Методика множественного корреляционного анализа
Необходимость применения многофакторного корреляционного анализа. Этапы многофакторного корреляционного анализа. Правила отбора факторов для корреляционной модели. Обоснование необходимого объема выборки данных для корреляционного анализа. Сбор и статистическая оценка исходной информации. Способы обоснования уравнения связи. Основные показатели связи в корреляционном анализе и их интерпретация. Сущность парных (общих), частных и множественных коэффициентов корреляции и детерминации. Оценка значимости коэффициентов корреляции. Порядок расчета уравнения множественной регрессии шаговым способом. Интерпретация его параметров. Назначение коэффициентов эластичности и стандартизированных бетта-коэф-фициентов.
Экономические явления и процессы хозяйственной деятельности предприятий зависят от большого количества факторов. Как правило, каждый фактор в отдельности не определяет изучаемое явление во всей полноте. Только комплекс факторов в их взаимосвязи может дать более или менее полное представление о характере изучаемого явления.
Многофакторный корреляционный анализ состоит из нескольких этапов.
На первом, этапе определяются факторы, которые оказывают воздействие на изучаемый показатель, и отбираются наиболее существенные для корреляционного анализа.
На втором этапе собирается и оценивается исходная информация, необходимая для корреляционного анализа.
На третьем этапе изучается характер и моделируется связь между факторами и результативным показателем, то есть подбирается и обосновывается математическое уравнение, которое наиболее точно выражает сущность исследуемой зависимости.
На четвертом этапе проводится расчет основных показателей связи корреляционного анализа.
На пятом этапе дается статистическая оценка результатов корреляционного анализа и практическое их применение.
Отбор факторов для корреляционного анализа является очень важным моментом в экономическом анализе. От того, насколько правильно он сделан, зависит точность выводов по итогам анализа. Главная роль при отборе факторов принадлежит теории, а также практическому опыту анализа. При этом необходимо придерживаться следующих правил.
1. При отборе факторов в первую очередь следует учитывать причинно-следственные связи между показателями, так как только они раскрывают сущность изучаемых явлений. Анализ же таких факторов, которые находятся только в математических соотношениях с результативным показателем, не имеет практического смысла.
2. При создании многофакторной корреляционной модели необходимо отбирать самые значимые факторы, которые оказывают решающее воздействие на результативный показатель, так как охватить все условия и обстоятельства практически невозможно. Факторы, которые имеют критерий надежности по Стьюденту меньше табличного, не рекомендуется принимать в расчет.
3. Все факторы должны быть количественно измеримы, т.е. иметь единицу измерения, и информация о них должна содержаться в учете и отчетности.
4. В корреляционную модель линейного типа не рекомендуется включать факторы, связь которых с результативным показателем имеет криволинейный характер.
5. Не рекомендуется включать в корреляционную модель взаимосвязанные факторы. Если парный коэффициент корреляции между двумя факторами больше 0,85, то по правилам корреляционного анализа один из них необходимо исключить, иначе это приведет к искажению результатов анализа.
6. Нежелательно включать в корреляционную модель факторы, связь которых с результативным показателем носит функциональный характер.
Большую помощь при отборе факторов для корреляционной. модели оказывают аналитические группировки, способ сопоставления параллельных и динамических рядов, линейные графики. Благодаря им можно определить наличие, направление и форму зависимости между изучаемыми показателями. Отбор факторов можно производить также в процессе решения задачи корреляционного анализа на основе оценки их значимости по критерию Стьюдента, о котором будет сказано ниже.
Исходя из перечисленных выше требований и используя названные способы отбора факторов,для многофакторной корреляционной модели уровня рентабельности (Y) подобраны. следующие факторы, которые оказывают наиболее существенное влияние на ее уровень:
x3 — производительность труда (среднегодовая выработка продукции на одного работника), млн руб.;
x4 — продолжительность оборота оборотных средств предприятия, дни;
x5 — удельный вес продукции высшей категории качества, %.
Поскольку корреляционная связь с достаточной выразительностью и полнотой проявляется только в массе наблюдений, объем выборки данных должен быть достаточно большим, так как только в массе наблюдений сглаживается влияние других факторов. Чем большая совокупность объектов исследуется, тем точнее результаты анализа.
Учитывая это требование, влияние перечисленных факторов на уровень рентабельности исследуется на примере 40 предприятий.
Следующим этапом анализа являетсясбор и статистическая оценка исходной информации, которая будет использоваться в корреляционном анализе. Собранная исходная информация должна быть проверена на достоверность, однородность и соответствие закону нормального распределения.
В первую очередь необходимо убедиться вдостоверности информации, насколько она соответствует объективной действительности. Использование недостоверной, неточной информации приведет к неправильным результатам анализа и выводам.
Одно из условий корреляционного анализа —однородность исследуемой информации относительно распределения ее около среднего уровня. Если в совокупности имеются группы объектов, которые значительно отличаются от среднего уровня, то это говорит о неоднородности исходной информации.
Критерием однородности информации служит среднеквадратическое отклонение и коэффициент вариации, которые рассчитываются по каждому факторному и результативному показателю.
Среднеквадратическое отклонение показывает абсолютное отклонение индивидуальных значений от среднеарифметического. Оно определяется по формуле:
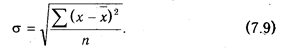
Коэффициент вариации характеризует относительную меру отклонения отдельных значений от среднеарифметической. Он рассчитывается по формуле:

Чем больше коэффициент вариации, тем относительно больший разброс и меньшая выравненность изучаемых объектов. Изменчивость вариационного ряда принято считать незначительной, если вариация не превышает 10 %, средней — если составляет 10-20 %, значительной — если она больше 20 %, но не превышает 33 %. Если же вариация выше 33 %, то это говорит о неоднородности информации и необходимости исключения нетипичных наблюдений, которые обычно бывают в первых и последних ранжированных рядах выборки.
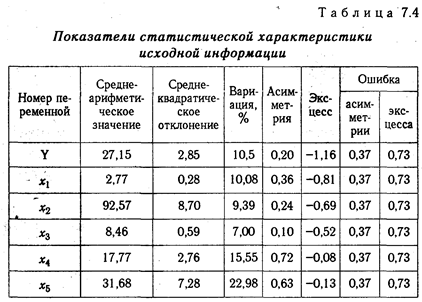
В нашем примере (табл. 7.4) самая высокая вариация по х5 (V = 22,98), но она не превышает 33 %. Значит, исходная информация является однородной и ее можно использовать для дальнейших расчетов.
На основании самого высокого показателя вариации можно определитьнеобходимый объем выборки данных для корреляционного анализа по следующей формуле:
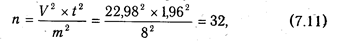
где п — необходимый объем выборки данных; V — вариация, %; t — показатель надежности связи, который при уровне вероятности Р = 0,05 равен 1,96; т — показатель точности расчетов (для экономических расчетов допускается ошибка 5-8 %).
Значит, принятый в расчет объем выборки (40 предприятий) является достаточным для проведения корреляционного анализа.
Следующее требование к исходной информации —соответствие ее закону нормального распределения. Согласно этому закону, основная масса исследуемых сведений по каждому показателю должна быть сгруппирована около ее среднего значения, а объекты с очень маленькими значениями или с очень большими должны встречаться как можно реже. График нормального распределения информации имеет следующий вид (рис. 7.1).
Для количественной оценки степени отклонения информации от нормального распределения служит отношение показателя асимметрии к ее ошибке и отношение показателя эксцесса к его ошибке.
Показатель асимметрии (A) и его ошибка (та) рассчитываются по следующим формулам:
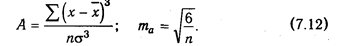
Показатель эксцесса (Е) и его ошибка (те) рассчитываются следующим образом:
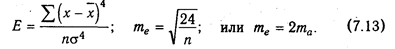
В симметричном распределении А = 0. Отличие от нуля указывает на наличие асимметрии в распределении данных около средней величины. Отрицательная асимметрия свидетельствует о том, что преобладают данные с большими значениями, а с меньшими значениями встречаются значительно реже. Положительная асимметрия показывает, что чаще встречаются данные с небольшими значениями.
В нормальном распределении показатель эксцесса Е = 0. Если Е > 0, то данные густо сгруппированы около средней, образуя островершинность. Если Е
Дата добавления: 2017-02-20 ; просмотров: 1894 ; ЗАКАЗАТЬ НАПИСАНИЕ РАБОТЫ
Парная регрессия и корреляция

1. Парная регрессия и корреляция
1.1. Понятие регрессии
Парной регрессией называется уравнение связи двух переменных у и х
где у – зависимая переменная (результативный признак); х – независимая, объясняющая переменная (признак-фактор).
Различают линейные и нелинейные регрессии.
Линейная регрессия описывается уравнением: y = a + b × x +e .
Нелинейные регрессии делятся на два класса: регрессии, нелинейные относительно включенных в анализ объясняющих переменных, но линейные по оцениваемым параметрам, и регрессии, нелинейные по оцениваемым параметрам.
Примеры регрессий, нелинейных по объясняющим переменным, но ли-
нейных по оцениваемым параметрам:
· полиномы разных степеней 
· равносторонняя гипербола: 
Примеры регрессий, нелинейных по оцениваемым параметрам:
· степенная 
· показательная 
· экспоненциальная 
Наиболее часто применяются следующие модели регрессий:
– прямой 
– гиперболы 
– параболы 
– показательной функции 
– степенная функция 
1.2. Построение уравнения регрессии
Постановка задачи. По имеющимся данным n наблюдений за совместным
изменением двух параметров x и y <(xi,yi), i=1,2. n> необходимо определить
аналитическую зависимость ŷ=f(x), наилучшим образом описывающую данные наблюдений.
Построение уравнения регрессии осуществляется в два этапа (предполагает решение двух задач):
– спецификация модели (определение вида аналитической зависимости
– оценка параметров выбранной модели.
1.2.1. Спецификация модели
Парная регрессия применяется, если имеется доминирующий фактор, который и используется в качестве объясняющей переменной.
Применяется три основных метода выбора вида аналитической зависимости:
– графический (на основе анализа поля корреляций);
– аналитический, т. е. исходя из теории изучаемой взаимосвязи;
– экспериментальный, т. е. путем сравнения величины остаточной дисперсии Dост или средней ошибки аппроксимации , рассчитанных для различных
моделей регрессии (метод перебора).
1.2.2. Оценка параметров модели
Для оценки параметров регрессий, линейных по этим параметрам, используется метод наименьших квадратов (МНК). МНК позволяет получить такие оценки параметров, при которых сумма квадратов отклонений фактических значений результативного признака у от теоретических значений ŷx при тех же значениях фактора x минимальна, т. е.

В случае линейной регрессии параметры а и b находятся из следующей
системы нормальных уравнений метода МНК:
 (1.1)
(1.1)
Можно воспользоваться готовыми формулами, которые вытекают из этой
 (1.2)
(1.2)
Для нелинейных уравнений регрессии, приводимых к линейным с помощью преобразования (x, y) → (x’, y’), система нормальных уравнений имеет
вид (1.1) в преобразованных переменных x’, y’.
Коэффициент b при факторной переменной x имеет следующую интерпретацию: он показывает, на сколько изменится в среднем величина y при изменении фактора x на 1 единицу измерения.
Линеаризующее преобразование: x’ = 1/x; y’ = y.
Уравнения (1.1) и формулы (1.2) принимают вид


Линеаризующее преобразование: x’ = x; y’ = lny.

Модифицированная экспонента:  , (0 K и со знаком «–» в противном случае.
, (0 K и со знаком «–» в противном случае.
Степенная функция: 
Линеаризующее преобразование: x’ = ln x; y’ = ln y.

Показательная функция: 
Линеаризующее преобразование: x’ = x; y’ = lny.
 Логарифмическая функция:
Логарифмическая функция:
Линеаризующее преобразование: x’ = ln x; y’ = y.

Парабола второго порядка: 
Парабола второго порядка имеет 3 параметра a0, a1, a2, которые определяются из системы трех уравнений

1.3. Оценка тесноты связи
Тесноту связи изучаемых явлений оценивает линейный коэффициент
парной корреляции rxy для линейной регрессии (–1 ≤ r xy ≤ 1)
и индекс корреляции ρxy для нелинейной регрессии 
 Имеет место соотношение
Имеет место соотношение

Долю дисперсии, объясняемую регрессией, в общей дисперсии результативного признака у характеризует коэффициент детерминации r2xy (для линейной регрессии) или индекс детерминации (для нелинейной регрессии).
Коэффициент детерминации – квадрат коэффициента или индекса корреляции.
Для оценки качества построенной модели регрессии можно использовать
показатель (коэффициент, индекс) детерминации R2 либо среднюю ошибку аппроксимации.
Чем выше показатель детерминации или чем ниже средняя ошибка аппроксимации, тем лучше модель описывает исходные данные.
Средняя ошибка аппроксимации – среднее относительное отклонение
расчетных значений от фактических

Построенное уравнение регрессии считается удовлетворительным, если
значение не превышает 10–12 %.
1.4. Оценка значимости уравнения регрессии, его коэффициентов,
Оценка значимости всего уравнения регрессии в целом осуществляется с
помощью F-критерия Фишера.
F-критерий Фишера заключается в проверке гипотезы Но о статистической незначимости уравнения регрессии. Для этого выполняется сравнение
фактического Fфакт и критического (табличного) Fтабл значений F-критерия
Fфакт определяется из соотношения значений факторной и остаточной
дисперсий, рассчитанных на одну степень свободы

где n – число единиц совокупности; m – число параметров при переменных.
Для линейной регрессии m = 1 .
Для нелинейной регрессии вместо r 2 xy используется R2.
Fтабл – максимально возможное значение критерия под влиянием случайных факторов при степенях свободы k1 = m, k2 = n – m – 1 (для линейной регрессии m = 1) и уровне значимости α.
Уровень значимости α – вероятность отвергнуть правильную гипотезу
при условии, что она верна. Обычно величина α принимается равной 0,05 или
Если Fтабл Fфакт, то гипотеза Но не отклоняется и признается статистическая незначимость, ненадежность уравнения регрессии.
Для оценки статистической значимости коэффициентов линейной регрессии и линейного коэффициента парной корреляции применяется
t-критерий Стьюдента и рассчитываются доверительные интервалы каждого
Согласно t-критерию выдвигается гипотеза Н0 о случайной природе показателей, т. е. о незначимом их отличии от нуля. Далее рассчитываются фактические значения критерия tфакт для оцениваемых коэффициентов регрессии и коэффициента корреляции путем сопоставления их значений с величиной стандартной ошибки

Стандартные ошибки параметров линейной регрессии и коэффициента
корреляции определяются по формулам
 Сравнивая фактическое и критическое (табличное) значения t-статистики
Сравнивая фактическое и критическое (табличное) значения t-статистики
tтабл и tфакт принимают или отвергают гипотезу Но.
tтабл – максимально возможное значение критерия под влиянием случайных факторов при данной степени свободы k = n–2 и уровне значимости α.
Связь между F-критерием Фишера (при k1 = 1; m =1) и t-критерием Стьюдента выражается равенством
Если tтабл tфакт, то гипотеза Но не отклоняется и признается случайная природа формирования а, b или  .
.
Значимость коэффициента детерминации R2 (индекса корреляции) определяется с помощью F-критерия Фишера. Фактическое значение критерия Fфакт определяется по формуле

Fтабл определяется из таблицы при степенях свободы k1 = 1, k2 = n–2 и при
заданном уровне значимости α. Если Fтабл
Python, корреляция и регрессия: часть 2
Предыдущий пост см. здесь.
Регрессия
Хотя, возможно, и полезно знать, что две переменные коррелируют, мы не можем использовать лишь одну эту информацию для предсказания веса олимпийских пловцов при наличии данных об их росте или наоборот. При установлении корреляции мы измерили силу и знак связи, но не наклон, т.е. угловой коэффициент. Для генерирования предсказания необходимо знать ожидаемый темп изменения одной переменной при заданном единичном изменении в другой.
Мы хотели бы вывести уравнение, связывающее конкретную величину одной переменной, так называемой независимой переменной, с ожидаемым значением другой, зависимой переменной. Например, если наше линейное уравнение предсказывает вес при заданном росте, то рост является нашей независимой переменной, а вес — зависимой.
Описываемые этими уравнениями линии называются линиями регрессии . Этот Термин был введен британским эрудитом 19-ого века сэром Фрэнсисом Гэлтоном. Он и его студент Карл Пирсон, который вывел коэффициент корреляции, в 19-ом веке разработали большое количество методов, применяемых для изучения линейных связей, которые коллективно стали известны как методы регрессионного анализа.
Вспомним, что из корреляции не следует причинная обусловленность, причем термины «зависимый» и «независимый» не означают никакой неявной причинной обусловленности. Они представляют собой всего лишь имена для входных и выходных математических значений. Классическим примером является крайне положительная корреляция между числом отправленных на тушение пожара пожарных машин и нанесенным пожаром ущербом. Безусловно, отправка пожарных машин на тушение пожара сама по себе не наносит ущерб. Никто не будет советовать сократить число машин, отправляемых на тушение пожара, как способ уменьшения ущерба. В подобных ситуациях мы должны искать дополнительную переменную, которая была бы связана с другими переменными причинной связью и объясняла корреляцию между ними. В данном примере это может быть размер пожара. Такие скрытые причины называются спутывающими переменными, потому что они искажают нашу возможность определять связь между зависимыми переменными.
Линейные уравнения
Две переменные, которые мы можем обозначить как x и y, могут быть связаны друг с другом строго или нестрого. Самая простая связь между независимой переменной x и зависимой переменной y является прямолинейной, которая выражается следующей формулой:

Здесь значения параметров a и b определяют соответственно точную высоту и крутизну прямой. Параметр a называется пересечением с вертикальной осью или константой, а b — градиентом, наклоном линии или угловым коэффициентом. Например, в соотнесенности между температурными шкалами по Цельсию и по Фаренгейту a = 32 и b = 1.8. Подставив в наше уравнение значения a и b, получим:

Для вычисления 10°С по Фаренгейту мы вместо x подставляем 10:

Таким образом, наше уравнение сообщает, что 10°С равно 50°F, и это действительно так. Используя Python и возможности визуализации pandas, мы можем легко написать функцию, которая переводит градусы из Цельсия в градусы Фаренгейта и выводит результат на график:
Этот пример сгенерирует следующий ниже линейный график:

Обратите внимание, как синяя линия пересекает 0 на шкале Цельсия при величине 32 на шкале Фаренгейта. Пересечение a — это значение y, при котором значение x равно 0.
Наклон линии с неким угловым коэффициентом определяется параметром b; в этом уравнении его значение близко к 2. Как видно, диапазон шкалы Фаренгейта почти вдвое шире диапазона шкалы Цельсия. Другими словами, прямая устремляется вверх по вертикали почти вдвое быстрее, чем по горизонтали.
Остатки
К сожалению, немногие связи столь же чистые, как перевод между градусами Цельсия и Фаренгейта. Прямолинейное уравнение редко позволяет нам определять y строго в терминах x. Как правило, будет иметься ошибка, и, таким образом, уравнение примет следующий вид:

Здесь, ε — это ошибка или остаточный член, обозначающий расхождение между значением, вычисленным параметрами a и b для данного значения x и фактическим значением y. Если предсказанное значение y — это ŷ, то ошибка — это разность между обоими:

Такая ошибка называется остатком. Остаток может возникать из-за случайных факторов, таких как погрешность измерения, либо неслучайных факторов, которые неизвестны. Например, если мы пытаемся предсказать вес как функцию роста, то неизвестные факторы могут состоять из диеты, уровня физической подготовки и типа телосложения (либо просто эффекта округления до самого близкого килограмма).
Если для a и b мы выберем неидеальные параметры, то остаток для каждого x будет больше, чем нужно. Из этого следует, что параметры, которые мы бы хотели найти, должны минимизировать остатки во всех значениях x и y.
Обычные наименьшие квадраты
Для того, чтобы оптимизировать параметры линейной модели, мы бы хотели создать функцию стоимости, так называемую функцией потери, которая количественно выражает то, насколько близко наши предсказания укладывается в данные. Мы не можем просто взять и просуммировать положительные и отрицательные остатки, потому что даже самые большие остатки обнулят друг друга, если их знаки противоположны.
Прежде, чем вычислить сумму, мы можем возвести значения в квадрат, чтобы положительные и отрицательные остатки учитывались в стоимости. Возведение в квадрат также создает эффект наложения большего штрафа на большие ошибки, чем на меньшие ошибки, но не настолько много, чтобы самый большой остаток всегда доминировал.
Выражаясь в терминах задачи оптимизации, мы стремимся выявить коэффициенты, которые минимизируют сумму квадратов остатков. Этот метод называется обычными наименьшими квадратами, от англ. Ordinary Least Squares (OLS), и формула для вычисления наклона линии регрессии по указанному методу выглядит так:

Хотя она выглядит сложнее предыдущих уравнений, на самом деле, эта формула представляет собой всего лишь сумму квадратов остатков, деленную на сумму квадратов отклонений от среднего значения. В данном уравнении используется несколько членов из других уравнений, которые уже рассматривались, и мы можем его упростить, приведя к следующему виду:

Пересечение (a) — это член, позволяющий прямой с заданным наклоном проходить через среднее значение X и Y:

Значения a и b — это коэффициенты, получаемые в результате оценки методом обычных наименьших квадратов.
Наклон и пересечение
Мы уже рассматривали функции covariance , variance и mean , которые нужны для вычисления наклона прямой и точки пересечения для данных роста и веса пловцов. Поэтому вычисление наклона и пересечения имеют тривиальный вид:
В результате будет получен наклон приблизительно 0.0143 и пересечение приблизительно 1.6910.
Интерпретация
Величина пересечения — это значение зависимой переменной (логарифмический вес), когда независимая переменная (рост) равна нулю. Для получения этого значения в килограммах мы можем воспользоваться функцией np.exp , обратной для функции np.log . Наша модель дает основания предполагать, что вероятнее всего вес олимпийского пловца с нулевым ростом будет 5.42 кг. Разумеется, такое предположение лишено всякого смысла, к тому же экстраполяция за пределы границ тренировочных данных является не самым разумным решением.
Величина наклона показывает, насколько y изменяется для каждой единицы изменения в x. Модель исходит из того, что каждый дополнительный сантиметр роста прибавляет в среднем 1.014 кг. веса олимпийских пловцов. Поскольку наша модель основывается на данных о всех олимпийских пловцах, она представляет собой усредненный эффект от увеличения в росте на единицу без учета любого другого фактора, такого как возраст, пол или тип телосложения.
Визуализация
Результат линейного уравнения можно визуализировать при помощи имплементированной ранее функции regression_line и простой функции от x, которая вычисляет ŷ на основе коэффициентов a и b.
Функция regression_line возвращает функцию от x, которая вычисляет a + bx.

Указанная функция может также использоваться для вычисления каждого остатка, показывая степень, с которой наша оценка ŷ отклоняется от каждого измеренного значения y.
График остатков — это график, который показывает остатки на оси Y и независимую переменную на оси X. Если точки на графике остатков разбросаны произвольно по обе стороны от горизонтальной оси, то линейная модель хорошо подогнана к нашим данным:

За исключением нескольких выбросов на левой стороне графика, график остатков, по-видимому, показывает, что линейная модель хорошо подогнана к данным. Построение графика остатков имеет важное значение для получения подтверждения, что линейная модель применима. В линейной модели используются некоторые допущения относительно данных, которые при их нарушении делают не валидными модели, которые вы строите.
Допущения
Первостепенное допущение линейной регрессии состоит в том, что, безусловно, существует линейная зависимость между зависимой и независимой переменной. Кроме того, остатки не должны коррелировать друг с другом либо с независимой переменной. Другими словами, мы ожидаем, что ошибки будут иметь нулевое среднее и постоянную дисперсию по отношению к зависимой и независимой переменной. График остатков позволяет быстро устанавливать, является ли это действительно так.
Левая сторона нашего графика имеет более крупные значения остатков, чем правая сторона. Это соответствует большей дисперсии веса среди более низкорослых спортсменов. Когда дисперсия одной переменной изменяется относительно другой, говорят, что переменные гетероскедастичны, т.е. их дисперсия неоднородна. Этот факт представляет в регрессионном анализе проблему, потому что делает не валидным допущение в том, что модельные ошибки не коррелируют и нормально распределены, и что их дисперсии не варьируются вместе с моделируемыми эффектами.
Гетероскедастичность остатков здесь довольно мала и особо не должна повлиять на качество нашей модели. Если дисперсия на левой стороне графика была бы более выраженной, то она привела бы к неправильной оценке дисперсии методом наименьших квадратов, что в свою очередь повлияло бы на выводы, которые мы делаем, основываясь на стандартной ошибке.
Качество подгонки и R-квадрат
Хотя из графика остатков видно, что линейная модель хорошо вписывается в данные, т.е. хорошо к ним подогнана, было бы желательно количественно измерить качество этой подгонки. Коэффициент детерминации R 2 , или R-квадрат, варьируется в интервале между 0 и 1 и обозначает объяснительную мощность линейной регрессионной модели. Он вычисляет объясненную долю изменчивости в зависимой переменной.
Обычно, чем ближе R 2 к 1, тем лучше линия регрессии подогнана к точкам данных и больше изменчивости в Y объясняется независимой переменной X. R 2 можно вычислить с помощью следующей ниже формулы:

Здесь var(ε) — это дисперсия остатков и var(Y) — дисперсия в Y. В целях понимания смысла этой формулы допустим, что вы пытаетесь угадать чей-то вес. Если вам больше ничего неизвестно об испытуемых, то наилучшей стратегией будет угадывать среднее значение весовых данных внутри популяции в целом. Таким путем средневзвешенная квадратичная ошибка вашей догадки в сравнении с истинным весом будет var(Y), т.е. дисперсией данных веса в популяции.
Но если бы я сообщил вам их рост, то в соответствии с регрессионной моделью вы бы предположили, что a + bx. В этом случае вашей средневзвешенной квадратичной ошибкой было бы или дисперсия остатков модели.
Компонент формулы var(ε)/var(Y) — это соотношение средневзвешенной квадратичной ошибки с объяснительной переменной и без нее, т. е. доля изменчивости, оставленная моделью без объяснения. Дополнение R 2 до единицы — это доля изменчивости, объясненная моделью.
Как и в случае с r , низкий R 2 не означает, что две переменные не коррелированы. Просто может оказаться, что их связь не является линейной.
Значение R 2 описывает качество подгонки линии регрессии к данным. Оптимально подогнанная линия — это линия, которая минимизирует значение R 2 . По мере удаления либо приближения от своих оптимальных значений R 2 всегда будет расти.

Левый график показывает дисперсию модели, которая всегда угадывает среднее значение для , правый же показывает меньшие по размеру квадраты, связанные с остатками, которые остались необъясненными моделью f. С чисто геометрической точки зрения можно увидеть, как модель объяснила большинство дисперсии в y. Приведенный ниже пример вычисляет R 2 путем деления дисперсии остатков на дисперсию значений y:
В результате получим значение 0.753. Другими словами, более 75% дисперсии веса пловцов, выступавших на Олимпийских играх 2012 г., можно объяснить ростом.
В случае простой регрессионной модели (с одной независимой переменной), связь между коэффициентом детерминации R 2 и коэффициентом корреляции r является прямолинейной:
Коэффициент корреляции r может означать, что половина изменчивости в переменной Y объясняется переменной X, но фактически R 2 составит 0.5 2 , т.е. 0.25.
Множественная линейная регрессия
Пока что в этой серии постов мы видели, как строится линия регрессии с одной независимой переменной. Однако, нередко желательно построить модель с несколькими независимыми переменными. Такая модель называется множественной линейной регрессией.
Каждой независимой переменной потребуется свой собственный коэффициент. Вместо того, чтобы для каждой из них пытаться подобрать букву в алфавите, зададим новую переменную β (бета), которая будет содержать все наши коэффициенты:

Такая модель эквивалентна двухфакторной линейно-регрессионной модели, где β1 = a и β2 = b при условии, что x1 всегда гарантированно равен 1, вследствие чего β1 — это всегда константная составляющая, которая представляет наше пересечение, при этом x1 называется (постоянным) смещением уравнения регрессии, или членом смещения.
Обобщив линейное уравнение в терминах β, его легко расширить на столько коэффициентов, насколько нам нужно:

Каждое значение от x1 до xn соответствует независимой переменной, которая могла бы объяснить значение y. Каждое значение от β1 до βn соответствует коэффициенту, который устанавливает относительный вклад независимой переменной.
Простая линейная регрессия преследовала цель объяснить вес исключительно с точки зрения роста, однако объяснить вес людей помогает много других факторов: их возраст, пол, питание, тип телосложения. Мы располагаем сведениями о возрасте олимпийских пловцов, поэтому мы смогли бы построить модель, которая учитывает и эти дополнительные данные.
До настоящего момента мы предоставляли независимую переменную в виде одной последовательности значений, однако при наличии двух и более параметров нам нужно предоставлять несколько значений для каждого x. Мы можем воспользоваться функциональностью библиотеки pandas, чтобы выбрать два и более столбцов и управлять каждым как списком, но есть способ получше: матрицы.
Примеры исходного кода для этого поста находятся в моем репо на Github. Все исходные данные взяты в репозитории автора книги.
Темой следующего поста, поста №3, будут матричные операции, нормальное уравнение и коллинеарность.
http://pandia.ru/text/78/146/82802.php
http://habr.com/ru/post/558084/