Уравнение регрессии
Вместе с этим калькулятором также используют следующие:
Уравнение множественной регрессии
В сервисе для нахождения параметров регрессии используется МНК. Система нормальных уравнений для линейной регрессии: 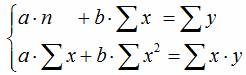 . Также можно получить ответ, используя матричный метод. см. также Статистические функции в Excel
. Также можно получить ответ, используя матричный метод. см. также Статистические функции в Excel
Уравнение парной регрессии относится к уравнению регрессии первого порядка. Если эконометрическая модель содержит только одну объясняющую переменную, то она имеет название парной регрессии. Уравнение регрессии второго порядка и уравнение регрессии третьего порядка относятся к нелинейным уравнениям регрессии.
Пример . Осуществите выбор зависимой (объясняемой) и объясняющей переменной для построения парной регрессионной модели. Дайте графическое изображение регрессионной зависимости. Определите теоретическое уравнение парной регрессии. Оцените адекватность построенной модели (интерпретируйте R-квадрат, показатели t-статистики, F-статистики).
Решение будем проводить на основе процесса эконометрического моделирования.
1-й этап (постановочный) – определение конечных целей моделирования, набора участвующих в модели факторов и показателей, их роли.
Спецификация модели — определение цели исследования и выбор экономических переменных модели.
Ситуационная (практическая) задача. По 10 предприятиям региона изучается зависимость выработки продукции на одного работника y (тыс. руб.) от удельного веса рабочих высокой квалификации в общей численности рабочих x (в %).
2-й этап (априорный) – предмодельный анализ экономической сущности изучаемого явления, формирование и формализация априорной информации и исходных допущений, в частности относящейся к природе и генезису исходных статистических данных и случайных остаточных составляющих в виде ряда гипотез.
Уже на этом этапе можно говорить о явной зависимости уровня квалификации рабочего и его выработкой, ведь чем опытней работник, тем выше его производительность. Но как эту зависимость оценить?
Парная регрессия представляет собой регрессию между двумя переменными – y и x , т. е. модель вида:
Линейная регрессия в машинном обучении
Линейная регрессия ( Linear regression ) — модель зависимости переменной x от одной или нескольких других переменных (факторов, регрессоров, независимых переменных) с линейной функцией зависимости.
Линейная регрессия относится к задаче определения «линии наилучшего соответствия» через набор точек данных и стала прос тым предшественником нелинейных методов, которые используют для обучения нейронных сетей. В этой статье покажем вам примеры линейной регрессии.
Применение линейной регрессии
Предположим, нам задан набор из 7 точек (таблица ниже).
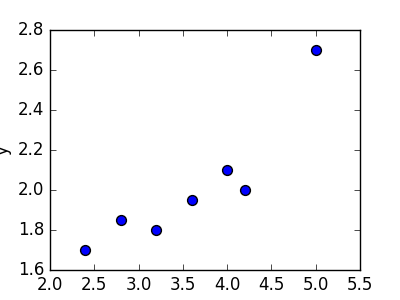
Цель линейной регрессии — поиск линии, которая наилучшим образом соответствует этим точкам. Напомним, что общее уравнение для прямой есть f (x) = m⋅x + b, где m — наклон линии, а b — его y-сдвиг. Таким образом, решение линейной регрессии определяет значения для m и b, так что f (x) приближается как можно ближе к y. Попробуем несколько случайных кандидатов:
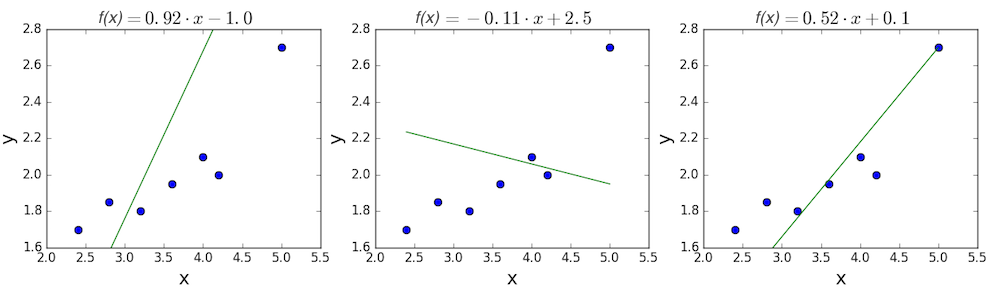
Довольно очевидно, что первые две линии не соответствуют нашим данным. Третья, похоже, лучше, чем две другие. Но как мы можем это проверить? Формально нам нужно выразить, насколько хорошо подходит линия, и мы можем это сделать, определив функцию потерь.
Функция потерь — метод наименьших квадратов
Функция потерь — это мера количества ошибок, которые наша линейная регрессия делает на наборе данных. Хотя есть разные функции потерь, все они вычисляют расстояние между предсказанным значением y( х) и его фактическим значением. Например, взяв строку из среднего примера выше, f(x)=−0.11⋅x+2.5, мы выделяем дистанцию ошибки между фактическими и прогнозируемыми значениями красными пунктирными линиями.
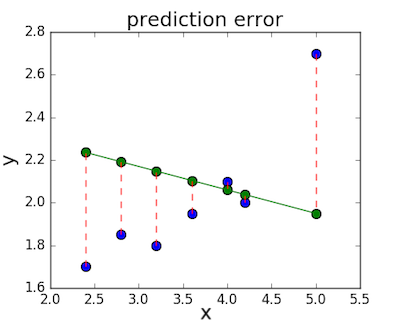
Одна очень распространенная функция потерь называется средней квадратичной ошибкой (MSE). Чтобы вычислить MSE, мы просто берем все значения ошибок, считаем их квадраты длин и усредняем.
Вычислим MSE для каждой из трех функций выше: первая функция дает MSE 0,17, вторая — 0,08, а третья — 0,02. Неудивительно, что третья функция имеет самую низкую MSE, подтверждая нашу догадку, что это линия наилучшего соответствия.
Рассмотрим приведенный ниже рисунок, который использует две визуализации средней квадратичной ошибки в диапазоне, где наклон m находится между -2 и 4, а b между -6 и 8.
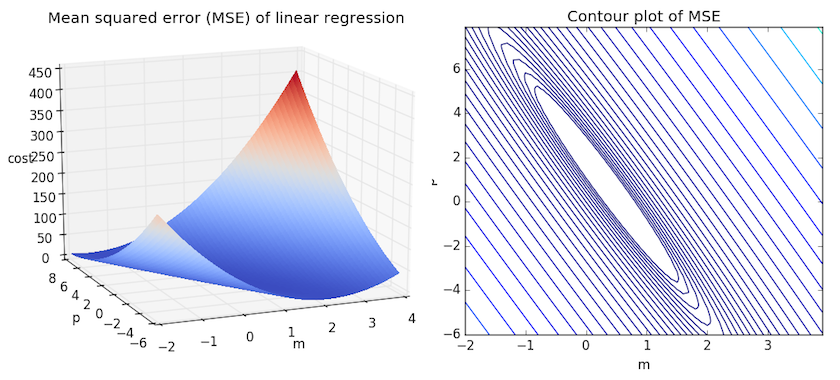 Слева: диаграмма, изображающая среднеквадратичную ошибку для -2≤m≤4, -6≤p≤8 Справа: тот же рисунок, но визуализирован как контурный график, где контурные линии являются логарифмически распределенными поперечными сечениями высоты.
Слева: диаграмма, изображающая среднеквадратичную ошибку для -2≤m≤4, -6≤p≤8 Справа: тот же рисунок, но визуализирован как контурный график, где контурные линии являются логарифмически распределенными поперечными сечениями высоты.
Глядя на два графика, мы видим, что наш MSE имеет форму удлиненной чаши, которая, по-видимому, сглаживается в овале, грубо центрированном по окрестности (m, p) ≈ (0.5, 1.0). Есл и мы построим MSE линейной регрессии для другого датасета, то получим аналогичную форму. Поскольку мы пытаемся минимизировать MSE, наша цель — выяснить, где находится самая низкая точка в чаше.
Больше размерностей
Вышеприведенный пример очень простой, он имеет только одну независимую переменную x и два параметра m и b. Что происходит, когда имеется больше переменных? В общем случае, если есть n переменных, их линейная функция может быть записана как:
Один трюк, который применяют, чтобы упростить это — думать о нашем смещении «b», как о еще одном весе, который всегда умножается на «фиктивное» входное значение 1. Другими словами:
Добавление измерений, на первый взгляд, ужасное усложнение проблемы, но оказывается, постановка задачи остается в точности одинаковой в 2, 3 или в любом количестве измерений. Существует функция потерь, которая выглядит как чаша — гипер-чаша! И, как и прежде, наша цель — найти самую нижнюю часть этой чаши, объективно наименьшее значение, которое функция потерь может иметь в отношении выбора параметров и набора данных.
Итак, как мы вычисляем, где именно эта точка на дне? Распространенный подход — обычный метод наименьших квадратов, который решает его аналитически. Когда есть только один или два параметра для решения, это может быть сделано вручную, и его обычно преподают во вводном курсе по статистике или линейной алгебре.
Проклятие нелинейности
Увы, обычный МНК не используют для оптимизации нейронных сетей, поэтому решение линейной регрессии будет оставлено как упражнение, оставленное читателю. Причина, по которой линейную регрессию не используют, заключается в том, что нейронные сети нелинейны.
Различие между линейными уравнениями, которые мы составили, и нейронной сетью — функция активации (например, сигмоида, tanh, ReLU или других).
Эта нелинейность означает, что параметры не действуют независимо друг от друга, влияя на форму функции потерь. Вместо того, чтобы иметь форму чаши, функция потерь нейронной сети более сложна. Она ухабиста и полна холмов и впадин. Свойство быть «чашеобразной» называется выпуклостью, и это ценное свойство в многопараметрической оптимизации. Выпуклая функция потерь гарантирует, что у нас есть глобальный минимум (нижняя часть чаши), и что все дороги под гору ведут к нему.
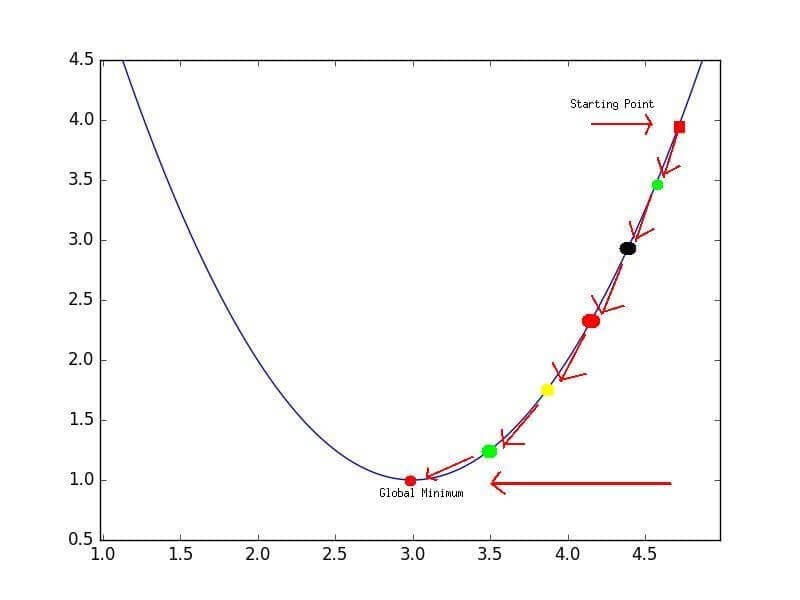 Минимум функции
Минимум функции
Но, вводя нелинейность, мы теряем это удобство ради того, чтобы дать нейронным сетям гораздо большую «гибкость» при моделировании произвольных функций. Цена, которую мы платим, заключается в том, что больше нет простого способа найти минимум за один шаг аналитически. В этом случае мы вынуждены использовать многошаговый численный метод, чтобы прийти к решению. Хотя существует несколько альтернативных подходов, градиентный спуск остается самым популярным методом.
Парная линейная регрессия. Задачи регрессионного анализа
Будут и задачи для самостоятельного решения, к которым можно посмотреть ответы.
Понятие линейной регрессии. Парная линейная регрессия
Линейная регрессия — выраженная в виде прямой зависимость среднего значения какой-либо величины от некоторой другой величины. В отличие от функциональной зависимости y = f(x) , когда каждому значению независимой переменной x соответствует одно определённое значение величины y, при линейной регрессии одному и тому же значению x могут соответствовать в зависимости от случая различные значения величины y.
Если в результате наблюдения установлено, что при каждом определённом значении x существует сколько-то (n) значений переменной y, то зависимость средних арифметических значений y от x и является регрессией в статистическом понимании.
Если установленная зависимость может быть записана в виде уравнения прямой
то эта регрессионная зависимость называется линейной регрессией.
О парной линейной регрессии говорят, когда установлена зависимость между двумя переменными величинами (x и y). Парная линейная регрессия называется также однофакторной линейной регрессией, так как один фактор (независимая переменная x) влияет на результирующую переменную (зависимую переменную y).
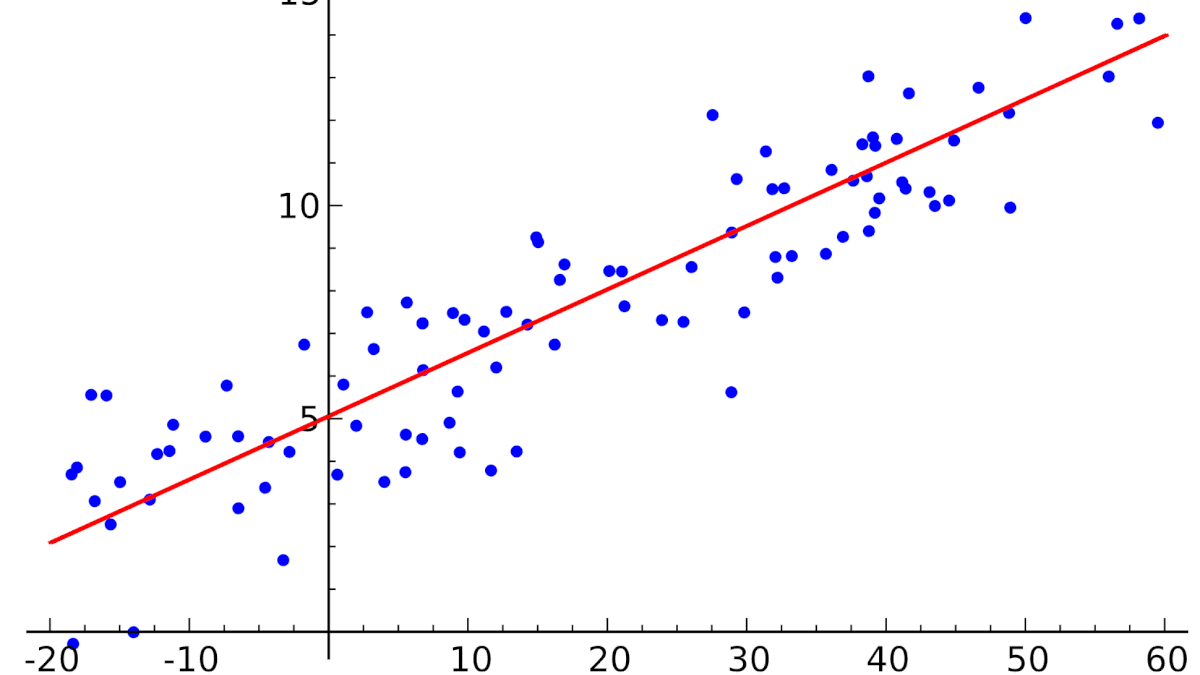
В уроке о корреляционной зависимости были разобраны примеры того, как цена на квартиры зависит от общей площади квартиры и от площади кухни (две различные независимые переменные) и о том, что результаты наблюдений расположены в некотором приближении к прямой, хотя и не на самой прямой. Если точки корреляционной диаграммы соединить ломанной линией, то будет получена линия эмпирической регрессии. А если эта линия будет выровнена в прямую, то полученная прямая будет прямой теоретической регрессии. На рисунке ниже она красного цвета (для увеличения рисунка щёлкнуть по нему левой кнопкой мыши).

По этой прямой теоретической регрессии может быть сделан прогноз или восстановление неизвестных значений зависимой переменной по заданным значениям независимой переменной.
В случае парной линейной регрессии для данных генеральной совокупности связь между независимой переменной (факториальным признаком) X и зависимой переменной (результативным признаком) Y описывает модель
 ,
,
 — свободный член прямой парной линейной регрессии,
— свободный член прямой парной линейной регрессии,
 — коэффициент направления прямой парной линейной регрессии,
— коэффициент направления прямой парной линейной регрессии,
 — случайная погрешность,
— случайная погрешность,
N — число элементов генеральной совокупности.
Уравнение парной линейной регрессии для генеральной совокупности можно построить, если доступны данные обо всех элементах генеральной совокупности. На практике данные всей генеральной совокупности недоступны, но доступны данные об элементах некоторой выборки.
Поэтому параметры генеральной совокупности оценивают при помощи соответствующих параметров соответствующей выборки: свободный член прямой парной линейной регрессии генеральной совокупности заменяют на свободный член прямой парной линейной регрессии выборки  , а коэффициент направления прямой парной линейной регрессии генеральной совокупности — на коэффициент направления прямой парной линейной регрессии выборки
, а коэффициент направления прямой парной линейной регрессии генеральной совокупности — на коэффициент направления прямой парной линейной регрессии выборки  .
.
В результате получаем уравнение парной линейной регрессии выборки


 — оценка полученной с помощью модели линейной регрессии зависимой переменной Y,
— оценка полученной с помощью модели линейной регрессии зависимой переменной Y,
 — погрешность,
— погрешность,
n — размер выборки.
Чтобы уравнение парной линейной регрессии было более похоже на привычное уравнение прямой, его часто также записывают в виде
 .
.
Уравнение парной линейной регрессии и метод наименьших квадратов
Определение коэффициентов уравнения парной линейной регрессии
Если заранее известно, что зависимость между факториальным признаком x и результативным признаком y должна быть линейной, выражающейся в виде уравнения типа , задача сводится к нахождению по некоторой группе точек наилучшей прямой, называемой прямой парной линейной регрессии. Следует найти такие значения коэффициентов a и b , чтобы сумма квадратов отклонений  была наименьшей:
была наименьшей:
 .
.
Если через  и
и  обозначить средние значения признаков X и Y,то полученная с помощью метода наименьших квадратов функция регрессии удовлетворяет следующим условиям:
обозначить средние значения признаков X и Y,то полученная с помощью метода наименьших квадратов функция регрессии удовлетворяет следующим условиям:
- прямая парной линейной регрессии проходит через точку
 ;
; - среднее значение отклонений равна нулю: ;
- значения и не связаны: .
 ;
; ;
; и
и  не связаны:
не связаны:  .
.Условие метода наименьших квадратов выполняется, если значения коэффициентов равны:
 ,
,
 .
.
Пример 1. Найти уравнение парной линейной регрессии зависимости между валовым внутренним продуктом (ВВП) и частным потреблением на основе данных примера урока о корреляционной зависимости (эта ссылка, которая откроется в новом окне, потребуется и при разборе следующих примеров).
Решение. Используем рассчитанные в решении названного выше примера суммы:




Используя эти суммы, вычислим коэффициенты:


Таким образом получили уравнение прямой парной линейной регрессии:

Составить уравнение парной линейной регрессии самостоятельно, а затем посмотреть решение
Пример 2. Найти уравнение парной линейной регрессии для выборки из 6 наблюдений, если уже вычислены следующие промежуточные результаты:
 ;
;
 ;
;
 ;
;
 ;
;
Анализ качества модели линейной регрессии
Метод наименьших квадратов имеет по меньшей мере один существенный недостаток: с его помощью можно найти уравнение линейной регрессии и в тех случаях, когда данные наблюдений значительно рассеяны вокруг прямой регрессии, то есть находятся на значительном расстоянии от этой прямой. В таких случаях за точность прогноза значений зависимой переменной ручаться нельзя. Существуют показатели, которые позволяют оценить качество уравнения линейной регрессии прежде чем использовать модели линейной регрессии для практических целей. Разберём важнейшие из этих показателей.
Коэффициент детерминации
Коэффициент детерминации  принимает значения от 0 до 1 и в случае качественной модели линейной регрессии стремится к единице. Коэффициент детерминации показывает, какую часть общего рассеяния зависимой переменной объясняет независимая переменная:
принимает значения от 0 до 1 и в случае качественной модели линейной регрессии стремится к единице. Коэффициент детерминации показывает, какую часть общего рассеяния зависимой переменной объясняет независимая переменная:
 ,
,
 — сумма квадратов отклонений, объясняемых моделью линейной регрессии, которая характеризует рассеяние точек прямой регрессии относительно арифметического среднего,
— сумма квадратов отклонений, объясняемых моделью линейной регрессии, которая характеризует рассеяние точек прямой регрессии относительно арифметического среднего,
 — общая сумма квадратов отклонений, которая характеризует рассеяние зависимой переменной Y относительно арифметического среднего,
— общая сумма квадратов отклонений, которая характеризует рассеяние зависимой переменной Y относительно арифметического среднего,
 — сумма квадратов отклонений ошибки (не объясняемых моделью линейной регрессии), которая характеризует рассеяние зависимой переменной Y относительно прямой регресии.
— сумма квадратов отклонений ошибки (не объясняемых моделью линейной регрессии), которая характеризует рассеяние зависимой переменной Y относительно прямой регресии.
Пример 3. Даны сумма квадратов отклонений, объясняемых моделью линейной регрессии (3500), общая сумма квадратов отклонений (5000) и сумма квадратов отклонений ошибки (1500). Найти коэффициент детерминации двумя способами.
F-статистика (статистика Фишера) для проверки качества модели линейной регрессии
Минимальное возможное значение F-статистики — 0. Чем выше значение статистики Фишера, тем качественнее модель линейной регрессии. Этот показатель представляет собой отношение объясненной суммы квадратов (в расчете на одну независимую переменную) к остаточной сумме квадратов (в расчете на одну степень свободы):

где m — число объясняющих переменных.
Сумма квадратов остатков
Сумма квадратов остатков (RSS) измеряет необъясненную часть дисперсии зависимой переменной:

 —
—
остатки — разности между реальными значениями зависимой переменной и значениями, оценёнными уравнением линейной регрессии.
В случае качественной модели линейной регрессии сумма квадратов остатков стремится к нулю.
Стандартная ошибка регрессии
Стандартная ошибка регрессии (SEE) измеряет величину квадрата ошибки, приходящейся на одну степень свободы модели:

Чем меньше значение SEE, тем качественнее модель.
Пример 4. Рассчитать коэффициент детерминации для данных из примера 1.
Решение. На основании данных таблицы (она была приведена в примере урока о корреляционной зависимости) получаем, что SST = 63 770,593 , SSE = 10 459,587 , SSR = 53 311,007 .
Можем убедиться, что выполняется закономерность SSR = SST — SSE :
Получаем коэффициент детерминации:
 .
.
Таким образом, 83,6% изменений частного потребления можно объяснить моделью линейной регресии.
Интерпретация коэффициентов уравнения парной линейной регрессии и прогноз значений зависимой переменной
Итак, уравнение парной линейной регрессии:
 .
.
В этом уравнении a — свободный член, b — коэффициент при независимой переменной.
Интерпретация свободного члена: a показывает, на сколько единиц график регрессии смещён вверх при x=0, то есть значение переменной y при нулевом значении переменной x.
Интерпретация коэффициента при независимой переменной: b показывает, на сколько единиц изменится значение зависимой переменной y при изменении x на одну единицу.
Пример 5. Зависимость частного потребления граждан от ВВП (истолкуем это просто: от дохода) описывается уравнением парной линейной регрессии  . Сделать прогноз потребления при доходе в 20 000 у.е. Выяснить, на сколько увеливается потребление при увеличении дохода на 5000 у.е. Меняется ли потребление, если доход не меняется?
. Сделать прогноз потребления при доходе в 20 000 у.е. Выяснить, на сколько увеливается потребление при увеличении дохода на 5000 у.е. Меняется ли потребление, если доход не меняется?
Решение. Подставляем в уравнение парной линейной регрессии x i = 20000 и получаем прогноз потребления при доходе в 20 000 у.е. y i = 17036,4662 .
Подставляем в уравнение парной линейной регрессии x i = 5000 и получаем прогноз увеличения потребления при увеличении дохода на 5000 у.е. y i = 4161,9662 .
Если доход не меняется, то x i = 0 и получаем, что потребление уменьшается на 129,5338 у.е.
Задачи регрессионного анализа
Регрессионный анализ — раздел математической статистики, объединяющий практические методы исследования регрессионной зависимости между величинами по статистическим данным.
Наиболее частые задачи регрессионного анализа:
- установление факта наличия или отсутствия статистических зависимостей между переменными величинами;
- выявление причинных связей между переменными величинами;
- прогноз или восстановление неизвестных значений зависимых переменных по заданным значениям независимых переменных.
Также делаются проверки статистических гипотез о регрессии. Кроме того, при изучении связи между двумя величинами по результатам наблюдений в соответствии с теорией регрессии предполагается, что зависимая переменная имеет некоторое распределение вероятностей при фиксированном значении независимой переменной.
В исследованиях поведения человека, чтобы они претендовали на объективность, важно не только установить зависимость между факторами, но и получить все необходимые статистические показатели для результата проверки соответствующей гипотезы.
Проверка гипотезы о равенстве нулю коэффициента направления прямой парной линейной регрессии
Одна из важнейших гипотез в регрессионном анализе — гипотеза о том, что коэффициент направления прямой регрессии генеральной совокупности равен нулю.
Если это предположение верно, то изменения независимой переменной X не влияют на изменения зависимой переменной Y: переменные X и Y не коррелированы, то есть линейной зависимости Y от X нет.

рассматривают во взаимосвязи с альтернативной гипотезой
 .
.
Статистика коэффициента направления

соответствует распределению Стьюдента с числом степеней свободы v = n — 2 ,
где  — стандартная погрешность коэффициента направления прямой линейной регресии b 1 .
— стандартная погрешность коэффициента направления прямой линейной регресии b 1 .
Доверительный интервал коэффициента направления прямой линейной регрессии:
 .
.
Критическая область, в которой с вероятностью P = 1 — α отвергают нулевую гипотезу и принимают альтернативную гипотезу:

Пример 6. На основе данных из предыдущих примеров (о ВВП и частном потреблении) определить доверительный интервал коэффициента направления прямой линейной регресии 95% и проверить гипотезу о равенстве нулю коэффициента направления прямой парной линейной регрессии.
Можем рассчитать, что  , а стандартная погрешность регрессии
, а стандартная погрешность регрессии  .
.
Таким образом, стандартная погрешность коэффициента направления прямой линейной регресии b 1 :
 .
.
Так как  и
и  (находим по таблице в приложениях к учебникам по статистике), то доверительный интервал 95% коэффициента направления прямой парной линейной регрессии:
(находим по таблице в приложениях к учебникам по статистике), то доверительный интервал 95% коэффициента направления прямой парной линейной регрессии:
 .
.
Так как гипотетическое значение коэффициента — нуль — не принадлежит доверительному интервалу, с вероятностью 95% можем отвергнуть основную гипотезу и принять альтернативную гипотезу, то есть считать, что зависимая переменная Y линейно зависит от независимой переменной X.
http://neurohive.io/ru/osnovy-data-science/linejnaja-regressija/
http://function-x.ru/statistics_regression1.html