Параболическая и полиномиальная регрессии.
Лабораторная работа
Прогнозирование экономических процессов
с помощью табличного процессора Excel.
Требования к содержанию, оформлению и порядку выполнения
Для выполнения лабораторной работы необходимо создать новую рабочую книгу Excel под именем «Ваша фамилия, Лабораторная работа №1, Вариант №_» (например: «Иванов И.П. Лабораторная работа №1»Вариант №4).
Перед выполнением лабораторной работы изучите теоретическую часть и методику выполнения заданий.
Задания необходимо выполнить и оформить согласно своему варианту. Рабочие листы рабочей книги должны быть именованы Задание1, Задание2. Результаты выполнения заданий занести в файл отчета.
Варианты лабораторной работы распределяются согласно номеру № в списке группы см. таблицу
| № | Вар. | № | Вар. | № | Вар. | № | Вар. | № | Вар. | № | Вар. | № | Вар. |
После выполнения лабораторной работы ответьте на контрольные вопросы. Ответы на контрольные вопросы поместите в файл отчета. Свою рабочую книгу вместе с файлом отчета, необходимо предоставить преподавателю на дискете, подписав ее «Отчет по лабораторной работе №2 студента Иванова И.П., гр. 170404».
Теоретическая часть
Прогнозирование — это метод научного исследования, ставящей своей целью предусмотреть возможные варианты тех процессов и явлений, которые выбраны в качестве предмета анализа.
Задачами экономического прогнозирования являются: предвидение возможного распределения ресурсов по различным направлениям; определение нижних и верхних границ получаемых результатов; оценка максимально возможного количества ресурсов, необходимого для решения хозяйственных и научно-технических проблем и др.
В зависимости от периода времени, на которой составляется прогноз (периода упреждения), прогнозы бывает:
Временная градация прогнозов является относительной и зависит от характера и цели данного прогноза.
Для выполнения краткосрочного прогноза чаще всего применяется метод экстраполяции.
Метод экстраполяциизаключается в нахождении значений, лежащих за пределами данного статистического ряда: по известным значениям статистического ряда находятся другие значения, лежащие за пределами этого ряда.
При экстраполяции переносится выводы, сделанные при изучении тенденций развития явления в прошлом и настоящем, на будущее, т.е. в основе экстраполяции лежит предположение об определенной стабильности факторных признаков, влияющих на развитие данного явления.


Рис.1. Основные обозначения метода экстраполяции.
При экстраполяции (см. рис.1.) используется следующая терминология:
t1 – глубина ретроспекции;
t2 – момент прогнозирования;
t3 – прогнозный горизонт;
t2 – t1 – интервал наблюдения (промежуток времени, на базе которого исследуется история развития объекта прогнозирования);
t3 – t2 – интервал упреждения (промежуток времени на который разрабатывается прогноз).
Чем более устойчивый характер носит прогнозируемые процессы и тенденции, тем дальше может быть отодвинут горизонт прогнозирования. Как показывает практика, интервал наблюдения должен быть в три и более раз длиннее интервала упреждения. Как правило, этот период – довольно короткий. Метод экстраполирования не работает при скачкообразных процессах.
Метод экстраполяции легко реализуется на персональном компьютере. Использование современных табличных процессоров, таких как MS Excel позволяет оперативно проводить прогнозирование экономических процессов с использованием экстраполяционного метода.
Для повышения точности прогноза, необходимо учитывать зависимость прогнозируемой величины Y, от внешних факторов Х. Совокупность изучаемых величин подвержена, как правило, воздействию случайных факторов. В связи с этим зависимость прогнозируемой величины Y, от внешних факторов Х чаще всего статистическая, или – корреляционная.
Статистической называется зависимость случайных величин, при которой каждому значению одной их них соответствует закон распределения другой, то есть изменение одной из величин влечет изменение распределения другой.
Корреляционной называется статистическая зависимость случайных величин, при которой изменение одной из величин влечет изменение среднего значения другой.
Мерой корреляционной зависимости двух случайных величин Х и Y служит коэффициент корреляции r, который является безразмерной величиной, и поэтому он не зависит от выбора единиц измерения изучаемых величин.
Свойства коэффициента корреляции:
1) Если две случайные величины Х и Y независимы, то их коэффициент корреляции равен нулю, т.е. r=0.
2) Модуль коэффициента корреляции не превышает единицы, т.е. |r|£1, что эквивалентно двойному неравенству: -1£r£1.
3) Равенство коэффициента -1 или +1 показывает наличие функциональной (прямой) связи. Знак «+» указывает на связь прямую (увеличение или уменьшение одного признака сопровождается аналогичным изменением другого признака), знак «-» — на связь обратную (увеличение или уменьшение одного признака сопровождается противоположным по направлению изменением другого признака).
После определения наиболее существенных факторных признаков влияющих прогнозируемую величину, не менее важно установить их математическое описание (уравнение), дающее возможность численно оценивать результативный показатель через факторные признаки.
Уравнение, выражающее изменение средней величины результативного показателя в зависимости от значений факторных признаков, называется уравнение регрессии.
Линии на координатной плоскости, соответствующие уравнениям регрессии называются линиями регрессии.
Корреляционные зависимости могут выражаться уравнениями регрессии различных видов: линейной, параболической, гиперболической, показательной и т.д.
Линейная регрессия
Уравнением линейной регрессии (выборочным) Y на Х называется зависимость  от наблюдаемых значений величины Х, выраженная линейной функцией:
от наблюдаемых значений величины Х, выраженная линейной функцией:
 , (1)
, (1)
где величина r называется коэффициентом линейной регрессии Y на Х, b — константа.
Линейная аппроксимация хорошо описывает изменение величин, происходящее с постоянной скоростью.
Если коэффициент корреляции двух величин Х и Y равен r=±1, то эти величины связаны линейной зависимостью. Коэффициент корреляции служит мерой силы (тесноты) линейной зависимости измеряемых величин. На практике, если коэффициент корреляции двух величин Х и Y |r|>0.5, то считают, что есть основания предполагать наличие линейной зависимости между этими величинами. Однако ориентироваться при выборе типа линии регрессии (линейной или нелинейной) лучше по виду эмпирической зависимости величин Х и Y.
Параболическая и полиномиальная регрессии.
Параболической зависимостью величины Y от величины Х называется зависимость, выраженная квадратичной функцией (параболой 2-ого порядка):
 . (2)
. (2)
Это уравнение называется уравнением параболической регрессии Y на Х. Параметры а, b, с называются коэффициентами параболической регрессии. Вычисление коэффициентов параболической регрессии всегда громоздко, поэтому для расчетов рекомендуется использовать компьютер.
Уравнение (2) параболической регрессии является частным случаем более общей регрессии, называемой полиномиальной. Полиномиальной зависимостью величины Y от величины Х называется зависимость, выраженная полиномом n-ого порядка:
 , (3)
, (3)
где числа аi (i=0,1,…, n) называются коэффициентами полиномиальной регрессии.
Полиномиальная аппроксимация используется для описания величин, попеременно возрастающих и убывающих. Она полезна, например, для анализа большого набора данных о нестабильной величине.
Степенная регрессия.
Степенной зависимостью величины Y от величины Х называется зависимость вида:
 . (4)
. (4)
Это уравнение называется уравнением степенной регрессии Y на Х. Параметры а и b называются коэффициентами степенной регрессии.
Степенная аппроксимация полезна для описания монотонно возрастающей либо монотонно убывающей величины, например расстояния, пройденного разгоняющимся автомобилем. Использование степенной аппроксимации невозможно, если данные содержат нулевые или отрицательные значения.
Показательная регрессия.
Показательной (или экспоненциальной) зависимостью величины Y от величины Х называется зависимость вида:
 (или
(или  ). (5)
). (5)
Это уравнение называется уравнением показательной (или экспоненциальной) регрессии Y на Х. Параметры а (или k) и b называются коэффициентами показательной (или экспоненциальной) регрессии.
Экспоненциальная аппроксимация полезна в том случае, если скорость изменения данных непрерывно возрастает. Однако для данных, которые содержат нулевые или отрицательные значения, этот вид приближения неприменим.
Логарифмическая регрессия.
Логарифмической зависимостью величины Y от величины Х называется зависимость вида:
 (6)
(6)
Это уравнение называется уравнением логарифмической регрессии Y на Х. Параметры а и b называются коэффициентами логарифмической регрессии.
Логарифмическая аппроксимация полезна для описания величины, которая вначале быстро растет или убывает, а затем постепенно стабилизируется. Логарифмическая аппроксимация использует как отрицательные, так и положительные величины.
Гиперболическая регрессия.
Гиперболической зависимостью величины Y от величины Х называется зависимость вида:
 . (7)
. (7)
Это уравнение называется уравнением гиперболической регрессии Y на Х. Параметры а и b называются коэффициентами гиперболической регрессии.
Качество построения уравнений регрессии характеризует средняя ошибка аппроксимации или относительная ошибка прогноза:
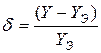 (8)
(8)
где Yэ – эмпирическое значение прогнозируемого показателя; Y – расчетное значение прогнозируемого показателя.
Проведение регрессионного анализа можно разделить на три этапа: выбор формы зависимости (вида уравнения) на основе статистических данных, вычисление коэффициентов выбранного уравнения, оценка достоверности выбранного уравнения.
Использование табличного процессора позволяет легко выполнить все этапы регрессионного анализа.
Уравнение нелинейной регрессии
Вместе с этим калькулятором также используют следующие:
Уравнение множественной регрессии
Виды нелинейной регрессии
| Вид | Класс нелинейных моделей |
| Нелинейные относительно включенных в анализ объясняющих переменных, но линейные по оцениваемым параметрам |
| Нелинейные по оцениваемым параметрам |
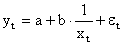
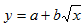
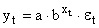
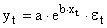

Здесь ε — случайная ошибка (отклонение, возмущение), отражающая влияние всех неучтенных факторов.
Уравнению регрессии первого порядка — это уравнение парной линейной регрессии.
Уравнение регрессии второго порядка это полиномальное уравнение регрессии второго порядка: y = a + bx + cx 2 .
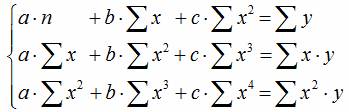
Уравнение регрессии третьего порядка соответственно полиномальное уравнение регрессии третьего порядка: y = a + bx + cx 2 + dx 3 .
Чтобы привести нелинейные зависимости к линейной используют методы линеаризации (см. метод выравнивания):
- Замена переменных.
- Логарифмирование обеих частей уравнения.
- Комбинированный.
| y = f(x) | Преобразование | Метод линеаризации |
| y = b x a | Y = ln(y); X = ln(x) | Логарифмирование |
| y = b e ax | Y = ln(y); X = x | Комбинированный |
| y = 1/(ax+b) | Y = 1/y; X = x | Замена переменных |
| y = x/(ax+b) | Y = x/y; X = x | Замена переменных. Пример |
| y = aln(x)+b | Y = y; X = ln(x) | Комбинированный |
| y = a + bx + cx 2 | x1 = x; x2 = x 2 | Замена переменных |
| y = a + bx + cx 2 + dx 3 | x1 = x; x2 = x 2 ; x3 = x 3 | Замена переменных |
| y = a + b/x | x1 = 1/x | Замена переменных |
| y = a + sqrt(x)b | x1 = sqrt(x) | Замена переменных |
Пример . По данным, взятым из соответствующей таблицы, выполнить следующие действия:
- Построить поле корреляции и сформулировать гипотезу о форме связи.
- Рассчитать параметры уравнений линейной, степенной, экспоненциальной, полулогарифмической, обратной, гиперболической парной регрессии.
- Оценить тесноту связи с помощью показателей корреляции и детерминации.
- Дать с помощью среднего (общего) коэффициента эластичности сравнительную оценку силы связи фактора с результатом.
- Оценить с помощью средней ошибки аппроксимации качество уравнений.
- Оценить с помощью F-критерия Фишера статистическую надежность результатов регрессионного моделирования. По значениям характеристик, рассчитанных в пп. 4, 5 и данном пункте, выбрать лучшее уравнение регрессии и дать его обоснование.
- Рассчитать прогнозное значение результата, если прогнозное значение фактора увеличится на 15% от его среднего уровня. Определить доверительный интервал прогноза для уровня значимости α=0,05 .
- Оценить полученные результаты, выводы оформить в аналитической записке.
| Год | Фактическое конечное потребление домашних хозяйств (в текущих ценах), млрд. руб. (1995 г. — трлн. руб.), y | Среднедушевые денежные доходы населения (в месяц), руб. (1995 г. — тыс. руб.), х |
| 1995 | 872 | 515,9 |
| 2000 | 3813 | 2281,1 |
| 2001 | 5014 | 3062 |
| 2002 | 6400 | 3947,2 |
| 2003 | 7708 | 5170,4 |
| 2004 | 9848 | 6410,3 |
| 2005 | 12455 | 8111,9 |
| 2006 | 15284 | 10196 |
| 2007 | 18928 | 12602,7 |
| 2008 | 23695 | 14940,6 |
| 2009 | 25151 | 16856,9 |
Решение. В калькуляторе последовательно выбираем виды нелинейной регрессии. Получим таблицу следующего вида.
Экспоненциальное уравнение регрессии имеет вид y = a e bx
После линеаризации получим: ln(y) = ln(a) + bx
Получаем эмпирические коэффициенты регрессии: b = 0.000162, a = 7.8132
Уравнение регрессии: y = e 7.81321500 e 0.000162x = 2473.06858e 0.000162x
Степенное уравнение регрессии имеет вид y = a x b
После линеаризации получим: ln(y) = ln(a) + b ln(x)
Эмпирические коэффициенты регрессии: b = 0.9626, a = 0.7714
Уравнение регрессии: y = e 0.77143204 x 0.9626 = 2.16286x 0.9626
Гиперболическое уравнение регрессии имеет вид y = b/x + a + ε
После линеаризации получим: y=bx + a
Эмпирические коэффициенты регрессии: b = 21089190.1984, a = 4585.5706
Эмпирическое уравнение регрессии: y = 21089190.1984 / x + 4585.5706
Логарифмическое уравнение регрессии имеет вид y = b ln(x) + a + ε
Эмпирические коэффициенты регрессии: b = 7142.4505, a = -49694.9535
Уравнение регрессии: y = 7142.4505 ln(x) — 49694.9535
Уравнение параболической регрессии
В некоторых случаях эмпирические данные статистической совокупности, изображенные наглядно с помощью координатной диаграммы, показывают, что увеличение фактора сопровождаются опережающим ростом результата. Для теоретического описания такого рода корреляционной взаимосвязи признаков можно взять уравнение параболической регрессии второго порядка:
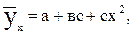 (11.16)
(11.16)
где  , – параметр, показывающий среднее значение результативного признака при условии полной изоляции влияния фактора (х=0);
, – параметр, показывающий среднее значение результативного признака при условии полной изоляции влияния фактора (х=0);  – коэффициент пропорциональности изменения результата при условии абсолютного прироста признака-фактора на каждую его единицу; с – коэффициент ускорения (замедления) прироста результативного признака на каждую единицу фактора.
– коэффициент пропорциональности изменения результата при условии абсолютного прироста признака-фактора на каждую его единицу; с – коэффициент ускорения (замедления) прироста результативного признака на каждую единицу фактора.
Положив в основу вычисления параметров , , с способ наименьших квадратов и приняв условно срединное значение ранжированного ряда за начальное, будем иметь Σх=0, Σх 3 =0. При этом система уравнений в упрощенном виде будет:
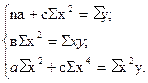
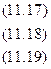
Из этих уравнений можно найти параметры , , с, которые в общем виде можно записать так:
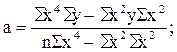 (11.20)
(11.20)
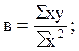 (11.21)
(11.21)
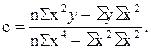 (11.22)
(11.22)
Отсюда видно, что для определения параметров , , с необходимо рассчитать следующие значения: Σ у, Σ ху, Σ х 2 , Σ х 2 у, Σ х 4 . С этой целью можно воспользоваться макетом табл. 11.9.
Допустим, имеются данные об удельном весе посевов картофеля в структуре всех посевных площадей и урожае (валовом сборе) культуры в 30 сельскохозяйственных организациях. Необходимо составить и решить уравнение корреляционной взаимосвязи между этими показателями.
Т а б л и ц а 11.9. Расчет вспомогательных показателей для уравнения
Параболической регрессии
| № п.п. | х | у | ху | х 2 | х 2 у | х 4 |
| х1 | у1 | х1у1 | 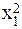 | 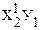 | 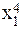 | |
| х2 | у2 | х2у2 | 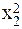 | 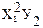 | 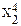 | |
| … | … | … | … | … | … | … |
| n | хn | уn | хnуn | 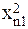 | 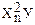 | 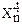 |
| Σ | Σх | Σу | Σху | Σх 2 | Σх 2 у | Σх 4 |
Графическое изображение поля корреляции показало, что изучаемые показатели эмпирически связаны между собой линией, приближающейся к параболе второго порядка. Поэтому расчет необходимых параметров , , с в составе искомого уравнения параболической регрессии проведем с использованием макета табл. 11.10.
Т а б л и ц а 11.10. Расчет вспомогательных данных для уравнения
Параболической регрессии
| № п.п. | х, % | у, тыс.т | ху | х 2 | х 2 у | х 4 |
| 1,0 | 5,0 | 5,0 | 1,0 | 5,0 | 1,0 | |
| 1,5 | 7,0 | 10,5 | 2,3 | 15,8 | 5,0 | |
| … | … | … | … | … | … | … |
| n | 8,0 | 20,0 | 160,0 | 64,0 | ||
| Σ |
Подставим конкретные значения Σ у=495, Σ ху=600, Σ х 2 =750, Σ х 2 у=12375, Σ х 4 =18750, имеющиеся в табл. 11.10, в формулы (11.20), (11.21), (11.22). Получим
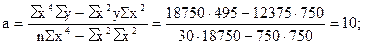
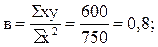
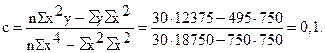
Таким образом, уравнение параболической регрессии, выражающие влияние удельного веса посевов картофеля в структуре посевных площадей на урожай (валовой сбор) культуры в сельскохозяйственных организациях, имеет следующий вид:
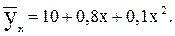 (11.23)
(11.23)
Уравнение 11.23 показывает, что в условиях заданной выборочной совокупности средний урожай (валовой сбор) картофеля (10 тыс. ц) может быть получен без влияния изучаемого фактора – повышения удельного веса посевов культуры в структуре посевных площадей, т.е. при таком условии, когда колебания удельного веса посевов не будут оказывать воздействие на размер урожая картофеля (х=0). Параметр (коэффициент пропорциональности) в=0,8 показывает, что каждый процент повышения удельного веса посевов обеспечивает прирост урожая в среднем на 0,8 тыс. т, а параметр с=0,1 свидетельствует о том, что на один процент (в квадрате) ускоряется приращение урожая в среднем на 0,1 тыс. т картофеля.
http://math.semestr.ru/corel/noncorel.php
http://lektsii.org/3-50985.html