Уравнение нелинейной регрессии
Вместе с этим калькулятором также используют следующие:
Уравнение множественной регрессии
Виды нелинейной регрессии
| Вид | Класс нелинейных моделей |
| Нелинейные относительно включенных в анализ объясняющих переменных, но линейные по оцениваемым параметрам |
| Нелинейные по оцениваемым параметрам |
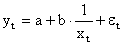
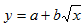
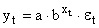
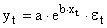

Здесь ε — случайная ошибка (отклонение, возмущение), отражающая влияние всех неучтенных факторов.
Уравнению регрессии первого порядка — это уравнение парной линейной регрессии.
Уравнение регрессии второго порядка это полиномальное уравнение регрессии второго порядка: y = a + bx + cx 2 .
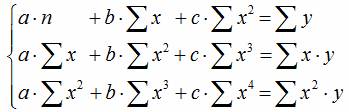
Уравнение регрессии третьего порядка соответственно полиномальное уравнение регрессии третьего порядка: y = a + bx + cx 2 + dx 3 .
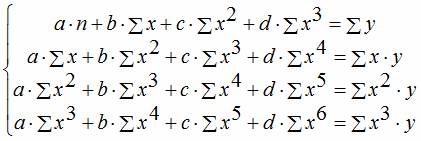
Чтобы привести нелинейные зависимости к линейной используют методы линеаризации (см. метод выравнивания):
- Замена переменных.
- Логарифмирование обеих частей уравнения.
- Комбинированный.
| y = f(x) | Преобразование | Метод линеаризации |
| y = b x a | Y = ln(y); X = ln(x) | Логарифмирование |
| y = b e ax | Y = ln(y); X = x | Комбинированный |
| y = 1/(ax+b) | Y = 1/y; X = x | Замена переменных |
| y = x/(ax+b) | Y = x/y; X = x | Замена переменных. Пример |
| y = aln(x)+b | Y = y; X = ln(x) | Комбинированный |
| y = a + bx + cx 2 | x1 = x; x2 = x 2 | Замена переменных |
| y = a + bx + cx 2 + dx 3 | x1 = x; x2 = x 2 ; x3 = x 3 | Замена переменных |
| y = a + b/x | x1 = 1/x | Замена переменных |
| y = a + sqrt(x)b | x1 = sqrt(x) | Замена переменных |
Пример . По данным, взятым из соответствующей таблицы, выполнить следующие действия:
- Построить поле корреляции и сформулировать гипотезу о форме связи.
- Рассчитать параметры уравнений линейной, степенной, экспоненциальной, полулогарифмической, обратной, гиперболической парной регрессии.
- Оценить тесноту связи с помощью показателей корреляции и детерминации.
- Дать с помощью среднего (общего) коэффициента эластичности сравнительную оценку силы связи фактора с результатом.
- Оценить с помощью средней ошибки аппроксимации качество уравнений.
- Оценить с помощью F-критерия Фишера статистическую надежность результатов регрессионного моделирования. По значениям характеристик, рассчитанных в пп. 4, 5 и данном пункте, выбрать лучшее уравнение регрессии и дать его обоснование.
- Рассчитать прогнозное значение результата, если прогнозное значение фактора увеличится на 15% от его среднего уровня. Определить доверительный интервал прогноза для уровня значимости α=0,05 .
- Оценить полученные результаты, выводы оформить в аналитической записке.
| Год | Фактическое конечное потребление домашних хозяйств (в текущих ценах), млрд. руб. (1995 г. — трлн. руб.), y | Среднедушевые денежные доходы населения (в месяц), руб. (1995 г. — тыс. руб.), х |
| 1995 | 872 | 515,9 |
| 2000 | 3813 | 2281,1 |
| 2001 | 5014 | 3062 |
| 2002 | 6400 | 3947,2 |
| 2003 | 7708 | 5170,4 |
| 2004 | 9848 | 6410,3 |
| 2005 | 12455 | 8111,9 |
| 2006 | 15284 | 10196 |
| 2007 | 18928 | 12602,7 |
| 2008 | 23695 | 14940,6 |
| 2009 | 25151 | 16856,9 |
Решение. В калькуляторе последовательно выбираем виды нелинейной регрессии. Получим таблицу следующего вида.
Экспоненциальное уравнение регрессии имеет вид y = a e bx
После линеаризации получим: ln(y) = ln(a) + bx
Получаем эмпирические коэффициенты регрессии: b = 0.000162, a = 7.8132
Уравнение регрессии: y = e 7.81321500 e 0.000162x = 2473.06858e 0.000162x
Степенное уравнение регрессии имеет вид y = a x b
После линеаризации получим: ln(y) = ln(a) + b ln(x)
Эмпирические коэффициенты регрессии: b = 0.9626, a = 0.7714
Уравнение регрессии: y = e 0.77143204 x 0.9626 = 2.16286x 0.9626
Гиперболическое уравнение регрессии имеет вид y = b/x + a + ε
После линеаризации получим: y=bx + a
Эмпирические коэффициенты регрессии: b = 21089190.1984, a = 4585.5706
Эмпирическое уравнение регрессии: y = 21089190.1984 / x + 4585.5706
Логарифмическое уравнение регрессии имеет вид y = b ln(x) + a + ε
Эмпирические коэффициенты регрессии: b = 7142.4505, a = -49694.9535
Уравнение регрессии: y = 7142.4505 ln(x) — 49694.9535
Основы линейной регрессии
Что такое регрессия?
Разместим точки на двумерном графике рассеяния и скажем, что мы имеем линейное соотношение, если данные аппроксимируются прямой линией.
Если мы полагаем, что y зависит от x, причём изменения в y вызываются именно изменениями в x, мы можем определить линию регрессии (регрессия y на x), которая лучше всего описывает прямолинейное соотношение между этими двумя переменными.
Статистическое использование слова «регрессия» исходит из явления, известного как регрессия к среднему, приписываемого сэру Френсису Гальтону (1889).
Он показал, что, хотя высокие отцы имеют тенденцию иметь высоких сыновей, средний рост сыновей меньше, чем у их высоких отцов. Средний рост сыновей «регрессировал» и «двигался вспять» к среднему росту всех отцов в популяции. Таким образом, в среднем высокие отцы имеют более низких (но всё-таки высоких) сыновей, а низкие отцы имеют сыновей более высоких (но всё-таки довольно низких).
Линия регрессии
Математическое уравнение, которое оценивает линию простой (парной) линейной регрессии:
x называется независимой переменной или предиктором.
Y – зависимая переменная или переменная отклика. Это значение, которое мы ожидаем для y (в среднем), если мы знаем величину x, т.е. это «предсказанное значение y»
- a – свободный член (пересечение) линии оценки; это значение Y, когда x=0 (Рис.1).
- b – угловой коэффициент или градиент оценённой линии; она представляет собой величину, на которую Y увеличивается в среднем, если мы увеличиваем x на одну единицу.
- a и b называют коэффициентами регрессии оценённой линии, хотя этот термин часто используют только для b.
Парную линейную регрессию можно расширить, включив в нее более одной независимой переменной; в этом случае она известна как множественная регрессия.

Рис.1. Линия линейной регрессии, показывающая пересечение a и угловой коэффициент b (величину возрастания Y при увеличении x на одну единицу)
Метод наименьших квадратов
Мы выполняем регрессионный анализ, используя выборку наблюдений, где a и b – выборочные оценки истинных (генеральных) параметров, α и β , которые определяют линию линейной регрессии в популяции (генеральной совокупности).
Наиболее простым методом определения коэффициентов a и b является метод наименьших квадратов (МНК).
Подгонка оценивается, рассматривая остатки (вертикальное расстояние каждой точки от линии, например, остаток = наблюдаемому y – предсказанный y, Рис. 2).
Линию лучшей подгонки выбирают так, чтобы сумма квадратов остатков была минимальной.

Рис. 2. Линия линейной регрессии с изображенными остатками (вертикальные пунктирные линии) для каждой точки.
Предположения линейной регрессии
Итак, для каждой наблюдаемой величины  остаток равен разнице
остаток равен разнице  и соответствующего предсказанного
и соответствующего предсказанного  Каждый остаток может быть положительным или отрицательным.
Каждый остаток может быть положительным или отрицательным.
Можно использовать остатки для проверки следующих предположений, лежащих в основе линейной регрессии:
- Между
 и существует линейное соотношение: для любых пар данные должны аппроксимировать прямую линию. Если нанести на двумерный график остатки, то мы должны наблюдать случайное рассеяние точек, а не какую-либо систематическую картину.
и существует линейное соотношение: для любых пар данные должны аппроксимировать прямую линию. Если нанести на двумерный график остатки, то мы должны наблюдать случайное рассеяние точек, а не какую-либо систематическую картину.
 данные должны аппроксимировать прямую линию. Если нанести на двумерный график остатки, то мы должны наблюдать случайное рассеяние точек, а не какую-либо систематическую картину.
данные должны аппроксимировать прямую линию. Если нанести на двумерный график остатки, то мы должны наблюдать случайное рассеяние точек, а не какую-либо систематическую картину.- Остатки нормально распределены с нулевым средним значением;
- Остатки имеют одну и ту же вариабельность (постоянную дисперсию) для всех предсказанных величин Если нанести остатки против предсказанных величин от мы должны наблюдать случайное рассеяние точек. Если график рассеяния остатков увеличивается или уменьшается с увеличением то это допущение не выполняется;
 Если нанести остатки против предсказанных величин
Если нанести остатки против предсказанных величин  от
от  мы должны наблюдать случайное рассеяние точек. Если график рассеяния остатков увеличивается или уменьшается с увеличением
мы должны наблюдать случайное рассеяние точек. Если график рассеяния остатков увеличивается или уменьшается с увеличением  то это допущение не выполняется;
то это допущение не выполняется;Если допущения линейности, нормальности и/или постоянной дисперсии сомнительны, мы можем преобразовать или и рассчитать новую линию регрессии, для которой эти допущения удовлетворяются (например, использовать логарифмическое преобразование или др.).
Аномальные значения (выбросы) и точки влияния
«Влиятельное» наблюдение, если оно опущено, изменяет одну или больше оценок параметров модели (т.е. угловой коэффициент или свободный член).
Выброс (наблюдение, которое противоречит большинству значений в наборе данных) может быть «влиятельным» наблюдением и может хорошо обнаруживаться визуально, при осмотре двумерной диаграммы рассеяния или графика остатков.
И для выбросов, и для «влиятельных» наблюдений (точек) используют модели, как с их включением, так и без них, обращают внимание на изменение оценки (коэффициентов регрессии).
При проведении анализа не стоит отбрасывать выбросы или точки влияния автоматически, поскольку простое игнорирование может повлиять на полученные результаты. Всегда изучайте причины появления этих выбросов и анализируйте их.
Гипотеза линейной регрессии
При построении линейной регрессии проверяется нулевая гипотеза о том, что генеральный угловой коэффициент линии регрессии β равен нулю.
Если угловой коэффициент линии равен нулю, между и нет линейного соотношения: изменение не влияет на 
Для тестирования нулевой гипотезы о том, что истинный угловой коэффициент  равен нулю можно воспользоваться следующим алгоритмом:
равен нулю можно воспользоваться следующим алгоритмом:
Вычислить статистику критерия, равную отношению  , которая подчиняется
, которая подчиняется  распределению с
распределению с  степенями свободы, где
степенями свободы, где  стандартная ошибка коэффициента
стандартная ошибка коэффициента 

 ,
,
 — оценка дисперсии остатков.
— оценка дисперсии остатков.
Обычно если достигнутый уровень значимости  нулевая гипотеза отклоняется.
нулевая гипотеза отклоняется.
Можно рассчитать 95% доверительный интервал для генерального углового коэффициента :

где  процентная точка распределения со степенями свободы
процентная точка распределения со степенями свободы  что дает вероятность двустороннего критерия
что дает вероятность двустороннего критерия 
Это тот интервал, который содержит генеральный угловой коэффициент с вероятностью 95%.
Для больших выборок, скажем,  мы можем аппроксимировать
мы можем аппроксимировать  значением 1,96 (то есть статистика критерия будет стремиться к нормальному распределению)
значением 1,96 (то есть статистика критерия будет стремиться к нормальному распределению)
Оценка качества линейной регрессии: коэффициент детерминации R 2
Из-за линейного соотношения и мы ожидаем, что изменяется, по мере того как изменяется , и называем это вариацией, которая обусловлена или объясняется регрессией. Остаточная вариация должна быть как можно меньше.
Если это так, то большая часть вариации будет объясняться регрессией, а точки будут лежать близко к линии регрессии, т.е. линия хорошо соответствует данным.
Долю общей дисперсии , которая объясняется регрессией называют коэффициентом детерминации, обычно выражают через процентное соотношение и обозначают R 2 (в парной линейной регрессии это величина r 2 , квадрат коэффициента корреляции), позволяет субъективно оценить качество уравнения регрессии.
Разность  представляет собой процент дисперсии который нельзя объяснить регрессией.
представляет собой процент дисперсии который нельзя объяснить регрессией.
Нет формального теста для оценки  мы вынуждены положиться на субъективное суждение, чтобы определить качество подгонки линии регрессии.
мы вынуждены положиться на субъективное суждение, чтобы определить качество подгонки линии регрессии.
Применение линии регрессии для прогноза
Можно применять регрессионную линию для прогнозирования значения по значению в пределе наблюдаемого диапазона (никогда не экстраполируйте вне этих пределов).
Мы предсказываем среднюю величину для наблюдаемых, которые имеют определенное значение  путем подстановки этого значения в уравнение линии регрессии.
путем подстановки этого значения в уравнение линии регрессии.
Итак, если  прогнозируем как
прогнозируем как  Используем эту предсказанную величину и ее стандартную ошибку, чтобы оценить доверительный интервал для истинной средней величины в популяции.
Используем эту предсказанную величину и ее стандартную ошибку, чтобы оценить доверительный интервал для истинной средней величины в популяции.
Повторение этой процедуры для различных величин позволяет построить доверительные границы для этой линии. Это полоса или область, которая содержит истинную линию, например, с 95% доверительной вероятностью.
Подобным образом можно рассчитать более широкую область, внутри которой, как мы ожидаем, лежит наибольшее число (обычно 95%) наблюдений.
Простые регрессионные планы
Простые регрессионные планы содержат один непрерывный предиктор. Если существует 3 наблюдения со значениями предиктора P , например, 7, 4 и 9, а план включает эффект первого порядка P , то матрица плана X будет иметь вид

а регрессионное уравнение с использованием P для X1 выглядит как
Если простой регрессионный план содержит эффект высшего порядка для P , например квадратичный эффект, то значения в столбце X1 в матрице плана будут возведены во вторую степень:

а уравнение примет вид
Y = b 0 + b 1 P 2
Сигма -ограниченные и сверхпараметризованные методы кодирования не применяются по отношению к простым регрессионным планам и другим планам, содержащим только непрерывные предикторы (поскольку, просто не существует категориальных предикторов). Независимо от выбранного метода кодирования, значения непрерывных переменных увеличиваются в соответствующей степени и используются как значения для переменных X . При этом перекодировка не выполняется. Кроме того, при описании регрессионных планов можно опустить рассмотрение матрицы плана X , а работать только с регрессионным уравнением.
Пример: простой регрессионный анализ
Этот пример использует данные, представленные в таблице:

Рис. 3. Таблица исходных данных.
Данные составлены на основе сравнения переписей 1960 и 1970 в произвольно выбранных 30 округах. Названия округов представлены в виде имен наблюдений. Информация относительно каждой переменной представлена ниже:

Рис. 4. Таблица спецификаций переменных.
Задача исследования
Для этого примера будут анализироваться корреляция уровня бедности и степень, которая предсказывает процент семей, которые находятся за чертой бедности. Следовательно мы будем трактовать переменную 3 ( Pt_Poor ) как зависимую переменную.
Можно выдвинуть гипотезу: изменение численности населения и процент семей, которые находятся за чертой бедности, связаны между собой. Кажется разумным ожидать, что бедность ведет к оттоку населения, следовательно, здесь будет отрицательная корреляция между процентом людей за чертой бедности и изменением численности населения. Следовательно мы будем трактовать переменную 1 ( Pop_Chng ) как переменную-предиктор.
Просмотр результатов
Коэффициенты регрессии

Рис. 5. Коэффициенты регрессии Pt_Poor на Pop_Chng.
На пересечении строки Pop_Chng и столбца Парам. не стандартизованный коэффициент для регрессии Pt_Poor на Pop_Chng равен -0.40374 . Это означает, что для каждого уменьшения численности населения на единицу, имеется увеличение уровня бедности на .40374. Верхний и нижний (по умолчанию) 95% доверительные пределы для этого не стандартизованного коэффициента не включают ноль, так что коэффициент регрессии значим на уровне p . Обратите внимание на не стандартизованный коэффициент, который также является коэффициентом корреляции Пирсона для простых регрессионных планов, равен -.65, который означает, что для каждого уменьшения стандартного отклонения численности населения происходит увеличение стандартного отклонения уровня бедности на .65.
Распределение переменных
Коэффициенты корреляции могут стать существенно завышены или занижены, если в данных присутствуют большие выбросы. Изучим распределение зависимой переменной Pt_Poor по округам. Для этого построим гистограмму переменной Pt_Poor .

Рис. 6. Гистограмма переменной Pt_Poor.
Как вы можете заметить, распределение этой переменной заметно отличается от нормального распределения. Тем не менее, хотя даже два округа (два правых столбца) имеют высокий процент семей, которые находятся за чертой бедности, чем ожидалось в случае нормального распределения, кажется, что они находятся «внутри диапазона.»

Рис. 7. Гистограмма переменной Pt_Poor.
Это суждение в некоторой степени субъективно. Эмпирическое правило гласит, что выбросы необходимо учитывать, если наблюдение (или наблюдения) не попадают в интервал (среднее ± 3 умноженное на стандартное отклонение). В этом случае стоит повторить анализ с выбросами и без, чтобы убедиться, что они не оказывают серьезного эффекта на корреляцию между членами совокупности.
Диаграмма рассеяния
Если одна из гипотез априори о взаимосвязи между заданными переменными, то ее полезно проверить на графике соответствующей диаграммы рассеяния.

Рис. 8. Диаграмма рассеяния.
Диаграмма рассеяния показывает явную отрицательную корреляцию ( -.65 ) между двумя переменными. На ней также показан 95% доверительный интервал для линии регрессии, т.е., с 95% вероятностью линия регрессии проходит между двумя пунктирными кривыми.
Критерии значимости

Рис. 9. Таблица, содержащая критерии значимости.
Критерий для коэффициента регрессии Pop_Chng подтверждает, что Pop_Chng сильно связано с Pt_Poor , p .
На этом примере было показано, как проанализировать простой регрессионный план. Была также представлена интерпретация не стандартизованных и стандартизованных коэффициентов регрессии. Обсуждена важность изучения распределения откликов зависимой переменной, продемонстрирована техника определения направления и силы взаимосвязи между предиктором и зависимой переменной.
Уравнение регрессии: Что это такое и как его использовать
Уравнение регрессии: Обзор
Уравнение регрессии используется в статистике для того, чтобы выяснить, какая связь, если таковая существует, существует между наборами данных. Например, если каждый год измерять рост ребенка, то можно обнаружить, что он растет примерно на 3 дюйма в год. Эта тенденция (которая растет на 3 дюйма в год) может быть смоделирована с помощью уравнения регрессии. Фактически, большинство вещей в реальном мире (от цен на газ до ураганов) можно смоделировать с помощью некоего уравнения, что позволяет нам предсказывать будущие события.
Линия регрессии – это “самая подходящая” линия для ваших данных. По сути, вы рисуете линию, которая наилучшим образом представляет точки данных. Она представляет собой среднее арифметическое того, где выравниваются все точки. В линейной регрессии линия регрессии является абсолютно прямой линией:
Линия регрессии представлена уравнением. В данном случае уравнение равно -2.2923x + 4624.4. Это означает, что если бы вы строили график уравнения -2.2923x + 4624.4, то линия была бы грубой аппроксимацией для ваших данных.
Не очень распространено, чтобы все точки данных действительно попадали на линию регрессии. На рисунке выше точки немного рассеяны вокруг линии. На следующем изображении точки падают на линию. Изогнутая форма этой линии является результатом полиномиальной регрессии, которая укладывает точки в уравнение полинома.
Уравнение регрессии: Что это такое и как его использовать
Статистические определения > Что такое уравнение регрессии?
Уравнение регрессии: Обзор
Уравнение регрессии используется в статистике для того, чтобы выяснить, какая связь, если таковая существует, существует между наборами данных. Например, если каждый год измерять рост ребенка, то можно обнаружить, что он растет примерно на 3 дюйма в год. Эта тенденция (которая растет на 3 дюйма в год) может быть смоделирована с помощью уравнения регрессии. Фактически, большинство вещей в реальном мире (от цен на газ до ураганов) можно смоделировать с помощью некоего уравнения, что позволяет нам предсказывать будущие события.
Линия регрессии – это “самая подходящая” линия для ваших данных. По сути, вы рисуете линию, которая наилучшим образом представляет точки данных. Она представляет собой среднее арифметическое того, где выравниваются все точки. В линейной регрессии линия регрессии является абсолютно прямой линией:
Линия линейной регрессии.
Линия регрессии представлена уравнением. В данном случае уравнение равно -2.2923x + 4624.4. Это означает, что если построить график уравнения -2.2923x + 4624.4, то линия будет представлять собой грубую аппроксимацию для Ваших данных.
Не очень распространено, чтобы все точки данных действительно попадали на линию регрессии. На рисунке выше точки немного рассеяны вокруг линии. На следующем изображении точки падают на линию. Изогнутая форма этой линии является результатом полиномиальной регрессии, которая укладывает точки в уравнение полинома.
В результате полиномиальной регрессии получается кривая линия.
Результатом полиномиальной регрессии является кривая линия.
Регрессия и линии прогнозирования
Регрессия полезна, так как позволяет делать прогнозы о данных. Первый график выше – с 1995 по 2015 год. Если вы хотите предсказать, что произойдет в 2020 году, вы можете поместить его в уравнение:
Отрицательное выпадение осадков не имеет особого смысла, но можно сказать, что до 2020 года осадки выпадут на 0 дюймов. Согласно этой конкретной линии регрессии, рано или поздно это произойдет в 2018 году:
Для чего нужно уравнение регрессии?
Уравнения регрессии могут помочь вам понять, подходят ли ваши данные для уравнения. Это чрезвычайно полезно, если вы хотите сделать прогноз на основе своих данных – как будущих прогнозов, так и указаний на прошлое поведение. Например, вы можете захотеть узнать, сколько ваших сбережений будет стоить в будущем. Или, возможно, вы захотите предсказать, сколько времени понадобится на выздоровление от болезни.
Существуют различные типы уравнений регрессии. К наиболее распространенным относятся экспоненциальная линейная регрессия и простая линейная регрессия (для адаптации данных к экспоненциальному уравнению или линейному уравнению). В элементарной статистике уравнение регрессии, с которым вы, скорее всего, столкнетесь, является линейной формой.
Расчет линейной регрессии
Есть несколько способов найти линию регрессии, даже вручную и с помощью технологий, таких как Excel (см. ниже). Поиск линии регрессии очень скучен вручную. Следующее видео иллюстрирует шаги:
Линию регрессии также можно найти в калькуляторах TI:
TI 83 Регрессия.
Как выполнять регрессию TI-89.
Уравнение линейной регрессии показано ниже.
Для того, чтобы данные вписались в уравнение, необходимо сначала понять, какая общая схема подходит для данных. Общие шаги для выполнения регрессии включают в себя составление дисперсионной диаграммы, а затем гипотезу о том, какой тип уравнения может быть наиболее подходящим. Затем можно выбрать наилучшее уравнение регрессии для задания.
Однако, как видно на следующем рисунке, не всегда легко выбрать подходящее уравнение регрессии, особенно при работе с реальными данными. Иногда получаются “шумные” данные, которые, кажется, не подходят ни под одно уравнение. Если большинство данных, кажется, следуют шаблону, вы можете пропустить пропуски. На самом деле, если игнорировать промахи, данные, кажется, моделируются экспоненциальным уравнением.
http://statistica.ru/theory/osnovy-lineynoy-regressii/
http://datascience.eu/ru/%D0%BC%D0%B0%D1%82%D0%B5%D0%BC%D0%B0%D1%82%D0%B8%D0%BA%D0%B0-%D0%B8-%D1%81%D1%82%D0%B0%D1%82%D0%B8%D1%81%D1%82%D0%B8%D0%BA%D0%B0/%D1%83%D1%80%D0%B0%D0%B2%D0%BD%D0%B5%D0%BD%D0%B8%D0%B5-%D1%80%D0%B5%D0%B3%D1%80%D0%B5%D1%81%D1%81%D0%B8%D0%B8-%D1%87%D1%82%D0%BE-%D1%8D%D1%82%D0%BE-%D1%82%D0%B0%D0%BA%D0%BE%D0%B5-%D0%B8-%D0%BA%D0%B0/