Please wait.
We are checking your browser. medium.com
Why do I have to complete a CAPTCHA?
Completing the CAPTCHA proves you are a human and gives you temporary access to the web property.
What can I do to prevent this in the future?
If you are on a personal connection, like at home, you can run an anti-virus scan on your device to make sure it is not infected with malware.
If you are at an office or shared network, you can ask the network administrator to run a scan across the network looking for misconfigured or infected devices.
Cloudflare Ray ID: 6e029f964a4b3a71 • Your IP : 85.95.188.35 • Performance & security by Cloudflare
Лекция по эконометрике. Лекция по эконометрике
| Название | Лекция по эконометрике |
| Дата | 21.06.2018 |
| Размер | 1.32 Mb. |
| Формат файла |  |
| Имя файла | Лекция по эконометрике.docx |
| Тип | Лекция #47509 |
| страница | 2 из 5 |
 С этим файлом связано 6 файл(ов). Среди них: ЭКОНО Задача.docx, СТАТ в жив. Лекция №9.docx, Вопросы по АВтоматике.docx, ЛЕКЦИЯ СОЦ.СТАТ..doc, доступность к прдовольствию.pdf, Лекция по эконометрике.docx. Показать все связанные файлы Подборка по базе: 1. Лекция Особенности макетирования и верстки длинных документов, Медицинская статистика Лекция проф.Виноградова К.А.(1).pptx, 6 лекция Отбасы.ppt, 9-10 Лекция дуниетану.ppt, такт 5 лекция.doc, Тест к лекциям.doc, 3 лекция. куиз.docx, 3 лекция.pptx, антибиотики лекция.docx, ТПЭФМ_Практическое занятие 1_между лекциями 11 и 12.doc С этим файлом связано 6 файл(ов). Среди них: ЭКОНО Задача.docx, СТАТ в жив. Лекция №9.docx, Вопросы по АВтоматике.docx, ЛЕКЦИЯ СОЦ.СТАТ..doc, доступность к прдовольствию.pdf, Лекция по эконометрике.docx. Показать все связанные файлы Подборка по базе: 1. Лекция Особенности макетирования и верстки длинных документов, Медицинская статистика Лекция проф.Виноградова К.А.(1).pptx, 6 лекция Отбасы.ppt, 9-10 Лекция дуниетану.ppt, такт 5 лекция.doc, Тест к лекциям.doc, 3 лекция. куиз.docx, 3 лекция.pptx, антибиотики лекция.docx, ТПЭФМ_Практическое занятие 1_между лекциями 11 и 12.doc2.1 Оценка общего качества уравнения регрессии
Коэффициент детерминации характеризует долю вариации (разброса) зависимой переменной, объяснённой с помощью данного уравнения. Замечание. В случае парной линейной регрессии коэффициент детерминации равен квадрату коэффициента линейной корреляции. Более точным является значение коэффициента детерминации с поправкой на число степеней свободы. Разделив каждую СКО на свое число степеней свободы, получим средний квадрат отклонений, или дисперсию на одну степень свободы: Учитывая приведённые выше обозначения, формула коэффициента детерминации с поправкой на число степеней свободы будет иметь вид: Близость коэффициента детерминации к +1 свидетельствует о том, что существует статистически значимая линейная связь между переменными, а уравнение имеет хорошее качество. Близость Самостоятельную важность коэффициент детерминации приобретает только в случае множественной регрессии. Проверить значимость уравнения регрессии – значит установить, соответствует ли математическая модель, выражающая зависимость между переменными, экспериментальным данным и достаточно ли включённых в уравнение объясняющих переменных (одной или нескольких) для описания зависимой переменной. Проверка значимости производится на основе дисперсионного анализа. Согласно идее дисперсионного анализа, общая сумма квадратов отклонений (СКО) y от среднего значения
В первом случае фактор х не оказывает влияния на результат, вся дисперсия y обусловлена воздействием прочих факторов, линия регрессии параллельна оси Ох и уравнение должно иметь вид Во втором случае прочие факторы не влияют на результат, y связан с x функционально, и остаточная СКО равна нулю. Однако на практике в правой части присутствуют оба слагаемых. Пригодность линии регрессии для прогноза зависит от того, какая часть общей вариации y приходится на объясненную вариацию. Если объясненная СКО будет больше остаточной СКО, то уравнение регрессии статистически значимо и фактор х оказывает существенное воздействие на результат y. Это равносильно тому, что коэффициент детерминации будет приближаться к единице. Число степеней свободы (df-degrees of freedom) – это число независимо варьируемых значений признака. Для общей СКО требуется (n-1) независимых отклонений, Из этого баланса определяем, что Разделив каждую СКО на свое число степеней свободы, получим средний квадрат отклонений, или дисперсию на одну степень свободы: Анализ статистической значимости коэффициентов линейной регрессии Хотя теоретические значения коэффициентов Дисперсии коэффициентов рассчитываются по формулам: Дисперсия коэффициента регрессии Дисперсия параметра Альтернативная гипотеза имеет вид: t – статистики имеют t – распределение Стьюдента с Если Если Интервальные оценки коэффициентов линейного уравнения регрессии: Доверительный интервал для а: Доверительный интервал для b: Это означает, что с заданной надёжностью Коэффициент регрессии имеет четкую экономическую интерпретацию, поэтому доверительные границы интервала не должны содержать противоречивых результатов, например, Анализ статистической значимости уравнения в целом. Распределение Фишера в регрессионном анализе Оценка значимости уравнения регрессии в целом дается с помощью F- критерия Фишера. При этом выдвигается нулевая гипотеза Величина F – критерия связана с коэффициентом детерминации. В случае множественной регрессии: В случае парной регрессии формула F – статистики принимает вид: Если Если Замечание. В парной линейной регрессии Распределение Фишера может быть использовано не только для проверки гипотезы об одновременном равенстве нулю всех коэффициентов линейной регрессии, но и гипотезы о равенстве нулю части этих коэффициентов. Это важно при развитии линейной регрессионной модели, так как позволяет оценить обоснованность исключения отдельных переменных или их групп из числа объясняющих переменных, или же, наоборот, включения их в это число. Пусть, например, вначале была оценена множественная линейная регрессия Для того, чтобы проверить гипотезу об одновременном равенстве нулю всех коэффициентов при исключённых переменных, рассчитывается величина По таблицам распределения Фишера, при заданном уровне значимости, находят Аналогичные рассуждения могут быть проведены и по поводу обоснованности включения в уравнение регрессии одной или нескольких k новых объясняющих переменных. В этом случае рассчитывается F – статистика Замечания. 1. Включать новые переменные целесообразно по одной. 2. Для расчёта F – статистики при рассмотрении вопроса о включении объясняющих переменных в уравнение желательно рассматривать коэффициент детерминации с поправкой на число степеней свободы. F – статистика Фишера используется также для проверки гипотезы о совпадении уравнений регрессии для отдельных групп наблюдений. Пусть имеются 2 выборки, содержащие, соответственно, Проверяется нулевая гипотеза Пусть оценено уравнение регрессии того же вида сразу для всех Тогда рассчитывается F – статистика по формуле: Если же Предпосылками МНК являются: 1. случайный характер ошибок регрессии; 2. нулевая средняя величина ошибок регрессии, не зависящая от значения объясняющих переменных; 3. независимость распределения ошибок для различных наблюдений; в случае оценки уравнения на временных рядах – отсутствие автокорреляции ошибок; 4. постоянство дисперсии ошибок, её независимость от значений объясняющих переменных – гомоскедастичность (если эта предпосылка не выполняется, то имеет место гетероскедастичность ошибок); 5. нормальность распределения ошибок регрессии. Для проверки выполнения каждой из предпосылок применения МНК имеются специальные тесты. Реализация многих из этих тестов предполагает значительный объём исходных данных. Если распределение случайных ошибок Проверка первой предпосылки МНК Прежде всего, проверяется случайный характер остатков Рис. 1. Зависимость случайных остатков Рис. 2. Зависимость случайных остатков Проверка второй предпосылки МНК Вторая предпосылка МНК относительно нулевой средней величины остатков означает, что Вместе с тем, несмещенность оценок коэффициентов регрессии, полученных МНК, зависит от независимости случайных остатков и величин Рис. .3. Зависимость величины остатков от величины фактора Замечание. Предпосылка о нормальном распределении остатков (пятая предпосылка) позволяет проводить проверку параметров регрессии и корреляции с помощью Совершенно необходимым для получения по МНК состоятельных оценок параметров регрессии является соблюдение третьей и четвертой предпосылок. Автокорреляция ошибок. Статистика Дарбина-Уотсона Важной предпосылкой построения качественной регрессионной модели по МНК является независимость значений случайных отклонений Автокорреляция (последовательная корреляция) остатков определяется как корреляция между соседними значениями случайных отклонений во времени (временные ряды) или в пространстве (перекрестные данные). Она обычно встречается во временных рядах и очень редко – в пространственных данных. Возможны следующие случаи: В экономических задачах значительно чаще встречается положительная автокорреляция, чем отрицательная автокорреляция. Если же характер отклонений случаен, то можно предположить, что в половине случаев знаки соседних отклонений совпадают, а в половине – различны. Автокорреляция в остатках может быть вызвана несколькими причинами, имеющими различную природу.
От истинной автокорреляции остатков следует отличать ситуации, когда причина автокорреляции заключается в неправильной спецификации функциональной формы модели. В этом случае следует изменить форму модели, а не использовать специальные методы расчета параметров уравнения регрессии при наличии автокорреляции в остатках. Для обнаружения автокорреляции используют либо графический метод. Либо статистические тесты. Графический метод заключается в построении графика зависимости ошибок от времени (в случае временных рядов) или от объясняющих переменных и визуальном определении наличия или отсутствия автокорреляции. Наиболее известный критерий обнаружения автокорреляции первого порядка – критерий Дарбина-Уотсона. Статистика DW Дарбина-Уотсона приводится во всех специальных компьютерных программах как одна из важнейших характеристик качества регрессионной модели. Сначала по построенному эмпирическому уравнению регрессии определяются значения отклонений
Можно показать, что статистика DW тесно связана с коэффициентом автокорреляции первого порядка: При отсутствии таблиц критических значений DW можно использовать следующее «грубое» правило: при достаточном числе наблюдений (12-15), при 1-3 объясняющих переменных, если Либо применить к данным уменьшающее автокорреляцию преобразование (например автокорреляционное преобразование или метод скользящих средних). Существует несколько ограничений на применение критерия Дарбина-Уотсона.
Для авторегрессионных моделей предлагается h – статистика Дарбина Обычно значение Методы устранения автокорреляции. Авторегрессионное преобразование В случае наличия автокорреляции остатков полученная формула регрессии обычно считается неудовлетворительной. Автокорреляция ошибок первого порядка говорит о неверной спецификации модели. Поэтому следует попытаться скорректировать саму модель. Посмотрев на график ошибок, можно поискать другую (нелинейную) формулу зависимости, включить неучтённые до этого факторы, уточнить период проведения расчётов или разбить его на части. Если все эти способы не помогают и автокорреляция вызвана какими–то внутренними свойствами ряда Формула AR(1) имеет вид: Рассмотрим AR(1) на примере парной регрессии: Сделаем замены переменных Поскольку случайные отклонения Т.о. если остатки по исходному уравнению регрессии автокоррелированы, то для оценки параметров уравнения используют следующие преобразования: 1) Преобразовать исходные переменные у и х к виду (3), (4). 2) Обычным МНК для уравнения (6) определить оценки а * и b. 3) Рассчитать параметр а исходного уравнения из соотношения (4) 4) Записать исходное уравнение (1) с параметрами а и b (где а — из п.3, а b берётся непосредственно из уравнения (6)). Авторегрессионное преобразование может быть обобщено на произвольное число объясняющих переменных, т.е. использовано для уравнения множественной регрессии. Для преобразования AR(1) важно оценить коэффициент автокорреляции ρ. Это делается несколькими способами. Самое простое – оценить ρ на основе статистики DW: В случае, когда есть основания считать, что положительная автокорреляция отклонений очень велика (
В случае полной отрицательной автокорреляции отклонений ( Вычисляются средние за 2 периода, а затем по ним рассчитывают а и b. Данная модель называется моделью регрессии по скользящим средним. Проверка гомоскедастичности дисперсии ошибок В соответствии с четвёртой предпосылкой МНК требуется, чтобы дисперсия остатков была гомоскедастичной. Это значит, что для каждого значения фактора В качестве примера реальной гетероскедастичности можно привести то, что люди с большим доходом не только тратят в среднем больше, чем люди с меньшим доходом, но и разброс в их потреблении также больше, поскольку они имеют больше простора для распределения дохода. Наличие гетероскедастичности можно наглядно видеть из поля корреляции (- графический метод обнаружения гетероскедастичности).
При нарушении гомоскедастичности имеем неравенства: Задача состоит в том, чтобы определить величину Чтобы убедиться в обоснованности использования обобщённого МНК проводят эмпирическое подтверждение наличия гетероскедастичности. При малом объёме выборки, что наиболее характерно для эмпирических исследований, для оценки гетероскедастичности может использоваться метод Гольдфельда-Квандта (в 1965 г. они рассмотрели модель парной линейной регрессии, в которой дисперсия ошибок пропорциональна квадрату фактора). Пусть рассматривается модель, в которой дисперсия Параметрический тест (критерий) Гольдфельда – Квандта: 1. Все n наблюдений в выборке упорядочиваются по величине x. 2. Вся упорядоченная выборка разбивается на три подвыборки (объёмом k, С, k.) 3. Оцениваются отдельные регрессии для первой подвыборки (k первых наблюдений) и для последней подвыборки (k последних наблюдений). 4. Определяются остаточные суммы квадратов 5. Выдвигается нулевая гипотеза Для проверки этой гипотезы рассчитывается отношение Если Этот же тест может быть использован и при предположении об обратной пропорциональности между дисперсией и значениями объясняющей переменной При нарушении гомоскедастичности и наличии автокорреляции ошибок рекомендуется традиционный метод наименьших квадратов заменять обобщенным методом наименьших квадратов (ОМНК). Обобщенный метод наименьших квадратов применяется к преобразованным данным и позволяет получать оценки, которые обладают не только свойством несмещенности, но и имеют меньшие выборочные дисперсии. Остановимся на использовании ОМНК для корректировки гетероскедастичности. Рассмотрим ОМНК для корректировки гетероскедастичности. Будем предполагать, что среднее значение остаточных величин равно нулю
При этом предполагается, что В общем виде для уравнения Иными словами, от регрессии Оценка параметров нового уравнения с преобразованными переменными приводит к взвешенному методу наименьших квадратов, для которого необходимо минимизировать сумму квадратов отклонений вида
Если преобразованные переменные Аналогичный подход возможен не только для уравнения парной, но и для множественной регрессии. Для применения ОМНК необходимо знать фактические значения дисперсий отклонений Если предположить, что дисперсии пропорциональны значениям фактора x, т.е.
Если предположить, что дисперсии В полученной регрессии по сравнению с исходным уравнением параметры поменялись ролями: свободный член а стал коэффициентом, а коэффициент b – свободным членом. Применяя обычный МНК в преобразованных переменных
Пример. Рассматривая зависимость сбережений В случае множественной регрессии Если предположить Следует иметь в виду, что новые преобразованные переменные получают новое экономическое содержание и их регрессия имеет иной смысл, чем регрессия по исходным данным. Пример. Пусть Если предположить, что в модели с первоначальными переменными дисперсия остатков пропорциональна квадрату объема продукции, В заключение следует отметить, что обнаружении гетероскедастичности и её корректировка являются весьма серьёзной и трудоёмкой проблемой. В случае применения обобщённого (взвешенного) МНК необходима определённая информация или обоснованные предположения о величинах Прогнозирование. Регрессионный анализ, его реализация и прогнозированиеМЕТОДИЧЕСКИЕ РЕКОМЕНДАЦИИСущность метода регрессионного анализаОдним из методов, используемых для прогнозирования, является регрессионный анализ. Регрессия – это статистический метод, который позволяет найти уравнение, наилучшим образом описывающее совокупность данных, заданных таблицей.
На графике данные отображаются точками. Регрессия позволяет подобрать к этим точкам кривую у=f(x), которая вычисляется по методу наименьших квадратов и даёт максимальное приближение к табличным данным. По полученному уравнению можно вычислить (сделать прогноз) значение функции у для любого значения х , как внутри интервала изменения х из таблицы(интерполяция), так и вне его (экстраполяция). Линейная регрессияЛинейная регрессия дает возможность наилучшим образом провести прямую линию через точки одномерного массива данных (рис.13.1 а). Уравнение с одной независимой переменной, описывающее прямую линию, имеет вид:
где:x – независимая переменная; y – зависимая переменная; m – характеристика наклона прямой; b – точка пересечения прямой с осью у. Например, имея данные о реализации товаров за год с помощью линейной регрессии можно получить коэффициенты прямой (1) и, предполагая дальнейший линейный рост, получить прогноз реализации на следующий год. Нелинейная регрессияНелинейная регрессия позволяет подбирать к табличным данным нелинейное уравнение (рис. 13.1 рис. 13.1, б.) – параболу, гиперболу и др. Excel реализует нелинейность в виде экспоненты, т.е. подбирает кривую вида:
которая позволяет наилучшим образом провести экспоненциальную кривую по точкам данных, которые изменяются нелинейно. Так, например, данные о росте населения почти всегда лучше описываются не прямой линией, а экспоненциальной кривой. При этом нужно помнить, что достоверное прогнозирование возможно только на участках подъёма или спуска кривой (при отрицательных значениях х), т.к. сама кривая (2) изменяется монотонно, без точек перегиба. Например, делать экспоненциальный прогноз для функции, изменяющейся синусоидально, можно только на участках подъёма или спуска функции, для чего её разбивают на соответствующие интервалы. Множественная регрессияМножественная регрессия представляет собой анализ более одного набора данных аргумента х и даёт более реалистичные результаты. Множественный регрессионный анализ также может быть как линейным, так и экспоненциальным. Уравнение регрессии (1) и (2) примут соответственно вид (3) и (4):
С помощью множественной регрессии, например, можно оценить стоимость дома в некотором районе, основываясь на данных его площади, размерах участка земли, этажности, вида из окон и т.д. Использование функций регрессииВ Excel имеется 5 функций для линейной регрессии: ЛИНЕЙН(…)(LINEST), ТЕНДЕНЦИЯ(…), ПРЕДСКАЗ(…), НАКЛОН(…), СТОШУХ(…)) и 2 функции для экспоненциальной регрессии – ЛГРФПРИБЛ(…) и РОСТ(…). Рассмотрим некоторые из них. Функция ЛИНЕЙН((LINEST) вычисляет коэффициент m и постоянную b для уравнения прямой (1). Синтаксис функции: Известные_значения_у и известные_значения_х – это множество значений у и необязательное множество значений х (их вводить необязательно), которые уже известны для соотношения (1). Константа – это логическое значение, которое указывает, требуется ли, чтобы константа b была равна 0. Если константа имеет значение ИСТИНА или опущено, то b вычисляется обычным образом. Статистика – это логическое значение, которое указывает требуется ли вывести дополнительную статистику по регрессии. Если статистика имеет значение ЛОЖЬ (или 0), то функция ЛИНЕЙН возвращает только значения коэффициентов m и b , в противном случае выводится дополнительная регрессионная статистика в виде табл. 13.1 таблица 13.1:
где: se1 , se2,…,sen – стандартные значения ошибок для коэффициентов m1 , m2,…, mn ; seb – стандартное значение ошибки для постоянной b (seb равно #Н/Д, т.е. «нет допустимого значения», если конст. имеет значение ЛОЖЬ); r 2 – коэффициент детерминированности. Сравниваются фактические значения у и значения, получаемые из уравнения прямой; по результатам сравнения вычисляется коэффициент детерминированности, нормированный от 0 до 1. Если он равен 1, то имеет место полная корреляция с моделью, т.е. нет различия между фактическим и оценочным значениями у. В противоположном случае, если коэффициент детерминированности равен 0, то уравнение регрессии неудачно для предсказания значений у; sey – стандартная ошибка для оценки у (предельное отклонение для у); F – F-cтатистика, или F-наблюдаемое значение. Она используется для определения того, является ли наблюдаемая взаимосвязь между зависимой и независимой переменными случайной или нет; df – степени свободы. Степени свободы полезны для нахождения F-критических значений в статистической таблице. Для определения уровня надёжности модели нужно сравнить значения в таблице с F-статистикой, возвращаемой функцией ЛИНЕЙН; ssreg – регрессионная сумма квадратов; ssresid – остаточная сумма квадратов; #Н/Д – ошибка, означающая «нет доступного значения». Любую прямую можно задать её наклоном m и у-пересечением: Наклон ( m ). Для того, чтобы определить наклон прямой, обычно обозначаемый через m , нужно взять 2 точки прямой (х1,у1) и (х2,у2); тогда наклон равен m=(y2-y1)/(x2-x1 ). у-пересечение ( b ) прямой, обычно обозначаемое через b , является значение у для точки, в которой прямая пересекает ось у. Уравнение прямой имеет вид: у=mx+b. Если известны значения m и b , то можно вычислить любую точку на прямой, подставляя значения у или х в уравнение. Можно также использовать функцию ТЕНДЕНЦИЯ ( TREND ) (см. ниже). Если для функции у имеется только одна независимая переменная х, можно получить наклон и у-пересечение непосредственно, используя следующие формулы: Точность аппроксимации с помощью прямой, вычисленной функцией ЛИНЕЙН, зависит от степени разброса данных. Чем ближе данные к прямой, тем более точными являются модель, используемая функцией ЛИНЕЙН, и значения, получаемые из уравнения прямой. В случае экспоненциальной регрессии аналогом функции (5) является функция ЛГРФПРИБЛ(LOGEST): которая отличается лишь тем, что вычисляет коэффициенты m и b для экспоненциальной кривой (2). Функция ТЕНДЕНЦИЯ(TREND) имеет вид: возвращает числовые значения, лежащие на прямой линии, наилучшим образом аппроксимирующие известные табличные данные. Новые_значения_х – это те, для которых необходимо вычислить соответствующие значения у. Если параметр новые_значения_х пропущен, то считается, что он совпадает с известными х. Назначение остальных параметров функции ТЕНДЕНЦИЯ совпадает с описанными выше. В случае экспоненциальной регрессии аналогом функции (7) является функция РОСТ(GROWTH): возвращает стандартную погрешность регрессии – меру погрешности предсказываемого значения у для заданного значения х. Правила ввода функцийФормулы(5)-(8) являются табличными, т.е. они заменяют собой несколько обычных формул и возвращают не один результат, а массив результатов. Поэтому необходимо соблюдать следующие правила:
Линия трендаExcel позволяет наглядно отображать тенденцию данных с помощью линии тренда, которая представляет собой интерполяционную кривую, описывающую отложенные на диаграмме данные. Для того, чтобы дополнить диаграмму исходных данных линией тренда, необходимо выполнить следующие действия:
Чтобы отобразить на графике (гистограмме и др.) новые, прогнозируемые в результате регрессионного анализа данные, нужно:
На диаграмме появится продолжение кривой, построенной по новым данным. Простая линейная регрессияПример 1. Функция ТЕНДЕНЦИЯ(TREND)а) Предположим, что фирма может приобрести земельный участок в июле. Фирма собирает информацию о ценах за последние 12 месяцев, начиная с марта, на типичный земельный участок. Название первого столбца «Месяц» с данными о номерах месяцев записано в ячейке А1, а второго столбца «Цена» – в ячейке В1. Номера месяцев с 1 по 12 (известные значения х) записаны в ячейки А2…А13. Известные значения у содержат множество известных значений (133 890 руб., 135 000 руб., 135 790 руб., 137 300 руб., 138 130 руб., 139 100 руб., 139 900 руб., 141 120 руб., 141 890 руб., 143 230 руб., 144 000 руб., 145 290 руб.), которые находятся в ячейках В2;В13 соответственно (данные условия). Новые значения х, т.е. числа 13, 14,15,16,17 введём в ячейки А14…А18. Для того чтобы определить ожидаемые значения цен на март, апрель, май, июнь, июль, выделим любой интервал ячеек, например, B14:B18 (по одной ячейке для каждого месяца) и в строке формул введем функцию: После нажатия клавиш Ctrl+ Shift+Enter данная функция будет выделена как формула вертикального массива, а в ячейках B14:B18 появится результат: <146172;174190;148208;149226;150244>. Таким образом, в июле фирма может ожидать цену около 150 244 руб. б) Тот же результат будет получен, если вводить в формулу не все массивы переменных х и у, а использовать часть массивов, которые предусматриваются автоматически по умолчанию. Тогда формула (10) примет вид: В формуле (11) используется массив по умолчанию (1:2:3:4:5:6:7:8:9:10:11:12) для аргумента «известные_значения_х», соответствующий 12 месяцам, для которых имеются данные по продажам. Он должен был бы быть помещен в формуле (11) между двумя знаками ;;. Массив (13:14:15:16:17) соответствует следующим 5 месяцам, для которых и получен массив результатов (146172:147190:148208:149226:150244). Элементы массивов разделяет знак «:», который указывает на то, что они расположены по столбцам. в) Аргумент «новые значения х» можно задать другим массивом ячеек, например, В14:В18, в которые предварительно записаны те же номера месяцев 13,14,15,16,17. Тогда вводимая в строку формул функция примет вид =ТЕНДЕНЦИЯ(В2:В13;;В14:В18). Пример 2. Функция ЛИНЕЙНа) Дана таблица изменения температуры в течение шести часов, введённая в ячейки D2 :E7 (табл. 13.2 таблица 13.2). Требуется определить температуру во время восьмого часа.
Выделим ячейки D8:E12 для вывода результата, введем в строку ввода формулу =ЛИНЕЙН(Е2:Е7;D2:D7;1;1), нажмем клавиши Сtrl+Shift+Enter, в выделенных ячейках появится результат:
Таким образом, коэффициент m=3,143 со стандартной ошибкой 0,541, а свободный член b=-3,333 со стандартной ошибкой 2,106, т.е. функция, описывающая данные табл. 13.2 таблица 13.2, имеет вид Стандартные ошибки показывают максимально возможное отклонение параметра от рассчитанной величины. Для у оно составляет 2,263, т.е. реальное значение у может лежать в пределах Точность приближения к табличным данным (коэффициент детерминированности r 2 ) составляет 0,894 или 89,4%, что является высоким показателем. При х=8 получим: у=3,143*8-3,333=21,81 град. б) Тот же результат можно получить, использовав функцию =ТЕНДЕНЦИЯ(Е2:Е7;;G2:G5) для, например, следующих четырёх часов, предварительно введя в ячейки G2 :G5 числа с 7 до 10. Выделив ячейки Н2:Н5, введя в строку формул эту функцию и нажав Сtrl+Shift+Enter, получим в выделенных ячейках массив <18,667;21,80952;24,95238;28,09524>, т.е. для восьмого часа значение в) Функция ПРЕДСКАЗ ( FORECAST ) – позволяет предсказать значение у для нового значения х по известным значениям х и у, используя линейное приближение зависимости у=f(x). Для данных примера 2 ввод формулы =ПРЕДСКАЗ(8;Е2:Е7;D2:D7) выводит в заранее выделенной ячейке результат 21,809. Новое значение х может быть задано не числом, а ячейкой, в которую записано это число. Отличие функции ПРЕДСКАЗ от функции ТЕНДЕНЦИЯ заключается в том, что ПРЕДСКАЗ прогнозирует значения функции линейного приближения только для одного нового значения х. Экспоненциальная регрессияПример 3а) Функция ЛГРФПРИБЛ. Рассмотрим условие примера 2. Поскольку функция в табл. 13.2 таблица 13.2 носит явно нелинейный характер, целесообразно искать ее приближение в виде не прямой линии, как в примере 2, а в виде нелинейной кривой. Из всех видов нелинейности (гипербола, парабола, и др.) Excel реализует только экспоненциальное приближение вида у=b*mx c помощью функции ЛГРФПРИБЛ, которая рассчитывает для этого уравнения значения b и m . Выделим для результата блок ячеек F8:G12 , введём в строку формул Функцию =ЛГРФПРИБЛ(Е2:Е7;D2:D7;1;1), нажмем клавиши Сtrl+Shift+Enter, в выделенных ячейках появится результат:
Таким образом, коэффициент m=1,566, а b=1,197, т.е. уравнение приближающей кривой имеет вид:
со стандартными ошибками для m, b , и у равными 0,02, 0,079 и 0,085 соответственно. Коэффициент детерминированности r 2 =0,992, т.е. полученное уравнение даёт совпадение с табличными данными с вероятностью 99,2%. Поскольку интерполяция табл. 13.2 таблица 13.2 экспоненциальной кривой даёт более точное приближение (99,2%) и с меньшими стандартными ошибками для m, b и у, в качестве приближающего уравнения принимаем уравнение (13). При х=8 получим у=1,197*34,363=41,131 град. б) Функция РОСТ вычисляет прогнозируемое по экспоненциальному приближению значение у для новых значений х, имеет формат: Выделим блок ячеек F14: F17 , введём формулу =РОСТ(Е2:Е7;D2:D7;G2:G5;ИСТИНА), в выделенных ячейках появится массив чисел <27,6696434;43,3384133;67,8800967;106,319248>, т.е. при х=8 значение функции у=43,34 град. Это значение немного отличается от вычисленного в п. а), поскольку функция РОСТ использует для расчетов линию экспонециального тренда. Примечание. При выборе экспоненциальной приближающей кривой следует учитывать, что интерполировать ею можно только участки, где функция монотонно возрастает или убывает (при отрицательном аргументе х), т.е. функцию, имеющую точки перегиба (например, параболу, синусоиду, кривую рис. 2 – т. А и др.) следует разбить на участки монотонного изменения от одной точки перегиба до другой и каждый участок интерполировать отдельно. Для рисунка 2 функцию нужно разбить на 2 участка – от начала до т. А и от т. А до конца кривой. Множественная линейная регрессияПример 4Предположим, что коммерческий агент рассматривает возможность закупки небольших зданий под офисы в традиционном деловом районе. Агент может использовать множественный регрессионный анализ для оценки цены здания под офис на основе следующих переменных: у – оценочная цена здания под офис; х1 – общая площадь в квадратных метрах; х2 – количество офисов; х3 – количество входов; х4 – время эксплуатации здания в годах. Агент наугад выбирает 11 зданий из имеющихся 1500 и получает следующие данные:
«Пол-входа» означает вход только для доставки корреспонденции. В этом примере предполагается, что существует линейная зависимость между каждой независимой переменной (х1,х2,х3,х4) и зависимой переменной (у), т.е. ценой зданий под офис в данном районе.
Уравнение множественной регрессии
Теперь агент может определить оценочную стоимость здания под офис в том же районе, которое имеет площадь 2500 м 2 , три офиса, два входа, зданию 25 лет, используя следующее уравнение:
Это значение может быть вычислено с помощью функции ТЕНДЕНЦИЯ: При интерполяции с помощью функции для получения уравнения множественной экспоненциальной регрессии выводится результат:
Коэффициент детерминированности здесь составляет 0,992 (99,2%), т.е. меньше, чем при линейной интерполяции, поэтому в качестве основного следует оставить уравнение множественной регрессии (14). Таким образом, функции ЛИНЕЙН, ЛГРФПРИБЛ, НАКЛОН определяют коэффициенты, свободные члены и статистические параметры для уравнений одномерной и множественной регрессии, а функции ТЕНДЕНЦИЯ, ПРЕДСКАЗ, РОСТ позволяют получить прогноз новых значений без составления уравнения регрессии по значениям тренда. ЗАДАНИЕВариант задания к данной лабораторной работе включает две задачи. Для каждой из них необходимо составить и определить:
Варианты заданий (номер варианта соответствует номеру компьютера).
Для выполнения задания нужно ввести ряд из 12 ячеек с ценами конкурирующей фирмы, сделать прогноз цены на следующий месяц и др. (см. Задание).
Для выполнения задания нужно составить таблицу со столбцами вида:
и сделать множественный регрессионный прогноз (см. Задание).
Для выполнения задания нужно составить таблицу вида:
и получить два уравнения – у=f(x1) и у=f(x2), сделать прогноз на следующий год для рядов х1, х2, у и др. (см. Задание).
Исходные данные нужно ввести в таблицу вида:
Массив ячеек В2-F6 заполняется произвольными числами от 0 до 1, столбец G2 -G6 – процентами удачных сделок по принципу «Чем выше уровень качеств агента, тем выше эффективность его работы», в ячейке G7 должна быть формула для вычисления среднего значения ячеек G2:G6 , в ячейке G8 нужно вычислить значение эффективности для среднего агента по формуле, полученной в результате множественного регрессионного анализа работы пяти агентов. Остальные пункты – см. Задание.
Для выполнения задания нужно составить и заполнить таблицу вида:
сделать прогноз продаж на новый квартал и выполнить другие пункты задания.
Для выполнения задания нужно составить таблицу вида:
и заполнить ячейки за 12 месяцев условными данными. По этим данным нужно сделать линейный и экспоненциальный прогноз и др. (см. Задание).
Для выполнения задания нужно составить таблицу вида:
Для выполнения задания нужно составить таблицу вида:
и сделать линейный прогноз на следующие 6 месяцев и др. (см. Задание).
Для выполнения задания нужно составить и заполнить таблицу вида:
и выполнить применительно к таблице пункты Задания.
Для выполнения задания нужно составить и заполнить таблицу вида
В ячейках столбца
Проанализируйте, связано ли увеличение спроса на матричные принтеры с уменьшением спроса на струйные и лазерные.
Необходимо сделать прогноз на седьмой месяц по уравнению у1=f(x1,z1), получить уравнение y=(у2,x2, z2, у3, x3, z2 ) и проанализировать его. Если слагаемые у2 и у3 входят в регрессионное уравнение со знаком «-«, то уменьшение спросов у2 и у3 ведёт к увеличению спроса у1.
Пользуясь данными таблицы
необходимо сделать прогноз при заданных характеристиках.
Эффективность определяется как сделки/звонки. Сделать линейный и экспоненциальный прогнозы по обоим изданиям.
Пользуясь данными таблицы
сделать прогноз и выполнить другие пункты задания.
В строке «Контакт» в ячейках С8 и D8 должны быть записаны формулы = С7/В7 и =Е7/D7 соответственно, вычисляющие стоимость 1 мин. Эфира для одного слушателя в прогнозируемом месяце. Прогноз нужно выполнить для линейного и экспоненциального приближений и выбрать более достоверный, а также сделать другие пункты Задания.
Определить возможное изменение количества вкладчиков данного банка в следующем месяце, если известны значения сфер рейтинга и количество вкладчиков в каждом из рассматриваемых 6 месяцев. источники: http://topuch.ru/lekciya-po-ekonometrike/index2.html http://intuit.ru/studies/courses/3659/901/lecture/32718 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 . Он рассчитывается по формуле:
. Он рассчитывается по формуле: .
. . В знаменателе – СКО наблюдений зависимой переменной от среднего значения.
. В знаменателе – СКО наблюдений зависимой переменной от среднего значения. – дисперсия, характеризующая общий разброс;
– дисперсия, характеризующая общий разброс; – остаточная дисперсия, где m – число независимых (объясняющих) переменных, в случае парной регрессии m =1 и формула имеет вид:
– остаточная дисперсия, где m – число независимых (объясняющих) переменных, в случае парной регрессии m =1 и формула имеет вид:  .
. .
. является лучшей по сравнению с найденной регрессионной прямой.
является лучшей по сравнению с найденной регрессионной прямой. раскладывается на две части – объясненную и необъясненную:
раскладывается на две части – объясненную и необъясненную:





 = n–2.
= n–2. — факторная,
— факторная,  — остаточная.
— остаточная. уравнения линейной зависимости
уравнения линейной зависимости  предполагаются постоянными величинами, оценки а и b этих коэффициентов, получаемые в ходе построения уравнения по данным случайной выборки, являются случайными величинами. Если ошибки регрессии имеют нормальное распределение, то оценки коэффициентов также распределены нормально и могут характеризоваться своими средними значениями и дисперсией. Поэтому анализ коэффициентов начинается с расчёта этих характеристик.
предполагаются постоянными величинами, оценки а и b этих коэффициентов, получаемые в ходе построения уравнения по данным случайной выборки, являются случайными величинами. Если ошибки регрессии имеют нормальное распределение, то оценки коэффициентов также распределены нормально и могут характеризоваться своими средними значениями и дисперсией. Поэтому анализ коэффициентов начинается с расчёта этих характеристик. :
:  ,
, – остаточная дисперсия на одну степень свободы.
– остаточная дисперсия на одну степень свободы. :
:
 ,
, .
. ,
, 
 .
. .
. степенями свободы. По таблицам распределения Стьюдента при определённом уровне значимости α и
степенями свободы. По таблицам распределения Стьюдента при определённом уровне значимости α и  .
. , то нулевая гипотеза должна быть отклонена, коэффициенты считаются статистически значимыми.
, то нулевая гипотеза должна быть отклонена, коэффициенты считаются статистически значимыми. , то нулевая гипотеза не может быть отклонена. (В случае, если коэффициент b статистически незначим, уравнение должно иметь вид
, то нулевая гипотеза не может быть отклонена. (В случае, если коэффициент b статистически незначим, уравнение должно иметь вид  ).
). .
.
 (где
(где  — уровень значимости) истинные значения а, b находятся в указанных интервалах.
— уровень значимости) истинные значения а, b находятся в указанных интервалах. Они не должны включать нуль.
Они не должны включать нуль. о том, что все коэффициенты регрессии, за исключением свободного члена а, равны нулю и, следовательно, фактор х не оказывает влияния на результат y (
о том, что все коэффициенты регрессии, за исключением свободного члена а, равны нулю и, следовательно, фактор х не оказывает влияния на результат y ( или
или  ).
). ,
, .
. – в случае множественной регрессии,
– в случае множественной регрессии,  – для парной регрессии.
– для парной регрессии. , то
, то  отклоняется и делается вывод о существенности статистической связи между y и x.
отклоняется и делается вывод о существенности статистической связи между y и x. , то вероятность уравнение регрессии считается статистически незначимым,
, то вероятность уравнение регрессии считается статистически незначимым,  не отклоняется.
не отклоняется. . Кроме того,
. Кроме того,  , поэтому
, поэтому  . Таким образом, проверка гипотез о значимости коэффициентов регрессии и корреляции равносильна проверке гипотезы о существенности линейного уравнения регрессии.
. Таким образом, проверка гипотез о значимости коэффициентов регрессии и корреляции равносильна проверке гипотезы о существенности линейного уравнения регрессии. по п наблюдениям с т объясняющими переменными, и коэффициент детерминации равен
по п наблюдениям с т объясняющими переменными, и коэффициент детерминации равен  , затем последние k переменных исключены из числа объясняющих, и по тем же данным оценено уравнение
, затем последние k переменных исключены из числа объясняющих, и по тем же данным оценено уравнение  , для которого коэффициент детерминации равен
, для которого коэффициент детерминации равен  (
(
 ,
, степенями свободы.
степенями свободы. . И если
. И если  ,
, . И если она превышает критический уровень, то включение новых переменных объясняет существенную часть необъяснённой ранее дисперсии зависимой переменной (т.е. включение новых объясняющих переменных оправдано).
. И если она превышает критический уровень, то включение новых переменных объясняет существенную часть необъяснённой ранее дисперсии зависимой переменной (т.е. включение новых объясняющих переменных оправдано). наблюдений. Для каждой из этих выборок оценено уравнение регрессии вида
наблюдений. Для каждой из этих выборок оценено уравнение регрессии вида  от линии регрессии (т.е.
от линии регрессии (т.е.  ) равны для них, соответственно,
) равны для них, соответственно,  .
. : о том, что все соответствующие коэффициенты этих уравнений равны друг другу, т.е. уравнение регрессии для этих выборок одно и то же.
: о том, что все соответствующие коэффициенты этих уравнений равны друг другу, т.е. уравнение регрессии для этих выборок одно и то же. наблюдений, и СКО
наблюдений, и СКО  .
.
 степенями свободы. F – статистика будет близкой к нулю, если уравнение для обеих выборок одинаково, т.к. в этом случае
степенями свободы. F – статистика будет близкой к нулю, если уравнение для обеих выборок одинаково, т.к. в этом случае  . Т.е. если
. Т.е. если  не соответствует некоторым предпосылкам МНК, то следует корректировать модель.
не соответствует некоторым предпосылкам МНК, то следует корректировать модель. хорошо аппроксимируют фактические значения
хорошо аппроксимируют фактические значения  .
.
 от теоретических значений
от теоретических значений  .
.
 от теоретических значений
от теоретических значений  (или
(или  ). Это выполнимо для линейных моделей и моделей, нелинейных относительно включаемых переменных.
). Это выполнимо для линейных моделей и моделей, нелинейных относительно включаемых переменных. , что также исследуется в рамках соблюдения второй предпосылки МНК. С этой целью наряду с изложенным графиком зависимости остатков
, что также исследуется в рамках соблюдения второй предпосылки МНК. С этой целью наряду с изложенным графиком зависимости остатков  (рис. 3).
(рис. 3).
 . Скопление точек в определенных участках значений фактора
. Скопление точек в определенных участках значений фактора  — и
— и  -критериев. Вместе с тем, оценки регрессии, найденные с применением МНК, обладают хорошими свойствами даже при отсутствии нормального распределения остатков, т.е. при нарушении пятой предпосылки МНК.
-критериев. Вместе с тем, оценки регрессии, найденные с применением МНК, обладают хорошими свойствами даже при отсутствии нормального распределения остатков, т.е. при нарушении пятой предпосылки МНК. от значений отклонений во всех других наблюдениях. Отсутствие зависимости гарантирует отсутствие коррелированности между любыми отклонениями, т.е.
от значений отклонений во всех других наблюдениях. Отсутствие зависимости гарантирует отсутствие коррелированности между любыми отклонениями, т.е.  и, в частности, между соседними отклонениями
и, в частности, между соседними отклонениями  .
.
 .
. . А затем рассчитывается статистика Дарбина-Уотсона по формуле:
. А затем рассчитывается статистика Дарбина-Уотсона по формуле: .
. об отсутствии автокорреляции остатков. Альтернативные гипотезы
об отсутствии автокорреляции остатков. Альтернативные гипотезы  и
и  состоят, соответственно, в наличии положительной или отрицательной автокорреляции в остатках. Далее по специальным таблицам определяются критические значения критерия Дарбина-Уотсона
состоят, соответственно, в наличии положительной или отрицательной автокорреляции в остатках. Далее по специальным таблицам определяются критические значения критерия Дарбина-Уотсона  (- нижняя граница признания положительной автокорреляции) и
(- нижняя граница признания положительной автокорреляции) и  (-верхняя граница признания отсутствия положительной автокорреляции) для заданного числа наблюдений
(-верхняя граница признания отсутствия положительной автокорреляции) для заданного числа наблюдений  , числа независимых переменных модели
, числа независимых переменных модели  и уровня значимости
и уровня значимости  . По этим значениям числовой промежуток
. По этим значениям числовой промежуток  разбивают на пять отрезков. Принятие или отклонение каждой из гипотез с вероятностью
разбивают на пять отрезков. Принятие или отклонение каждой из гипотез с вероятностью  осуществляется следующим образом:
осуществляется следующим образом: – положительная автокорреляция, принимается
– положительная автокорреляция, принимается  – зона неопределенности;
– зона неопределенности; – автокорреляция отсутствует;
– автокорреляция отсутствует; – зона неопределенности;
– зона неопределенности; – отрицательная автокорреляция, принимается
– отрицательная автокорреляция, принимается 
 .
.
 .
. , то отклонения от линии регрессии можно считать взаимно независимыми.
, то отклонения от линии регрессии можно считать взаимно независимыми. ,
, – случайный член.
– случайный член. ,
, – оценка коэффициента автокорреляции первого порядка, D(c) – выборочная дисперсия коэффициента при лаговой переменной yt-1, n – число наблюдений.
– оценка коэффициента автокорреляции первого порядка, D(c) – выборочная дисперсия коэффициента при лаговой переменной yt-1, n – число наблюдений. , а D(c) равна квадрату стандартной ошибки Sc оценки коэффициента с.
, а D(c) равна квадрату стандартной ошибки Sc оценки коэффициента с. определяется значением той же самой величины, но с запаздыванием. Т.к. максимальное запаздывание равно 1, то это авторегрессия первого порядка).
определяется значением той же самой величины, но с запаздыванием. Т.к. максимальное запаздывание равно 1, то это авторегрессия первого порядка). .
. -коэффициент автокорреляции первого порядка ошибок регрессии.
-коэффициент автокорреляции первого порядка ошибок регрессии. .
. (1),
(1), (2).
(2). и вычтем из (1):
и вычтем из (1): .
.
 (6).
(6). .
. ,
, ), можно использовать метод первых разностей (метод исключения тенденции), уравнение принимает вид
), можно использовать метод первых разностей (метод исключения тенденции), уравнение принимает вид

 .
. .
. )
) ,
,
 .
. имеют одинаковую дисперсию
имеют одинаковую дисперсию  . Если это условие применения МНК не соблюдается, то имеет место гетероскедастичность.
. Если это условие применения МНК не соблюдается, то имеет место гетероскедастичность.

 , где
, где  наблюдении пропорциональна постоянной дисперсии:
наблюдении пропорциональна постоянной дисперсии: 
 .
. — коэффициент пропорциональности. Он меняется при переходе от одного значения фактора
— коэффициент пропорциональности. Он меняется при переходе от одного значения фактора  пропорциональна квадрату фактора:
пропорциональна квадрату фактора:  ,
,  . А также остатки имеют нормальное распределение и отсутствует автокорреляция остатков.
. А также остатки имеют нормальное распределение и отсутствует автокорреляция остатков. .
. для первой и второй
для первой и второй  групп. Если предположение о пропорциональности дисперсий отклонений значениям x верно, то
групп. Если предположение о пропорциональности дисперсий отклонений значениям x верно, то  .
. которая предполагает отсутствие гетероскедастичности.
которая предполагает отсутствие гетероскедастичности. ,
, степеней свободы (здесь m – число объясняющих переменных).
степеней свободы (здесь m – число объясняющих переменных). , то гипотеза об отсутствии гетероскедастичности отклоняется при уровне значимости α.
, то гипотеза об отсутствии гетероскедастичности отклоняется при уровне значимости α. . В этом случае статистика Фишера принимает вид:
. В этом случае статистика Фишера принимает вид: .
. . Обобщенный метод наименьших квадратов (ОМНК)
. Обобщенный метод наименьших квадратов (ОМНК) , а дисперсия пропорциональна величине
, а дисперсия пропорциональна величине  .
. – дисперсия ошибки при конкретном
– дисперсия ошибки при конкретном  -м значении фактора;
-м значении фактора;  – постоянная дисперсия ошибки при соблюдении предпосылки о гомоскедастичности остатков;
– постоянная дисперсия ошибки при соблюдении предпосылки о гомоскедастичности остатков;  модель примет вид:
модель примет вид: .
. . Тогда дисперсия остатков будет величиной постоянной, т. е.
. Тогда дисперсия остатков будет величиной постоянной, т. е.  .
. и
и  . Уравнение регрессии примет вид:
. Уравнение регрессии примет вид: ,
, ,
, .
. .
. .
.
 ,
, при использовании обобщенного МНК с целью корректировки гетероскедастичности представляет собой взвешенную величину по отношению к обычному МНК с весом
при использовании обобщенного МНК с целью корректировки гетероскедастичности представляет собой взвешенную величину по отношению к обычному МНК с весом  .
. .
. .
. . На практике такие значения известны крайне редко. Поэтому, чтобы применить ВНК, необходимо сделать реалистические предположения о значениях
. На практике такие значения известны крайне редко. Поэтому, чтобы применить ВНК, необходимо сделать реалистические предположения о значениях  , т.е
, т.е  или
или  .
. :
:
 .
. выполняется условие гомоскедастичности. Следовательно, для регрессии применим обычный МНК. Следует отметить, что новая регрессия не имеет свободного члена, но зависит от двух факторов. Оценив для неё по МНК коэффициенты а и b, возвращаемся к исходному уравнению регрессии.
выполняется условие гомоскедастичности. Следовательно, для регрессии применим обычный МНК. Следует отметить, что новая регрессия не имеет свободного члена, но зависит от двух факторов. Оценив для неё по МНК коэффициенты а и b, возвращаемся к исходному уравнению регрессии.
 :
: .
. ,
, .
. .
. ,
, (т.е. дисперсия ошибок пропорциональна квадрату первой объясняющей переменной), то в этом случае обобщенный МНК предполагает оценку параметров следующего трансформированного уравнения:
(т.е. дисперсия ошибок пропорциональна квадрату первой объясняющей переменной), то в этом случае обобщенный МНК предполагает оценку параметров следующего трансформированного уравнения: .
. – объем продукции,
– объем продукции,  – основные производственные фонды,
– основные производственные фонды,  – численность работников, тогда уравнение
– численность работников, тогда уравнение
 пропорциональна квадрату численности работников
пропорциональна квадрату численности работников  , а в качестве факторов следующие показатели: производительность труда
, а в качестве факторов следующие показатели: производительность труда  и фондовооруженность труда
и фондовооруженность труда  . Соответственно трансформированная модель примет вид
. Соответственно трансформированная модель примет вид ,
, ,
,  ,
,  численно не совпадают с аналогичными параметрами предыдущей модели. Кроме этого, коэффициенты регрессии меняют экономическое содержание: из показателей силы связи, характеризующих среднее абсолютное изменение издержек производства с изменением абсолютной величины соответствующего фактора на единицу, они фиксируют при обобщенном МНК среднее изменение затрат на работника; с изменением производительности труда на единицу при неизменном уровне фовдовооруженности труда; и с изменением фондовооруженности труда на единицу при неизменном уровне производительности труда.
численно не совпадают с аналогичными параметрами предыдущей модели. Кроме этого, коэффициенты регрессии меняют экономическое содержание: из показателей силы связи, характеризующих среднее абсолютное изменение издержек производства с изменением абсолютной величины соответствующего фактора на единицу, они фиксируют при обобщенном МНК среднее изменение затрат на работника; с изменением производительности труда на единицу при неизменном уровне фовдовооруженности труда; и с изменением фондовооруженности труда на единицу при неизменном уровне производительности труда. , можно перейти к уравнению регрессии вида
, можно перейти к уравнению регрессии вида .
. – затраты на единицу (или на 1 руб. продукции),
– затраты на единицу (или на 1 руб. продукции),  – фондоемкость продукции,
– фондоемкость продукции,  – трудоемкость продукции.
– трудоемкость продукции.
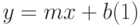
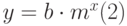 ,
,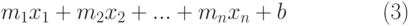
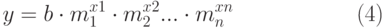
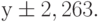 .
. град.
град.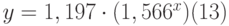
 теперь может быть получено из строки 14:
теперь может быть получено из строки 14: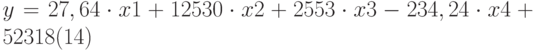
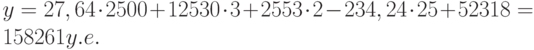
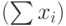
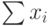 ) должны быть записаны формулы, вычисляющие суммы всех расходов х1+х2+…+х7 в каждом году, в ячейках столбца Доход – соответствующие среднегодовые доходы, в ячейках столбца Кредит – формулы разности содержимого ячеек с ежегодными доходами и затратами, т.е. Кредит = Доход-
) должны быть записаны формулы, вычисляющие суммы всех расходов х1+х2+…+х7 в каждом году, в ячейках столбца Доход – соответствующие среднегодовые доходы, в ячейках столбца Кредит – формулы разности содержимого ячеек с ежегодными доходами и затратами, т.е. Кредит = Доход-