 | 0,013 | X10 |
Когда осталась одна переменная, имеющая значимое влияние на зависимую переменную, больше не исключаем переменные, иначе получится, что в модели все переменные незначимы.
Уравнение конечной множественной линейной регрессии после исключения незначимых переменных:
Переменные X1 и X2 в задании 3 не вошли в список незначимых переменных, поэтому они вошли в уравнение конечной множественной линейной регрессии «автоматически».
Нелинейные модели для сравнения
Пример. Задание 5. Построить две нелинейные модели регрессии — с квадратами двух наиболее значимых переменных и с логарифмами тех же наиболее значимых переменных.
Так как в наблюдениях переменных X9 и X10 имеется 0, а натуральный логарифм от 0 вычислить невозможно, то берутся следующие по значимости переменные: X1 и X2.
Полученное уравнение нелинейной регрессии с квадратами двух наиболее значимых переменных:
Показатели качества первой модели нелинейной регрессии:
| adj. | RSS | SEE | F | p-level |
| 0,17 | 0,134 | 159,9 | 1,845 | 4,8 | 0,0127 |
Вывод: модель некачественная, так как RSS и SEE принимают высокие значения, p-level стремится к нулю, коэффициент детерминации незначимо отличается от нуля.
Полученное уравнение нелинейной регрессии с логарифмами двух наиболее значимых переменных:
Показатели качества второй модели нелинейной регрессии:
| adj. | RSS | SEE | F | p-level |
| 0,182 | 0,148 | 157,431 | 1,83 | 5,245 | 0 |
Вывод: модель некачественная, так как RSS и SEE принимают высокие значения, p-level стремится к нулю, коэффициент детерминации незначимо отличается от нуля.
Применение пошаговых алгоритмов включения и исключения переменных
Пример. Задание 6. Настроить пакет STATISTICA для применения пошаговых процедур включения (FORWARD STEPWISE) и исключения (BACKWARD STEPWISE). Для этого в диалоговом окне MULTIPLE REGRESSION указать Advanced Options (stepwise or ridge regression). В поле Method выбрать либо Forward Stepwise (алгоритм пошагового включения), либо Backward Stepwise (алгоритм пошагового исключения). Необходимо настроить следующие параметры:
- в окне Tolerance необходимо установить критическое значение для уровня толерантности (оставить предложенное по умолчанию);
- в окне F-remove необходимо установить критическое значение для статистики исключения (оставить предложенное по умолчанию);
- в окне Display Results необходимо установить режим At each step (результаты выводятся на каждом шаге процедуры).
Построить, как описано выше, модели множественной линейной регрессии автоматически.
В результате применения пошагового алгоритма включения получено следующее уравнение множественной линейной регрессии:
Показатели качества модели нелинейной регрессии, полученной с применением пошаговой процедуры включения:
| adj. | RSS | SEE | F | p-level |
| 0,41 | 0,343 | 113,67 | 1,61 | 6,11 | 0,002 |
В результате применения пошагового алгоритма исключения получено следующее уравнение множественной линейной регрессии:
Показатели качества модели нелинейной регрессии, полученной с применением пошаговой процедуры исключения:
| adj. | RSS | SEE | F | p-level |
| 0,22 | 0,186 | 150,28 | 1,79 | 6,61 | 0 |
Выбор самой качественной модели множественной линейной регрессии
Пример. Задание 7. Сравнить модели, полученные на предыдущих шагах и определить самую качественную.
| Модель | Ручная | Кв. перем. | Лог. перем. | forward stepwise | backward stepwise |
| 0,255 | 0,17 | 0,182 | 0,41 | 0,22 |
| adj. | 0,184 | 0,134 | 0,148 | 0,343 | 0,186 |
| RSS | 122,01 | 159,9 | 157,43 | 113,67 | 150,28 |
| SEE | 1,705 | 1,845 | 1,83 | 1,61 | 1,79 |
| F | 3,599 | 4,8 | 5,245 | 6,11 | 6,61 |
| p-level | 0,013 | 0,0127 | 0 | 0,002 | 0 |
Самая качественная модель множественной линейной регрессии — модель, построенная методом FORWARD STEPWISE (пошаговое включение переменных), так как коэффициент детерминации у неё самый высокий, а RSS и SEE наименьшие в сравнении значений оценок качества других регрессионных моделей.
Уравнение регрессии. Уравнение множественной регрессии
Во время учебы студенты очень часто сталкиваются с разнообразными уравнениями. Одно из них – уравнение регрессии — рассмотрено в данной статье. Такой тип уравнения применяется специально для описания характеристики связи между математическими параметрами. Данный вид равенств используют в статистике и эконометрике.
Определение понятия регрессии
В математике под регрессией подразумевается некая величина, описывающая зависимость среднего значения совокупности данных от значений другой величины. Уравнение регрессии показывает в качестве функции определенного признака среднее значение другого признака. Функция регрессии имеет вид простого уравнения у = х, в котором у выступает зависимой переменной, а х – независимой (признак-фактор). Фактически регрессия выражаться как у = f (x).
Какие бывают типы связей между переменными
В общем, выделяется два противоположных типа взаимосвязи: корреляционная и регрессионная.
Первая характеризуется равноправностью условных переменных. В данном случае достоверно не известно, какая переменная зависит от другой.
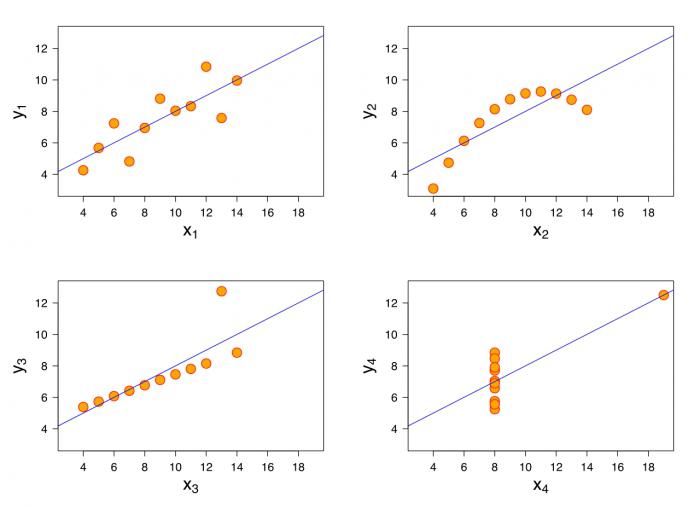
Если же между переменными не наблюдается равноправности и в условиях сказано, какая переменная объясняющая, а какая – зависимая, то можно говорить о наличии связи второго типа. Для того чтобы построить уравнение линейной регрессии, необходимо будет выяснить, какой тип связи наблюдается.
Виды регрессий
На сегодняшний день выделяют 7 разнообразных видов регрессии: гиперболическая, линейная, множественная, нелинейная, парная, обратная, логарифмически линейная.
Гиперболическая, линейная и логарифмическая
Уравнение линейной регрессии применяют в статистике для четкого объяснения параметров уравнения. Оно выглядит как у = с+т*х+Е. Гиперболическое уравнение имеет вид правильной гиперболы у = с + т / х + Е. Логарифмически линейное уравнение выражает взаимосвязь с помощью логарифмической функции: In у = In с + т* In x + In E.
Множественная и нелинейная
Два более сложных вида регрессии – это множественная и нелинейная. Уравнение множественной регрессии выражается функцией у = f(х1 , х2 . хс)+E. В данной ситуации у выступает зависимой переменной, а х – объясняющей. Переменная Е — стохастическая, она включает влияние других факторов в уравнении. Нелинейное уравнение регрессии немного противоречиво. С одной стороны, относительно учтенных показателей оно не линейное, а с другой стороны, в роли оценки показателей оно линейное.
Обратные и парные виды регрессий
Обратная – это такой вид функции, который необходимо преобразовать в линейный вид. В самых традиционных прикладных программах она имеет вид функции у = 1/с + т*х+Е. Парное уравнение регрессии демонстрирует взаимосвязь между данными в качестве функции у = f (x) + Е. Точно так же, как и в других уравнениях, у зависит от х, а Е — стохастический параметр.
Понятие корреляции
Это показатель, демонстрирующий существование взаимосвязи двух явлений или процессов. Сила взаимосвязи выражается в качестве коэффициента корреляции. Его значение колеблется в рамках интервала [-1;+1]. Отрицательный показатель говорит о наличии обратной связи, положительный – о прямой. Если коэффициент принимает значение, равное 0, то взаимосвязи нет. Чем ближе значение к 1 – тем сильнее связь между параметрами, чем ближе к 0 – тем слабее.
Методы
Корреляционные параметрические методы могут оценить тесноту взаимосвязи. Их используют на базе оценки распределения для изучения параметров, подчиняющихся закону нормального распределения.
Параметры уравнения линейной регрессии необходимы для идентификации вида зависимости, функции регрессионного уравнения и оценивания показателей избранной формулы взаимосвязи. В качестве метода идентификации связи используется поле корреляции. Для этого все существующие данные необходимо изобразить графически. В прямоугольной двухмерной системе координат необходимо нанести все известные данные. Так образуется поле корреляции. Значение описывающего фактора отмечаются вдоль оси абсцисс, в то время как значения зависимого – вдоль оси ординат. Если между параметрами есть функциональная зависимость, они выстраиваются в форме линии.
В случае если коэффициент корреляции таких данных будет менее 30 %, можно говорить о практически полном отсутствии связи. Если он находится между 30 % и 70 %, то это говорит о наличии связей средней тесноты. 100 % показатель – свидетельство функциональной связи.
Нелинейное уравнение регрессии так же, как и линейное, необходимо дополнять индексом корреляции (R).
Корреляция для множественной регрессии
Коэффициент детерминации является показателем квадрата множественной корреляции. Он говорит о тесноте взаимосвязи представленного комплекса показателей с исследуемым признаком. Он также может говорить о характере влияния параметров на результат. Уравнение множественной регрессии оценивают с помощью этого показателя.
Для того чтобы вычислить показатель множественной корреляции, необходимо рассчитать его индекс.
Метод наименьших квадратов
Данный метод является способом оценивания факторов регрессии. Его суть заключается в минимизировании суммы отклонений в квадрате, полученных вследствие зависимости фактора от функции.
Парное линейное уравнение регрессии можно оценить с помощью такого метода. Этот тип уравнений используют в случае обнаружения между показателями парной линейной зависимости.
Параметры уравнений
Каждый параметр функции линейной регрессии несет определенный смысл. Парное линейное уравнение регрессии содержит два параметра: с и т. Параметр т демонстрирует среднее изменение конечного показателя функции у, при условии уменьшения (увеличения) переменной х на одну условную единицу. Если переменная х – нулевая, то функция равняется параметру с. Если же переменная х не нулевая, то фактор с не несет в себе экономический смысл. Единственное влияние на функцию оказывает знак перед фактором с. Если там минус, то можно сказать о замедленном изменении результата по сравнению с фактором. Если там плюс, то это свидетельствует об ускоренном изменении результата.
Каждый параметр, изменяющий значение уравнения регрессии, можно выразить через уравнение. Например, фактор с имеет вид с = y – тх.
Сгруппированные данные
Бывают такие условия задачи, в которых вся информация группируется по признаку x, но при этом для определенной группы указываются соответствующие средние значения зависимого показателя. В таком случае средние значения характеризуют, каким образом изменяется показатель, зависящий от х. Таким образом, сгруппированная информация помогает найти уравнение регрессии. Ее используют в качестве анализа взаимосвязей. Однако у такого метода есть свои недостатки. К сожалению, средние показатели достаточно часто подвергаются внешним колебаниям. Данные колебания не являются отображением закономерности взаимосвязи, они всего лишь маскируют ее «шум». Средние показатели демонстрируют закономерности взаимосвязи намного хуже, чем уравнение линейной регрессии. Однако их можно применять в виде базы для поиска уравнения. Перемножая численность отдельной совокупности на соответствующую среднюю можно получить сумму у в пределах группы. Далее необходимо подбить все полученные суммы и найти конечный показатель у. Чуть сложнее производить расчеты с показателем суммы ху. В том случае если интервалы малы, можно условно взять показатель х для всех единиц (в пределах группы) одинаковым. Следует перемножить его с суммой у, чтобы узнать сумму произведений x на у. Далее все суммы подбиваются вместе и получается общая сумма ху.
Множественное парное уравнение регрессии: оценка важности связи
Как рассматривалось ранее, множественная регрессия имеет функцию вида у = f (x1,x2,…,xm)+E. Чаще всего такое уравнение используют для решения проблемы спроса и предложения на товар, процентного дохода по выкупленным акциям, изучения причин и вида функции издержек производства. Ее также активно применяют в самых разнообразным макроэкономических исследованиях и расчетах, а вот на уровне микроэкономики такое уравнение применяют немного реже.
Основной задачей множественной регрессии является построение модели данных, содержащих огромное количество информации, для того чтобы в дальнейшем определить, какое влияние имеет каждый из факторов по отдельности и в их общей совокупности на показатель, который необходимо смоделировать, и его коэффициенты. Уравнение регрессии может принимать самые разнообразные значения. При этом для оценки взаимосвязи обычно используется два типа функций: линейная и нелинейная.
Линейная функция изображается в форме такой взаимосвязи: у = а0 + a1х1 + а2х2,+ . + amxm. При этом а2, am, считаются коэффициентами «чистой» регрессии. Они необходимы для характеристики среднего изменения параметра у с изменением (уменьшением или увеличением) каждого соответствующего параметра х на одну единицу, с условием стабильного значения других показателей.
Нелинейные уравнения имеют, к примеру, вид степенной функции у=ах1 b1 х2 b2 . xm bm . В данном случае показатели b1, b2. bm – называются коэффициентами эластичности, они демонстрируют, каким образом изменится результат (на сколько %) при увеличении (уменьшении) соответствующего показателя х на 1 % и при стабильном показателе остальных факторов.
Какие факторы необходимо учитывать при построении множественной регрессии
Для того чтобы правильно построить множественную регрессию, необходимо выяснить, на какие именно факторы следует обратить особое внимание.
Необходимо иметь определенное понимание природы взаимосвязей между экономическими факторами и моделируемым. Факторы, которые необходимо будет включать, обязаны отвечать следующим признакам:
- Должны быть подвластны количественному измерению. Для того чтобы использовать фактор, описывающий качество предмета, в любом случае следует придать ему количественную форму.
- Не должна присутствовать интеркорреляция факторов, или функциональная взаимосвязь. Такие действия чаще всего приводят к необратимым последствиям – система обыкновенных уравнений становится не обусловленной, а это влечет за собой ее ненадежность и нечеткость оценок.
- В случае существования огромного показателя корреляции не существует способа для выяснения изолированного влияния факторов на окончательный результат показателя, следовательно, коэффициенты становятся неинтерпретируемыми.
Методы построения
Существует огромное количество методов и способов, объясняющих, каким образом можно выбрать факторы для уравнения. Однако все эти методы строятся на отборе коэффициентов с помощью показателя корреляции. Среди них выделяют:
- Способ исключения.
- Способ включения.
- Пошаговый анализ регрессии.
Первый метод подразумевает отсев всех коэффициентов из совокупного набора. Второй метод включает введение множества дополнительных факторов. Ну а третий – отсев факторов, которые были ранее применены для уравнения. Каждый из этих методов имеет право на существование. У них есть свои плюсы и минусы, но они все по-своему могут решить вопрос отсева ненужных показателей. Как правило, результаты, полученные каждым отдельным методом, достаточно близки.
Методы многомерного анализа
Такие способы определения факторов базируются на рассмотрении отдельных сочетаний взаимосвязанных признаков. Они включают в себя дискриминантный анализ, распознание обликов, способ главных компонент и анализ кластеров. Кроме того, существует также факторный анализ, однако он появился вследствие развития способа компонент. Все они применяются в определенных обстоятельствах, при наличии определенных условий и факторов.
Множественная (многофакторная) регрессия
Уравнение множественной регрессии имеет вид
СЛАД 8
 , (1)
, (1)
где y – зависимая переменная (результативный признак);
 — независимые переменные (факторы).
— независимые переменные (факторы).
Такого рода уравнение может использоваться при изучении потребления. Тогда коэффициенты  — частные производные потребления y по соответствующим факторам
— частные производные потребления y по соответствующим факторам  :
:  в предположении, что все остальные постоянны.
в предположении, что все остальные постоянны.
Множественная регрессия – один из наиболее распространенных методов в эконометрике. Основная цель множественной регрессии – построить модель с большим числом факторов, определив при этом влияние каждого из них в отдельности, а также совокупное их воздействие на моделируемый показатель.
Построение уравнения множественной регрессии начинается с решения вопроса о спецификации модели. Она включает в себя два круга вопросов:
— выбор вида уравнения регрессии.
Включение в уравнение множественной регрессии того или иного набора факторов связано, прежде всего, с представлением исследователя о природе взаимосвязи моделируемого показателя с другими экономическими явлениями. Факторы, включаемые во множественную регрессию, должны отвечать следующим требованиям:
1. Они должны быть количественно измеримы. Если необходимо включить в модель качественный фактор, не имеющий количественного измерения, то ему нужно придать количественную определенность. Например, в модели стоимости объектов недвижимости учитывается место нахождения недвижимости; районы могут быть проранжированы.
2. Факторы не должны быть интеркоррелированы и тем более находиться в точной функциональной связи.
Если между факторами существует высокая корреляция, то нельзя определить их изолированное влияние на результативный показатель и параметры уравнения регрессии оказываются неинтерпретируемыми. Так, в уравнении  предполагается, что факторы
предполагается, что факторы  независимы друг от друга, т.е.
независимы друг от друга, т.е.  . Тогда можно говорить, что параметр
. Тогда можно говорить, что параметр  измеряет силу влияния фактора
измеряет силу влияния фактора  на результат y при неизменном значении фактора
на результат y при неизменном значении фактора  . Если же
. Если же  , то с изменением фактора , не может оставаться неизменным. Отсюда
, то с изменением фактора , не может оставаться неизменным. Отсюда  и
и  нельзя интерпретировать как показатели раздельного влияния и на y.
нельзя интерпретировать как показатели раздельного влияния и на y.
Пример. Рассмотрим регрессию себестоимости единицы продукции y (руб.) от заработной платы работника x (руб.) и производительности его труда z (единиц в час)  . Коэффициент регрессии при переменной z показывает, что с ростом производительности труда на 1 ед. себестоимость единицы продукции снижается в среднем на 10 руб. при постоянном уровне оплаты труда. Вместе с тем параметр при x нельзя интерпретировать как снижение себестоимости единицы продукции за счет роста заработной платы. Отрицательное значение коэффициента регрессии при переменной x в данном случае обусловлено высокой корреляцией между x и z (
. Коэффициент регрессии при переменной z показывает, что с ростом производительности труда на 1 ед. себестоимость единицы продукции снижается в среднем на 10 руб. при постоянном уровне оплаты труда. Вместе с тем параметр при x нельзя интерпретировать как снижение себестоимости единицы продукции за счет роста заработной платы. Отрицательное значение коэффициента регрессии при переменной x в данном случае обусловлено высокой корреляцией между x и z (  ). Поэтому роста заработной платы при неизменности производительности труда (если не брать во внимание проблемы инфляции) быть не может.
). Поэтому роста заработной платы при неизменности производительности труда (если не брать во внимание проблемы инфляции) быть не может.
Считается, что две переменные явно коллинеарны, т.е. находятся между собой в линейной зависимости, если  . Наибольшие трудности в использовании аппарата множественной регрессии возникают при наличии мультиколлинеарности факторов, когда более чем два фактора связаны между собой линейной зависимостью, т.е. имеет место совокупное воздействие факторов друг на друга. В результате вариация в исходных данных перестает быть полностью независимой, и нельзя оценить воздействие каждого фактора в отдельности.
. Наибольшие трудности в использовании аппарата множественной регрессии возникают при наличии мультиколлинеарности факторов, когда более чем два фактора связаны между собой линейной зависимостью, т.е. имеет место совокупное воздействие факторов друг на друга. В результате вариация в исходных данных перестает быть полностью независимой, и нельзя оценить воздействие каждого фактора в отдельности.
Включение в модель мультиколлинеарных факторов нежелательно в силу следующих последствий:
1. параметры линейной регрессии теряют экономический смысл;
2. оценки параметров ненадежны, что делает модель непригодной для анализа и прогнозирования.
Для оценки мультиколлинеарности факторов может использоваться определитель матрицы парных коэффициентов корреляции между факторами. Если бы факторы не коррелировали между собой, то матрица парных коэффициентов корреляции между факторами была бы единичной матрицей, поскольку все недиагональные элементы были бы равны нулю.
Так, для включающего три объясняющих переменных уравнения  матрица коэффициентов корреляции между факторами имела бы определитель, равный единице.
матрица коэффициентов корреляции между факторами имела бы определитель, равный единице.
 , т.к.
, т.к.  .
.
Если же, наоборот, между факторами существует полная линейная зависимость и все коэффициенты корреляции равны единице, то определитель такой матрицы равен нулю:  .
.
Чем ближе к нулю определитель матрицы межфакторной корреляции, тем сильнее мультиколлинеарность факторов и ненадежнее результаты множественной регрессии. И, наоборот, чем ближе к единице определитель матрицы, тем меньше мультиколлинеарность факторов.
Проверка мультиколлинеарности факторов может быть проведена методом испытания гипотезы о независимости переменных H0:  . Доказано, что величина
. Доказано, что величина

имеет приближенное распределение  с
с  степенями свободы. Если фактическое значение
степенями свободы. Если фактическое значение  превосходит табличное (критическое)
превосходит табличное (критическое)  , то гипотеза H0 отклоняется. Это означает, что
, то гипотеза H0 отклоняется. Это означает, что  , недиагональные ненулевые коэффициенты корреляции указывают на коллинеарность факторов. Мультиколлинеарность считается доказанной.
, недиагональные ненулевые коэффициенты корреляции указывают на коллинеарность факторов. Мультиколлинеарность считается доказанной.
Как и в парной зависимости, возможны разные виды уравнений множественной регрессии: линейные и нелинейные. Ввиду четкой интерпретации параметров наиболее широко используются линейная и степенная функции.
В линейной множественной регрессии  параметры при x называются коэффициентами «чистой» регрессии. Они характеризуют среднее изменение результата с изменением соответствующего фактора на единицу при неизменном значении других факторов, закрепленных на среднем уровне.
параметры при x называются коэффициентами «чистой» регрессии. Они характеризуют среднее изменение результата с изменением соответствующего фактора на единицу при неизменном значении других факторов, закрепленных на среднем уровне.
Пример. Предположим, что зависимость расходов на продукты питания по совокупности семей характеризуется следующим уравнением:
 ,
,
где y – расходы семьи за месяц на продукты питания, тыс. руб.;
— месячный доход на одного члена семьи, тыс. руб.;
 — размер семьи, человек.
— размер семьи, человек.
Анализ данного уравнения позволяет сделать вывод: с ростом дохода на одного члена семьи на 1 тыс. рублей расходы на питание возрастут в среднем на 350 рублей при том же среднем размере семьи. Иными словами, 35% дополнительных семейных расходов тратится на питание. Увеличение размера семьи при тех же ее доходах предполагает дополнительный рост расходов на питание на 730 рублей.
Параметр a не подлежит экономической интерпретации.
В степенной функции
 (2)
(2)
коэффициенты  являются коэффициентами эластичности. Они показывают, на сколько процентов изменяется в среднем результат с изменением соответствующего фактора на 1% при неизменности действия других факторов. Этот вид уравнения регрессии получил наибольшее распространение в производственных функциях, в исследованиях спроса и потребления.
являются коэффициентами эластичности. Они показывают, на сколько процентов изменяется в среднем результат с изменением соответствующего фактора на 1% при неизменности действия других факторов. Этот вид уравнения регрессии получил наибольшее распространение в производственных функциях, в исследованиях спроса и потребления.
Пример. Предположим, что при исследовании спроса на мясо получено уравнение  ,
,
где y – количество спрашиваемого мяса;
— цена;
 — доход.
— доход.
Следовательно, рост цен на 1% при том же доходе вызывает снижение спроса в среднем на 2,63%. Увеличение дохода на 1% обусловливает при неизменных ценах рост спроса на 1,11%.
Возможны и другие линеаризуемые функции для построения уравнения множественной регрессии:
 ; (3)
; (3)
 , (4)
, (4)
которая используется при обратных связях признаков.
Стандартные компьютерные программы обработки регрессионного анализа позволяют перебирать различные функции и выбирать ту из них, для которой остаточная дисперсия и ошибка аппроксимации минимальны, а коэффициент детерминации максимален.
Для оценки параметров уравнения множественной регрессии применяют метод наименьших квадратов (МНК). Для линейных и нелинейных уравнений, приводимых к линейным, строится следующая система нормальных уравнений, решение которой позволяет получить оценки параметров регрессии:
СЛАД 9
 . (5)
. (5)
Для ее решения может быть применен метод определителей
 , (6)
, (6)
где Δ – определитель матрицы;
 — частные определители, которые получаются путем замены соответствующего столбца матрицы данными левой части системы.
— частные определители, которые получаются путем замены соответствующего столбца матрицы данными левой части системы.
При этом определитель системы

 . (7)
. (7)
СЛАД 10
Другой вид уравнений множественной регрессии – уравнение регрессии в стандартизованном масштабе
 , (8)
, (8)
где  — стандартизованные переменные:
— стандартизованные переменные:
 ,
,  , (9)
, (9)
для которых среднее значение равно нулю  , а среднее квадратическое отклонение равно единице
, а среднее квадратическое отклонение равно единице  ;
;
β – стандартизованные коэффициенты регрессии.
К уравнению множественной регрессии в стандартизованном масштабе применим МНК. Стандартизованные β – коэффициенты определяются из следующей системы уравнений:
СЛАД 11
 (10)
(10)
Стандартизованные коэффициенты регрессии показывают, на сколько сигм изменится в среднем результат, если соответствующий фактор  изменится на одну сигму при неизменном среднем уровне других факторов.
изменится на одну сигму при неизменном среднем уровне других факторов.
Стандартизованные коэффициенты  сравнимы между собой. Сравнивая их друг с другом, можно ранжировать факторы по силе их воздействия на результат. В этом основное достоинство стандартизованных коэффициентов регрессии в отличие от коэффициентов «чистой» регрессии, которые несравнимы между собой.
сравнимы между собой. Сравнивая их друг с другом, можно ранжировать факторы по силе их воздействия на результат. В этом основное достоинство стандартизованных коэффициентов регрессии в отличие от коэффициентов «чистой» регрессии, которые несравнимы между собой.
Пример. Пусть функция издержек производства y (тыс. руб.) характеризуется уравнением вида  ,
,
где  — основные производственные фонды (ОПФ) (тыс. руб.);
— основные производственные фонды (ОПФ) (тыс. руб.);
 — численность занятых в производстве (чел.).
— численность занятых в производстве (чел.).
Анализируя его, видим, что при той же занятости дополнительный рост стоимости ОПФ на 1 тыс. руб. влечет за собой увеличение затрат в среднем на 1,2 тыс. руб., а увеличение численности занятых на одного человека способствует при той же технической оснащенности предприятий росту затрат в среднем на 1,1 тыс. руб.
Однако это не означает, что фактор оказывает более сильное влияние на издержки производства по сравнению с фактором . Такое сравнение возможно, если обратиться к уравнению регрессии в стандартизованном масштабе. Предположим, оно выглядит так:  . Это означает, что с ростом фактора на одну сигму при неизменной численности занятых затраты на продукцию увеличиваются в среднем на 0,5 сигмы. Так как
. Это означает, что с ростом фактора на одну сигму при неизменной численности занятых затраты на продукцию увеличиваются в среднем на 0,5 сигмы. Так как  (0,5
(0,5


ЧТО ТАКОЕ УВЕРЕННОЕ ПОВЕДЕНИЕ В МЕЖЛИЧНОСТНЫХ ОТНОШЕНИЯХ? Исторически существует три основных модели различий, существующих между.
http://www.syl.ru/article/178055/new_uravnenie-regressii-uravnenie-mnojestvennoy-regressii
http://zdamsam.ru/a61238.html