Решения задач: линейная регрессия и коэффициент корреляции
Парная линейная регрессия — это зависимость между одной переменной и средним значением другой переменной. Чаще всего модель записывается как $y=ax+b+e$, где $x$ — факторная переменная, $y$ — результативная (зависимая), $e$ — случайная компонента (остаток, отклонение).
В учебных задачах по математической статистике обычно используется следующий алгоритм для нахождения уравнения регрессии.
- Выбор модели (уравнения). Часто модель задана заранее (найти линейную регрессию) или для подбора используют графический метод: строят диаграмму рассеяния и анализируют ее форму.
- Вычисление коэффициентов (параметров) уравнения регрессии. Часто для этого используют метод наименьших квадратов.
- Проверка значимости коэффициента корреляции и параметров модели (также для них можно построить доверительные интервалы), оценка качества модели по критерию Фишера.
- Анализ остатков, вычисление стандартной ошибки регрессии, прогноз по модели (опционально).
Ниже вы найдете решения для парной регрессии (по рядам данных или корреляционной таблице, с разными дополнительными заданиями) и пару задач на определение и исследование коэффициента корреляции.
Примеры решений онлайн: линейная регрессия
Простая выборка
Пример 1. Имеются данные средней выработки на одного рабочего Y (тыс. руб.) и товарооборота X (тыс. руб.) в 20 магазинах за квартал. На основе указанных данных требуется:
1) определить зависимость (коэффициент корреляции) средней выработки на одного рабочего от товарооборота,
2) составить уравнение прямой регрессии этой зависимости.
Пример 2. С целью анализа взаимного влияния зарплаты и текучести рабочей силы на пяти однотипных фирмах с одинаковым числом работников проведены измерения уровня месячной зарплаты Х и числа уволившихся за год рабочих Y:
X 100 150 200 250 300
Y 60 35 20 20 15
Найти линейную регрессию Y на X, выборочный коэффициент корреляции.
Пример 3. Найти выборочные числовые характеристики и выборочное уравнение линейной регрессии $y_x=ax+b$. Построить прямую регрессии и изобразить на плоскости точки $(x,y)$ из таблицы. Вычислить остаточную дисперсию. Проверить адекватность линейной регрессионной модели по коэффициенту детерминации.
Пример 4. Вычислить коэффициенты уравнения регрессии. Определить выборочный коэффициент корреляции между плотностью древесины маньчжурского ясеня и его прочностью.
Решая задачу необходимо построить поле корреляции, по виду поля определить вид зависимости, написать общий вид уравнения регрессии Y на Х, определить коэффициенты уравнения регрессии и вычислить коэффициенты корреляции между двумя заданными величинами.
Пример 5. Компанию по прокату автомобилей интересует зависимость между пробегом автомобилей X и стоимостью ежемесячного технического обслуживания Y. Для выяснения характера этой связи было отобрано 15 автомобилей. Постройте график исходных данных и определите по нему характер зависимости. Рассчитайте выборочный коэффициент линейной корреляции Пирсона, проверьте его значимость при 0,05. Постройте уравнение регрессии и дайте интерпретацию полученных результатов.
Корреляционная таблица
Пример 6. Найти выборочное уравнение прямой регрессии Y на X по заданной корреляционной таблице
Пример 7. В таблице 2 приведены данные зависимости потребления Y (усл. ед.) от дохода X (усл. ед.) для некоторых домашних хозяйств.
1. В предположении, что между X и Y существует линейная зависимость, найдите точечные оценки коэффициентов линейной регрессии.
2. Найдите стандартное отклонение $s$ и коэффициент детерминации $R^2$.
3. В предположении нормальности случайной составляющей регрессионной модели проверьте гипотезу об отсутствии линейной зависимости между Y и X.
4. Каково ожидаемое потребление домашнего хозяйства с доходом $x_n=7$ усл. ед.? Найдите доверительный интервал для прогноза.
Дайте интерпретацию полученных результатов. Уровень значимости во всех случаях считать равным 0,05.
Пример 8. Распределение 100 новых видов тарифов на сотовую связь всех известных мобильных систем X (ден. ед.) и выручка от них Y (ден.ед.) приводится в таблице:
Необходимо:
1) Вычислить групповые средние и построить эмпирические линии регрессии;
2) Предполагая, что между переменными X и Y существует линейная корреляционная зависимость:
А) найти уравнения прямых регрессии, построить их графики на одном чертеже с эмпирическими линиями регрессии и дать экономическую интерпретацию полученных уравнений;
Б) вычислить коэффициент корреляции, на уровне значимости 0,05 оценить его значимость и сделать вывод о тесноте и направлении связи между переменными X и Y;
В) используя соответствующее уравнение регрессии, оценить среднюю выручку от мобильных систем с 20 новыми видами тарифов.
Коэффициент корреляции
Пример 9. На основании 18 наблюдений установлено, что на 64% вес X кондитерских изделий зависит от их объема Y. Можно ли на уровне значимости 0,05 утверждать, что между X и Y существует зависимость?
Пример 10. Исследование 27 семей по среднедушевому доходу (Х) и сбережениям (Y) дало результаты: $\overline
Корреляционная таблица
Пример 1 . По данной корреляционной таблице построить прямые регрессии с X на Y и с Y на X . Найти соответствующие коэффициенты регрессии и коэффициент корреляции между X и Y .
| y/x | 15 | 20 | 25 | 30 | 35 | 40 |
| 100 | 2 | 2 | ||||
| 120 | 4 | 3 | 10 | 3 | ||
| 140 | 2 | 50 | 7 | 10 | ||
| 160 | 1 | 4 | 3 | |||
| 180 | 1 | 1 |
Решение:
Уравнение линейной регрессии с y на x будем искать по формуле
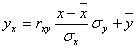
а уравнение регрессии с x на y, использовав формулу:
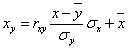
где x x , y — выборочные средние величин x и y, σx, σy — выборочные среднеквадратические отклонения.
Находим выборочные средние:
x = (15(1 + 1) + 20(2 + 4 + 1) + 25(4 + 50) + 30(3 + 7 + 3) + 35(2 + 10 + 10) + 40(2 + 3))/103 = 27.961
y = (100(2 + 2) + 120(4 + 3 + 10 + 3) + 140(2 + 50 + 7 + 10) + 160(1 + 4 + 3) + 180(1 + 1))/103 = 136.893
Выборочные дисперсии:
σ 2 x = (15 2 (1 + 1) + 20 2 (2 + 4 + 1) + 25 2 (4 + 50) + 30 2 (3 + 7 + 3) + 35 2 (2 + 10 + 10) + 40 2 (2 + 3))/103 — 27.961 2 = 30.31
σ 2 y = (100 2 (2 + 2) + 120 2 (4 + 3 + 10 + 3) + 140 2 (2 + 50 + 7 + 10) + 160 2 (1 + 4 + 3) + 180 2 (1 + 1))/103 — 136.893 2 = 192.29
Откуда получаем среднеквадратические отклонения:
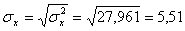 и
и 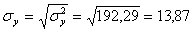
Определим коэффициент корреляции:
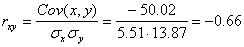
где ковариация равна:
Cov(x,y) = (35•100•2 + 40•100•2 + 25•120•4 + 30•120•3 + 35•120•10 + 40•120•3 + 20•140•2 + 25•140•50 + 30•140•7 + 35•140•10 + 15•160•1 + 20•160•4 + 30•160•3 + 15•180•1 + 20•180•1)/103 — 27.961 • 136.893 = -50.02
Запишем уравнение линий регрессии y(x):
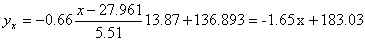
и уравнение x(y):
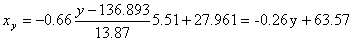
Построим найденные уравнения регрессии на чертеже, из которого сделаем следующие вывод:
1) обе линии проходят через точку с координатами (27.961; 136.893)
2) все точки расположены близко к линиям регрессии.

Пример 2 . По данным корреляционной таблицы найти условные средние y и x . Оценить тесноту линейной связи между признаками x и y и составить уравнения линейной регрессии y по x и x по y . Сделать чертеж, нанеся его на него условные средние и найденные прямые регрессии. Оценить силу связи между признаками с помощью корреляционного отношения.
Корреляционная таблица:
| X / Y | 2 | 4 | 6 | 8 | 10 |
| 1 | 5 | 4 | 2 | 0 | 0 |
| 2 | 0 | 6 | 3 | 3 | 0 |
| 3 | 0 | 0 | 1 | 2 | 3 |
| 5 | 0 | 0 | 0 | 0 | 1 |
Уравнение линейной регрессии с y на x имеет вид:
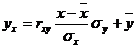
Уравнение линейной регрессии с x на y имеет вид:
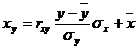
найдем необходимые числовые характеристики.
Выборочные средние:
x = (2(5) + 4(4 + 6) + 6(2 + 3 + 1) + 8(3 + 2) + 10(3 + 1) + )/30 = 5.53
y = (2(5) + 4(4 + 6) + 6(2 + 3 + 1) + 8(3 + 2) + 10(3 + 1) + )/30 = 1.93
Дисперсии:
σ 2 x = (2 2 (5) + 4 2 (4 + 6) + 6 2 (2 + 3 + 1) + 8 2 (3 + 2) + 10 2 (3 + 1))/30 — 5.53 2 = 6.58
σ 2 y = (1 2 (5 + 4 + 2) + 2 2 (6 + 3 + 3) + 3 2 (1 + 2 + 3) + 5 2 (1))/30 — 1.93 2 = 0.86
Откуда получаем среднеквадратические отклонения:
σx = 2.57 и σy = 0.93
и ковариация:
Cov(x,y) = (2•1•5 + 4•1•4 + 6•1•2 + 4•2•6 + 6•2•3 + 8•2•3 + 6•3•1 + 8•3•2 + 10•3•3 + 10•5•1)/30 — 5.53 • 1.93 = 1.84
Определим коэффициент корреляции:
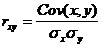
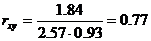
Запишем уравнения линий регрессии y(x):
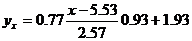
и вычисляя, получаем:
yx = 0.28 x + 0.39
Запишем уравнения линий регрессии x(y):
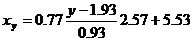
и вычисляя, получаем:
xy = 2.13 y + 1.42
Если построить точки, определяемые таблицей и линии регрессии, увидим, что обе линии проходят через точку с координатами (5.53; 1.93) и точки расположены близко к линиям регрессии.
Значимость коэффициента корреляции.
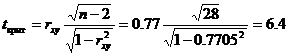
По таблице Стьюдента с уровнем значимости α=0.05 и степенями свободы k=30-m-1 = 28 находим tкрит:
tкрит (n-m-1;α/2) = (28;0.025) = 2.048
где m = 1 — количество объясняющих переменных.
Если tнабл > tкритич, то полученное значение коэффициента корреляции признается значимым (нулевая гипотеза, утверждающая равенство нулю коэффициента корреляции, отвергается).
Поскольку tнабл > tкрит, то отклоняем гипотезу о равенстве 0 коэффициента корреляции. Другими словами, коэффициент корреляции статистически — значим.
Пример 3 . Распределение 50 предприятий пищевой промышленности по степени автоматизации производства Х (%) и росту производительности труда Y (%) представлено в таблице. Необходимо:
1. Вычислить групповые средние i и j x y, построить эмпирические линии регрессии.
2. Предполагая, что между переменными Х и Y существует линейная корреляционная зависимость:
а) найти уравнения прямых регрессии, построить их графики на одном чертеже с эмпирическими линиями регрессии и дать экономическую интерпретацию полученных уравнений;
б) вычислить коэффициент корреляции; на уровне значимости α= 0,05 оценить его значимость и сделать вывод о тесноте и направлении связи между переменными Х и Y;
в) используя соответствующее уравнение регрессии, оценить рост производительности труда при степени автоматизации производства 43%.
Скачать решение
Пример . По корреляционной таблице рассчитать ковариацию и коэффициент корреляции, построить прямые регрессии.
Пример 4 . Найти выборочное уравнение прямой Y регрессии Y на X по данной корреляционной таблице.
Решение находим с помощью калькулятора.
Скачать
Пример №4
Пример 5 . С целью анализа взаимного влияния прибыли предприятия и его издержек выборочно были проведены наблюдения за этими показателями в течение ряда месяцев: X — величина месячной прибыли в тыс. руб., Y — месячные издержки в процентах к объему продаж.
Результаты выборки сгруппированы и представлены в виде корреляционной таблицы, где указаны значения признаков X и Y и количество месяцев, за которые наблюдались соответствующие пары значений названных признаков.
Решение.
Пример №5
Пример №6
Пример №7
Пример 6 . Данные наблюдений над двумерной случайной величиной (X, Y) представлены в корреляционной таблице. Методом наименьших квадратов найти выборочное уравнение прямой регрессии Y на X. Построить график уравнения регрессии и показать точки (x;y)б рассчитанные по таблице данных.
Решение.
Скачать решение
Пример 7 . Дана корреляционная таблица для величин X и Y, X- срок службы колеса вагона в годах, а Y — усредненное значение износа по толщине обода колеса в миллиметрах. Определить коэффициент корреляции и уравнения регрессий.
| X / Y | 0 | 2 | 7 | 12 | 17 | 22 | 27 | 32 | 37 | 42 |
| 0 | 3 | 6 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 25 | 108 | 44 | 8 | 2 | 0 | 0 | 0 | 0 | 0 |
| 2 | 30 | 50 | 60 | 21 | 5 | 5 | 0 | 0 | 0 | 0 |
| 3 | 1 | 11 | 33 | 32 | 13 | 2 | 3 | 1 | 0 | 0 |
| 4 | 0 | 5 | 5 | 13 | 13 | 7 | 2 | 0 | 0 | 0 |
| 5 | 0 | 0 | 1 | 2 | 12 | 6 | 3 | 2 | 1 | 0 |
| 6 | 0 | 1 | 0 | 1 | 0 | 0 | 2 | 1 | 0 | 1 |
| 7 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 0 |
Решение.
Скачать решение
Пример 8 . По заданной корреляционной таблице определить групповые средние количественных признаков X и Y. Построить эмпирические и теоретические линии регрессии. Предполагая, что между переменными X и Y существует линейная зависимость:
- Вычислить выборочный коэффициент корреляции и проанализировать степень тесноты и направления связи между переменными.
- Определить линии регрессии и построить их графики.
Скачать
Линейный коэффициент корреляции Пирсона
Обнаружение взаимосвязей между явлениями – одна из главных задач статистического анализа. На то есть две причины. Первая. Если известно, что один процесс зависит от другого, то на первый можно оказывать влияние через второй. Вторая. Даже если причинно-следственная связь отсутствует, то по изменению одного показателя можно предсказать изменение другого.
Взаимосвязь двух переменных проявляется в совместной вариации: при изменении одного показателя имеет место тенденция изменения другого. Такая взаимосвязь называется корреляцией, а раздел статистики, который занимается взаимосвязями – корреляционный анализ.
Корреляция – это, простыми словами, взаимосвязанное изменение показателей. Она характеризуется направлением, формой и теснотой. Ниже представлены примеры корреляционной связи.

Далее будет рассматриваться только линейная корреляция. На диаграмме рассеяния (график корреляции) изображена взаимосвязь двух переменных X и Y. Пунктиром показаны средние.

При положительном отклонении X от своей средней, Y также в большинстве случаев отклоняется в положительную сторону от своей средней. Для X меньше среднего, Y, как правило, тоже ниже среднего. Это прямая или положительная корреляция. Бывает обратная или отрицательная корреляция, когда положительное отклонение от средней X ассоциируется с отрицательным отклонением от средней Y или наоборот.
Линейность корреляции проявляется в том, что точки расположены вдоль прямой линии. Положительный или отрицательный наклон такой линии определяется направлением взаимосвязи.
Крайне важная характеристика корреляции – теснота. Чем теснее взаимосвязь, тем ближе к прямой точки на диаграмме. Как же ее измерить?
Складывать отклонения каждого показателя от своей средней нет смысла, получим нуль. Похожая проблема встречалась при измерении вариации, а точнее дисперсии. Там эту проблему обходят через возведение каждого отклонения в квадрат.

Квадрат отклонения от средней измеряет вариацию показателя как бы относительно самого себя. Если второй множитель в числителе заменить на отклонение от средней второго показателя, то получится совместная вариация двух переменных, которая называется ковариацией.

Чем больше пар имеют одинаковый знак отклонения от средней, тем больше сумма в числителе (произведение двух отрицательных чисел также дает положительное число). Большая положительная ковариация говорит о прямой взаимосвязи между переменными. Обратная взаимосвязь дает отрицательную ковариацию. Если количество совпадающих по знаку отклонений примерно равно количеству не совпадающих, то ковариация стремится к нулю, что говорит об отсутствии линейной взаимосвязи.
Таким образом, чем больше по модулю ковариация, тем теснее линейная взаимосвязь. Однако значение ковариации зависит от масштаба данных, поэтому невозможно сравнивать корреляцию для разных переменных. Можно определить только направление по знаку. Для получения стандартизованной величины тесноты взаимосвязи нужно избавиться от единиц измерения путем деления ковариации на произведение стандартных отклонений обеих переменных. В итоге получится формула коэффициента корреляции Пирсона.

Показатель имеет полное название линейный коэффициент корреляции Пирсона или просто коэффициент корреляции.
Коэффициент корреляции показывает тесноту линейной взаимосвязи и изменяется в диапазоне от -1 до 1. -1 (минус один) означает полную (функциональную) линейную обратную взаимосвязь. 1 (один) – полную (функциональную) линейную положительную взаимосвязь. 0 – отсутствие линейной корреляции (но не обязательно взаимосвязи). На практике всегда получаются промежуточные значения. Для наглядности ниже представлены несколько примеров с разными значениями коэффициента корреляции.

Таким образом, ковариация и корреляция отражают тесноту линейной взаимосвязи. Последняя используется намного чаще, т.к. является относительным показателем и не имеет единиц измерения.
Диаграммы рассеяния дают наглядное представление, что измеряет коэффициент корреляции. Однако нужна более формальная интерпретация. Эту роль выполняет квадрат коэффициента корреляции r 2 , который называется коэффициентом детерминации, и обычно применяется при оценке качества регрессионных моделей. Снова представьте линию, вокруг которой расположены точки.

Линейная функция является моделью взаимосвязи между X иY и показывает ожидаемое значение Y при заданном X. Коэффициент детерминации – это соотношение дисперсии ожидаемых Y (точек на прямой линии) к общей дисперсии Y, или доля объясненной вариации Y. При r = 0,1 r 2 = 0,01 или 1%, при r = 0,5 r 2 = 0,25 или 25%.
Выборочный коэффициент корреляции
Коэффициент корреляции обычно рассчитывают по выборке. Значит, у аналитика в распоряжении не истинное значение, а оценка, которая всегда ошибочна. Если выборка была репрезентативной, то истинное значение коэффициента корреляции находится где-то относительно недалеко от оценки. Насколько далеко, можно определить через доверительные интервалы.
Согласно Центральное Предельной Теореме распределение оценки любого показателя стремится к нормальному с ростом выборки. Но есть проблемка. Распределение коэффициента корреляции вблизи придельных значений не является симметричным. Ниже пример распределения при истинном коэффициенте корреляции ρ = 0,86.

Предельное значение не дает выйти за 1 и, как бы «поджимает» распределение справа. Симметричная ситуация наблюдается, если коэффициент корреляции близок к -1.
В общем рассчитывать на свойства нормального распределения нельзя. Поэтому Фишер предложил провести преобразование выборочного коэффициента корреляции по формуле:

Распределение z для тех же r имеет следующий вид.

Намного ближе к нормальному. Стандартная ошибка z равна:

Далее исходя из свойств нормального распределения несложно найти верхнюю и нижнюю границы доверительного интервала для z. Определим квантиль стандартного нормального распределения для заданной доверительной вероятности, т.е. количество стандартных отклонений от центра распределения.

cγ – квантиль стандартного нормального распределения;
N -1 – функция обратного стандартного распределения;
γ – доверительная вероятность (часто 95%).
Затем рассчитаем границы доверительного интервала.
Нижняя граница z:

Верхняя граница z:

Теперь обратным преобразованием Фишера из z вернемся к r.
Нижняя граница r:

Верхняя граница r:

Это была теоретическая часть. Переходим к практике расчетов.
Как посчитать коэффициент корреляции в Excel
Корреляционный анализ в Excel лучше начинать с визуализации.

На диаграмме видна взаимосвязь двух переменных. Рассчитаем коэффициент парной корреляции с помощью функции Excel КОРРЕЛ. В аргументах нужно указать два диапазона.

Коэффициент корреляции 0,88 показывает довольно тесную взаимосвязь между двумя показателями. Но это лишь оценка, поэтому переходим к интервальному оцениванию.
Расчет доверительного интервала для коэффициента корреляции в Excel
В Эксель нет готовых функций для расчета доверительного интервала коэффициента корреляции, как для средней арифметической. Поэтому план такой:
— Делаем преобразование Фишера для r.
— На основе нормальной модели рассчитываем доверительный интервал для z.
— Делаем обратное преобразование Фишера из z в r.
Удивительно, но для преобразования Фишера в Excel есть специальная функция ФИШЕР.

Стандартная ошибка z легко подсчитывается с помощью формулы.

Используя функцию НОРМ.СТ.ОБР, определим квантиль нормального распределения. Доверительную вероятность возьмем 95%.

Значение 1,96 хорошо известно любому опытному аналитику. В пределах ±1,96σ от средней находится 95% нормально распределенных величин.
Используя z, стандартную ошибку и квантиль, легко определим доверительные границы z.

Последний шаг – обратное преобразование Фишера из z назад в r с помощью функции Excel ФИШЕРОБР. Получим доверительный интервал коэффициента корреляции.

Нижняя граница 95%-го доверительного интервала коэффициента корреляции – 0,724, верхняя граница – 0,953.
Надо пояснить, что значит значимая корреляция. Коэффициент корреляции статистически значим, если его доверительный интервал не включает 0, то есть истинное значение по генеральной совокупности наверняка имеет тот же знак, что и выборочная оценка.
Несколько важных замечаний
1. Коэффициент корреляции Пирсона чувствителен к выбросам. Одно аномальное значение может существенно исказить коэффициент. Поэтому перед проведением анализа следует проверить и при необходимости удалить выбросы. Другой вариант – перейти к ранговому коэффициенту корреляции Спирмена. Рассчитывается также, только не по исходным значениям, а по их рангам (пример показан в ролике под статьей).
2. Синоним корреляции – это взаимосвязь или совместная вариация. Поэтому наличие корреляции (r ≠ 0) еще не означает причинно-следственную связь между переменными. Вполне возможно, что совместная вариация обусловлена влиянием третьей переменной. Совместное изменение переменных без причинно-следственной связи называется ложная корреляция.
3. Отсутствие линейной корреляции (r = 0) не означает отсутствие взаимосвязи. Она может быть нелинейной. Частично эту проблему решает ранговая корреляция Спирмена, которая показывает совместный рост или снижение рангов, независимо от формы взаимосвязи.
В видео показан расчет коэффициента корреляции Пирсона с доверительными интервалами, ранговый коэффициент корреляции Спирмена.
http://math.semestr.ru/math/corel.php
http://statanaliz.info/statistica/korrelyaciya-i-regressiya/linejnyj-koefficient-korrelyacii-pirsona/