Структура регрессии машинного обучения временных рядов
Дата публикации Apr 6, 2019

Введение
Время! Одна из самых сложных концепций во Вселенной. Я много лет изучал физику и видел, как самые блестящие ученые пытаются справиться с концепцией времени. В машинном обучении даже мы далеки от тех сложных физических теорий, в которых изменяется общее понимание концепции времени, существование времени и последовательность наблюдений в проблеме ОД могут значительно усложнить проблему.
Машинное обучение для временных рядов:

Временной ряд — это последовательность наблюдений, сделанных последовательно во времени. Прогнозирование временных рядов включает в себя выбор моделей, затем подгонку их к историческим данным, а затем их использование для прогнозирования будущих наблюдений. Поэтому, например, min (s), day (s), month (s), ago измерения используются в качестве входных данных для прогнозирования

следующие минуты, день (ы), месяц (ы). Шаги, которые, как считается, сдвигают данные назад во времени (последовательности), называемые временами задержки или запаздывания. Следовательно, проблема временного ряда может быть преобразована в контролируемый ML, добавляя задержки измерений в качестве входных данных контролируемого ML. см. рис.3 справа. Как правило, исследуйте количество лагов как гиперпараметр.

Перекрестная проверка для временных рядов
Перекрестная проверка временных рядов отличается от проблем машинного обучения тем, что время или последовательность не задействованы. В случае отсутствия времени мы выбираем случайное подмножество данных в качестве набора проверки для оценки точности измерения. Во временных рядах мы часто прогнозируем ценность в будущем. Таким образом, данные проверки всегда должны происходитьпоследанные обучения. Есть две схемыраздвижное окноа такжеМетоды проверки прямого цепочки, что может быть использовано для временного ряда CV.

На рис. 5 сверху показан метод скользящего окна. Для этого метода мы тренируемся на n-точках данных и проверяем прогноз на следующих n-точках данных, сдвигая окно 2n обучения / проверки во времени для следующего шага. На рис. 5 внизу показан метод прямой цепочки. Для этого метода мы обучаемся последним n-точкам данных и проверяем прогноз на следующих m-точках данных, сдвигая окно обучения и проверки n + m во времени. Таким образом, мы можем оценить параметры нашей модели. Чтобы проверить достоверность модели, мы можем использовать блок данных в конце нашего временного ряда, который зарезервирован для тестирования модели с изученными параметрами.

На рис. 6. показано, как работает прямое CV. Здесь есть одно отставание. Таким образом, мы тренируем модель с первой по третью секунды / мин / час / день и т. Д., Затем проверяем далее и так далее. Поскольку теперь мы знакомимся с проблемой TS, давайте выберем проблему временных рядов и построим модель прогнозирования.
Прогнозирование недельных продаж
Представьте себе, что менеджер магазина попросил нас построить модель ML для прогнозирования количества продаж на следующую неделю. Модель должна запускаться каждое воскресенье, а результат прогноза должен сообщаться каждое утро понедельника. Затем менеджер может принять решение о количестве заказов на неделю. Менеджер предоставляет нам данные о продажах 811 товаров за 52 недели. Данные о продажах можно найти вUCI Repositoryилиkaggle,
Давайте посмотрим на данные.

Многие исследователи данных могут создать единую модель для каждого продукта для прогнозирования количества продаж. И хотя это может хорошо работать, у нас могут быть проблемы из-за наличия только 52 точек данных для каждой модели, что действительно мало! Хотя такой подход возможен, он не может быть лучшим решением. Кроме того, если между числом продаж двух или более продуктов существует взаимодействие, мы можем пропустить их взаимодействие, построив единую модель для каждого продукта. Поэтому в этом посте мы рассмотрим, как мы можем построить модели прогнозирования для нескольких временных рядов.
Подготовка данных
Необработанные данные имеют столбец для кода продукта и 52 недели для продаж. Во-первых, мы собираемся создать новый фрейм данных, объединив данные за недели. Таким образом, новый фрейм данных имеет три столбца: код продукта, неделя и объем продаж. Кроме того, «W» и «P» исключены из недели и продукта соответственно. Итак, давайте посмотрим на голову и хвост нового фрейма данных

Чтобы ознакомиться с набором данных, распределение продаж представлено на рис.7. Видно, что существует большое количество продуктов с очень небольшим объемом продаж, и данные также смещаются влево. Влияние проблемы на моделирование будет обсуждаться позже.

Основное проектирование
Поскольку целью этого поста не является Feature Engineering for TS, мы постараемся сделать эту часть максимально простой. Давайте создадим две функции, которые обычно используются для временных рядов. Один шаг назад во времени, 1 лаг (смещение = 1) и разница между количеством покупок неделю назад (W 1) и предыдущей неделей, то есть две недели назад (W2). После этого, поскольку из-за запаздывания и различий в наборе данных есть ноль, см. Рис. 4, мы их отбрасываем. Поэтому, когда мы смотрим на заголовок фрейма данных, он начинается с недели = 2.

Классы «ToSupervised» и «ToSupervisedDiff», код 1 и код 2, показанные в разделе кодирования, используются для получения нового кадра данных через простой конвейер:
Теперь данные имеют правильную форму для их использования на контролируемой ОД.
Прямая перекрестная проверка:
Другая проблема, когда мы работаем над временными рядами, нам приходится иметь дело с его резюме для временных рядов. Мы выбрали прямую цепочку для проверки модели. Чтобы избежать очень хорошей модели в течение небольшого количества недель, мы будем использовать каждую неделю от 40 до 52, повторяя процесс по одной за раз, и вычислять счет. Следовательно, k-кратный код в этой схеме можно найти в C. 3.
Поскольку этот пост является просто демонстрацией, я не разделяю тестовый набор данных. В реальном проекте всегда оставляйте несколько периодов в виде набора тестовых данных для оценки модели на невидимых данных.
метрический
Поскольку проблема заключается в регрессии, существует несколько известных метрик для оценки модели, таких как среднеквадратическая ошибка (MSE), средняя абсолютная ошибка (MAE), среднеквадратичная ошибка (RMSE), среднеквадратичная ошибка журнала (RMSLE) R-квадрат и пр. У каждой из этих метрик есть свой вариант использования, и они по-разному наказывают ошибку, хотя между ними также есть некоторые сходства. В этом посте RMSLE выбран для оценки модели.
Исходные данные:
Обычно, когда мы строим модель, мы можем прийти с очень простым предположением, что мы ожидаем, что использование ML может улучшить ее. Здесь, давайте предположим, что количество каждого продукта продается на текущей неделе, оно будет таким же на следующую неделю. Это означает, что если продукт-1 будет продаваться 10 раз в неделю, его количество продаж будет таким же, как и в течение недели 2. Как правило, это не плохое предположение. Итак, давайте рассмотрим это предположение в качестве нашей базовой модели.
Базовая модель закодирована в C. 5, давайте посмотрим, как работает базовая модель
Сгиб: 0, ошибка: 0,520
Сгиб: 1, ошибка: 0,517
Сгиб: 2, ошибка: 0,510
Сгиб: 3, ошибка: 0.508
Сгиб: 4, ошибка: 0,534
Сгиб: 5, ошибка: 0,523
Сгиб: 6, ошибка: 0,500
Сгиб: 7, ошибка: 0,491
Сгиб: 8, ошибка: 0.506
Сгиб: 9, ошибка: 0,505
Сгиб: 10, ошибка: 0,522
Сгиб: 11, ошибка: 0,552
Общая ошибка 0.516
Здесь, от 0 до 11 указывают на неделю от 40 до недели = 52. Среднее значение RMSLE для базовой модели за эти 12 недель составляет 0,51. Это можно рассматривать как большую ошибку, которая может возникнуть из-за того, что огромное количество предметов было продано очень небольшими суммами, как показано на фиг.7.
Модели машинного обучения:
Теперь мы применим ML для улучшения базового прогноза. Давайте определим класс регрессора временных рядов, C. 5, который работает с нашей перекрестной проверкой временных рядов. Этот класс получает резюме и модель, а также возвращает прогноз модели и ее оценку. Существует широкий спектр алгоритмов ML, которые можно использовать в качестве оценщика. Здесь мы выбираем случайный лес. Проще говоря, RF можно рассматривать как комбинацию суммирования и случайного выбора столбцов функций поверх деревьев решений. Следовательно, это уменьшает дисперсию предсказания модели дерева решений. Таким образом, он обычно имеет лучшую производительность, чем одно дерево, и имеет более низкую производительность, чем методы ансамбля, которые предназначены для уменьшения ошибки смещения модели дерева решений.
Сгиб: 0, ошибка: 0,4624
Сгиб: 1, ошибка: 0,4596
Сгиб: 2, ошибка: 0,4617
Сгиб: 3, ошибка: 0,4666
Сгиб: 4, ошибка: 0,4712
Сгиб: 5, ошибка: 0,4310
Сгиб: 6, ошибка: 0,4718
Сгиб: 7, ошибка: 0,4494
Сгиб: 8, ошибка: 0,4608
Сгиб: 9, ошибка: 0,4470
Сгиб: 10, ошибка: 0,4746
Сгиб: 11, ошибка: 0,4865
Общая ошибка 0.4619
Кажется, что модель работает и ошибка уменьшается. Давайте добавим больше лагов и еще раз оценим модель. Поскольку мы построили конвейер, добавить больше лагов было бы очень просто.
Сгиб: 0, ошибка: 0,4312
Сгиб: 1, ошибка: 0,4385
Сгиб: 2, ошибка: 0,4274
Сгиб: 3, ошибка: 0,4194
Сгиб: 4, ошибка: 0,4479
Сгиб: 5, ошибка: 0,4070
Сгиб: 6, ошибка: 0,4395
Сгиб: 7, ошибка: 0,4333
Сгиб: 8, ошибка: 0,4387
Сгиб: 9, ошибка: 0,4305
Сгиб: 10, ошибка: 0,4591
Сгиб: 11, ошибка: 0,4534
Общая ошибка 0.4355
Кажется, что ошибка предсказания снова уменьшается, и модель учится больше. Мы можем продолжить добавлять лаги и посмотреть, как меняется производительность модели; однако мы отложим этот процесс до тех пор, пока не будем использовать LGBM в качестве оценщика.
Статистические преобразования:
Распределение продаж, рис. 7 показывает, что данные смещаются в сторону низкого количества продаж или влево. Обычно преобразования Log полезны при применении к искаженным распределениям, так как они имеют тенденцию расширять значения, попадающие в диапазон более низких величин, и имеют тенденцию сжимать или уменьшать значения, попадающие в диапазон более высоких величин. Интерпретируемость моделей изменяется, когда мы выполняем статистические преобразования, поскольку коэффициенты больше не говорят нам об исходных характеристиках, а о преобразованных признаках. Поэтому, в то время как мы применяем np.log1p к номеру продаж, чтобы преобразовать его распределение, чтобы стать ближе к нормальному распределению, мы также применяем np.expm1 к результату прогноза, см. C. 6, TimeSeriesRegressorLog. Теперь повторим расчет с указанным преобразованием
так что у нас есть
Сгиб: 0, ошибка: 0,4168
Сгиб: 1, ошибка: 0,4221
Сгиб: 2, ошибка: 0,4125
Сгиб: 3, ошибка: 0,4035
Сгиб: 4, ошибка: 0,4332
Сгиб: 5, ошибка: 0,3977
Сгиб: 6, ошибка: 0,4263
Сгиб: 7, ошибка: 0,4122
Сгиб: 8, ошибка: 0,4301
Сгиб: 9, ошибка: 0,4375
Сгиб: 10, ошибка: 0,4462
Сгиб: 11, ошибка: 0,4727
Общая ошибка 0.4259
Это показывает, что производительность модели улучшается, а ошибка снова уменьшается.
Ансамбль МЛ:
Теперь пришло время использовать более сильную оценку ML для улучшения прогнозирования. Мы выбрали LightGBM в качестве нового оценщика. Итак, давайте повторим расчет
Сгиб: 0, ошибка: 0,4081
Сгиб: 1, ошибка: 0,3980
Сгиб: 2, ошибка: 0,3953
Сгиб: 3, ошибка: 0,3949
Сгиб: 4, ошибка: 0,4202
Сгиб: 5, ошибка: 0,3768
Сгиб: 6, ошибка: 0,4039
Сгиб: 7, ошибка: 0,3868
Сгиб: 8, ошибка: 0,3984
Сгиб: 9, ошибка: 0,4075
Сгиб: 10, ошибка: 0,4209
Сгиб: 11, ошибка: 0,4520
Общая ошибка 0,4052
Опять же, мы успешно улучшили прогноз.
Настройка количества шагов:
В этом разделе мы собираемся настроить количество шагов (лагов / различий). Я намеренно откладываю настройку шагов в этом разделе после использования LGBM в качестве регрессора, потому что это быстрее, чем RF. Рис. 8 ясно показывает, что при добавлении дополнительных шагов в модель ошибка уменьшается; однако, как мы ожидаем, видно, что после преодоления порога в пределах шагов = 14, добавление дальнейших шагов не уменьшит ошибку значительно. Возможно, вам будет интересно определить порог ошибки для остановки этого процесса. Шаги = 20 выбран для остальной части расчета. Пожалуйста, проверьте код C 7. A и B для настройки.

Гиперпараметры настройки:
В этой части мы собираемся реализовать метод поиска по сетке таким образом, чтобы мы могли применять его по конвейеру, см. Код 8 A и B. C.8. Код заимствован из библиотеки Sklearn. Целью этой части является не создание полностью настроенной модели. Мы пытаемся показать, как рабочий процесс. После небольшой настройки ошибка становится
Когда лучшие параметры настройки находятся на грани параметров настройки, это означает, что мы должны пересмотреть диапазон гиперпараметров и пересчитать модель, хотя мы не будем делать это на этом посту.
Прогноз против реальных продаж
На рис. 9 показано значение прогнозирования в зависимости от объема продаж на 52 неделе. Видно, что модель хорошо работает для показателей продаж до 15; однако, он прогнозирует плохо для продаж около 30. Как мы обсуждаем на рис. 7, мы могли бы построить разные модели для различного диапазона продаж, чтобы преодолеть эту проблему и иметь более надежную модель прогнозирования, хотя дальнейшее моделирование выходит за рамки этого поста и этот пост уже так долго.

Наконец, на рис. 10 показаны все наши попытки прогнозировать продажи. Мы начали с очень простого предположения в качестве базовой линии и попытались улучшить его, используя различные лаги / различия, статистическое преобразование и применяя различные алгоритмы машинного обучения для улучшения прогнозирования. Базовая ошибка составляла 0,516, а ошибка настроенной модели — 0,3868, что означает снижение ошибки на 25%.

Есть еще много способов улучшить представленную модель, например, правильно обрабатывать продукты как категориальные переменные, расширять возможности инженера, настраивать гиперпараметры, использовать различные алгоритмы машинного обучения, а также смешивать и складывать.
Вывод:
Мы построили конвейер прогнозирования временных рядов для прогнозирования еженедельных продаж. Мы начали с простого логического предположения в качестве базовой модели; затем мы могли бы уменьшить базовую ошибку на 25%, построив конвейер, включающий разработку базовых функций, статистическое преобразование, применение Random forest и LGBM и, наконец, их настройку. Кроме того, мы обсудили различные методы перекрестной проверки временных рядов. Кроме того, мы покажем, как мы можем использовать базовые классы Sklearn для построения конвейера.
Кодирование:
Полный код этого поста можно найти на моемGitHub,
Анализ временных рядов
В трех предыдущих заметках описаны регрессионные модели, позволяющие прогнозировать отклик по значениям объясняющих переменных. В настоящей заметке мы покажем, как с помощью этих моделей и других статистических методов анализировать данные, собранные на протяжении последовательных временных интервалов. В соответствии с особенностями каждой компании, упомянутой в сценарии, мы рассмотрим три альтернативных подхода к анализу временных рядов. [1]
Материал будет проиллюстрирован сквозным примером: прогнозирование доходов трех компаний. Представьте себе, что вы работаете аналитиком в крупной финансовой компании. Чтобы оценить инвестиционные перспективы своих клиентов, вам необходимо предсказать доходы трех компаний. Для этого вы собрали данные о трех интересующих вас компаниях — Eastman Kodak, Cabot Corporation и Wal-Mart. Поскольку компании различаются по виду деловой активности, каждый временной ряд обладает своими уникальными особенностями. Следовательно, для прогнозирования необходимо применять разные модели. Как выбрать наилучшую модель прогнозирования для каждой компании? Как оценить инвестиционные перспективы на основе результатов прогнозирования?
Обсуждение начинается с анализа ежегодных данных. Демонстрируются два метода сглаживания таких данных: скользящее среднее и экспоненциальное сглаживание. Затем демонстрируется процедура вычисления тренда с помощью метода наименьших квадратов и более сложные методы прогнозирования. В заключение, эти модели распространяются на временные ряды, построенные на основе ежемесячных или ежеквартальных данных.
Скачать заметку в формате Word или pdf, примеры в формате Excel
Прогнозирование в бизнесе
Поскольку экономические условия с течением времени изменяются, менеджеры должны прогнозировать влияние, которое эти изменения окажут на их компанию. Одним из методов, позволяющих обеспечить точное планирование, является прогнозирование. Несмотря на большое количество разработанных методов, все они преследуют одну и ту же цель — предсказать события, которые произойдут в будущем, чтобы учесть их при разработке планов и стратегии развития компании.
Современное общество постоянно испытывает необходимость в прогнозировании. Например, чтобы выработать правильную политику, члены правительства должны прогнозировать уровни безработицы, инфляции, промышленного производства, подоходного налога отдельных лиц и корпораций. Чтобы определить потребности в оборудовании и персонале, директора авиакомпаний должны правильно предсказать объем авиаперевозок. Для того чтобы создать достаточное количество мест в общежитии, администраторы колледжей или университетов хотят знать, сколько студентов поступят в их учебное заведение в следующем году.
Существуют два общепринятых подхода к прогнозированию: качественный и количественный. Методы качественного прогнозирования особенно важны, если исследователю недоступны количественные данные. Как правило, эти методы носят весьма субъективный характер. Если статистику доступны данные об истории объекта исследования, следует применять методы количественного прогнозирования. Эти методы позволяют предсказать состояние объекта в будущем на основе данных о его прошлом. Методы количественного прогнозирования разделяются на две категории: анализ временных рядов и методы анализа причинно-следственных зависимостей.
Временной ряд — это набор числовых данных, полученных в течение последовательных периодов времени. Метод анализа временных рядов позволяет предсказать значение числовой переменной на основе ее прошлых и настоящих значений. Например, ежедневные котировки акций на Нью-Йоркской фондовой бирже образуют временной ряд. Другим примером временного ряда являются ежемесячные значения индекса потребительских цен, ежеквартальные величины валового внутреннего продукта и ежегодные доходы от продаж какой-нибудь компании.
Методы анализа причинно-следственных зависимостей позволяют определить, какие факторы влияют на значения прогнозируемой переменной. К ним относятся методы множественного регрессионного анализа с запаздывающими переменными, эконометрическое моделирование, анализ лидирующих индикаторов, методы анализа диффузионных индексов и других экономических показателей. Мы расскажем лишь о методах прогнозирования на основе анализа временных рядов.
Компоненты классической мультипликативной модели временных рядов
Основное предположение, лежащее в основе анализа временных рядов, состоит в следующем: факторы, влияющие на исследуемый объект в настоящем и прошлом, будут влиять на него и в будущем. Таким образом, основные цели анализа временных рядов заключаются в идентификации и выделении факторов, имеющих значение для прогнозирования. Чтобы достичь этой цели, были разработаны многие математические модели, предназначенные для исследования колебаний компонентов, входящих в модель временного ряда. Вероятно, наиболее распространенной является классическая мультипликативная модель для ежегодных, ежеквартальных и ежемесячных данных. Для демонстрации классической мультипликативной модели временных рядов рассмотрим данные о фактических доходах компании Wm.Wrigley Jr. Company за период с 1982 по 2001 годы (рис. 1).

Рис. 1. График фактического валового дохода компании Wm.Wrigley Jr. Company (млн. долл. в текущих ценах) за период с 1982 по 2001 годы
Как видим, на протяжении 20 лет фактический валовой доход компании имел возрастающую тенденцию. Эта долговременная тенденция называется трендом. Тренд — не единственный компонент временного ряда. Кроме него, данные имеют циклический и нерегулярный компоненты. Циклический компонент описывает колебание данных вверх и вниз, часто коррелируя с циклами деловой активности. Его длина изменяется в интервале от 2 до 10 лет. Интенсивность, или амплитуда, циклического компонента также не постоянна. В некоторые годы данные могут быть выше значения, предсказанного трендом (т.е. находиться в окрестности пика цикла), а в другие годы — ниже (т.е. быть на дне цикла). Любые наблюдаемые данные, не лежащие на кривой тренда и не подчиняющиеся циклической зависимости, называются иррегулярными или случайными компонентами. Если данные записываются ежедневно или ежеквартально, возникает дополнительный компонент, называемый сезонным. Все компоненты временных рядов, характерных для экономических приложений, приведены на рис. 2.

Рис. 2. Факторы, влияющие на временные ряды
Классическая мультипликативная модель временного ряда утверждает, что любое наблюдаемое значение является произведением перечисленных компонентов. Если данные являются ежегодными, наблюдение Yi, соответствующее i-му году, выражается уравнением:
где Ti — значение тренда, Ci — значение циклического компонента в i-ом году, Ii — значение случайного компонента в i-ом году.
Если данные измеряются ежемесячно или ежеквартально, наблюдение Yi, соответствующее i-му периоду, выражается уравнением:
где Ti — значение тренда, Si — значение сезонного компонента в i-ом периоде, Ci — значение циклического компонента в i-ом периоде, Ii — значение случайного компонента в i-ом периоде.
На первом этапе анализа временных рядов строится график данных и выявляется их зависимость от времени. Сначала необходимо выяснить, существует ли долговременное возрастание или убывание данных (т.е. тренд), или временной ряд колеблется вокруг горизонтальной линии. Если тренд отсутствует, то для сглаживания данных можно применить метод скользящих средних или экспоненциального сглаживания.
Сглаживание годовых временных рядов
В сценарии мы упомянули о компании Cabot Corporation. Имея штаб-квартиру в Бостоне, штат Массачусеттс, она специализируется на производстве и продаже химикатов, строительных материалов, продуктов тонкой химии, полупроводников и сжиженного природного газа. Компания имеет 39 заводов в 23 странах. Рыночная стоимость компании составляет около 1,87 млрд. долл. Ее акции котируются на Нью-Йоркской фондовой бирже под аббревиатурой СВТ. Доходы компании за указанный период приведены на рис. 3.

Рис. 3. Доходы компании Cabot Corporation в 1982–2001 годах (млрд. долл.)
Как видим, долговременная тенденция повышения доходов затемнена большим количеством колебаний. Таким образом, визуальный анализ графика не позволяет утверждать, что данные имеют тренд. В таких ситуациях можно применить методы скользящего среднего или экспоненциального сглаживания.
Скользящие средние. Метод скользящих средних весьма субъективен и зависит от длины периода L, выбранного для вычисления средних значений. Для того чтобы исключить циклические колебания, длина периода должна быть целым числом, кратным средней длине цикла. Скользящие средние для выбранного периода, имеющего длину L, образуют последовательность средних значений, вычисленных для последовательностей длины L. Скользящие средние обозначаются символами MA(L).
Предположим, что мы хотим вычислить пятилетние скользящие средние значения по данным, измеренным в течение n = 11 лет. Поскольку L = 5, пятилетние скользящие средние образуют последовательность средних значений, вычисленных по пяти последовательным значениям временного ряда. Первое из пятилетних скользящих средних значений вычисляется путем суммирования данных о первых пяти годах с последующим делением на пять:

Второе пятилетнее скользящее среднее вычисляется путем суммирования данных о годах со 2-го по 6-й с последующим делением на пять:

Этот процесс продолжается, пока не будет вычислено скользящее среднее для последних пяти лет. Работая с годовыми данными, следует полагать число L (длину периода, выбранного для вычисления скользящих средних) нечетным. В этом случае невозможно вычислить скользящие средние для первых (L – 1)/2 и последних (L – 1)/2 лет. Следовательно, при работе с пятилетними скользящими средними невозможно выполнить вычисления для первых двух и последних двух лет. Год, для которого вычисляется скользящее среднее, должен находиться в середине периода, имеющего длину L. Если n = 11, a L = 5, первое скользящее среднее должно соответствовать третьему году, второе — четвертому, а последнее — девятому. На рис. 4 показаны графики 3- и 7-летних скользящих средних, вычисленные для доходов компании Cabot Corporation за период с 1982 по 2001 годы.

Рис. 4. Графики 3- и 7-летних скользящих средних, вычисленные для доходов компании Cabot Corporation
Обратите внимание на то, что при вычислении трехлетних скользящих средних проигнорированы наблюдаемые значения, соответствующие первому и последнему годам. Аналогично при вычислении семилетних скользящих средних нет результатов для первых и последних трех лет. Кроме того, семилетние скользящие средние намного больше сглаживают временной ряд, чем трехлетние. Это происходит потому, что семилетним скользящим средним соответствует более долгий период. К сожалению, чем больше длина периода, тем меньшее количество скользящих средних можно вычислить и представить на графике. Следовательно, больше семи лет для вычисления скользящих средних выбирать нежелательно, поскольку из начала и конца графика выпадет слишком много точек, что исказит форму временного ряда.
Экспоненциальное сглаживание. Для выявления долговременных тенденций, характеризующих изменения данных, кроме скользящих средних, применяется метод экспоненциального сглаживания. Этот метод позволяет также делать краткосрочные прогнозы (в рамках одного периода), когда наличие долговременных тенденций остается под вопросом. Благодаря этому метод экспоненциального сглаживания обладает значительным преимуществом над методом скользящих средних.
Метод экспоненциального сглаживания получил свое название от последовательности экспоненциально взвешенных скользящих средних. Каждое значение в этой последовательности зависит от всех предыдущих наблюдаемых значений. Еще одно преимущество метода экспоненциального сглаживания над методом скользящего среднего заключается в том, что при использовании последнего некоторые значения отбрасываются. При экспоненциальном сглаживании веса, присвоенные наблюдаемым значениям, убывают со временем, поэтому после выполнения вычислений наиболее часто встречающиеся значения получат наибольший вес, а редкие величины — наименьший. Несмотря на громадное количество вычислений, Excel позволяет реализовать метод экспоненциального сглаживания.
Уравнение, позволяющее сгладить временной ряд в пределах произвольного периода времени i, содержит три члена: текущее наблюдаемое значение Yi, принадлежащее временному ряду, предыдущее экспоненциально сглаженное значение Ei–1 и присвоенный вес W.
где Ei – значение экспоненциально сглаженного ряда, вычисленное для i-го периода, Ei–1 – значение экспоненциально сглаженного ряда, вычисленное для (i – 1)-гo периода, Yi – наблюдаемое значение временного ряда в i-ом периоде, W – субъективный вес, или сглаживающий коэффициент (0  = b0 + b1Xi, в него можно подставлять значения X, чтобы определять отклик Y.
= b0 + b1Xi, в него можно подставлять значения X, чтобы определять отклик Y.
Если при аппроксимации временного ряда с помощью метода наименьших квадратов первое наблюдение расположить в начале координат, поставив его в соответствие значению X = 0, интерпретация коэффициентов упрощается. Все последующие наблюдения получают целочисленные номера: 1, 2, 3, так что n-е (последнее) наблюдение будет иметь номер n – 1. Например, если временной ряд записывается на протяжении 20 лет, первый год обозначается цифрой 0, второй— цифрой 1, третий — цифрой 2 и так далее, а последний (20-й) год — числом 19.
В сценарии была упомянута компания Wm. Wrigley Jr. Company, являющаяся крупнейшим производителем жевательной резинки в США. Акции компании котируются на Нью-Йоркской фондовой бирже под аббревиатурой WWY. Рыночная стоимость компании составляет 13 млрд. долл. Фактические доходы компании Wm. Wrigley Jr. Company в 1982-2001 годах приведены на рис. 7. Затем с помощью индекса потребительских цен (Consumer Price Index — CPI), вычисляемого Бюро статистики Министерства труда США, фактические доходы были преобразованы в реальные. Для этого следует умножить величину фактического дохода на коэффициент 100/CPI.

Рис. 7. Фактические и реальные доходы компании Wm. Wrigley Jr. Company в 1982-2001 годах
Обозначим последовательные значения переменной X с помощью целых чисел от 0 до 19, а затем выполним регрессионный анализ с помощью Пакета анализа (рис. 8).

Рис. 8. Модель линейной регрессии для предсказания реального дохода компании Wm. Wrigley Jr.; построена с помощью Пакета анализа Excel
Уравнение линейной регрессии имеет следующий вид (см. ячейки Е17, Е18 на рис. 8): Ŷi = 498,656 + 45,485Хi, где началом координат является 1982 год, а шаг переменной X равен одному году. Регрессионные коэффициенты интерпретируются следующим образом:
- Сдвиг b0 = 498,656 представляет собой предсказанное среднее значение реальных доходов компании Wm. Wrigley Jr. Company в 1982 году.
- Наклон b1 = 45,485 представляет собой предсказанное увеличение реальных доходов компании в среднем на 45,485 млн. долл. в год.
Линия тренда и временной ряд реальных доходов показаны на рис. 9. График можно построить на основании уравнения линейной регрессии (колонка D; рис. 9а) или простым добавлением линии тренда на ранее построенный график доходов (рис. 9б). Видно, что на протяжении ряда лет доходы компании линейно возрастали. Скорректированный коэффициент r 2 равен 0,966 (ячейка Е6 на рис. 8). Следовательно, все изменения реальных доходов хорошо описываются линейным трендом. Возникает вопрос: а нельзя ли выбрать еще более точную модель? Для ответа на него рассмотрим еще две модели — квадратичную и экспоненциальную.

Рис. 9. Линия тренда реальных доходов компании Wm. Wrigley Jr., вычисленная с помощью метода наименьших квадратов, построенная: (а) на основании уравнения линейной регрессии; (б) добавлением линии тренда на график
Модель квадратичного тренда, или полиномиальная модель второй степени является простейшей нелинейной моделью, применяемой для прогнозирования:  . Уравнение квадратичного тренда:
. Уравнение квадратичного тренда:

где b0 – оценка сдвига отклика Y, b1 – оценка линейного эффекта, b2 – оценка квадратичного эффекта.
Построим квадратичный тренд путем добавления линии тренда на график с исходными данными (рис. 10).
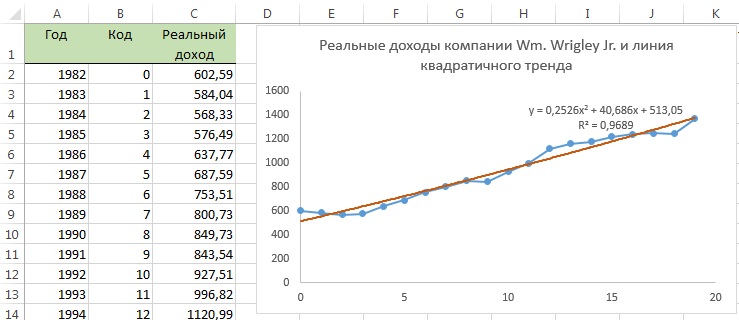
Рис. 10. График квадратичного тренда для предсказания реальных доходов компании Wm. Wrigley Jr.
Как показано на рис. 10, уравнение линейной регрессии: Y =513,05 + 40,686Х + 0,2526Х 2 , где началом координат является 1982 год, а шаг переменной X равен одному году. Этот график аппроксимирует временной ряд почти так же, как и линейный тренд. Скорректированный коэффициент r 2 равен 0,965 (рис. 11), а t-статистика, учитывающая вклад квадратичного эффекта, равна 0,656 (соответствующее р-значение равно 0,521).

Рис. 11. Модель квадратичного тренда реальных годовых доходов
Модель экспоненциального тренда. Если временной ряд является возрастающим, а относительное изменение данных — постоянным, можно применять модель экспоненциального тренда. Учитывая сложность формул ограничимся только графическим анализом. Для этого на график с исходными данными добавим линию экспоненциального тренда, а также выведем на график уравнение тренда и параметр r 2 (рис. 12).

Рис. 12. График экспоненциального тренда для предсказания реальных доходов компании Wm. Wrigley Jr.
Экспоненциальная модель аппроксимирует временной ряд почти так же, как линейная и квадратичная модель. Скорректированный коэффициент r 2 равен 0,960, в то время как для линейной модели этот коэффициент равен 0,966, а для квадратичной – 0,965.
Выбор модели на основе разностей первого и второго порядка, а также относительных разностей
Для аппроксимации данных о реальном доходе компании Wm. Wrigley Jr. Company мы применили три модели: линейную, квадратичную и экспоненциальную. Какая из этих моделей лучше? Кроме визуального впечатления и сравнения скорректированных коэффициентов r 2 , в качестве инструмента для оценки качества модели применяются разности первого, второго и третьего порядка.
Выбор модели на основе анализа разностей первого и второго порядка, а также относительных разностей:
Не следует ожидать, что модель будет идеально аппроксимировать конкретный набор данных. Несмотря на это, при выборе подходящей модели необходимо анализировать разности первого и второго порядка, а также относительные разности. Для нашего примера с компанией Wm. Wrigley Jr. результаты такого анализа приведены на рис. 13.

Рис. 13. Разности первого и второго порядка, а также относительные разности, вычисленные на основе данных о реальных доходах компании Wm. Wrigley Jr.
Анализ рис. 13 показывает, что разности первого и второго порядка, а также относительные разности не остаются постоянными. Итак, несмотря на то, что скорректированный коэффициент r 2 у всех трех моделей, рассмотренных выше, одинаков и приближенно равен 0,96, возможно, существуют более точные модели.
Вычисление тренда с помощью авторегрессии и прогнозирование
Другой подход к прогнозированию основан на авторегрессионной модели. Часто значения временного ряда в какой-то момент времени сильно коррелируют как с предшествующими, так и с последующими значениями. Автокорреляция первого порядка оценивает степень зависимости между последовательными значениями временного ряда. Автокорреляция второго порядка оценивает силу связи между значениями, разделенными двумя временными интервалами. Автокорреляция р-го порядка представляет собой величину корреляции между значениями, разделенными р временными интервалами. Авторегрессионная модель позволяет лучше оценить предысторию и получить более точный прогноз.

Авторегрессионная модель первого порядка внешне напоминает модель простой линейной регрессии, а авторегрессионные модели второго и р-го порядков похожи на модель множественной регрессии. В регрессионных моделях параметры регрессии обозначаются символами β0, β1, …, βk а их оценки — символами b0, b1, …, bk. В авторегрессионных моделях аналогичные параметры обозначаются символами А0, А1 …, Аp, а их оценки — символами а0, а0, …, аp.
В авторегрессионной модели первого порядка рассматриваются лишь соседние значения временного ряда. В авторегрессионной модели второго порядка оценивается зависимость и корреляция как между соседними, так и между последовательными значениями временного ряда, разделенными двумя временными интервалами. В авторегрессионной модели р-го порядка оценивается зависимость и корреляция между соседними значениями, последовательными значениями временного ряда, разделенными двумя временными интервалами, и так далее вплоть до последовательных значений временного ряда, разделенных р временными интервалами.
Выбор подходящей авторегрессионной модели представляет собой нелегкую задачу. В процессе ее решения необходимо оценить простоту модели и возможные потери вследствие игнорирования автокорреляции между данными. С другой стороны, модели высоких порядков сопряжены с оценками многочисленных параметров, которые могут оказаться бесполезными, особенно если длина n временного ряда не очень велика. Это происходит потому, что при вычислении параметра Ар каждое значение временного ряда Yi сравнивается с его ближайшими соседями, расположенными не далее, чем через р временных интервалов (т.е. величина Yi сравнивается со значениями Yi–1, Yi–2, …, Yi–p). Иными словами, чем выше порядок авторегрессионной модели, тем больше первых ее членов теряется.
Выбрав модель и применив метод наименьших квадратов для вычисления оценок регрессионных параметров, необходимо оценить ее адекватность. Для этого можно использовать либо авторегрессионную модель конкретного порядка, которую уже применяли для похожих данных, либо сразу построить модель с несколькими параметрами, а затем последовательно исключать из нее параметры, не имеющие статистически значимого вклада. В последнем случае применяется t-критерий значимости параметра Аp, имеющего наивысший порядок в данной авторегрессионной модели. Нулевая и альтернативная гипотезы формулируются следующим образом: H0: Ар = 0, H1: Ар ≠ 0.
Использование t-критерия значимости параметра авторегрессии Ар, имеющего наивысший порядок:

где Аp — гипотетическое значение параметра, имеющего наивысший порядок в регрессионной модели, ар — оценка параметра авторегрессии Аp, имеющего наивысший порядок, Sap — стандартная ошибка оценки ар. Тестовая t-статистика имеет t-распределение с n–2р–1 степенями свободы. [2]
При заданном уровне значимости α нулевая гипотеза отклоняется, если тестовая t-статистика больше верхнего или меньше нижнего критического уровня t-распределения. Иначе говоря, решающее правило формулируется следующим образом: если t > tU или t α = 0,05, нулевую гипотезу Н0 отклонять нельзя. Таким образом, параметр третьего порядка не имеет статистической значимости в авторегрессионной модели и должен быть удален.
Повторим анализ для авторегрессионной модели второго порядка (рис. 17). Оценка параметра, имеющего наивысший порядок, а2 = –0,205, а ее стандартная ошибка равна 0,276. Для проверки гипотез Н0: А2 = 0 и Н1: А2 ≠ 0 вычислим t-статистику:


Рис. 17. Авторегрессионная модель второго порядка для реальных доходов компании Wm. Wrigley Jr.
При уровне значимости α = 0,05, критические величины двухстороннего t-критерия с n–2p–1 = 20–2*2–1 = 15 степенями свободы равны: tL =СТЬЮДЕНТ.ОБР(0,025;15) = –2,131; tU =СТЬЮДЕНТ.ОБР(0,975;15) = +2,131. Поскольку –2,131 α = 0,05, нулевую гипотезу Н0 отклонять нельзя. Таким образом, параметр второго порядка не является статистически значимым, и его следует удалить из модели.
Повторим анализ для авторегрессионной модели первого порядка (рис. 18). Оценка параметра, имеющего наивысший порядок, а1 = 1,024, а ее стандартная ошибка равна 0,039. Для проверки гипотез Н0: А1 = 0 и Н1: А1 ≠ 0 вычислим t-статистику:


Рис. 18. Авторегрессионная модель первого порядка для реальных доходов компании Wm. Wrigley Jr.
При уровне значимости α = 0,05, критические величины двухстороннего t-критерия с n–2p–1 = 20–2*1–1 = 17 степенями свободы равны: tL =СТЬЮДЕНТ.ОБР(0,025;17) = –2,110; tU =СТЬЮДЕНТ.ОБР(0,975;17) = +2,110. Поскольку –2,110 2 равен 99,4% (ячейки J5), скорректированный коэффициент смешанной корреляции — 99,3% (ячейки J6), тестовая F-статистика — 1 333,51 (ячейки M12), а р-значение равно 0,0000. При уровне значимости α = 0,05, каждый регрессионный коэффициент в классической мультипликативной модели временного ряда является статистически значимым. Применяя к ним операцию потенцирования, получаем следующие параметры:

Коэффициенты  интерпретируются следующим образом.
интерпретируются следующим образом.
- Параметр
 = 18 416,376, сдвиг зависимой переменной Y, является значением некорректированного тренда квартальных доходов в первом квартале 1994 года, т.е. в первом временном периоде.
= 18 416,376, сдвиг зависимой переменной Y, является значением некорректированного тренда квартальных доходов в первом квартале 1994 года, т.е. в первом временном периоде. - Величина ( — 1) х 100% = 3,66% оценивает темп роста квартальных доходов.
- Величина = 0,807 представляет собой сезонный множитель для первого квартала по отношению к четвертому кварталу. Это число означает, что доходы, полученные в первом квартале, на 19,3% меньше, чем доходы, полученные в четвертом квартале.
- Величина = 0,869 представляет собой сезонный множитель для второго квартала по отношению к четвертому. Это число означает, что доходы, полученные во втором квартале, на 13,1% меньше, чем доходы, полученные в четвертом квартале.
- Величина = 0,848 представляет собой сезонный множитель для третьего квартала по отношению к четвертому. Это число означает, что доходы, полученные в третьем квартале, на 15,2% меньше, чем доходы, полученные в четвертом квартале.
 = 18 416,376, сдвиг зависимой переменной Y, является значением некорректированного тренда квартальных доходов в первом квартале 1994 года, т.е. в первом временном периоде.
= 18 416,376, сдвиг зависимой переменной Y, является значением некорректированного тренда квартальных доходов в первом квартале 1994 года, т.е. в первом временном периоде. — 1) х 100% = 3,66% оценивает темп роста квартальных доходов.
— 1) х 100% = 3,66% оценивает темп роста квартальных доходов. = 0,807 представляет собой сезонный множитель для первого квартала по отношению к четвертому кварталу. Это число означает, что доходы, полученные в первом квартале, на 19,3% меньше, чем доходы, полученные в четвертом квартале.
= 0,807 представляет собой сезонный множитель для первого квартала по отношению к четвертому кварталу. Это число означает, что доходы, полученные в первом квартале, на 19,3% меньше, чем доходы, полученные в четвертом квартале. = 0,869 представляет собой сезонный множитель для второго квартала по отношению к четвертому. Это число означает, что доходы, полученные во втором квартале, на 13,1% меньше, чем доходы, полученные в четвертом квартале.
= 0,869 представляет собой сезонный множитель для второго квартала по отношению к четвертому. Это число означает, что доходы, полученные во втором квартале, на 13,1% меньше, чем доходы, полученные в четвертом квартале. = 0,848 представляет собой сезонный множитель для третьего квартала по отношению к четвертому. Это число означает, что доходы, полученные в третьем квартале, на 15,2% меньше, чем доходы, полученные в четвертом квартале.
= 0,848 представляет собой сезонный множитель для третьего квартала по отношению к четвертому. Это число означает, что доходы, полученные в третьем квартале, на 15,2% меньше, чем доходы, полученные в четвертом квартале.Используя регрессионные коэффициенты bi, можно предсказать доход, полученный компанией в конкретном квартале. Например, предскажем доход компании для четвертого квартала 2002 года (Xi = 35):
log = b0 + b1Хi = 4,265 + 0,016*35 = 4,825
= 10 4,825 = 66 834
Таким образом, согласно прогнозу в четвертом квартале 2002 года компания должна была получить доход, равный 67 млрд. долл. (вряд ли следует делать прогноз с точностью до миллиона). Для того чтобы распространить прогноз на период времени, находящийся за пределами временного ряда, например, на первый квартал 2003 года (Xi = 36, Q1 = 1), необходимо выполнить следующие вычисления:
= 10 4,748 = 55 976
Индексы
Индексы используются в качестве индикаторов, реагирующих на изменения экономической ситуации или деловой активности. Существуют многочисленные разновидности индексов, в частности, индексы цен, количественные индексы, ценностные индексы и социологические индексы. В данном разделе мы рассмотрим лишь индекс цен. Индекс — величина некоторого экономического показателя (или группы показателей) в конкретный момент времени, выраженный в процентах от его значения в базовый момент времени.
Индекс цен. Простой индекс цен отражает процентное изменение цены товара (или группы товаров) в течение заданного периода времени по сравнению с ценой этого товара (или группы товаров) в конкретный момент времени в прошлом. При вычислении индекса цен прежде всего следует выбрать базовый промежуток времени — интервал времени в прошлом, с которым будут производиться сравнения. При выборе базового промежутка времени для конкретного индекса периоды экономической стабильности являются более предпочтительными по сравнению с периодами экономического подъема или спада. Кроме того, базовый промежуток не должен быть слишком удаленным во времени, чтобы на результаты сравнения не слишком сильно влияли изменения технологии и привычек потребителей. Индекс цен вычисляется по формуле:

Индекс цен — процентное изменение цены товара (или группы товаров) в заданный период времени по отношению к цене товара в базовый момент времени. В качестве примера рассмотрим индекс цен на неэтилированный бензин в США в промежутке времени с 1980 по 2002 г. (рис. 24). Например:


Рис. 24. Цена галлона неэтилированного бензина и простой индекс цен в США с 1980 по 2002 г. (базовые годы — 1980 и 1995)
Итак, в 2002 г. цена неэтилированного бензина в США была на 4,8% больше, чем в 1980 г. Анализ рис. 24 показывает, что индекс цен в 1981 и 1982 гг. был больше индекса цен в 1980 г., а затем вплоть до 2000 года не превышал базового уровня. Поскольку в качестве базового периода выбран 1980 г., вероятно, имеет смысл выбрать более близкий год, например, 1995 г. Формула для пересчета индекса по отношению к новому базовому промежутку времени:

где Iновый — новый индекс цен, Iстарый — старый индекс цен, Iновая база – значение индекса цен в новом базовом году при расчете для старого базового года.
Предположим, что в качестве новой базы выбран 1995 год. Используя формулу (10), получаем новый индекс цен для 2002 года:

Итак, в 2002 г. неэтилированный бензин в США стоил на 13,9% больше, чем в 1995 г.
Невзвешенные составные индексы цен. Несмотря на то что индекс цен на любой отдельный товар представляет несомненный интерес, более важным является индекс цен на группу товаров, позволяющий оценить стоимость и уровень жизни большого количества потребителей. Невзвешенный составной индекс цен, определенный формулой (11), приписывает каждому отдельному виду товаров одинаковый вес. Составной индекс цен отражает процентное изменение цены группы товаров (часто называемой потребительской корзиной) в заданный период времени по отношению к цене этой группы товаров в базовый момент времени.

где t — период времени (0, 1, 2, …), i — номер товара (1, 2, …, n), n — количество товаров в рассматриваемой группе,  — сумма цен на каждый из n товаров в период времени t,
— сумма цен на каждый из n товаров в период времени t,  — сумма цен на каждый из n товаров в нулевой период времени,
— сумма цен на каждый из n товаров в нулевой период времени,  — величина невзвешенного составного индекса в период времени t.
— величина невзвешенного составного индекса в период времени t.
На рис. 25 представлены средние цены на три вида фруктов за период с 1980 по 1999 гг. Для вычисления невзвешенного составного индекса цен в разные годы применяется формула (11), считая базовым 1980 год.
Итак, в 1999 г. суммарная цена фунта яблок, фунта бананов и фунта апельсинов на 59,4% превышала суммарную цену на эти фрукты в 1980 г.

Рис. 25. Цены (в долл.) на три вида фруктов и невзвешенный составной индекс цен
Невзвешенный составной индекс цен выражает изменения цен на всю группу товаров с течением времени. Несмотря на то что этот индекс легко вычислять, у него есть два явных недостатка. Во-первых, при вычислении этого индекса все виды товаров считаются одинаково важными, поэтому дорогие товары приобретают излишнее влияние на индекс. Во-вторых, не все товары потребляются одинаково интенсивно, поэтому изменения цен на мало потребляемые товары слишком сильно влияют на невзвешенный индекс.
Взвешенные составные индексы цен. Из-за недостатков невзвешенных индексов цен более предпочтительными являются взвешенные индексы цен, учитывающие различия цен и уровней потребления товаров, образующих потребительскую корзину. Существуют два типа взвешенных составных индексов цен. Индекс цен Лапейрэ, определенный формулой (12), использует уровни потребления в базовом году. Взвешенный составной индекс цен позволяет учесть уровни потребления товаров, образующих потребительскую корзину, присваивая каждому товару определенный вес.

где t — период времени (0, 1, 2, …), i — номер товара (1, 2, …, n), n — количество товаров в рассматриваемой группе,  — количество единиц товара i в нулевой период времени,
— количество единиц товара i в нулевой период времени,  — значение индекса Лапейрэ в период времени t.
— значение индекса Лапейрэ в период времени t.
Вычисления индекса Лапейрэ показаны на рис. 26; в качестве базового используется 1980 год.

Рис. 26. Цены (в долл.), количество (потребление в фунтах на душу населения) трех видов фруктов и индекс Лапейрэ
Итак, индекс Лапейрэ в 1999 г. равен 154,2. Это свидетельствует от том, что в 1999 году эти три вида фруктов были на 54,2% дороже, чем в 1980 году. Обратите внимание на то, что этот индекс меньше невзвешенного индекса, равного 159,4, поскольку цены на апельсины — фрукты, потребляемые меньше остальных, — выросли больше, чем цена яблок и бананов. Иначе говоря, поскольку цены на фрукты, потребляемые наиболее интенсивно, выросли меньше, чем цены на апельсины, индекс Лапейрэ меньше невзвешенного составного индекса.
Индекс цен Пааше использует уровни потребления товара в текущем, а не базовом периоде времени. Следовательно, индекс Пааше более точно отражает полную стоимость потребления товаров в заданный момент времени. Однако этот индекс имеет два существенных недостатка. Во-первых, как правило, текущие уровни потребления трудно определить. По этой причине многие популярные индексы используют индекс Лапейрэ, а не индекс Пааше. Во-вторых, если цена некоторого конкретного товара, входящего в потребительскую корзину, резко возрастает, покупатели снижают уровень его потребления по необходимости, а не вследствие изменения вкусов. Индекс Пааше вычисляется по формуле:

где t — период времени (0, 1, 2, …), i — номер товара (1, 2, …, n), n — количество товаров в рассматриваемой группе,  — количество единиц товара i в нулевой период времени,
— количество единиц товара i в нулевой период времени,  — значение индекса Пааше в период времени t.
— значение индекса Пааше в период времени t.
Вычисления индекса Пааше показаны на рис. 27; в качестве базового используется 1980 год.

Рис. 27. Цены (в долл.), количество (потребление в фунтах на душу населения) трех видов фруктов и индекс Пааше
Итак, индекс Пааше в 1999 г. равен 147,0. Это свидетельствует от том, что в 1999 году эти три вида фруктов были на 47,0% дороже, чем в 1980 году.
Некоторые популярные индексы цен. В бизнесе и экономике используется несколько индексов цен. Наиболее популярным является индекс потребительских цен (Consumer Index Price — CPI). Официально этот индекс называется CPI-U, чтобы подчеркнуть, что он вычисляется для городов (urban), хотя, как правило, его называют просто CPI. Этот индекс ежемесячно публикуется Бюро статистики труда (U. S. Bureau of Labor Statistics) в качестве основного инструмента для измерения стоимости жизни в США. Индекс потребительских цен является составным и взвешенным по методу Лапейрэ. При его вычислении используются цены 400 наиболее широко потребляемых продуктов, видов одежды, транспортных, медицинских и коммунальных услуг. В данный момент при вычислении этого индекса в качестве базового используется период 1982–1984 гг. (рис. 28). Важной функцией индекса CPI является его использование в качестве дефлятора. Индекс CPI используется для пересчета фактических цен в реальные путем умножения каждой цены на коэффициент 100/CPI. Расчеты показывают, что за последние 30 лет среднегодовые темпы инфляции в США составили 2,9%.

Рис. 28. Динамика Consumer Index Price; полные данные см. Excel-файл
Другим важным индексом цен, публикуемым Бюро статистики труда, является индекс цен производителей (Producer Price Index — PPI). Индекс PPI является взвешенным составным индексом, использующим метод Лапейрэ для оценки изменения цен товаров, продаваемых их производителями. Индекс PPI является лидирующим индикатором для индекса CPI. Иначе говоря, увеличение индекса PPI приводит к увеличению индекса CPI, и наоборот, уменьшение индекса PPI приводит к уменьшению индекса CPI. Финансовые индексы, такие как индекс Доу-Джонса для акций промышленных предприятий (Dow Jones Industrial Average — DJIA), S&P 500 и NASDAQ, используются для оценки изменения стоимости акций в США. Многие индексы позволяют оценить прибыльность международных фондовых рынков. К таким индексам относятся индекс Nikkei в Японии, Dax 30 в Германии и SSE Composite в Китае.
Ловушки, связанные с анализом временных рядов
Значение методологии, использующей информацию о прошлом и настоящем для того, чтобы прогнозировать будущее, более двухсот лет назад красноречиво описал государственный деятель Патрик Генри: «У меня есть лишь одна лампа, освещающая путь, — мой опыт. Только знание прошлого позволяет судить о будущем».
Анализ временных рядов основан на предположении, что факторы, влиявшие на деловую активность в прошлом и влияющие в настоящем, будут действовать и в будущем. Если это правда, анализ временных рядов представляет собой эффективное средство прогнозирования и управления. Однако критики классических методов, основанных на анализе временных рядов, утверждают, что эти методы слишком наивны и примитивны. Иначе говоря, математическая модель, учитывающая факторы, действовавшие в прошлом, не должна механически экстраполировать тренды в будущее без учета экспертных оценок, опыта деловой активности, изменения технологии, а также привычек и потребностей людей. Пытаясь исправить это положение, в последние годы специалисты по эконометрии разрабатывали сложные компьютерные модели экономической активности, учитывающие перечисленные выше факторы.
Тем не менее, методы анализа временных рядов представляют собой превосходный инструмент прогнозирования (как краткосрочного, так и долгосрочного), если они применяются правильно, в сочетании с другими методами прогнозирования, а также с учетом экспертных оценок и опыта.
Резюме. В заметке с помощью анализа временных рядов разработаны модели для прогнозирования доходов трех компаний: Wm. Wrigley Jr. Company, Cabot Corporation и Wal-Mart. Описаны компоненты временного ряда, а также несколько подходов к прогнозированию годовых временных рядов — метод скользящих средних, метод экспоненциального сглаживания, линейная, квадратичная и экспоненциальная модели, а также авторегрессионная модель. Рассмотрена регрессионная модель, содержащая фиктивные переменные, соответствующие сезонному компоненту. Показано применение метода наименьших квадратов для прогнозирования месячных и квартальных временных рядов (рис. 29).
Рис. 29. Структурная схема заметки
[1] Используются материалы книги Левин и др. Статистика для менеджеров. – М.: Вильямс, 2004. – с. 983–1074
[2] Тестовая t-статистика теряет р степеней свободы при оценке наклона и одну при оценке сдвига генеральной совокупности откликов. Еще р степеней свободы утрачиваются при сравнении значений временного ряда.
Временные ряды

Понятие временного ряда
Временной ряд (time series) — это данные, последовательно собранные в регулярные промежутки времени.
К таким данным относятся, например, цены на акции, объемы продаж чего-либо, изменения температуры с течением времени и т.д. Посмотрим на изменение обычных данных и временных рядов.

Основное отличие: перекрестные данные предполагают независимость наблюдений, во временных рядах будущее зависит от прошлого.
Работа с временными рядами предполагает два аспекта:
- Анализ временного ряда (time series analysis), т.е. понимание его структуры и закономерностей; и
- Моделирование и построение прогноза на будущее (time series forecasting)
Договоримся о терминах:
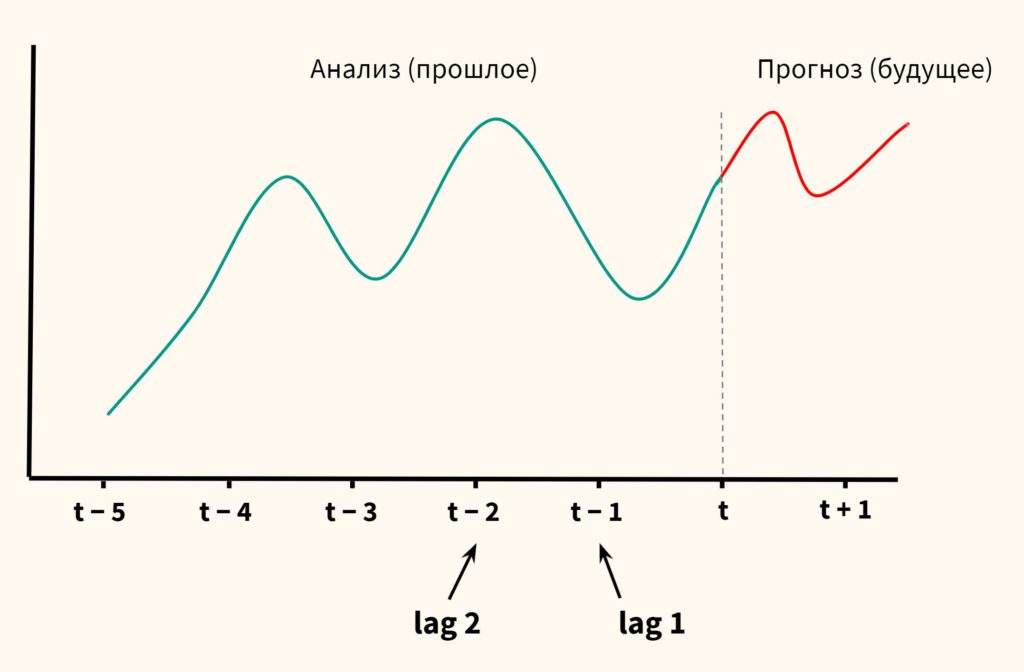
- Во-первых, определим нотацию периодов. Временем t обозначим настоящее, t−1, t−2,… прошлое, t+1, t+2,… будущее.
- Во-вторых, введем важное понятие временного лага (lag), т.е. запаздывания по сравнению с заданным периодом.
Датасеты
Мы будем использовать два популярных набора данных, а именно (1) ежемесячные данные о количестве пассажиров, перевезенных одной американской авиакомпанией с 1949 по 1960 годы и (2) ежедневные данные о родившихся в Калифорнии в 1959 году девочках.
Подгружать внешние данные в ноутбук Google Colab мы уже умеем. Можем переходить непосредственно к работе с кодом.
Анализ временных рядов
Импорт данных и работа в библиотеке Pandas
Для начала давайте импортируем данные. Пока что мы будем использовать только первый набор данных с информацией об авиаперевозках.

Сделаем дату индексом.

Питон воспринимает дату как число. Это не очень удобно, если мы хотим делать срезы и в целом изменять данные во времени. Дату можно преобразовать в специальный объект datetime.
Все эти операции также можно проделать в одну строчку.
Теперь мы можем делать срезы за определенный период, например, с августа 1949 по март 1950 года.

Обратите внимание, что в отличие от других перечней в Питоне (например, списков), во временном ряде мы получаем данные и по начальной, и по конечной дате среза (в частности, март 1950 года вошел в наш интервал).
Изменение шага временного ряда, сдвиг и скользящее среднее
Отдельно хотелось бы поговорить про возможность обобщения и изменения данных. Помимо прочего, мы можем изменить шаг (resample) нашего временного ряда, и посмотреть средние показатели перевозок, например, за год.

Кроме того, мы можем сдвинуть (shift) наши данные на n периодов вперед или назад.

Что логично, после сдвига первые два значения определяются как пропущенные (NaN или Not a number).
Мы также можем рассчитать скользящее среднее (moving average, rolling average) за n предыдущих периодов. Вначале посмотрим, что это такое.

Теперь давайте рассчитаем его для наших данных. Период, за который рассчитывается скользящее среднее, также называется окном (window).

Опять же, так как в данном случае мы использовали три месяца для расчета скользящего среднего, этот показатель недоступен для первых двух значений. В целом, скользящее среднее сглаживает временные показатели (мы это увидим на графике в следующем разделе).
Построение графиков
Для того чтобы построить график временного ряда мы можем воспользоваться инструментами, которые уже содержатся в библиотеке Pandas. Например, простым методом .plot().

График можно усложнить.
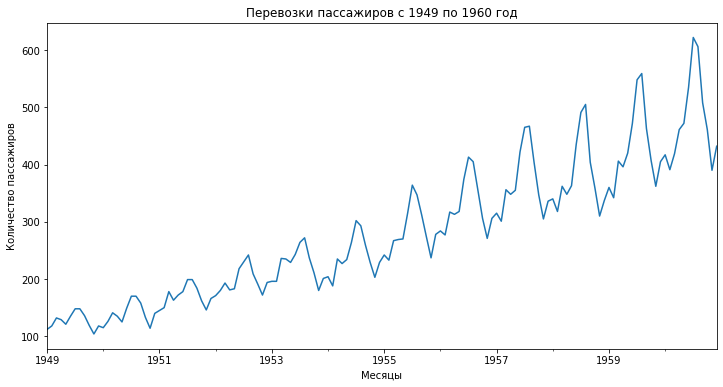
Визуализацию можно также построить с помощью библиотеки Matplotlib. Давайте выведем на одном графике перевозки пассажиров и скользящее среднее.

Как вы видите, скользящее среднее сильно сглаживает показатели. Также обратите внимание, что так как в данном случае мы взяли окно равное двенадцати месяцам, то первое значение скользящего среднего мы получили только за декабрь 1949 года (самое начало желтой кривой на графике).
В целом не стоит недооценивать важность визуальной оценки ряда на графике. Многие особенности можно выявить именно так.
Разложение временного ряда на компоненты
Выявление компонентов временного ряда (time series decomposition) предполагает его разложение на тренд, сезонность и случайные колебания. Дадим несколько неформальных определений.
- Тренд — долгосрочное изменение уровня ряда
- Сезонность предполагает циклические изменения уровня ряда с постоянным периодом
- Случайные колебания — непрогнозируемое случайное изменение ряда
В Питоне в модуле statsmodels есть функция seasonal_decompose(). Воспользуемся ей для визуализации компонентов ряда.
Перед этим импортируем второй датасет для последующего сравнения.

Теперь давайте разложим наш временной ряд по авиаперевозкам на компоненты.

Сделаем то же самое с данными о рождаемости.

Как мы видим, графики совершенно разные. В следующем разделе мы изучим это различие более подробно.
Стационарность
Стационарность (stationarity) временного ряда как раз означает, что такие компоненты как тренд и сезонность отсутствуют. Говоря более точно, среднее значение и дисперсия не меняются со смещением во времени.
Понимание того, стационарные ли у нас данные или нестационарные важно для последующего моделирования.
Стационарность процесса можно оценить визуально. Датасет о перевозках демонстрирует очевидный тренд и сезонность, в то время как в наборе данных о рождаемости этого не видно (см. графики выше).
Для более точной оценки стационарности можно применить тест Дики-Фуллера (Dickey-Fuller test). О том, что такое статистический вывод мы с вами уже говорили.
В данном случае гипотезы звучат следующим образом.
- Нулевая гипотеза предполагает, что процесс нестационарный
- Альтернативная гипотеза соответственно говорит об обратном
Применим этот тест к обоим датасетам. Используем пороговое значение, равное 0,05 (5%).
Как мы видим, вероятность (p-value) для данных о перевозках существенно выше 0,05. Мы не можем отвергнуть нулевую гипотезу. Процесс нестанионарный. Проведем тест для второго набора данных.
Результат существенно меньше 5%. Временной ряд стационарен.
Надо сказать, что наша визуальная оценка полностью совпала с математическими вычислениями.
Автокорреляция
Изучая статистику, мы с вами уже познакомились с корреляцией. Корреляция показывает силу взаимосвязи двух переменных и позволяет строить модель.
Автокорреляция также показывает степень взаимосвязи в диапазоне от –1 до 1, но только не двух переменных, а одной и той же переменной в разные моменты времени.
Допустим, у нас есть временной ряд и этот же ряд, взятый с лагом 1, 2 и 3.

Мы можем посчитать автокорреляцию ряда с лагом 1.
Визуально это будет выглядеть следующим образом (вспомните график обычной корреляции).
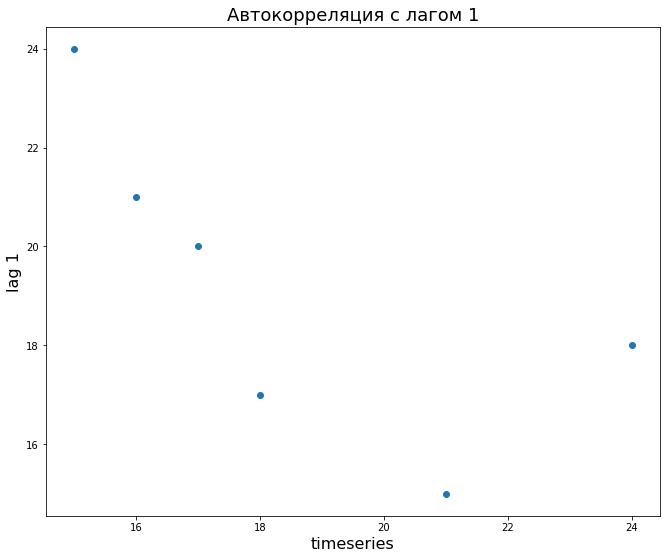
Аналогично мы можем посчитать корреляцию для лагов 2 и 3 и на самом деле любого другого лага. Такие измерения автокорреляции удобно вычислить и изобразить с помощью графика автокорреляционной функции (autocorrelation function, ACF).

В частности, мы видим, что автокорреляция ряда с самим собой (первый столбец) равна 1, что логично. Второй столбец (то есть лаг 1) как раз примерно равен – 0,71.
Разные значения, полученные через np.corrcoef() и plot_acf(), объясняются небольшим различием в заложенных в этих функциях формулах.
Теперь построим график ACF для наших данных о перевозках.

Автокорреляция позволяет выявлять тренд и сезонность, а также используется при подборе параметров моделей. В частности, мы видим, что лаг 12 сильнее коррелирует с исходным рядом, чем соседние лаги 10 и 11. То же самое можно сказать и про лаг 24. Такая автокорреляция позволяет предположить наличие (ежегодных) сезонных колебаний.
То, что корреляция постоянно положительная говорит о наличии тренда. Все это согласуется с тем, что мы узнали о данных, когда раскладывали их на компоненты.
Также замечу, что синяя граница позволяет оценить статистическую значимость корреляции. Если столбец выходит за ее пределы, то автокорреляция достаточно сильна и ее можно использовать при построении модели.
Сравним полученный выше график с графиком автокорреляционной функции данных о рождаемости.

Во-первых, важно отметить, что автокорреляция в данном случае намного слабее. Во-вторых, мы не можем выявить четкой сезонности и тренда.
Моделирование и построение прогноза
На сегодняшнем занятии мы познакомимся с двумя типами моделей: экспоненциальное сглаживание и модель ARMA (и ее более продвинутые версии, ARIMA, SARIMA и SARIMAX).
Экспоненциальное сглаживание
Вновь обратимся к скользящему среднему (см. выше). В этой модели (1) всем предыдущим наблюдениям задавался одинаковый вес и (2) количество таких наблюдений было ограничено (мы называли это размером окна).
Однако логично предположить, что недавние наблюдения более важны для прогноза, чем более отдаленные. Кроме того, мы можем взять все, а не некоторые из имеющихся у нас наблюдений.
В модели экспоненциального сглаживания (exponential smoothing) или экспоненциального скользящего среднего мы как раз (1) берем все предыдущие значения и (2) задаем каждому из наблюдений определенный вес и (экспоненциально) уменьшаем этот вес по мере углубления в прошлое.
$$ \hat
где ŷt — это прогнозное значение, yt — текущее истинное значение, ŷt–1 — предыдущее прогнозное значение.
Как мы видим, прогнозное значение зависит от текущего истинного и предыдущего прогнозного значения. Важность этих значений определяется параметром альфа, который варьируется от 0 до 1. Чем альфа больше, тем больший вес у текущего наблюдения.
Формула рекурсивна, т.е. каждый раз мы умножаем (1 – α) на предыдущее прогнозное значение и так до конца временного ряда.
Практика
На Питоне эту модель не сложно прописать руками.
Для временного ряда, состоящего из 365 наблюдений (весь 1959 год), мы получим 366 значений (включая прогноз на 1 января 1960 года).
Для того чтобы представить кривую экспоненциального сглаживания на графике, добавим эти данные в исходный датафрейм births. Полностью код работы с датафреймом я приведу в ноутбуке⧉. Здесь представлю только получившийся результат.

Теперь выведем результат на графике.

Очень советую в качестве упражнения попробовать построить график с несколькими значениями альфа от 0 до 1.
Модель экспоненциального сглаживания можно усложнить и тогда она будет улавливать тренд и сезонность. Кроме того, усложненные модели способны предсказывать более одного значения (обратите внимание, здесь мы смогли сделать прогноз лишь на один день вперёд).
Теперь поговорим про модели семейства ARMA.
Модель ARMA
Модель ARMA состоит из двух компонентов.

Авторегрессия (autoregressive model, AR) — это регрессия ряда на собственные значения в прошлом. Другими словами, наши признаки в модели обычной регрессии мы заменяем значениями той же переменной, но за предыдущие периоды.
Когда мы прогнозируем значение в период t с помощью данных за предыдущий период (AR(1)), уравнение будет выглядеть следующим образом.
$$ y_t = c + \varphi \cdot y_
где c — это константа, φ — вес модели, yt–1 — значение в период t – 1.
То, сколько предыдущих периодов использовать определяется параметром p. Обычно записывается как AR(p).
Модель скользящего среднего (moving average, MA) помогает учесть случайные колебания или отклонения (ошибки) истинного значения от прогнозного. Можно также сказать, что модель скользящего среднего — это авторегрессия на ошибку.
Обратите внимание, что скользящее среднее временного ряда, которое мы рассмотрели выше, и модель скользящего среднего — это разные понятия.
Если использовать ошибку только предыдущего наблюдения, то уравнение будет выглядеть следующим образом.
$$ y_t = \mu + \varphi \cdot \varepsilon_
где μ — это среднее значение временного ряда, φ — вес модели, εt–1 — ошибка в период t – 1.
Такую модель принято называть моделью скользящего среднего с параметром q = 1 или MA(1). Разумеется, параметр q может принимать и другие значения (MA(q)).
Модель ARMA с параметрами (или как еще говорят порядками, orders) p и q или ARMA(p, q) позволяет описать любой стационарный временной ряд.
ARMA предполагает, что в данных отсутствует тренд и сезонность (данные стационарны). Если данные нестационарны, нужно использовать более сложные версии этих моделей:
- ARIMA, здесь добавляется компонент Integrated (I), который отвечает за удаление тренда (сам процесс называется дифференцированием); и
- SARIMA, эта модель учитывает сезонность (Seasonality, S)
- SARIMAX включает еще и внешние или экзогенные факторы (eXogenous factors, отсюда и буква X в названии), которые напрямую не учитываются моделью, но влияют на нее.
Параметров у модели SARIMAX больше. Их полная версия выглядит как SARIMAX(p, d, q) x (P, D, Q, s). В данном случае, помимо известных параметров p и q, у нас появляется параметр d, отвечающий за тренд, а также набор параметров (P, D, Q, s), отвечающих за сезонность.
Теперь давайте воспользуемся моделью SARIMAX для прогнозирования авиаперевозок.
Практика
В первую очередь нужно разбить данные на обучающую и тестовую выборки. Как мы помним, у нас есть данные с января 1949 года по декабрь 1960 года.
http://baguzin.ru/wp/analiz-vremennyh-ryadov/
http://www.dmitrymakarov.ru/intro/time-series-20/