Уравнение регрессии в натуральном масштабе
Значение свободного члена уравнения регрессии в натуральном масштабе находим из уравнения [c.181]
Это означает, что с ростом фактора а , на одну сигму при неизменной численности занятых затраты на продукцию увеличиваются в среднем на 0,5 сигмы. Так как /3, 1. Преобразование в этих случаях заключается во взятии натурального логарифма от Y, а и X. Получающееся уравнение регрессии будет выглядеть так [c.295]
Результаты полученных средних значений скорости чтения позволили построить уравнение регрессии (в натуральных переменных) следующего вида [c.125]
Применение в практических целях уравнения множественной регрессии в стандартизованном масштабе затруднительно, поэтому уравнение множественной регрессии следует перевести в натуральный масштаб. Перевод коэффициентов множественной регрессии из стандартизованного масштаба в натуральный производится по формуле [c.180]
Отсюда уравнение множественной регрессии в натуральном масштабе для уровня торгово-управленческих расходов I группы управлений имеет вид [c.181]
Найдите уравнение множественной регрессии в стандартизованном и натуральном масштабе. [c.88]
Постройте уравнение линейной регрессии, отражающее зависимость между объемом реализации продукции (в натуральных единицах) и ценой за единицу продукции, по следующим данным [c.437]
Теоретическая линия регрессии может быть рассчитана в этом случае по результатам отдельных наблюдений. Для решения системы нормальных уравнений нам потребуются те же данные х, у, ху и хг. Рассмотрим пример расчета. Мы располагаем данными об объеме производства цемента и объеме основных производственных фондов в 1958 г. Ставится задача исследовать зависимость между объемом производства цемента (в натуральном выражении) и объемом основных фондов. [c.73]
Подставив эти значения в выражение (30), получим уравнение множественной регрессии улова рыбы в натуральном масштабе [c.130]
Проблемы с методологией регрессии. Методология регрессии — это традиционный способ уплотнения больших массивов данных и их сведения в одно уравнение, отражающее связь между мультипликаторами РЕ и финансовыми фундаментальными переменными. Но данный подход имеет свои ограничения. Во-первых, независимые переменные коррелируют друг с другом . Например, как видно из таблицы 18,2, обобщающей корреляцию между коэффициентами бета, ростом и коэффициентами выплат для всех американских фирм, быстрорастущие фирмы обычно имеют большой риск и низкие коэффициенты выплат. Обратите внимание на отрицательную корреляцию между коэффициентами выплат и ростом, а также на положительную корреляцию между коэффициентами бета и ростом. Эта мультиколлинеарность делает мультипликаторы регрессии ненадежными (увеличивает стандартную ошибку) и, возможно, объясняет ошибочные знаки при коэффициентах и крупные изменения этих мультипликаторов в разные периоды. Во-вторых, регрессия основывается на линейной связи между мультипликаторами РЕ и фундаментальными переменными, и данное свойство, по всей вероятности, неадекватно. Анализ остаточных явлений, связанных с корреляцией, может привести к трансформациям независимых переменных (их квадратов или натуральных логарифмов), которые в большей степени подходят для объяснения мультипликаторов РЕ. В-третьих, базовая связь между мультипликаторами РЕ и финансовыми переменными сама по себе не является стабильной. Если же эта связь смещается из года в год, то прогнозы, полученные из регрессионного уравнения, могут оказаться ненадежными для более длительных периодов времени. По всем этим причинам, несмотря на полезность регрессионного анализа, его следует рассматривать только как еще один инструмент поиска подлинного значения ценности. [c.649]
Для практического использования полученные зависимости должны быть выражены в натуральном масштабе. Уравнение множественной регрессии в натуральном масштабе имеет вид [c.126]
Дли более удобного практического использования приведенной формулы полученные зависимости переводим в натуральный масштаб. С этой целью проводим ряд преобразований, смысл которых заключается в выделении соотношений между о 0, ор, O M, оМж.б и соответствующими р и Ь (принятыми в начальном уравнении множественной регрессии). [c.150]
Кроме проверки значимости всей модели, необходимо провести проверки значимости коэффициентов регрессии по /-критерию Стюдента. Минимальное значение коэффициента регрессии Ьг должно соответствовать условию bifob- t, где bi — значение коэффициента уравнения регрессии в натуральном масштабе при i-ц факторном признаке аь. — средняя квадратическая ошибка каждого коэффициента. [c.181]
Интересно также выявить, как изменяется исследуемый показатель при изменении факторов, измеряемых в натуральных единицах. От уравнения регресии в стандартизованном масштабе к уравнению регрессии в натуральном масштабе можно перейти следующим образом. Пусть в ре зультате расчетов получено уравнение регрессии [c.130]
уравнение множественной регрессии в натуральном и стандартизированном виде
Оценка параметров уравнения регресии в стандартизованном масштабе
Параметры уравнения множественной регрессии в задачах по эконометрике оценивают аналогично парной регрессии, методом наименьших квадратов (МНК). При применении этого метода строится система нормальных уравнений, решение которой и позволяет получать оценки параметров регрессии.
При определении параметров уравнения множественной регрессии на основе матрицы парных коэффициентов корреляции строим уравнение регрессии в стандартизованном масштабе:

в уравнении стандартизированные переменные

Применяя метод МНК к моделям множественной регрессии в стандартизованном масштабе, после опрделенных преобразований получим систему нормальных уравнений вида

Решая системы методом определителей, находим параметры — стандартизованные коэффициенты регрессии (бета — коэффициенты). Сравнивая коэффициенты друг с другом, можно ранжировать факторы по силе их воздействия на результат. В этом заключается основное достоинство стандартизованных коэффициентов в отличие от обычных коэффициентов регрессии, которые несравнимы между собой.
В парной зависимости стандартизованный коэффициент регрессии связан с соответствующим коэфициентом уравнения зависимостью

Это позволяет от уравнения в стандартизованном масштабе переходить к регрессионному уравнению в натуральном масштабе переменных:

Параметр а определяется из следующего уравнения

Стандартизованные коэффициенты регрессии показывают, на сколько сигм изменится в среднем результат, если соответствующий фактор xj изменится на одну сигму при неизменном среднем уровне других факторов. В силу того, что все перемеyные заданы как центрированные и нормированные, стандартизованные коэффициенты регрессии сравнимы между собой.
Рассмотренный смысл стандартизованных коэффициентов позволяет использовать их при отсеве факторов, исключая из модели факторы с наименьшим значением.
Компьютерные программы построения уравнения множественной регрессии позволяют получать либо только уравнение регрессии для исходных данных и уравнение регрессии в стандартизованном масштабе.
19. Характеристика эластичности по модели множественной регрессии. СТР 132-136
20. Взаимосвязь стандартизированных коэффициентов регрессии и коэффициентов эластичности. СТР 120-124
21. Показатели множественной и частной корреляции. Их роль при построении эконометрических моделей
Корреляция—это статистическая взаимосвязь двух или нескольких случайных величин (либо величин, которые можно с некоторой допустимой степенью точности считать таковыми). При этом, изменения одной или нескольких из этих величин приводят к систематическому изменению другой или других величин. Математической мерой Корреляции двух случайных величин служит коэффициент Корреляции. Понятие корреляции появилось в середине XIX века в работах английских статистиков Ф. Гальтона и К. Пирсона.
Коэффициент множественной корреляции (R) характеризует тесноту связи между результативным показателем и набором факторных показателей:

где σ 2 — общая дисперсия эмпирического ряда, характеризующая общую вариацию результативного показателя (у) за счет факторов;
σост 2 — остаточная дисперсия в ряду у, отражающая влияния всех факторов, кроме х;
у — среднее значение результативного показателя, вычисленное по исходным наблюдениям;
s — среднее значение результативного показателя, вычисленное по уравнению регрессии.
Коэффициент множественной корреляции принимает только положительные значения в пределах от 0 до 1. Чем ближе значение коэффициента к 1, тем больше теснота связи. И, наоборот, чем ближе к 0, тем зависимость меньше. При значении R 0,6 говорят о наличии существенной связи.
Квадрат коэффициента множественной корреляции называется коэффициентом детерминации (D): D = R 2 . Коэффициент детерминации показывает, какая доля вариации результативного показателя связана с вариацией факторных показателей. В основе расчета коэффициента детерминации и коэффициента множественной корреляции лежит правило сложения дисперсий, согласно которому общая дисперсия (σ 2 ) равна сумме межгрупповой дисперсии (δ 2 ) и средней из групповых дисперсий σi 2 ):
Межгрупповая дисперсия характеризует колеблемость результативного показателя за счет изучаемого фактора, а средняя из групповых дисперсий отражает колеблемость результативного показателя за счет всех прочих факторов, кроме изучаемого.
Показатели частной корреляции. Основаны на соотношении сокращения остаточной вариации за счет дополнительно включенного в модель фактора к остаточной вариации до включения в модель соответствующего фактора

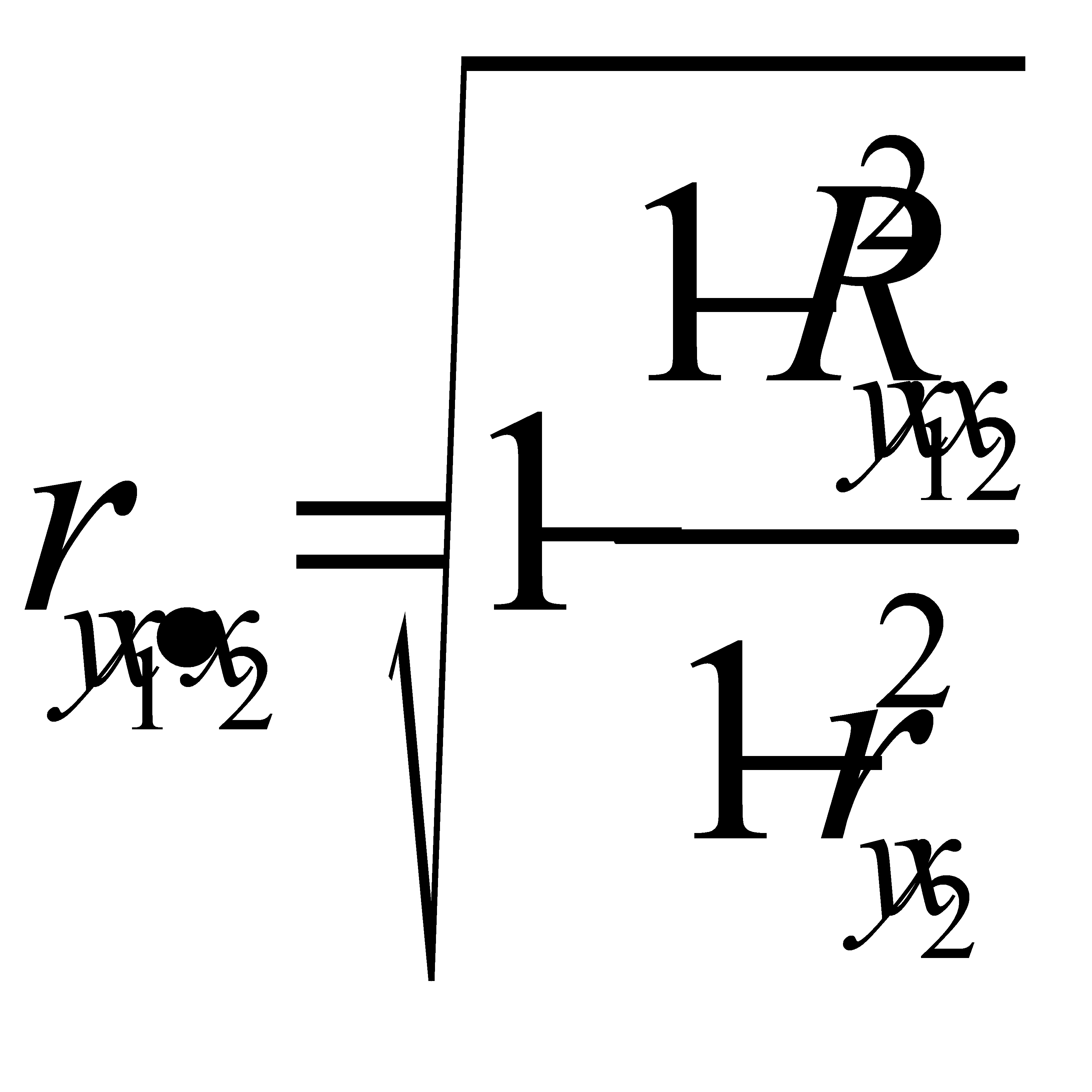
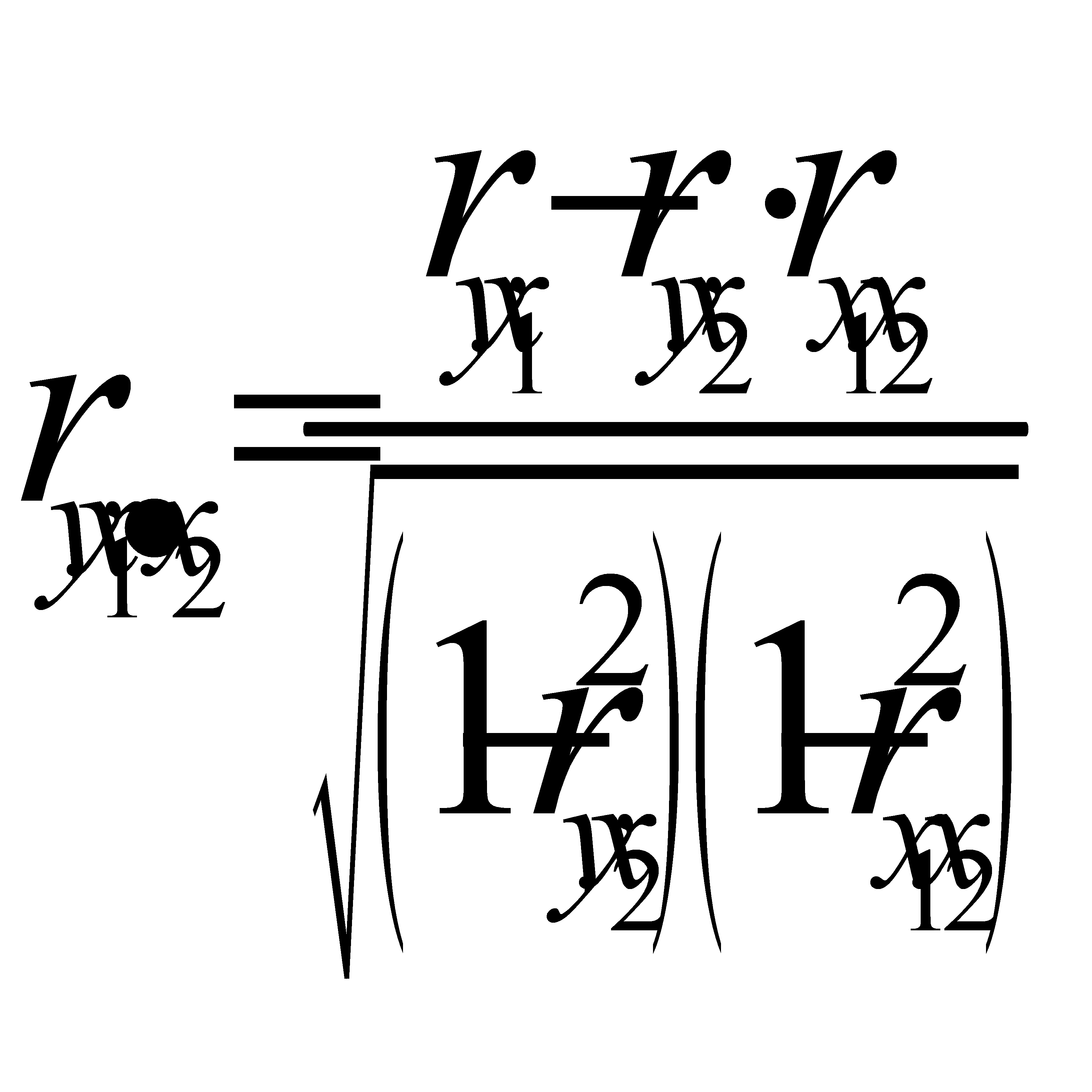


Рассмотренные показатели можно также использовать для сравнения факторов, т.е. Можно ранжировать факторы(т.е.2ой фактор более тесно связан).
Частные коэффициенты могут быть использованы в процедуре отсева факторов при построении модели.
Рассмотренные выше показатели являются коэф-ми корреляции первого порядка,т.е.они характризуют связь между двумя факторами при закреплении одного фактора (yx1.x2). Однако можно построить коэф-ты 2го и более порядка (yx1.x2x3, yx1.x2x3x4).
22. Оценка надежности результатов множественной регрессии.
Коэфициенты структурной модели могут быть оценены разными способами в зависимости от вида одновренных уравнений.
Методы оценивания коэф-тов структурной модели:
1) Косвенный МНК(КМНК)
4)МНП с полной информацией
5)МНП при огранич. информации
КМНК применяется в случаеточнойидентификацииструктурноймодели.
Процедуры примения КМНК:
1. Структурн. модель преобраз. в привед. форму модели.
2. Для каждого уравнения привед.форма модели обычным МНК оцениваются привед. коэф 
3. Коэфициенты приведенной формы модели трансформируются в параметры структурной модели.
Еслиси стема сверхидентифицируема, то КМНК не исп, так как не дает однозначных оценок для параметров структурной модели. В этом случае могут исп. разные методы оценивания, среди которых наиболее распространен ДМНК.
Основная идея ДМНК на основе приведенной модели получить для сверхидентиф. уравнения теор. значения эндогенных переменных, содерж. в правой части ур-ния. Далее подставив в найденные значения вместо факт.значений применяется обычный МНК и структурн. форма сверхидент. ур-ния.
1 шаг: при опред.привед. формы модели и нахождении на ее основе оценок теор. значений эндогенной переменой
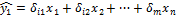
2 шаг: Применительно к структурному сверхидентифицируемому уравнению при определении структурных коэфициентов модели по данным теоритических значений эндогенных переменных.
23. Дисперсионный анализ результатов множественной регрессии.
 Задача дисперсионного анализа в проверке гипот Н0 о статист незачимости уравн регрессии в целом и показат тесн связи. Выполняется на основе сравнения факт и табличн значений F-крит кот определяются из соотн факторной и остаточной дисперсий, рассчитан на одну степень свободы
Задача дисперсионного анализа в проверке гипот Н0 о статист незачимости уравн регрессии в целом и показат тесн связи. Выполняется на основе сравнения факт и табличн значений F-крит кот определяются из соотн факторной и остаточной дисперсий, рассчитан на одну степень свободы
| таблица дисперсионного анализа | ||||
| Вару | df | СКО,S | Дисп на одну df,S 2 | Fфакт |
 общ общ | n-1 | dy 2 * n | — | — |
| факт | m | dy 2 * n*R 2 yx1x2 | 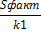 |  |
| Ост | n-m-1 | dy 2 * n*(1-R 2 yx1x2) =Sобщ-Sфакт | 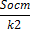 | — |
Также можно построить таблицу частного дисперсионного анализа, и найти частный F крит который оценивает целесообразность включения фактора в модель после включения др переменной
| Вариация у | df | S | S^2 |
| общая | df=n-1 | d 2 у*n | — |
| факторная | k1=m | d 2 у*n*R 2 | Sфакт/k1 |
| в том числе: | |||
| за счет x2 | d 2 у*n*r 2 yx2 | Sфактx2/1 | |
| за счет доп включ. х1 | Sфакт-Sфактх2 | Sфактx1/1 | |
| Остаточная | k2=n-m | Sобщ-Sфакт |

24. Частный F-критерий Фишера, t- критерий Стьюдента. Их роль в построении регрессионных моделей.
Для оценки статистич целесообразности добавления нов факторов в регрессион модель исп-ся частн критерий Фишера, т.к на рез-ты регрессион анализа влияет не только состав факторов, но и последовательность включения фактора в модель. Это обьясняется наличием связи между факторами.
Fxj =( (R 2 по yx1x2. xm – R 2 по yx1x2…xj-1,хj+1…xm)/(1- R 2 по yx1x2. xm) )*( (n-m-1)/1)
Fтабл (альфа,1, n-m-1) Fxj больше Fтабл – фактор xj целесообразно лючать в модель после др.факторов.
Если рассматривается уравнение y=a+b1x1+b2+b3x3+e, то определяются последовательно F-критерий для уравнения с одним фактором х1, далее F- критерий для дополнительного включения в модель фактора х2, т. е. для перехода от однофакторного уравнения регрессии к двухфакторному, и, наконец, F-критерий для дополнительного включения в модель фактора х3, т.е. дается оценка значимости фактора х3 после включения в модель факторов x1 их2. В этом случае F-критерий для дополнительного включения фактора х2 после х1 является последовательным в отличие от F-критерия для дополнительного включения в модель фактора х3, который является частным F- критерием, ибо оценивает значимость фактора в предположении, что он включен в модель последним. С t-критерием Стьюдента связан именно частный F- критерий. Последовательный F-критерий может интересовать исследователя настадии формирования модели. Для уравнения y=a+b1x1+b2+b3x3+e оценка значимости коэффициентов регрессии Ь1,Ь2,,b3 предполагает расчет трех межфакторных коэффициентов детерминации.
Для оценки статистической значимости коэффициентов регрессии и корреляции рассчитываются t-критерий Стьюдентаи доверительные интервалыкаждого из показателей.






 Сравнивая фактическое и критическое (табличное) значения t-статистики и tтабл. — принимаем или отвергаем гипотезу H0. Связь между F-критерием Фишера и t-статистикой Стьюдента выражается равенством
Сравнивая фактическое и критическое (табличное) значения t-статистики и tтабл. — принимаем или отвергаем гипотезу H0. Связь между F-критерием Фишера и t-статистикой Стьюдента выражается равенством
Если t табл. tфакт. то гипотеза H0 не отклоняется и признается случайная природа формирования a, b или rху.
25. Оценка качества регрессионных моделей. Стандартная ошибка линии регрессии.
Оценка качества линейной регрессии: коэффициент детерминации R 2
Из-за линейного соотношения  и
и  мы ожидаем, что изменяется, по мере того как изменяется , и называем это вариацией, которая обусловлена или объясняется регрессией. Остаточная вариация должна быть как можно меньше.
мы ожидаем, что изменяется, по мере того как изменяется , и называем это вариацией, которая обусловлена или объясняется регрессией. Остаточная вариация должна быть как можно меньше.
Если это так, то большая часть вариации будет объясняться регрессией, а точки будут лежать близко к линии регрессии, т.е. линия хорошо соответствует данным.
Долю общей дисперсии , которая объясняется регрессией называют коэффициентом детерминации, обычно выражают через процентное соотношение и обозначают R 2 (в парной линейной регрессии это величина r 2 , квадрат коэффициента корреляции), позволяет субъективно оценить качество уравнения регрессии.
Разность  представляет собой процент дисперсии который нельзя объяснить регрессией.
представляет собой процент дисперсии который нельзя объяснить регрессией.
Нет формального теста для оценки  мы вынуждены положиться на субъективное суждение, чтобы определить качество подгонки линии регрессии.
мы вынуждены положиться на субъективное суждение, чтобы определить качество подгонки линии регрессии.
Применение линии регрессии для прогноза
Можно применять регрессионную линию для прогнозирования значения по значению в пределе наблюдаемого диапазона (никогда не экстраполируйте вне этих пределов).
Мы предсказываем среднюю величину для наблюдаемых, которые имеют определенное значение 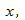 путем подстановки этого значения в уравнение линии регрессии.
путем подстановки этого значения в уравнение линии регрессии.
Итак, если  прогнозируем как
прогнозируем как  Используем эту предсказанную величину и ее стандартную ошибку, чтобы оценить доверительный интервал для истинной средней величины в популяции.
Используем эту предсказанную величину и ее стандартную ошибку, чтобы оценить доверительный интервал для истинной средней величины в популяции.
Повторение этой процедуры для различных величин позволяет построить доверительные границы для этой линии. Это полоса или область, которая содержит истинную линию, например, с 95% доверительной вероятностью.
Подобным образом можно рассчитать более широкую область, внутри которой, как мы ожидаем, лежит наибольшее число (обычно 95%) наблюдений.
Применение линии регрессии для прогноза
Можно применять регрессионную линию для прогнозирования значения по значению в пределе наблюдаемого диапазона (никогда не экстраполируйте вне этих пределов).
Мы предсказываем среднюю величину для наблюдаемых, которые имеют определенное значение путем подстановки этого значения в уравнение линии регрессии.
Итак, если прогнозируем как Используем эту предсказанную величину и ее стандартную ошибку, чтобы оценить доверительный интервал для истинной средней величины в популяции.
Повторение этой процедуры для различных величин позволяет построить доверительные границы для этой линии. Это полоса или область, которая содержит истинную линию, например, с 95% доверительной вероятностью.
Подобным образом можно рассчитать более широкую область, внутри которой, как мы ожидаем, лежит наибольшее число (обычно 95%) наблюдений.
26. Взаимосвязь частного F-критерия, t- критерия Стьюдента и частного коэффициента корреляции.
Ввиду корреляции м/у факторами значимость одного и того же фактора м/б различной в зависимости от последовательности его введения в модель. Мерой для оценки включения фактора в модель служит частый F-критерий, т.е. Fxi. В общем виде для фактора xi частый F-критерий определяется как :

Если рассматривается уравнение y=a+b1x1+b2+b3x3+e, то определяются последовательно F-критерий для уравнения с одним фактором х1, далее F-критерий для дополнительного включения в модель фактора х2, т. е. для перехода от однофакторного уравнения регрессии к двухфакторному, и, наконец, F-критерий для дополнительного включения в модель фактора х3, т. е. дается оценка значимости фактора х3 после включения в модель факторов x1 их2. В этом случае F-критерий для дополнительного включения фактора х2 после х1является последовательнымв отличие от F-критерия для дополнительного включения в модель фактора х3, который является частнымF-критерием, ибо оценивает значимость фактора в предположении, что он включен в модель последним. С t-критерием Стьюдента связан именно частный F-критерий. Последовательный F-критерий может интересовать исследователя на стадии формирования модели. Для уравнения y=a+b1x1+b2+b3x3+e оценка значимости коэффициентов регрессии Ь1,Ь2,,b3 предполагает расчет трех межфакторных коэффициентов детерминации, а именно:  ,
,  ,
,  и можно убедиться, что существует связьмежду собой t- критерия Стьюдента для оценки значимости bi и частным F-критерием:
и можно убедиться, что существует связьмежду собой t- критерия Стьюдента для оценки значимости bi и частным F-критерием:
 На основе соотношения bi и
На основе соотношения bi и 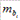 получим:
получим:


27. Варианты построения регрессионной модели. Их краткая характеристика.
28. Интерпретация параметров линейной и нелинейной регрессии.
| b | a | ||||||||||||||||||||||||
| парная | линейная | Коэффициент регрессии b показывает среднее изменение результативного показателя (в единицах измерения у) с повышением или понижением величины фактора х на единицу его измерения. Связь между у и х определяет знак коэффициента регрессии b (если > 0 – прямая связь, иначе – обратная | не интерпретируется, только знак >0 – рез-т изменяется медленнее фактора, * предполагают наличие положительной или отрицательной автокорреляции в остатках. Затем по спец. таблицам определяютсякритические значения критерия Дарбина — Уотсона dL и du для заданного числа наблюдений n, числа независимых переменных модели k при уровня значимости ɑ (обычно 0,95). По этим значениям промежуток [0;4] разбивают на пять отрезков. Принятие или отклонение каждой из гипотез с вероятностью (1-ɑ) представлено на след: рисунке:
Если фактич. значение критерия Дарбина — Уотсона попадает в зону неопределенности, то на практике предполагают существование автокорреляции остатков и гипотезу Н0 отклоняют. 34. Выбор наилучшего варианта модели регрессии.
35. Нелинейные модели множественной регрессии, их общая характеристика. Если между экономическими явлениями существуют нелинейные соотношения, то они выражаются с помощью соответствующих нелинейных функций: например, равносторонней гиперболы Различают два класса нелинейных регрессий: • регрессии, нелинейные относительно включенных в анализ объясняющих переменных, но линейные по оцениваемым параметрам; • регрессии, нелинейные по оцениваемым параметрам.
К нелинейным регрессиям по оцениваемым параметрам относятся функции: 36. Модели гиперболического типа. Кривые Энгеля, кривая Филипса, и другие примеры использования моделей данного типа. Кривые Энгеля (Engel curve) иллюстрируют зависимость между объемом потребления благ (C) и доходом потребителя (I) при неизменных ценах и предпочтениях. Названа в честь немецкого статистика Эрнста Энгеля, занимавшегося анализом влияния изменения дохода на структуру потребительских расходов.
На оси абсцисс откладывается уровень дохода потребителя, а на оси ординат — расходы на потребление данного блага. На графике показан примерный вид кривых Энгеля:
Кривая филипса отражает взаимосвязь между темпами инфляции ибезработицы. Кейнсианская модель экономики показывает, что в экономике может возникнуть либо безработица (вызванная спадом производства, следовательно уменьшением спроса на рабочую силу), либо инфляция (если экономика функционирует в состоянии полной занятости). Одновременно высокая инфляция и высокая безработица существовать не могут.
Кривая Филипса была построена А.У. Филлипсом на основе данных заработной платы и безработицы в Великобритании за 1861-1957 годы. Следуя кривой Филлипса государство может выстроить свою экономическую политику. Государство с помощью стимулирования совокупного спроса может увеличить инфляцию и снизить безработицу и наоборот. Кривая Филипса была полностью верна до середины 70х годов. В этот период случилась стагнация (одновременный рост инфляции и безработицы), которую кривая филипса не смогла объяснить. Конспект лекций по курсу «Эконометрика» для студентов III курса дневного отделения всех специальностей (стр. 1 )
ФЕДЕРАЛЬНОЕ АГЕНТСТВО ПО ОБРАЗОВАНИЮ ФИНАНСОВО – ЭКОНОМИЧЕСКИЙ ИНСТИТУТ Кафедра статистики и эконометрики по курсу «ЭКОНОМЕТРИКА» для студентов III курса дневного отделения Печатается по решению кафедры прогнозирования и статистики : протокол от 01.01.2001 г. МОДЕЛЬ МНОЖЕСТВЕННОЙ РЕГРЕССИИ На любой экономический показатель чаще всего оказывает влияние не один, а несколько факторов. Например, спрос на некоторое благо определяется не только ценой данного блага, но и ценами на замещающие и дополняющие блага, доходом потребителей и многими другими факторами. В этом случае вместо парной регрессии рассматривается множественная регрессия Множественная регрессия широко используется в решении проблем спроса, доходности акций, при изучении функции издержек производства, в макроэкономических расчетах и в ряде других вопросов экономики. В настоящее время множественная регрессия – один из наиболее распространенных методов в эконометрике. Основной целью множественной регрессии является построение модели с большим числом факторов, а также определение влияния каждого фактора в отдельности и совокупного их воздействия на моделируемый показатель. Множественный регрессионный анализ является развитием парного регрессионного анализа в случаях, когда зависимая переменная связана более чем с одной независимой переменной. Большая часть анализа является непосредственным расширением парной регрессионной модели, но здесь также появляются и некоторые новые проблемы, из которых следует выделить две. Первая проблема касается исследования влияния конкретной независимой переменной на зависимую переменную, а также разграничения её воздействия и воздействий других независимых переменных. Второй важной проблемой является спецификация модели, которая состоит в том, что необходимо ответить на вопрос, какие факторы следует включить в регрессию (1), а какие – исключить из неё. В дальнейшем изложение общих вопросов множественного регрессионного анализа будем вести, разграничивая эти проблемы. Поэтому вначале будем полагать, что спецификация модели правильна. Самой употребляемой и наиболее простой из моделей множественной регрессии является линейная модель множественной регрессии: По математическому смыслу коэффициенты
Параметр α называется свободным членом и определяет значение y в случае, когда все объясняющие переменные равны нулю. Однако, как и в случае парной регрессии, факторы по своему экономическому содержанию часто не могут принимать нулевых значений, и значение свободного члена не имеет экономического смысла. При этом, в отличие от парной регрессии, значение каждого регрессионного коэффициента Попутно отметим, что наиболее просто можно определять оценки параметров Получение оценок параметров Здесь Пусть имеется n наблюдений объясняющих переменных и соответствующих им значений результативного признака: Для однозначного определения значений параметров уравнения (4) объем выборки n должен быть не меньше количества параметров, т. е. Для проведения анализа в рамках линейной модели множественной регрессии необходимо выполнение ряда предпосылок МНК. В основном это те же предпосылки, что и для парной регрессии, однако здесь нужно добавить предположения, специфичные для множественной регрессии: 50.Спецификация модели имеет вид (2). 60.Отсутствие мультиколлинеарности: между объясняющими переменными отсутствует строгая линейная зависимость, что играет важную роль в отборе факторов при решении проблемы спецификации модели. 70.Ошибки При выполнимости всех этих предпосылок имеет место многомерный аналог теоремы Гаусса – Маркова: оценки Оценка параметров линейного уравнения множественной регрессии Рассмотрим три метода расчета параметров множественной линейной регрессии. 1. Матричный метод. Представим данные наблюдений и параметры модели в матричной форме. Для удобства записи столбцы записаны как строки и поэтому снабжены штрихом для обозначения операции транспонирования. Наконец, значения независимых переменных запишем в виде прямоугольной матрицы размерности
Каждому столбцу этой матрицы отвечает набор из n значений одного из факторов, а первый столбец состоит из единиц, которые соответствуют значениям переменной при свободном члене. В этих обозначениях эмпирическое уравнение регрессии выглядит так: Отсюда вектор остатков регрессии можно выразить таким образом: Таким образом, функционал В соответствии с МНК дифференцирование Q по вектору В приводит к выражению: которое для нахождения экстремума следует приравнять к нулю. В результате преобразований получаем выражение для вектора параметров регрессии: Здесь Пример. Бюджетное обследование пяти случайно выбранных семей дало следующие результаты (в тыс. руб.): источники: http://poisk-ru.ru/s47443t1.html http://pandia.ru/text/79/355/36162.php |


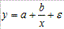 , параболы второй степени
, параболы второй степени 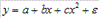 и д.р.
и д.р.



 (1)
(1) (2)
(2) в уравнении (2) равны частным производным результативного признака y по соответствующим факторам:
в уравнении (2) равны частным производным результативного признака y по соответствующим факторам: ,
, ,…,
,…, .
. уравнения регрессии (2) – одна из важнейших задач множественного регрессионного анализа. Самым распространенным методом решения этой задачи является метод наименьших квадратов (МНК). Его суть состоит в минимизации суммы квадратов отклонений наблюдаемых значений зависимой переменной y от её значений
уравнения регрессии (2) – одна из важнейших задач множественного регрессионного анализа. Самым распространенным методом решения этой задачи является метод наименьших квадратов (МНК). Его суть состоит в минимизации суммы квадратов отклонений наблюдаемых значений зависимой переменной y от её значений  , получаемых по уравнению регрессии. Поскольку параметры
, получаемых по уравнению регрессии. Поскольку параметры  (3)
(3) — оценки теоретических значений
— оценки теоретических значений  (4)
(4) (5)
(5) . В противном случае значения параметров не могут быть определены однозначно. Если n=p +1, оценки параметров рассчитываются единственным образом без МНК простой подстановкой значений (5) в выражение (4). Получается система ( p +1) уравнений с таким же количеством неизвестных, которая решается любым способом, применяемым к системам линейных алгебраических уравнений (СЛАУ). Однако с точки зрения статистического подхода такое решение задачи является ненадежным, поскольку измеренные значения переменных (5) содержат различные виды погрешностей. Поэтому для получения надежных оценок параметров уравнения (4) объём выборки должен значительно превышать количество определяемых по нему параметров. Практически, как было сказано ранее, объём выборки должен превышать количество параметров при xj в уравнении (4) в 6-7 раз.
. В противном случае значения параметров не могут быть определены однозначно. Если n=p +1, оценки параметров рассчитываются единственным образом без МНК простой подстановкой значений (5) в выражение (4). Получается система ( p +1) уравнений с таким же количеством неизвестных, которая решается любым способом, применяемым к системам линейных алгебраических уравнений (СЛАУ). Однако с точки зрения статистического подхода такое решение задачи является ненадежным, поскольку измеренные значения переменных (5) содержат различные виды погрешностей. Поэтому для получения надежных оценок параметров уравнения (4) объём выборки должен значительно превышать количество определяемых по нему параметров. Практически, как было сказано ранее, объём выборки должен превышать количество параметров при xj в уравнении (4) в 6-7 раз. имеют нормальное распределение
имеют нормальное распределение  . Выполнимость этого условия нужна для проверки статистических гипотез и построения интервальных оценок.
. Выполнимость этого условия нужна для проверки статистических гипотез и построения интервальных оценок. — n – мерный вектор – столбец наблюдений зависимой переменной;
— n – мерный вектор – столбец наблюдений зависимой переменной; — ( p +1) – мерный вектор – столбец параметров уравнения регрессии (3);
— ( p +1) – мерный вектор – столбец параметров уравнения регрессии (3); — n – мерный вектор – столбец отклонений выборочных значений yi от значений
— n – мерный вектор – столбец отклонений выборочных значений yi от значений  , получаемых по уравнению (4).
, получаемых по уравнению (4). :
:
 (6)
(6) (7)
(7) , который, собственно, и минимизируется по МНК, можно записать как произведение вектора – строки е’ на вектор – столбец е :
, который, собственно, и минимизируется по МНК, можно записать как произведение вектора – строки е’ на вектор – столбец е : (8)
(8) (9)
(9) 10)
10) — матрица, обратная к
— матрица, обратная к  .
.